Zeitreihenanalyse
Clouddienste und IoT-Geräte generieren Telemetriedaten, die verwendet werden können, um Erkenntnisse wie die Überwachung der Dienstintegrität, physische Produktionsprozesse und Nutzungstrends zu gewinnen. Die Durchführung von Zeitreihenanalysen ist eine Möglichkeit, Abweichungen im Muster dieser Metriken im Vergleich zu ihrem typischen Baselinemuster zu identifizieren.
Kusto-Abfragesprache (KQL) enthält native Unterstützung für die Erstellung, Bearbeitung und Analyse mehrerer Zeitreihen. In diesem Artikel erfahren Sie, wie KQL verwendet wird, um Tausende von Zeitreihen in Sekunden zu erstellen und zu analysieren und so Überwachungslösungen und Workflows nahezu in Echtzeit zu ermöglichen.
Erstellung von Zeitreihen
In diesem Abschnitt erstellen wir einen umfangreichen Satz regulärer Zeitreihen. Dabei verwenden wir ganz einfach und intuitiv den Operator make-series und geben fehlende Werte nach Bedarf ein.
Der erste Schritt bei der Einrichtung von Zeitreihenanalysen besteht darin, die ursprüngliche Telemetriedatentabelle zu partitionieren und in einen Satz Zeitreihen umzuwandeln. Die Tabelle enthält in der Regel eine Zeitstempelspalte, kontextbezogene Dimensionen und optionale Metriken. Die Dimensionen werden zum Partitionieren der Daten verwendet. Ziel ist es, pro Partition Tausende von Zeitreihen in regelmäßigen Zeitintervallen zu erstellen.
Die Eingabetabelle demo_make_series1 enthält 600.000 Datensätze aus beliebigem Webdienstdatenverkehr. Verwenden Sie den folgenden Befehl, um ein Beispiel für 10 Datensätze zu erstellen:
demo_make_series1 | take 10
Die resultierende Tabelle enthält eine Zeitstempelspalte, drei kontextbezogene Dimensionsspalten und keine Metriken:
| TimeStamp | BrowserVer | OsVer | Land/Region |
|---|---|---|---|
| 2016-08-25 09:12:35.4020000 | Chrome 51.0 | Windows 7 | United Kingdom |
| 2016-08-25 09:12:41.1120000 | Chrome 52.0 | Windows 10 | |
| 2016-08-25 09:12:46.2300000 | Chrome 52.0 | Windows 7 | United Kingdom |
| 2016-08-25 09:12:46.5100000 | Chrome 52.0 | Windows 10 | United Kingdom |
| 2016-08-25 09:12:46.5570000 | Chrome 52.0 | Windows 10 | Republik Litauen |
| 2016-08-25 09:12:47.0470000 | Chrome 52.0 | Windows 8.1 | Indien |
| 2016-08-25 09:12:51.3600000 | Chrome 52.0 | Windows 10 | United Kingdom |
| 2016-08-25 09:12:51.6930000 | Chrome 52.0 | Windows 7 | Niederlande |
| 2016-08-25 09:12:56.4240000 | Chrome 52.0 | Windows 10 | United Kingdom |
| 2016-08-25 09:13:08.7230000 | Chrome 52.0 | Windows 10 | Indien |
Da keine Metriken vorhanden sind, können wir nur einen Satz Zeitreihen erstellen, die die Anzahl von Datenverkehrsbewegungen selbst darstellen, partitioniert nach Betriebssystem. Dazu erstellen wir folgende Abfrage:
let min_t = toscalar(demo_make_series1 | summarize min(TimeStamp));
let max_t = toscalar(demo_make_series1 | summarize max(TimeStamp));
demo_make_series1
| make-series num=count() default=0 on TimeStamp from min_t to max_t step 1h by OsVer
| render timechart
- Verwenden Sie den Operator
make-series, um einen Satz aus drei Zeitreihen zu erstellen, wobei Folgendes gilt:num=count(): Zeitreihe für den Datenverkehr.from min_t to max_t step 1h: Die Zeitreihe wird im Zeitbereich in Abschnitten von jeweils einer Stunde erstellt (ältester und neuester Zeitstempel der Tabellendatensätze).default=0: Geben Sie eine Füllmethode für fehlende Zeitabschnitte an, um eine reguläre Zeitreihe zu erstellen. Verwenden Sie alternativ dazuseries_fill_const(),series_fill_forward(),series_fill_backward()undseries_fill_linear(), um Änderungen zu berücksichtigen.by OsVer: Partitioniert nach Betriebssystem
- Die tatsächliche Datenstruktur der Zeitreihen ist ein numerisches Array des aggregierten Werts pro Zeitabschnitt. Wir verwenden
render timechartfür die Visualisierung.
In der oben stehenden Tabelle haben wir drei Partitionen. Wir können separate Zeitreihen für jede Betriebssystemversion erstellen – Windows 10 (rot), 7 (blau) und 8.1 (grün) –, wie im Diagramm zu sehen:
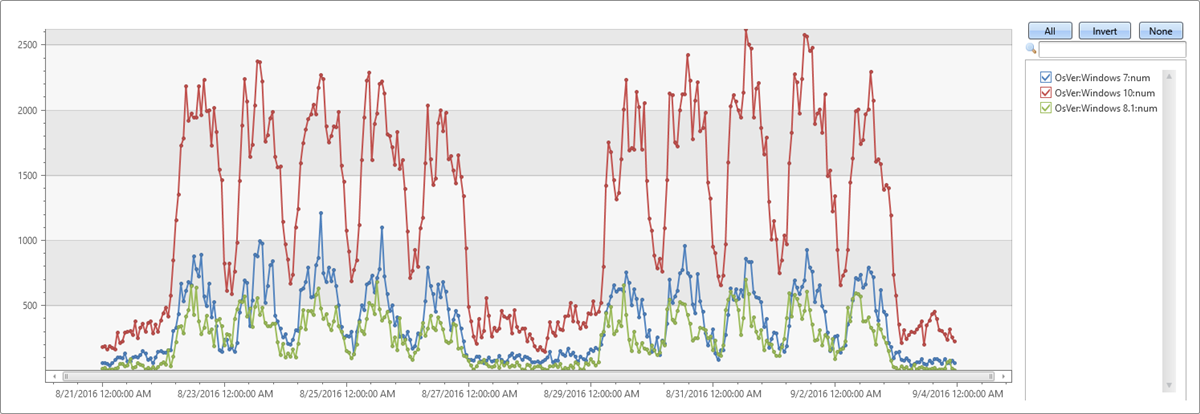
Analysefunktionen für Zeitreihen
In diesem Abschnitt führen wir typische Funktionen zum Verarbeiten von Zeitreihen aus. Sobald eine Reihe von Zeitreihen erstellt wurde, unterstützt KQL eine wachsende Liste von Funktionen, um sie zu verarbeiten und zu analysieren. Wir beschreiben einige repräsentative Funktionen für die Verarbeitung und Analyse von Zeitreihen.
Filterung
Die Filterung ist ein gängiges Verfahren zur Signalverarbeitung und eignet sich gut für Aufgaben zur Verarbeitung von Zeitreihen (z.B. zum Glätten eines Signals mit Rauschen oder zum Erkennen von Änderungen).
- Es gibt zwei allgemeine Filterfunktionen:
series_fir(): Anwenden eines FIR-Filters. Wird zur einfachen Berechnung des gleitenden Durchschnitts und zur Differenzierung der Zeitreihe zum Erkennen von Änderungen verwendet.series_iir(): Anwenden eines IIR-Filters. Wird zur exponentiellen Glättung und für kumulative Summen verwendet.
Extend: Erweitern Sie die Zeitreihe, indem Sie der Abfrage eine neue Reihe für den gleitenden Durchschnitt von Abschnitten der Größe 5 (namens ma_num) hinzufügen:
let min_t = toscalar(demo_make_series1 | summarize min(TimeStamp));
let max_t = toscalar(demo_make_series1 | summarize max(TimeStamp));
demo_make_series1
| make-series num=count() default=0 on TimeStamp from min_t to max_t step 1h by OsVer
| extend ma_num=series_fir(num, repeat(1, 5), true, true)
| render timechart
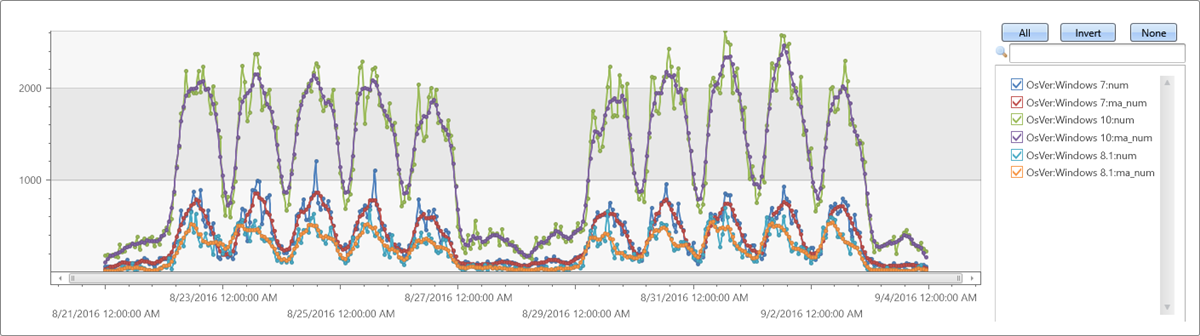
Regressionsanalyse
Azure Data Explorer unterstützt segmentierte lineare Regressionsanalysen, um den Trend der Zeitreihe zu schätzen.
- Verwenden Sie series_fit_line(), um zum Erkennen eines allgemeinen Trends die beste angepasste Linie für eine Zeitreihe zu ermitteln.
- Verwenden Sie series_fit_2lines(), um Trendänderungen relativ zur Baseline zu erkennen – diese sind in Überwachungsszenarien nützlich.
Beispiel für die Funktionen series_fit_line() und series_fit_2lines() in einer Zeitreihenabfrage:
demo_series2
| extend series_fit_2lines(y), series_fit_line(y)
| render linechart with(xcolumn=x)
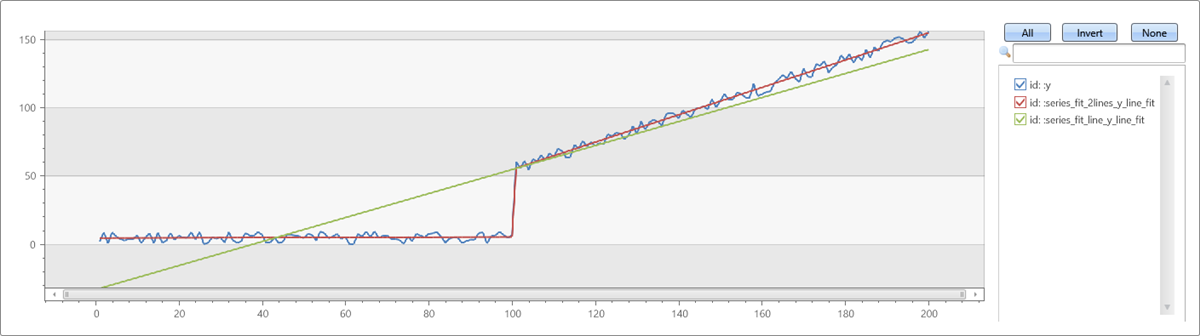
- Blau: ursprüngliche Zeitreihe
- Grün: angepasste Linie
- Rot: zwei angepasste Linien
Hinweis
Die Funktion hat den Punkt des Sprungs (der Änderung der Stufe) erkannt.
Erkennung der Saisonalität
Viele Metriken folgen saisonalen (periodischen) Mustern. Benutzerdatenverkehr in Clouddiensten weist in der Regel tägliche und wöchentliche Muster auf, wobei die höchsten Werte etwa um die Mitte der Werktage und die niedrigsten während der Nacht und am Wochenende zu finden sind. IoT-Sensoren messen in regelmäßigen Abständen. Physikalische Messwerte wie Temperatur, Luftdruck oder Luftfeuchtigkeit können ebenfalls ein saisonales Verhalten zeigen.
Das folgende Beispiel wendet die Erkennung von Saisonalität auf einen Monat Datenverkehr eines Webdiensts an (Zeitabschnitte von 2 Stunden):
demo_series3
| render timechart
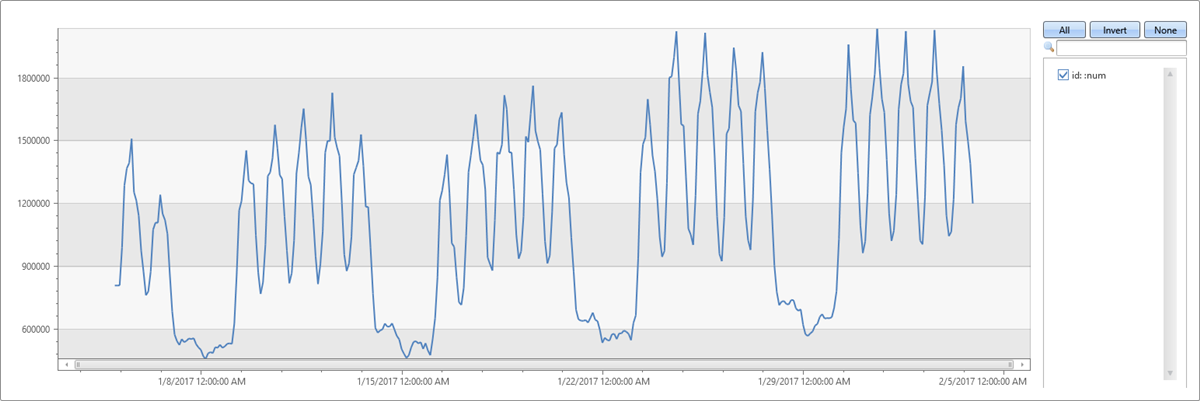
- Verwenden Sie series_periods_detect(), um die Zeiträume in der Zeitreihe automatisch zu erkennen.
- Verwenden Sie series_periods_validate(), wenn Sie wissen, dass eine Metrik bestimmte Zeiträume aufweisen sollte und Sie überprüfen möchten, ob diese tatsächlich vorhanden sind.
Hinweis
Wenn bestimmte Zeiträume nicht vorhanden sind, handelt es sich um eine Anomalie.
demo_series3
| project (periods, scores) = series_periods_detect(num, 0., 14d/2h, 2) //to detect the periods in the time series
| mv-expand periods, scores
| extend days=2h*todouble(periods)/1d
| Zeiträume | Treffer | days |
|---|---|---|
| 84 | 0.820622786055595 | 7 |
| 12 | 0.764601405803502 | 1 |
Die Funktion erkennt tägliche und wöchentliche Saisonalität. Der Trefferwert bei der täglichen Messung ist geringer, weil sich Wochenendtage von Wochentagen unterscheiden.
Elementbezogene Funktionen
In einer Zeitreihe können arithmetische und logische Operationen durchgeführt werden. Mit series_subtract() können wir eine residuale Zeitreihe berechnen, also den Unterschied zwischen der ursprünglichen Rohdatenmetrik und einer geglätteten Metrik, und nach Anomalien im verbleibenden Signal suchen:
let min_t = toscalar(demo_make_series1 | summarize min(TimeStamp));
let max_t = toscalar(demo_make_series1 | summarize max(TimeStamp));
demo_make_series1
| make-series num=count() default=0 on TimeStamp in from min_t to max_t step 1h by OsVer
| extend ma_num=series_fir(num, repeat(1, 5), true, true)
| extend residual_num=series_subtract(num, ma_num) //to calculate residual time series
| where OsVer == "Windows 10" // filter on Win 10 to visualize a cleaner chart
| render timechart
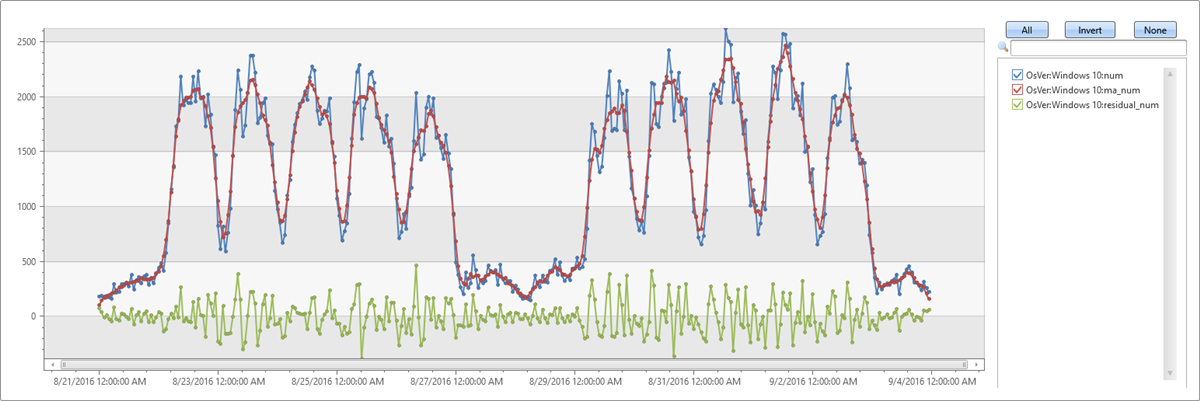
- Blau: ursprüngliche Zeitreihe
- Rot: geglättete Zeitreihe
- Grün: residuale Zeitreihe
Zeitreihenworkflow für eine große Anzahl von Vorgängen
Das folgende Beispiel zeigt, wie diese Funktionen innerhalb von Sekunden für mehrere Tausend Zeitreihen ausgeführt werden können, um Anomalien zu erkennen. Um einige beispielhafte Telemetriedatensätze aus der Metrik für die Anzahl von Lesevorgängen eines Datenbankdiensts im Lauf von vier Tagen anzuzeigen, führen Sie die folgende Abfrage aus:
demo_many_series1
| take 4
| timestamp | Loc | Op | DB | DataRead |
|---|---|---|---|---|
| 2016-09-11 21:00:00.0000000 | Loc 9 | 5117853934049630089 | 262 | 0 |
| 2016-09-11 21:00:00.0000000 | Loc 9 | 5117853934049630089 | 241 | 0 |
| 2016-09-11 21:00:00.0000000 | Loc 9 | -865998331941149874 | 262 | 279862 |
| 2016-09-11 21:00:00.0000000 | Loc 9 | 371921734563783410 | 255 | 0 |
Und eine einfache Statistik:
demo_many_series1
| summarize num=count(), min_t=min(TIMESTAMP), max_t=max(TIMESTAMP)
| num | min_t | max_t |
|---|---|---|
| 2177472 | 2016-09-08 00:00:00.0000000 | 2016-09-11 23:00:00.0000000 |
Eine Zeitreihe in 1-Stunden-Abschnitten der Metrik für die Anzahl von Lesevorgängen (4 Tage × 24 Stunden = 96 Punkte) führt zu einer normalen Musterfluktuation:
let min_t = toscalar(demo_many_series1 | summarize min(TIMESTAMP));
let max_t = toscalar(demo_many_series1 | summarize max(TIMESTAMP));
demo_many_series1
| make-series reads=avg(DataRead) on TIMESTAMP from min_t to max_t step 1h
| render timechart with(ymin=0)
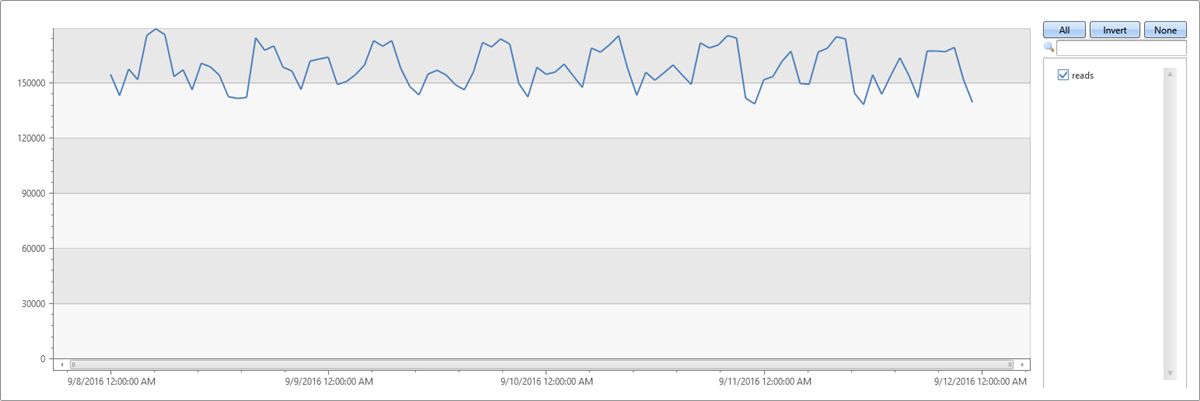
Das oben beschriebene Verhalten ist irreführend, da die einzelne normale Zeitreihe aus Tausenden von verschiedenen Instanzen aggregiert wurde, die anomale Muster aufweisen können. Daher erstellen wir eine Zeitreihe pro Instanz. Ein instance wird durch Loc (Location), Op (Vorgang) und DB (spezifischer Computer) definiert.
Wie viele Zeitreihen können wir erstellen?
demo_many_series1
| summarize by Loc, Op, DB
| count
| Anzahl |
|---|
| 18339 |
Jetzt erstellen wir einen Satz aus 18.339 Zeitreihen der Metrik für die Anzahl von Lesevorgängen. Wir fügen die by-Klausel zur make-series-Anweisung hinzu, wenden lineare Regression an und wählen die beiden Zeitreihen aus, bei denen der signifikanteste Abwärtstrend zu beobachten war:
let min_t = toscalar(demo_many_series1 | summarize min(TIMESTAMP));
let max_t = toscalar(demo_many_series1 | summarize max(TIMESTAMP));
demo_many_series1
| make-series reads=avg(DataRead) on TIMESTAMP from min_t to max_t step 1h by Loc, Op, DB
| extend (rsquare, slope) = series_fit_line(reads)
| top 2 by slope asc
| render timechart with(title='Service Traffic Outage for 2 instances (out of 18339)')
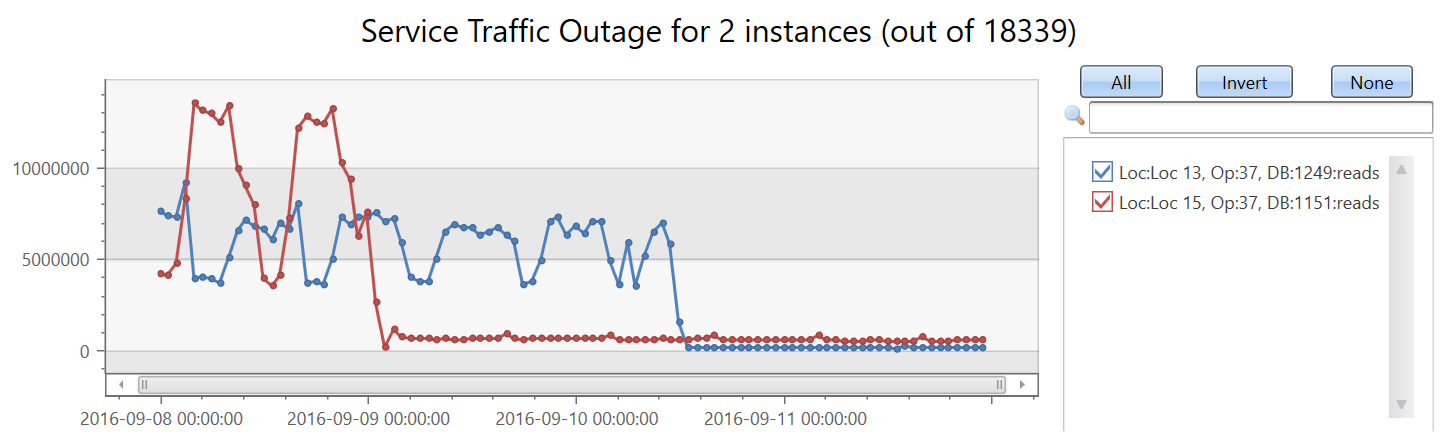
Zeigen Sie die Instanzen an:
let min_t = toscalar(demo_many_series1 | summarize min(TIMESTAMP));
let max_t = toscalar(demo_many_series1 | summarize max(TIMESTAMP));
demo_many_series1
| make-series reads=avg(DataRead) on TIMESTAMP from min_t to max_t step 1h by Loc, Op, DB
| extend (rsquare, slope) = series_fit_line(reads)
| top 2 by slope asc
| project Loc, Op, DB, slope
| Loc | Op | DB | slope |
|---|---|---|---|
| Loc 15 | 37 | 1151 | -102743.910227889 |
| Loc 13 | 37 | 1249 | -86303.2334644601 |
In weniger als zwei Minuten wurden fast 20.000 Zeitreihen analysiert und zwei ungewöhnliche Zeitreihen erkannt, in denen die Leseanzahl plötzlich gesunken ist.
Diese erweiterten Funktionen in Kombination mit schneller Leistung bieten eine einzigartige und leistungsstarke Lösung für die Zeitreihenanalyse.
Verwandte Inhalte
- Erfahren Sie mehr über die Anomalieerkennung und -vorhersage mit KQL.
- Erfahren Sie mehr über Machine Learning-Funktionen mit KQL.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für