Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure DevOps Services bietet Tools für die Entwicklungszusammenarbeit wie leistungsstarke Pipelines, kostenlose private Git-Repositorys, konfigurierbare Kanban-Boards und umfangreiche automatisierte und kontinuierliche Testfunktionen. Azure Pipelines ist eine Azure DevOps-Funktion, die es Ihnen ermöglicht, CI/CD zu verwalten, um Ihren Code mit leistungsstarken Pipelines bereitzustellen, die mit jeder Sprache, Plattform und Cloud funktionieren. Azure Data Explorer – Pipeline Tools ist die Azure Pipelines-Aufgabe, mit der Sie Releasepipelines erstellen und Ihre Datenbankänderungen in Ihren Azure Data Explorer-Datenbanken bereitstellen können. Sie ist kostenlos im Visual Studio Marketplace verfügbar. Die Erweiterung umfasst die folgenden grundlegenden Aufgaben:
Azure Data Explorer-Befehl – Ausführen von Administratorbefehlen für einen Azure Data Explorer-Cluster
Azure Data Explorer-Abfrage – Ausführen von Abfragen für einen Azure Data Explorer-Cluster und Analysieren der Ergebnisse
Azure Data Explorer-Abfrageserver-Schranke – Agentlose Aufgabe für die Freigabe von Veröffentlichungen abhängig vom Abfrageergebnis
In diesem Dokument wird ein einfaches Beispiel für die Verwendung des Azure Data Explorer - Pipelinetools-Vorgangs zum Bereitstellen von Schemaänderungen in Ihrer Datenbank beschrieben. Vollständige CI/CD-Pipelines finden Sie unter Azure DevOps-Dokumentation.
Voraussetzungen
- Ein Azure-Abonnement. Erstellen Sie ein kostenloses Azure-Konto.
- Ein Azure Data Explorer-Cluster und eine Datenbank. Erstellen eines Clusters und einer Datenbank
- Setup eines Azure Data Explorer-Clusters:
- Erstellen Sie eine Microsoft Entra-App durch Bereitstellen einer Microsoft Entra-Anwendung.
- Gewährleisten Sie den Zugriff auf Ihre Microsoft Entra-App in Ihrer Azure Data Explorer-Datenbank, indem Sie die Berechtigungen der Azure Data Explorer-Datenbank verwalten.
- Azure DevOps-Setup:
- Erweiterungsinstallation:
Wenn Sie Besitzer von Azure DevOps-Instanzen sind, installieren Sie die Erweiterung aus dem Marketplace, andernfalls wenden Sie sich an den Besitzer Ihrer Azure DevOps-Instanz und bitten ihn, sie zu installieren.

Vorbereiten Ihrer Inhalte für das Release
Sie können die folgenden Methoden verwenden, um Admin-Befehle für einen Cluster innerhalb einer Aufgabe auszuführen:
Verwenden Sie ein Suchmuster, um mehrere Befehlsdateien aus einem lokalen Agentordner abzurufen (Buildquellen oder Freigabeartefakte). Die einzeilige Option unterstützt mehrere Dateien mit einem Befehl pro Datei.

Befehle direkt im Text schreiben.
Geben Sie einen Dateipfad an, um Befehlsdateien direkt aus der Git-Quellcodeverwaltung abzurufen (empfohlen).
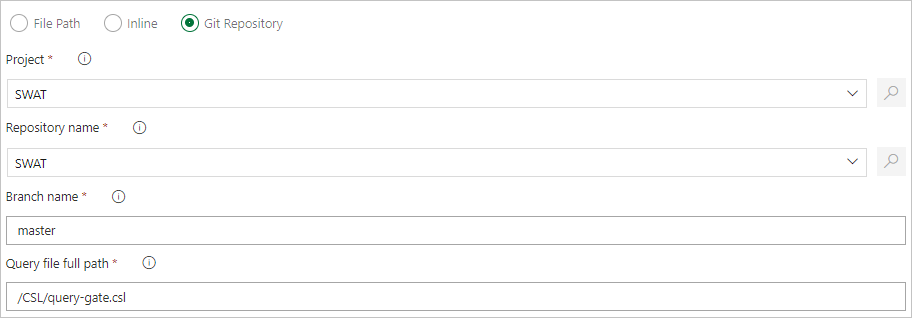
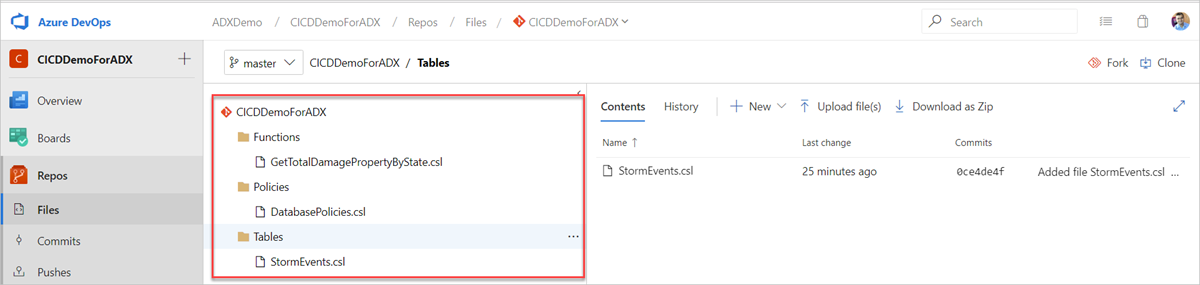
Erstellen Sie die folgenden Beispielordner (Funktionen, Richtlinien, Tabellen) in Ihrem Git-Repository. Kopieren Sie die Dateien aus dem Beispiel-Repository in die entsprechenden Ordner, und übernehmen Sie die Änderungen. Die Beispieldateien werden zur Verfügung gestellt, um den folgenden Workflow auszuführen.
Tipp
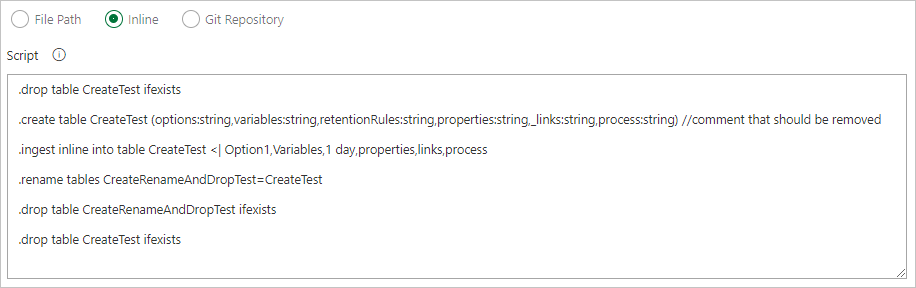
Bei der Erstellung eines eigenen Workflows empfehlen wir, den Code idempotent zu gestalten. Verwenden Sie
.create-merge tablez. B. anstelle von.create table, und verwenden Sie die.create-or-alterFunktion anstelle der.createFunktion.
Eine Release-Pipeline erstellen
Melden Sie sich bei Ihrer Azure DevOps-Organisation an.
Wählen Sie "Pipelines>Releases" im linken Menü aus, und wählen Sie dann "Neue Pipeline" aus.
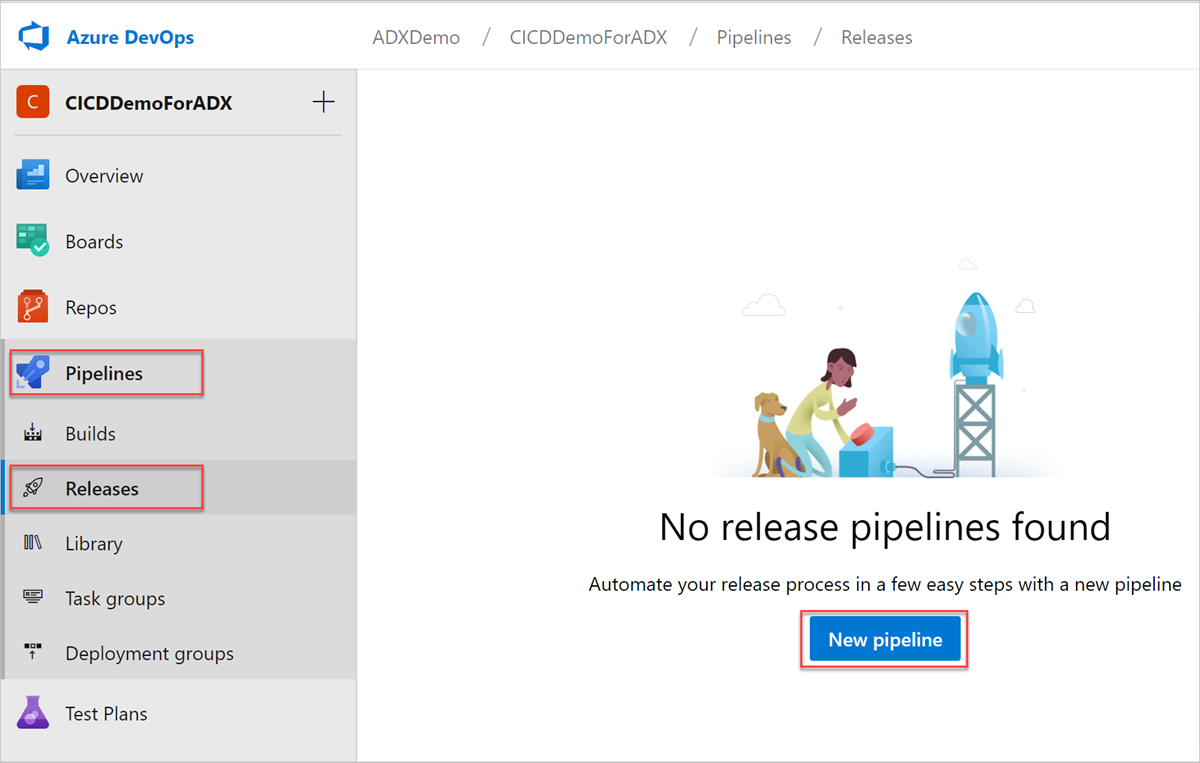
Das Fenster Neue Releasepipeline wird geöffnet. Wählen Sie auf der Registerkarte Pipelines im Bereich Eine Vorlage auswählen die Option Leerer Auftrag aus.
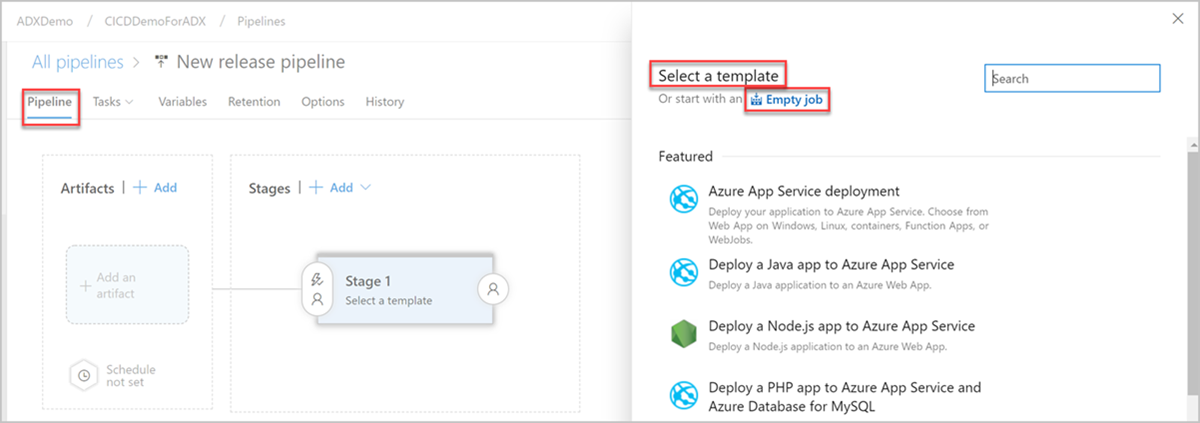
Wählen Sie die Schaltfläche "Stufe " aus. Fügen Sie im Phasenbereich den Namen der Stufe hinzu, und wählen Sie dann " Speichern " aus, um Die Pipeline zu speichern.
Ein Screenshot, der zeigt, wie man die Pipeline-Phase benennt.
Klicken Sie auf die Schaltfläche Artefakt hinzufügen. Wählen Sie im Bereich Artefakt hinzufügen das Repository aus, in dem sich Ihr Code befindet, geben Sie die relevanten Informationen ein, und wählen Sie dann Hinzufügen aus. Klicken Sie auf Speichern, um Ihre Pipeline zu speichern.
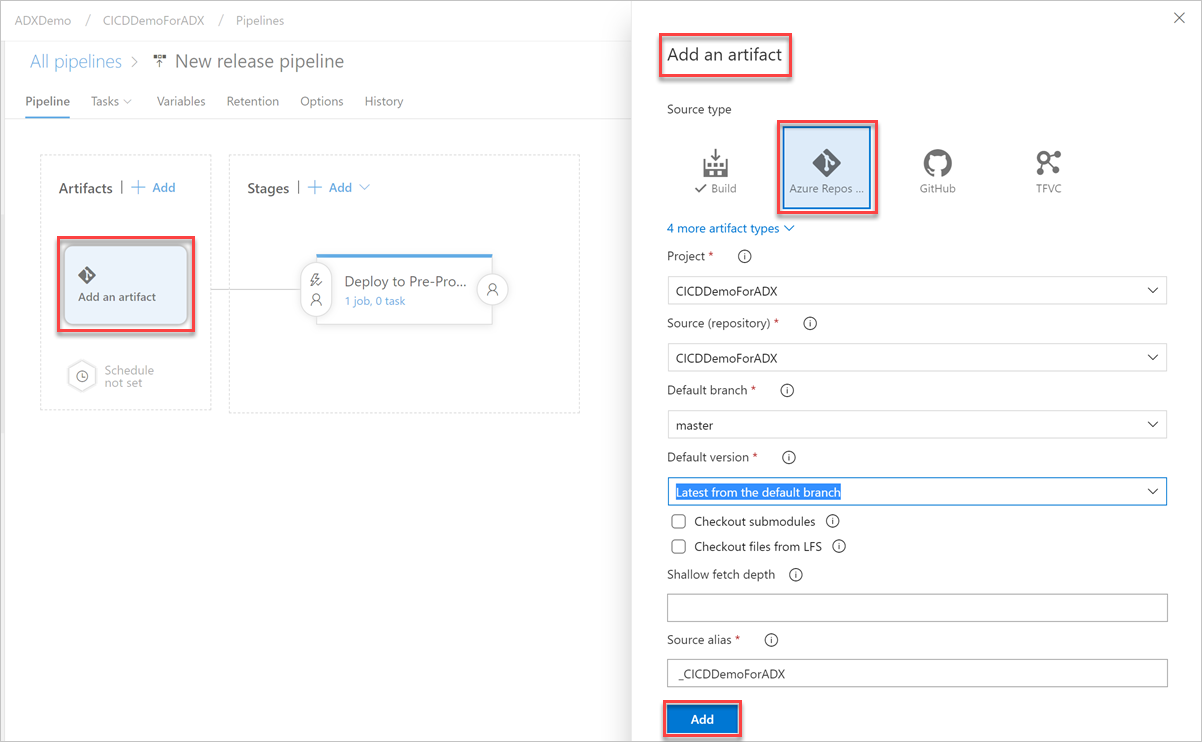
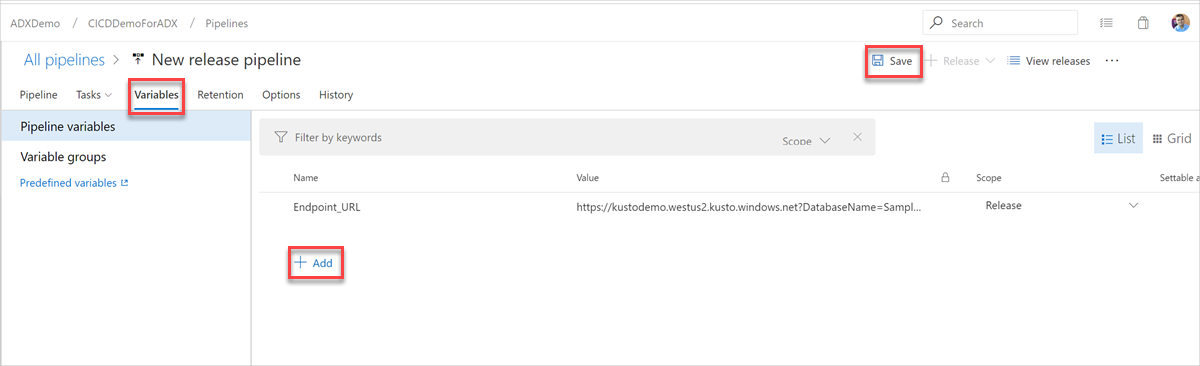
Wählen Sie auf der Registerkarte "Variablen " die Option "+Hinzufügen " aus, um eine Variable für die in der Aufgabe verwendete Endpunkt-URL zu erstellen. Geben Sie den Namen und den Wert des Endpunkts ein, und wählen Sie dann "Speichern" aus, um Ihre Pipeline zu speichern.
Um Ihre Endpunkt-URL zu finden, gehen Sie zur Übersichtsseite Ihres Azure Data Explorer-Clusters im Azure-Portal und kopieren Sie den Cluster-URI. Erstellen Sie die Variable URI im folgenden Format
https://<ClusterURI>?DatabaseName=<DBName>. Beispiel: https://kustodocs.westus.kusto.windows.net?DatabaseName=SampleDB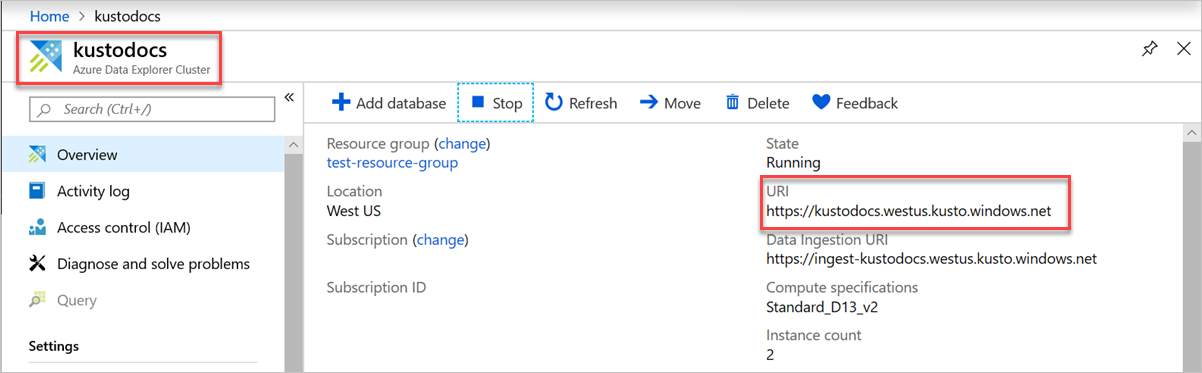
Erstelle eine Aufgabe zum Bereitstellen der Ordner
Wählen Sie auf der Registerkarte Pipeline1 Auftrag, 0 Aufgabe aus, um Aufgaben hinzuzufügen.
Wiederholen Sie die folgenden Schritte, um Befehlsaufgaben zum Bereitstellen von Dateien aus den Ordnern für Tabellen, Funktionen und Richtlinien zu erstellen:
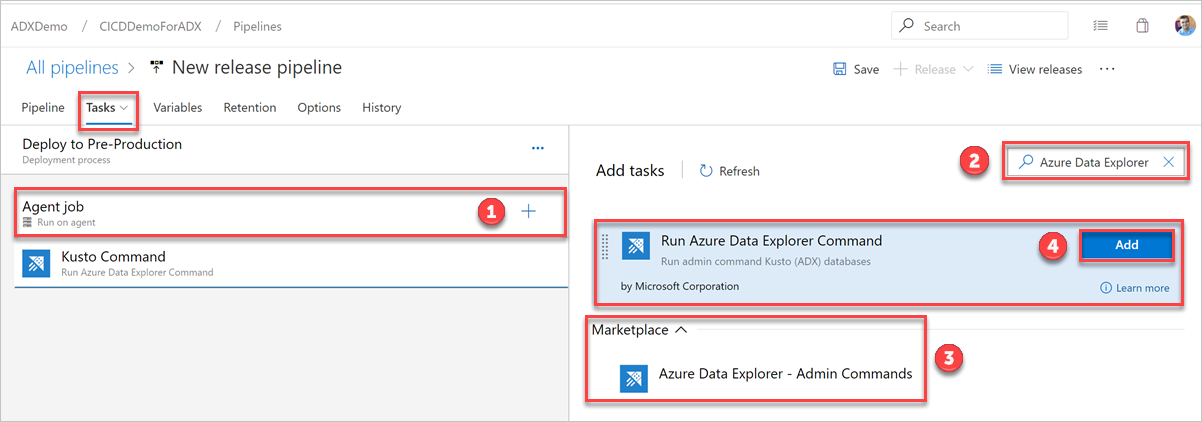
Wählen Sie auf der Registerkarte Aufgaben das + für den Agent-Job aus, und suchen Sie nach Azure Data Explorer.
Wählen Sie unter Azure Data Explorer-Befehl ausführen die Option Hinzufügen aus.
Wählen Sie Kusto-Befehl aus, und aktualisieren Sie die Aufgabe mit den folgenden Informationen:
Anzeigename: Der Name der Aufgabe. Ein Beispiel hierfür ist
Deploy <FOLDER>, wobei<FOLDER>der Name des Ordners für die von Ihnen erstellte Bereitstellungsaufgabe ist.Dateipfad: Geben Sie für jeden Ordner den Pfad in der Form
*/<FOLDER>/*.cslan, wobei<FOLDER>der relevante Ordner für die Aufgabe ist.Endpunkt-URL: Geben Sie die im vorherigen Schritt erstellte Variable
EndPoint URLan.Dienstendpunkt verwenden: Wählen Sie diese Option aus.
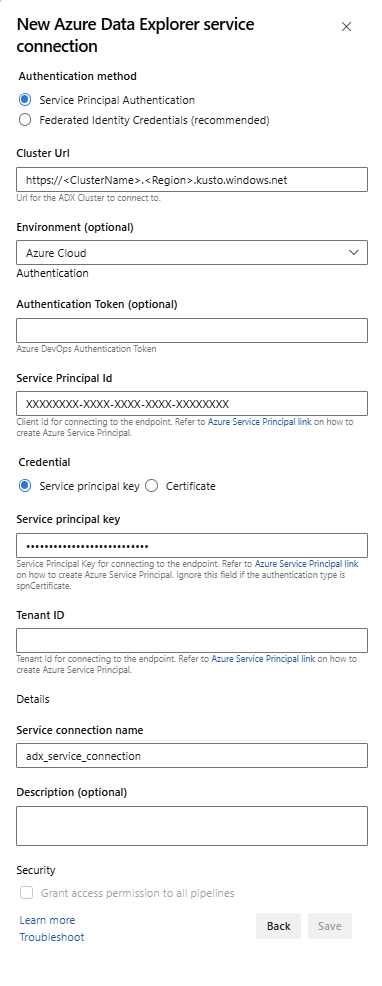
Dienstendpunkt: Wählen Sie einen vorhandenen Dienstendpunkt aus, oder erstellen Sie einen neuen (+ Neu), indem Sie im Fenster Azure Data Explorer-Dienstverbindung hinzufügen die folgenden Informationen angeben:
Einstellung Vorgeschlagener Wert Authentifizierungsmethode Richten Sie föderierte Identitätsanmeldeinformationen (FIC) ein (empfohlen) oder wählen Sie die Dienstprinzipalauthentifizierung (SPA). Verbindungsname Geben Sie den Namen zum Identifizieren dieses Dienstendpunkts ein. Cluster-URL Den Wert finden Sie im Übersichtsbereich Ihres Azure Data Explorer-Clusters im Azure-Portal. Dienstprinzipal-ID Geben Sie die Microsoft Entra App-ID ein (als Voraussetzung erstellt) Dienstprinzipal-Anwendungsschlüssel Geben Sie den Microsoft Entra App Key ein (als Voraussetzung erstellt). Microsoft Entra-Mandanten-ID Geben Sie Ihren Microsoft Entra-Mandanten ein (z. B. microsoft.com oder contoso.com).
Aktivieren Sie das Kontrollkästchen Nutzung dieser Verbindung für alle Pipelines erlauben, und wählen Sie anschließend OK aus.
Wenn Ihre Administratorbefehle asynchrone Vorgänge mit langer Laufzeit sind, aktivieren Sie das Kontrollkästchen "Auf Abschluss langer asynchroner Admin-Befehle warten". Wenn aktiviert, fragt die Aufgabe den Status der Operation über
.show operationsab, bis der Befehl abgeschlossen ist.
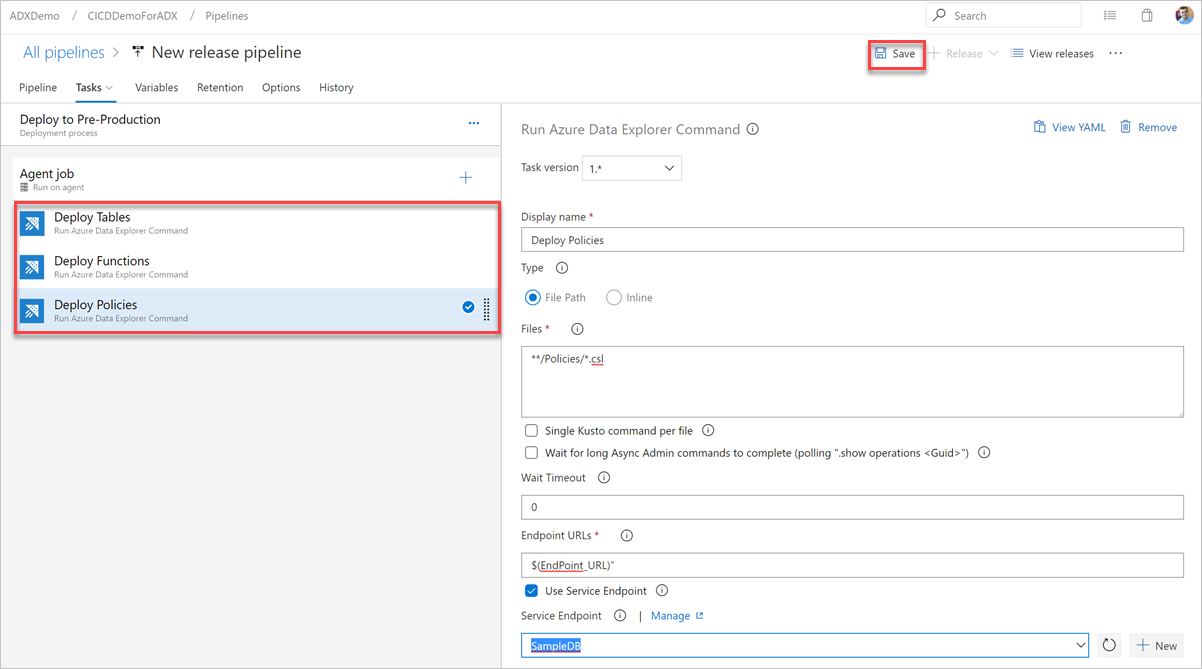
Wählen Sie "Speichern" aus, und überprüfen Sie dann auf der Registerkarte " Aufgaben ", ob es drei Aufgaben gibt: "Tabellen bereitstellen", "Funktionen bereitstellen" und "Richtlinien bereitstellen".
Erstellen einer Abfrageaufgabe
Erstellen Sie bei Bedarf eine Aufgabe, um für den Cluster eine Abfrage auszuführen. Das Ausführen von Abfragen in einer Build- oder Releasepipeline kann verwendet werden, um ein Dataset zu überprüfen und einen Schritt basierend auf den Abfrageergebnissen als erfolgreich oder nicht erfolgreich einzustufen. Die Erfolgskriterien für Aufgaben können auf einem Schwellenwert für die Zeilenanzahl oder einem einzelnen Wert basieren. Dies hängt davon ab, was von der Abfrage zurückgegeben wird.
Wählen Sie auf der Registerkarte Aufgaben das Pluszeichen (+) neben Agentenauftrag aus und suchen Sie nach Azure Data Explorer.
Wählen Sie unter Azure Data Explorer-Abfrage ausführen die Option Hinzufügen aus.
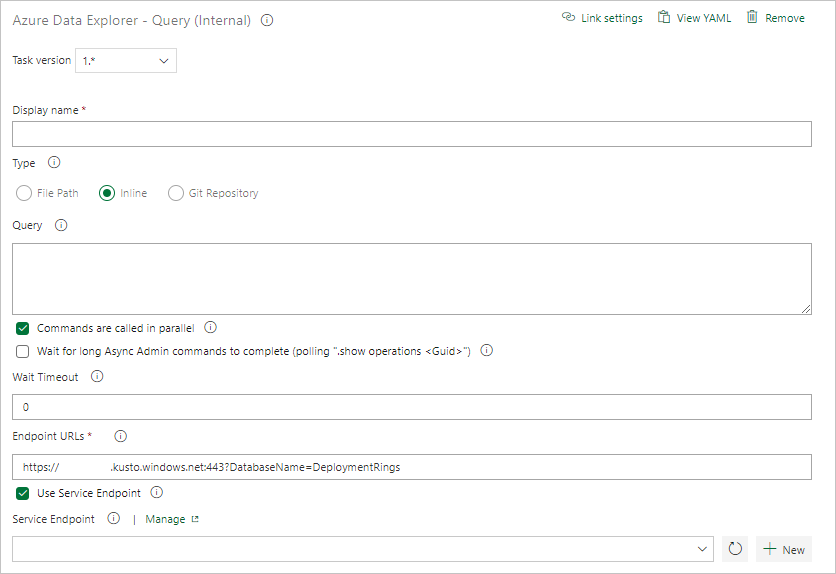
Wählen Sie Kusto-Abfrage aus, und aktualisieren Sie die Aufgabe mit den folgenden Informationen:
- Anzeigename: Der Name der Aufgabe. Beispiel: Abfragecluster.
- Typ: Wählen Sie Inline aus.
- Abfrage: Geben Sie die Abfrage ein, die Sie ausführen möchten.
-
Endpunkt-URL:Geben Sie die zuvor erstellte Variable
EndPoint URLan. - Dienstendpunkt verwenden: Wählen Sie diese Option aus.
- Dienstendpunkt: Wählen Sie einen Dienstendpunkt aus.
Wählen Sie unter „Aufgabenergebnisse“ die Erfolgskriterien der Aufgabe je nach den Ergebnissen Ihrer Abfrage wie folgt aus:
Wenn von Ihrer Abfrage Zeilen zurückgegeben werden, wählen Sie die Option Zeilenanzahl aus und geben die erforderlichen Kriterien an.
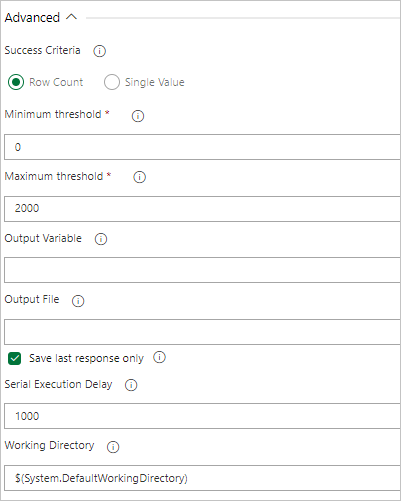
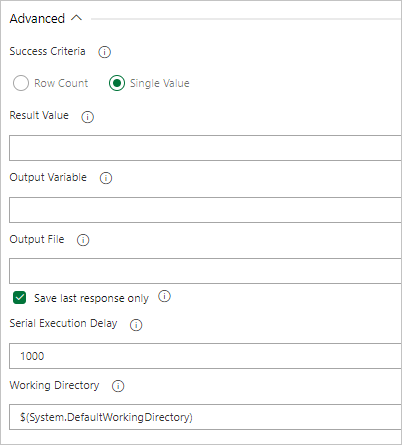
Wenn von Ihrer Abfrage ein Wert zurückgegeben wird, wählen Sie Einzelwert aus und geben das erwartete Ergebnis an.
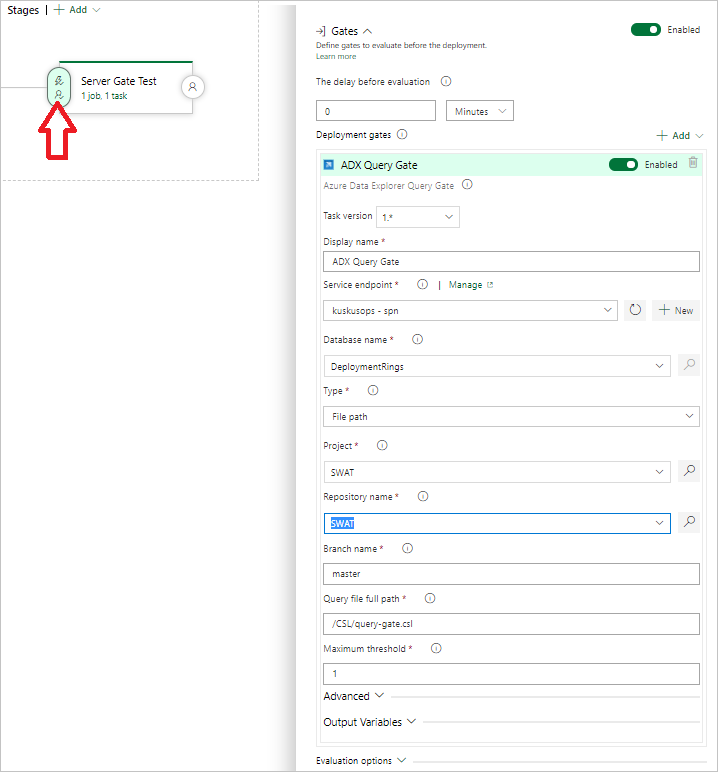
Erstelle eine Aufgabe für ein Abfrageserver-Gateway
Erstellen Sie bei Bedarf eine Aufgabe zum Ausführen einer Abfrage für einen Cluster, und richten Sie ein Gate für den Releaseprozess in Abhängigkeit der Zeilenanzahl in den Abfrageergebnissen ein. Die Serverabfrage-Gate-Aufgabe ist ein agentenloser Auftrag, was bedeutet, dass die Abfrage direkt auf dem Azure DevOps Server ausgeführt wird.
Wählen Sie auf der Registerkarte Aufgaben das Pluszeichen (+) bei Agentenloser Auftrag aus und suchen Sie nach Azure Data Explorer.
Wählen Sie unter Run Azure Data Explorer Query Server Gate (Azure Data Explorer-Abfrageservergate ausführen) die Option Hinzufügen aus.
Wählen Sie Kusto Query Server Gate und dann Server Gate Test aus.
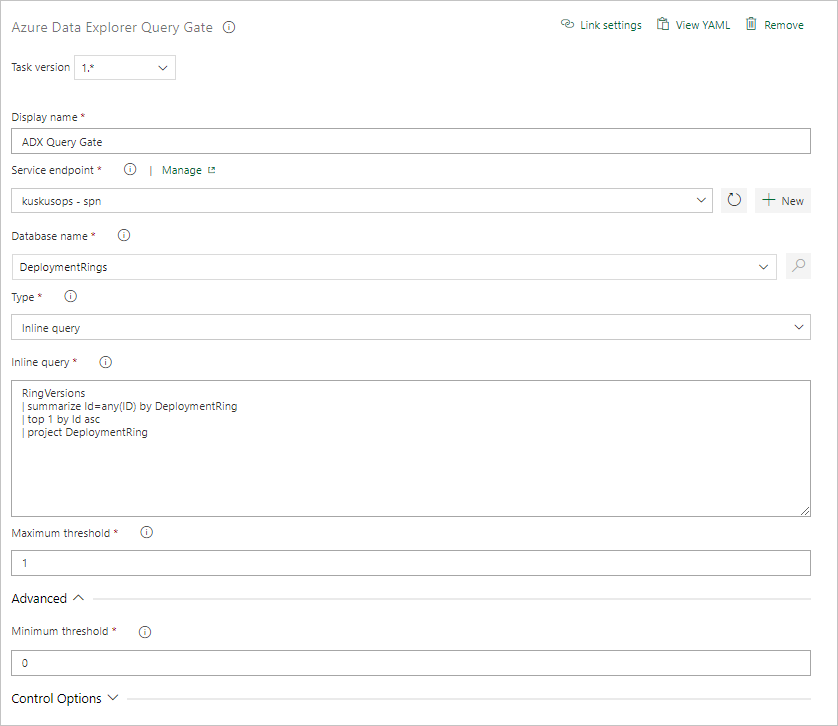
Konfigurieren Sie die Aufgabe, indem Sie die folgenden Informationen angeben:
- Anzeigename: Der Name des Gates.
- Dienstendpunkt: Wählen Sie einen Dienstendpunkt aus.
- Datenbankname: Geben Sie den Namen der Datenbank an.
- Typ: Wählen Sie Inline query (Inline-Abfrage) aus.
- Abfrage: Geben Sie die Abfrage ein, die Sie ausführen möchten.
- Maximum threshold (Maximaler Schwellenwert): Geben Sie die maximale Zeilenanzahl für die Erfolgskriterien der Abfrage an.
Hinweis
Beim Ausführen des Release sollten Ergebnisse der folgenden Art angezeigt werden.
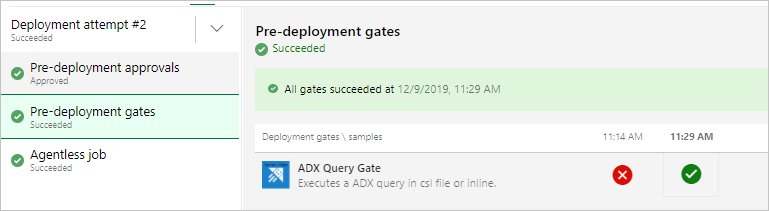
Ausführen des Release
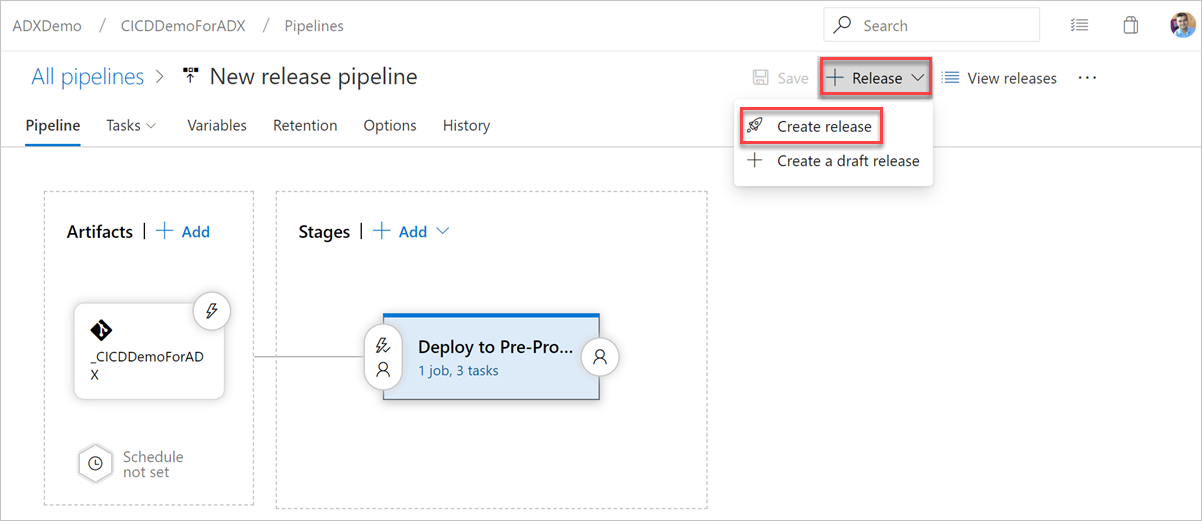
Wählen Sie +Release>Erstellen , um eine Version zu starten.
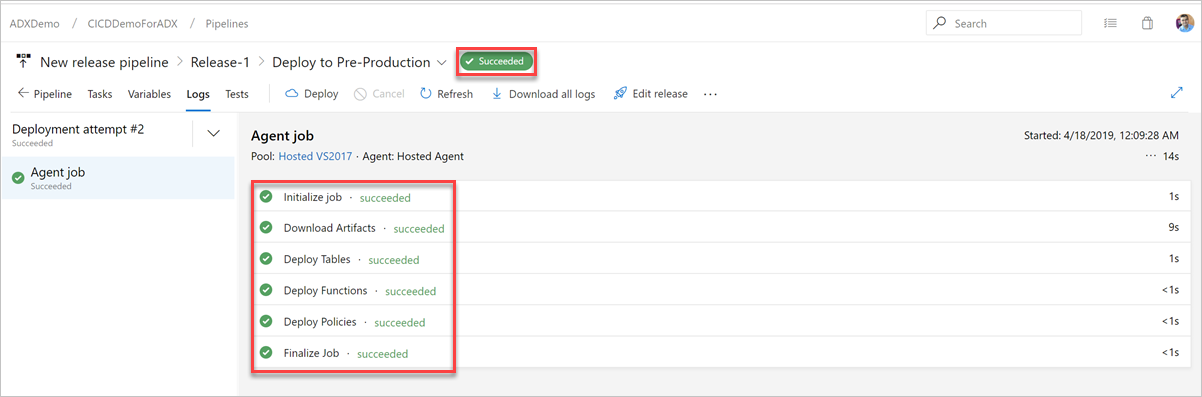
Überprüfen Sie auf der Registerkarte Protokolle, ob die Bereitstellung erfolgreich war.
Jetzt ist die Erstellung einer Releasepipeline für die Bereitstellung für die Vorproduktion abgeschlossen.
Unterstützung für schlüssellose Authentifizierung für DevOps-Aufgaben im Azure Data Explorer
Die Erweiterung unterstützt die schlüssellose Authentifizierung für Azure Data Explorer-Cluster. Mit der schlüssellosen Authentifizierung können Sie sich bei Azure Data Explorer-Clustern authentifizieren, ohne einen Schlüssel zu verwenden. Es ist sicherer und einfacher zu verwalten.
Hinweis
Kusto Fabric-Cluster-URLs werden für die Workload Identity Federation (WIF) und die verwaltete Identitätsauthentifizierung nicht unterstützt.
Verwenden Sie die Authentifizierung mit Verbundidentitätsanmeldeinformationen (FIC) in einer Azure Data Explorer-Dienstverbindung
Hinweis
Ab Erweiterungsversion 4.0.x unterstützt der Azure Data Explorer-Dienstendpunkt zusätzlich zur Dienstprinzipalauthentifizierung die Workload Identity Federation (WIF)-Authentifizierung.
Wechseln Sie in Ihrer DevOps-Instanz zu Projekteinstellungen>Dienstverbindungen>Neue Dienstverbindung>Azure Data Explorer.
Wählen Sie Verbundidentitätsanmeldeinformationen aus, und geben Sie Ihre Cluster-URL, Dienstprinzipal-ID, Mandanten-ID, einen Dienstverbindungsnamen ein, und wählen Sie dann Speichern aus.
Öffnen Sie im Azure-Portal die Microsoft Entra-App für den angegebenen Dienstprinzipal.
Wählen Sie unter Zertifikate und Geheimnisse die Option Verbundanmeldeinformationen aus.
Wählen Sie Anmeldeinformationen hinzufügen und wählen Sie dann für VerbundanmeldeinformationsszenarioAnderer Aussteller aus, und füllen Sie die Einstellungen mithilfe der folgenden Informationen aus:
Aussteller:
<https://vstoken.dev.azure.com/{System.CollectionId}>wobei{System.CollectionId}die Sammlungs-ID Ihrer Azure DevOps-Organisation ist. Sie finden die Sammlungs-ID auf folgende Weise:- Wählen Sie in der klassischen Azure DevOps-Releasepipeline Auftrag initialisieren aus. Die Sammlungs-ID wird in den Protokollen angezeigt.
Antragstellerbezeichner:
<sc://{DevOps_Org_name}/{Project_Name}/{Service_Connection_Name}>wobei{DevOps_Org_name}der Name der Azure DevOps-Organisation ist,{Project_Name}der Projektname ist und{Service_Connection_Name}der zuvor erstellte Dienstverbindungsname ist.Hinweis
Wenn der Dienstverbindungsname leer ist, können Sie ihn mit dem Leerzeichen im Feld verwenden. Beispiel:
sc://MyOrg/MyProject/My Service ConnectionName: Geben Sie einen Namen für die Anmeldeinformationen ein.
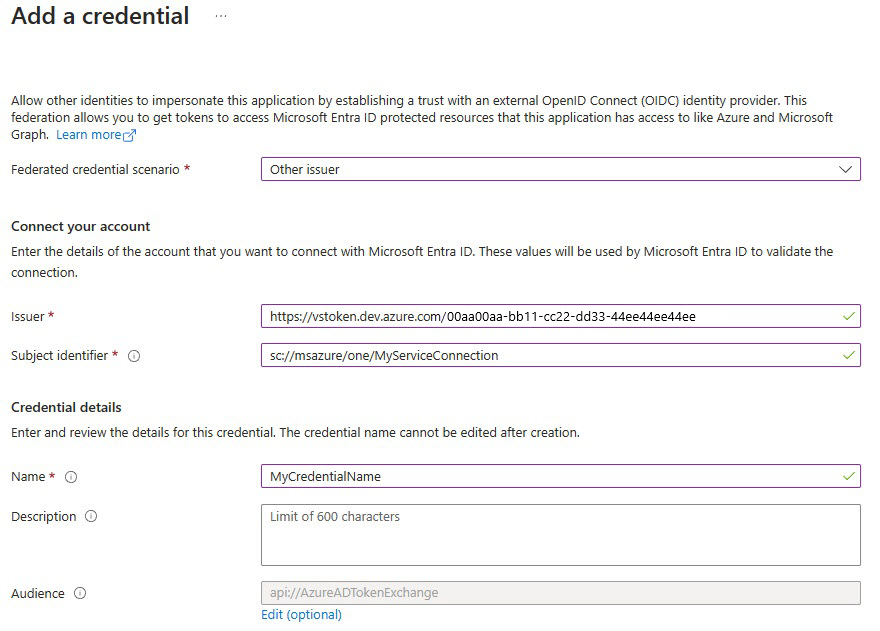
Wählen Sie Hinzufügen.
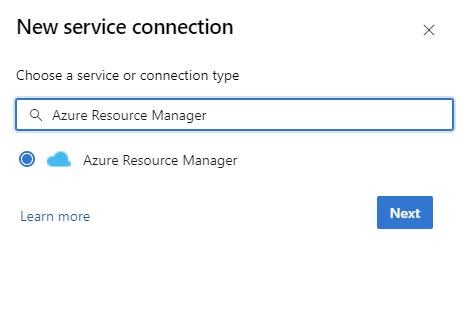
Verwenden von Verbundidentitätsanmeldeinformationen oder verwalteter Identität in einer Azure Resource Manager (ARM)-Dienstverbindung
Wechseln Sie in Ihrer DevOps-Instanz zu Projekteinstellungen>Dienstverbindungen>Neue Dienstverbindung>Azure Resource Manager.
Wählen Sie unter "Authentifizierungsmethode" die Option "Workload Identity Federation" (automatisch) aus, um fortzufahren. Sie können auch die manuelle Option "Workload Identity Federation" (manuell) verwenden, um die Details des Workload Identity Federation oder die Option "Verwaltete Identität " anzugeben. Erfahren Sie mehr über das Einrichten einer verwalteten Identität mithilfe von Azure Resource Management in Azure Resource Manager (ARM)-Dienstverbindungen.
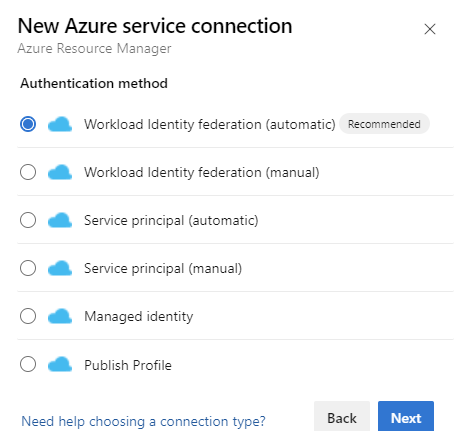
Füllen Sie die erforderlichen Details aus, wählen Sie Überprüfen und dann Speichernaus.
YAML-Pipelinekonfiguration
Sie können Aufgaben mithilfe der Azure DevOps-Webbenutzeroberfläche oder des YAML-Codes innerhalb des Pipelineschemas konfigurieren.
Die Erweiterung bietet drei Pipelineaufgaben, die über YAML zugänglich sind:
-
Azure Data Explorer Command (
ADXAdminCommand@5) – Ausführen von Administrator-/Steuerelementbefehlen für einen ADX-Cluster - Azure Data Explorer Query – Ausführen von Abfragen für einen ADX-Cluster und Analysieren der Ergebnisse
- Azure Data Explorer Query Server Gate – Agentlose Aufgabe zur Steuerung von Freigaben basierend auf dem Abfrageergebnis
Tipp
Um die Sicherheit zu erhöhen, verwenden Sie workload Identity Federation oder Managed Identity Authentication über eine Azure Resource Manager-Dienstverbindung, anstatt Anmeldeinformationen direkt in Ihrer Pipeline zu speichern. Diese schlüssellosen Authentifizierungsmethoden sind die empfohlene bewährte Methode.
Beispiel für Administratorbefehle – Inlinebefehle
Im folgenden Beispiel wird ein Inlineadministratorbefehl mit einer Azure Resource Manager (ARM)-Dienstverbindung ausgeführt, die Workload Identity Federation (WIF) und verwaltete Identitätsauthentifizierung unterstützt:
steps:
- task: Azure-Kusto.ADXAdminCommands.PublishToADX.ADXAdminCommand@5
displayName: 'Run inline ADX admin command'
inputs:
clusterUri: 'https://<ClusterName>.<Region>.kusto.windows.net'
databaseName: '<DatabaseName>'
commandsSource: 'inline'
inlineCommands: |
.create-merge table MyTable (Id:int, Name:string, Timestamp:datetime)
.create-or-alter function MyFunction() { MyTable | take 10 }
azureSubscription: '<ARM Service Connection Name>'
continueOnError: true
Beispiel für Administratorbefehle – dateibasierte Befehle
Im folgenden Beispiel werden Administratorbefehle aus Dateien ausgeführt, die mit einem Glob-Muster übereinstimmen, wobei die AAD-App-Registrierungsauthentifizierung verwendet wird:
steps:
- task: Azure-Kusto.ADXAdminCommands.PublishToADX.ADXAdminCommand@5
displayName: 'Deploy schema from files'
inputs:
clusterUri: 'https://<ClusterName>.<Region>.kusto.windows.net'
databaseName: '<DatabaseName>'
commandsSource: 'files'
commandFilesPattern: '**/*.csl'
aadAppId: '$(AAD_APP_ID)'
aadAppKey: '$(AAD_APP_KEY)'
aadTenantId: '$(AAD_TENANT_ID)'
continueOnError: true
Sie können auch je nach Ihrer Benennungskonvention für Dateien als Globmuster verwenden **/*.kql .
Beispiel für Administratorbefehle – Azure Resource Manager-Dienstverbindung
Im folgenden Beispiel wird eine Azure Resource Manager-Dienstverbindung verwendet, die Workload Identity Federation (WIF) und verwaltete Identität für die schlüssellose Authentifizierung unterstützt:
steps:
- task: Azure-Kusto.ADXAdminCommands.PublishToADX.ADXAdminCommand@5
displayName: 'Deploy schema via ARM service connection'
inputs:
clusterUri: 'https://<ClusterName>.<Region>.kusto.windows.net'
databaseName: '<DatabaseName>'
commandsSource: 'files'
commandFilesPattern: '**/*.csl'
azureSubscription: '<ARM Service Connection Name>'
continueOnError: true
condition: ne(variables['ProductVersion'], '')
Eingabeparameter für Aufgaben
In der folgenden Tabelle werden die wichtigsten Eingabeparameter für den ADXAdminCommand@5 Vorgang beschrieben:
| Parameter | Beschreibung |
|---|---|
clusterUri |
Der Basis-URI für den Kusto-Cluster (z. B. https://<ClusterName>.<Region>.kusto.windows.net) |
databaseName |
Der Name der Zieldatenbank |
commandsSource |
Die Quelle von Befehlen: inline für Inline-KQL-Befehle oder files für dateibasierte Befehle |
inlineCommands |
Auszuführende Inline-KQL-Befehle (verwendet, wenn commandsSourceinline ist) |
commandFilesPattern |
Glob-Muster für Skriptdateien (wird verwendet, wenn commandsSourcefiles ist), zum Beispiel **/*.csl oder **/*.kql. |
aadAppId |
Die Microsoft Entra App -ID (Dienstprinzipal) für die AAD-App-Authentifizierung |
aadAppKey |
Der Microsoft Entra-Applikationsschlüssel/geheimer Schlüssel für die AAD-Anwendungsauthentifizierung |
aadTenantId |
Die Microsoft Entra-Mandanten-ID für die AAD-App-Authentifizierung |
azureSubscription |
Der Name der Azure Resource Manager-Dienstverbindung für ARM-basierte Authentifizierung (unterstützt WIF und verwaltete Identität) |
Authentifizierungsmethoden
Die Erweiterung unterstützt die folgenden Authentifizierungsmethoden:
-
Azure Active Directory (AAD)-App-Registrierung – Verwenden Sie
aadAppId,aadAppKeyundaadTenantId, um sich mit einem Dienstprinzipal-Konto zu authentifizieren. Speichern Sie Anmeldeinformationen als sichere Pipelinevariablen. - Zertifikatbasierte Authentifizierung – Verwenden Sie ein Zertifikat anstelle eines App-Schlüssels für die Dienstprinzipalauthentifizierung. Speichern Sie die Zertifikatdetails als sichere Pipelinevariablen.
-
Verwaltete Identität – Verwenden Sie eine Azure Resource Manager-Dienstverbindung, die mit verwalteter Identität konfiguriert ist. Legen Sie die
azureSubscriptionEingabe auf den Dienstverbindungsnamen fest. -
Workload Identity Federation (WIF) – Verwenden Sie eine Azure Resource Manager-Dienstverbindung mit Workload Identity Federation (automatisch oder manuell). Dies ist der empfohlene schlüssellose Ansatz. Legen Sie die
azureSubscriptionEingabe auf den Dienstverbindungsnamen fest.
Hinweis
Workload Identity Federation (WIF) ist eine neuere Ergänzung zur Erweiterung. Es ermöglicht geheimnislose Authentifizierung und ist der empfohlene Ansatz für neue Pipelines. Anweisungen zum Einrichten finden Sie unter Verwenden von Verbundidentitätsanmeldeinformationen oder verwalteter Identität in einer Azure Resource Manager (ARM)-Dienstverbindung.
Abfragebeispiel
steps:
- task: Azure-Kusto.PublishToADX.ADXQuery.ADXQuery@5
displayName: '<Task Display Name>'
inputs:
targetType: 'inline'
script: |
let badVer=
RunnersLogs | where Timestamp > ago(30m)
| where EventText startswith "$$runnerresult" and Source has "ShowDiagnostics"
| extend State = extract(@"Status='(.*)', Duration.*",1, EventText)
| where State == "Unhealthy"
| extend Reason = extract(@'"NotHealthyReason":"(.*)","IsAttentionRequired.*',1, EventText)
| extend Cluster = extract(@'Kusto.(Engine|DM|CM|ArmResourceProvider).(.*).ShowDiagnostics',2, Source)
| where Reason != "Merge success rate past 60min is < 90%"
| where Reason != "Ingestion success rate past 5min is < 90%"
| where Reason != "Ingestion success rate past 5min is < 90%, Merge success rate past 60min is < 90%"
| where isnotempty(Cluster)
| summarize max(Timestamp) by Cluster,Reason
| order by max_Timestamp desc
| where Reason startswith "Differe"
| summarize by Cluster
;
DimClusters | where Cluster in (badVer)
| summarize by Cluster , CmConnectionString , ServiceConnectionString ,DeploymentRing
| extend ServiceConnectionString = strcat("#connect ", ServiceConnectionString)
| where DeploymentRing == "$(DeploymentRing)"
kustoUrls: 'https://<ClusterName>.kusto.windows.net?DatabaseName=<DatabaseName>'
authType: 'kustoserviceconn'
connectedServiceName: '<connection service name>'
minThreshold: '0'
maxThreshold: '10'
continueOnError: true