hll() (Aggregationsfunktion)
Die hll() Funktion ist eine Möglichkeit, die Anzahl eindeutiger Werte in einer Gruppe von Werten zu schätzen. Dazu werden Zwischenergebnisse für die Aggregation innerhalb des Zusammenfassungsoperators für eine Datengruppe mithilfe der dcount Funktion berechnet.
Lesen Sie den zugrunde liegenden Algorithmus (HyperLogL og Log) und die Schätzungsgenauigkeit.
Tipp
- Verwenden Sie die hll_merge-Funktion , um die Ergebnisse mehrerer
hll()Funktionen zusammenzuführen. - Verwenden Sie die funktion dcount_hll , um die Anzahl der unterschiedlichen Werte aus der Ausgabe der
hll()Funktionen zuhll_mergeberechnen.
Wichtig
Die Ergebnisse von hll(), hll_if() und hll_merge() können gespeichert und später abgerufen werden. Sie können z. B. eine tägliche eindeutige Benutzerzusammenfassung erstellen, die dann zum Berechnen der wöchentlichen Anzahl verwendet werden kann. Die genaue binäre Darstellung dieser Ergebnisse kann sich jedoch im Laufe der Zeit ändern. Es gibt keine Garantie dafür, dass diese Funktionen identische Ergebnisse für identische Eingaben erzeugen, und daher raten wir nicht davon ab, darauf zu vertrauen.
Syntax
hll( Ausdruck [, Genauigkeit])
Erfahren Sie mehr über Syntaxkonventionen.
Parameter
| Name | Type | Erforderlich | Beschreibung |
|---|---|---|---|
| expr | string |
✔️ | Der Ausdruck, der für die Aggregationsberechnung verwendet wird. |
| Genauigkeit | int |
Der Wert, der das Gleichgewicht zwischen Geschwindigkeit und Genauigkeit steuert. Wenn nichts angegeben wird, beträgt der Standardwert 1. Unterstützte Werte finden Sie unter Schätzungsgenauigkeit. |
Gibt zurück
Gibt die Zwischenergebnisse der unterschiedlichen Anzahl von Ausdrungen in der gesamten Gruppe zurück.
Beispiel
Im folgenden Beispiel wird die hll() Funktion verwendet, um die Anzahl eindeutiger Werte der DamageProperty Spalte innerhalb jedes 10-Minuten-Zeitcontainers der StartTime Spalte zu schätzen.
StormEvents
| summarize hll(DamageProperty) by bin(StartTime,10m)
Die angezeigte Ergebnistabelle enthält nur die ersten 10 Zeilen.
| StartTime | hll_DamageProperty |
|---|---|
| 2007-01-01T00:20:00Z | [[1024,14],["3803688792395291579"],[]] |
| 2007-01-01T01:00:00Z | [[1024,14],["7755241107725382121","-5665157283053373866","3803688792395291579","-1003235211361077779"],[]] |
| 2007-01-01T02:00:00Z | [[1024,14],["-1003235211361077779","-5665157283053373866","7755241107725382121"],[]] |
| 2007-01-01T02:20:00Z | [[1024,14],["7755241107725382121"],[]] |
| 2007-01-01T03:30:00Z | [[1024,14],["3803688792395291579"],[]] |
| 2007-01-01T03:40:00Z | [[1024,14],["-5665157283053373866"],[]] |
| 2007-01-01T04:30:00Z | [[1024,14],["3803688792395291579"],[]] |
| 2007-01-01T05:30:00Z | [[1024,14],["3803688792395291579"],[]] |
| 2007-01-01T06:30:00Z | [[1024,14],["1589522558235929902"],[]] |
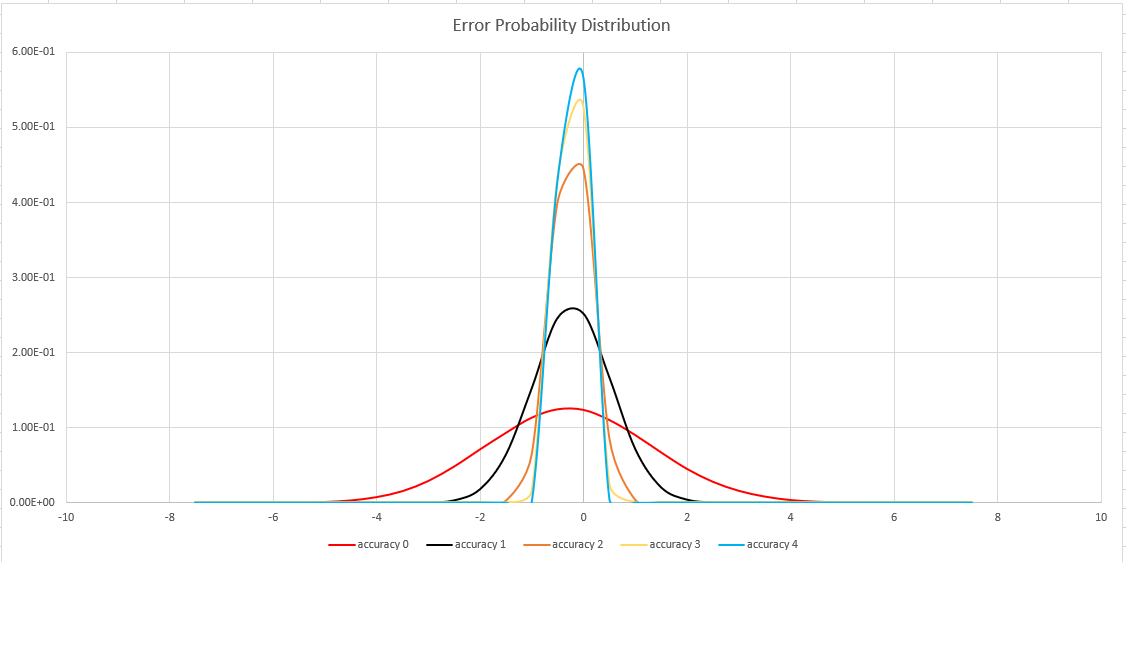
Schätzgenauigkeit
Diese Funktion verwendet eine Variante des HyperLogLog (HLL)-Algorithmus, der eine stochastische Schätzung der Set-Kardinalität durchführt. Der Algorithmus stellt einen „Knopf“ bereit, über den Genauigkeit und Ausführungszeit pro Arbeitsspeichergröße ausgeglichen werden können:
| Genauigkeit | Fehler (%) | Entry count |
|---|---|---|
| 0 | 1.6 | 212 |
| 1 | 0,8 | 214 |
| 2 | 0,4 | 216 |
| 3 | 0.28 | 217 |
| 4 | 0.2 | 218 |
Hinweis
Die Spalte „entry count“ ist die Anzahl von 1-Byte-Leistungsindikatoren in der HLL-Implementierung.
Der Algorithmus enthält einige Vorkehrungen für eine perfekte Anzahl (null Fehler), wenn die festgelegte Kardinalität klein genug ist:
- Wenn die Genauigkeitsgrad
1ist, werden 1.000 Werte zurückgegeben. - Wenn die Genauigkeitsgrad
2ist, werden 8.000 Werte zurückgegeben.
Die Fehlerbindung ist probabilistisch und keine theoretische Grenze. Der Wert ist die Standardabweichung der Fehlerverteilung (Sigma), und 99,7 % der Schätzungen weisen einen relativen Fehler von unter 3 x Sigma auf.
Die folgende Abbildung zeigt die Wahrscheinlichkeitsverteilungsfunktion des relativen Schätzfehlers in Prozent für alle unterstützten Genauigkeitseinstellungen:
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für