Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure Data Explorer bietet einen Preisrechner , um die Kosten Ihres Clusters zu schätzen. Die Schätzung basiert auf Spezifikationen wie geschätzter Datenaufnahme und Modularbeitsauslastung. Wenn Sie Änderungen an der Konfiguration vornehmen, ändert sich auch die Preisschätzung, damit Sie die Kostenauswirkungen Ihrer Konfigurationsoptionen verstehen können.
In diesem Artikel werden die einzelnen Komponenten des Rechners erläutert und Tipps zum Treffen besserer Entscheidungen zum Konfigurieren des Clusters angezeigt.
Funktionsweise
Sie legen die Region, Umgebung und geschätzte Datenaufnahme Ihres Clusters fest. Anschließend schätzt der Rechner die monatlichen Kosten basierend auf automatisch ausgewählten oder manuell ausgewählten Spezifikationen in den folgenden Komponenten:
- Anzahl der Engine-Instanzen
- Datenverwaltungsinstanzen
- Speicher und Transaktionen
- Netzwerk
- Azure Data Explorer-Markup
Am Ende des Formulars werden die einzelnen Komponentenschätzungen zusammen addiert, um eine monatliche Gesamtschätzung zu erstellen. Die Komponente schätzt und aktualisiert, während Sie Konfigurationsänderungen vornehmen.
Erste Schritte
- Wechseln Sie zum Preisrechner.
- Scrollen Sie nach unten auf der Seite, bis eine Registerkarte mit dem Titel "Ihre Schätzung" angezeigt wird.
- Überprüfen Sie, ob Azure-Daten-Explorer auf der Registerkarte angezeigt wird. Wenn dies nicht der Fehler ist, gehen Sie wie folgt vor:
- Scrollen Sie zurück zum Anfang der Seite.
- Geben Sie im Suchfeld den Azure-Daten-Explorer ein.
- Wählen Sie das Azure Data Explorer-Widget aus.
- Starten Sie die Konfiguration.
Die Abschnitte dieses Artikels entsprechen den Komponenten im Rechner, und heben Sie hervor, was Sie wissen müssen.
Region und Umgebung
Die Region und Umgebung, die Sie für Ihren Cluster auswählen, wirkt sich auf die Kosten der einzelnen Komponenten aus. Dies liegt daran, dass die verschiedenen Regionen und Umgebungen nicht genau dieselben Dienste oder Kapazitäten bereitstellen.
Wählen Sie die Umgebung für Ihren Cluster aus.
Produktionscluster enthalten zwei oder mehr Knoten für die Modul- und Datenverwaltung und arbeiten unter azure Data Explorer SLA.
Entwicklungs-/Testcluster sind die niedrigste Kostenoption, was sie hervorragend für die Dienstbewertung, das Durchführen von PoCs und Szenarioüberprüfungen macht. Sie sind in der Größe begrenzt und können nicht über einen einzelnen Knoten hinaus wachsen. Für diese Cluster gibt es keine Azure Data Explorer-Markupgebühr oder Produkt-SLA.
Wählen Sie die gewünschte Region für Ihren Cluster aus.
Verwenden Sie den Entscheidungsleitfaden für Regionen, um die richtige Region für Sie zu finden. Ihre Wahl hängt möglicherweise von den Anforderungen ab, z. B.:
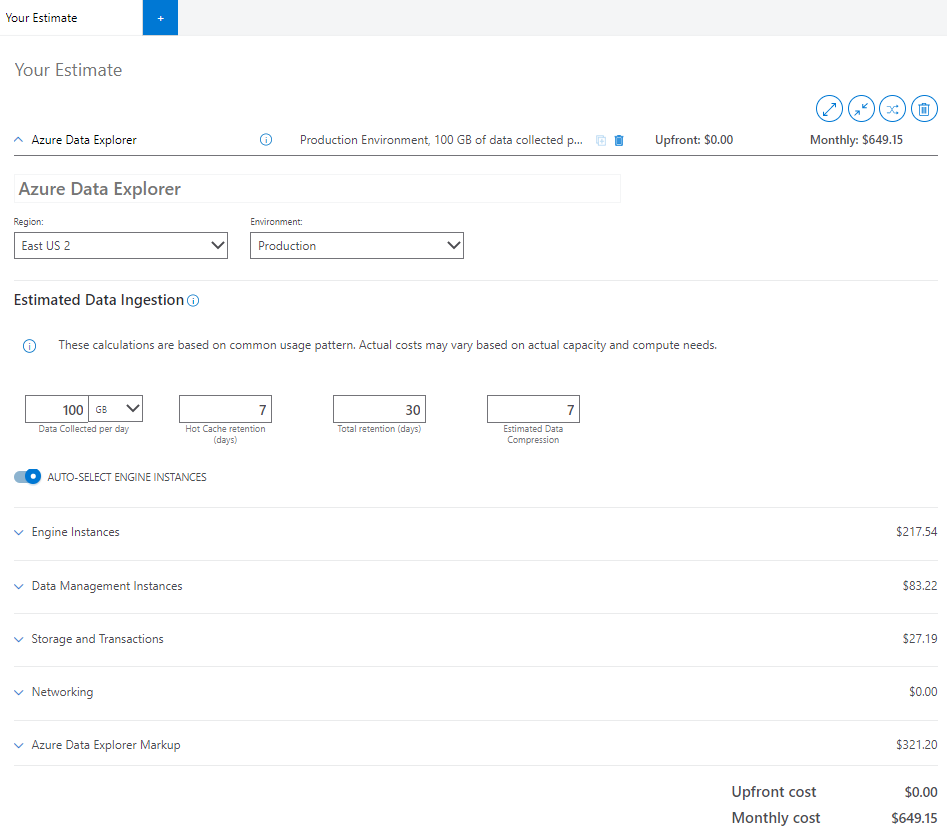
Geschätzte Datenaufnahme
Die Informationen im Abschnitt "Geschätzte Datenaufnahme " des Rechners beeinflussen den Preis aller Komponenten Ihres Clusters.
Geben Sie im Rechner Schätzungen für die folgenden Felder ein:
Gesammelte Daten pro Tag (GB/TB): Daten, die Sie täglich ohne Komprimierung in Azure Data Explorer-Cluster aufnehmen möchten. Berechnen Sie diese Schätzung basierend auf der Anzahl der Dateien und der durchschnittlichen Größe einer aufgenommenen Datei. Wenn Sie die Daten mithilfe von Nachrichten streamen, überprüfen Sie die durchschnittliche Größe einer einzelnen Nachricht und die Anzahl der Nachrichten, die Sie aufnehmen.
Aufbewahrungszeiträume (Tage): Zeitraum, für den Ihre Daten im Cache für den schnellen Abfragezugriff gespeichert werden. Erfasste Daten, die gemäß unserer Cacherichtlinie auf der lokalen SSD des Moduldiensts zwischengespeichert werden. Ihre Abfrageleistungsanforderung bestimmt die Menge der Computeknoten und den erforderlichen lokalen SSD-Speicher.
Gesamtaufbewahrung (Tage):Zeitraum, für den Ihre Daten gespeichert und für die Abfrage verfügbar sind. Nach dem Aufbewahrungsfenster werden Ihre Daten automatisch entfernt. Wählen Sie das Datenaufbewahrungsfenster basierend auf Compliance- oder anderen gesetzlichen Anforderungen aus. Wenden Sie die Hot Window-Funktion an, um die Daten basierend auf dem Zeitfenster für schnellere Abfragen zu warmieren.
Geschätzte Datenkomprimierung: Verhältnis zwischen der nicht komprimierten Datengröße und der komprimierten Größe. Die Datenkomprimierung variiert je nach Kardinalität der Werte und deren Struktur. Beispielsweise weist Protokolle, die in strukturierten Spalten aufgenommen werden, eine höhere Komprimierung im Vergleich zu dynamischen Spalten oder GUID auf. Alle aufgenommenen Daten werden standardmäßig komprimiert.
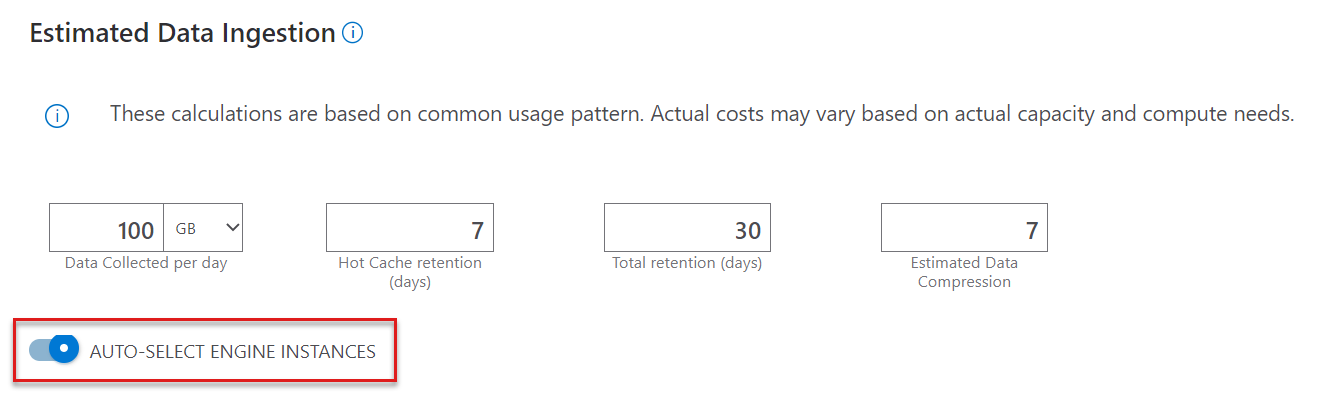
Automatisch ausgewählte Modulinstanzen
Wenn Sie die verbleibenden Komponenten einzeln konfigurieren möchten, deaktivieren Sie AUTO-SELECT ENGINE INSTANCES. Wenn der Rechner aktiviert ist, wählt der Rechner die optimale Lagerhaltungseinheit (SKU) basierend auf den Aufnahmeeingaben aus.
Anzahl der Engine-Instanzen
Modulinstanzen sind für die Indizierung, das Zwischenspeichern von Daten auf lokalen SSDs, premium-Speicher als verwaltete Datenträger und das Bereitstellen von Abfragen verantwortlich. Der Moduldienst erfordert mindestens zwei Computeinstanzen.
Workloadoptionen
Im Folgenden sind die Optionen für die Arbeitsauslastung des Moduls aufgeführt:
- Alles: Wählt automatisch die optimale SKU basierend auf der von Ihnen bereitgestellten Eingabe aus.
-
Berechnete optimierte SKUs:
- Bietet hohe Kerne zum Hot Cache-Verhältnis
- Geeignet für hohe Abfrageraten
- Lokale SSD für E/A mit geringer Latenz
-
Speicheroptimierte SKUs:
- Bietet größere Speicheroptionen von 1 TB bis 4 TB pro Modulknoten
- Geeignet für Workloads, für die große Datenmengen zwischengespeichert werden müssen
- In einigen SKUs ist der premiumverwaltete Datenträgerspeicher an den Modulknoten anstatt an lokale SSD für hot Data Storage angefügt.
So erhalten Sie eine Schätzung für Modulinstanzen:
- Wählen Sie zwischen den Workloadoptionen aus. Die Modulinstanz wird entsprechend angepasst. Wenn Sie AUTO-SELECT ENGINE INSTANCES deaktiviert haben, wählen Sie die spezifische Modulinstanz und die VM-Serie aus.
- Geben Sie die Anzahl der Stunden, Tage oder Monate an, die Sie das Modul ausführen möchten.
- (Optional) Wählen Sie einen Sparoptionenplan aus.
Die Premium Managed Disk-Komponente basiert auf der ausgewählten SKU.
Hinweis
Nicht alle VM-Reihen werden in jeder Region angeboten. Wenn Sie nach einer SKU suchen, die nicht in der ausgewählten Region aufgeführt ist, wählen Sie eine andere Region aus.
Datenverwaltungsinstanzen
Der Datenverwaltungsdienst (DM) ist für die Datenaufnahme aus verwalteten Datenpipelines wie Azure Blob Storage, Event Hubs, IoT Hubs und anderen Diensten wie Azure Data Factory, Azure Stream Analytics und Kafka verantwortlich. Der Dienst erfordert mindestens zwei Computeinstanzen, die basierend auf der Modulinstanzgröße automatisch konfiguriert und verwaltet werden.
So erhalten Sie eine Schätzung für Datenverwaltung Instanzen:
- Geben Sie die Anzahl der Stunden, Tage oder Monate an, die Sie ausführen möchten.
- (Optional) Wählen Sie einen Sparoptionenplan aus.
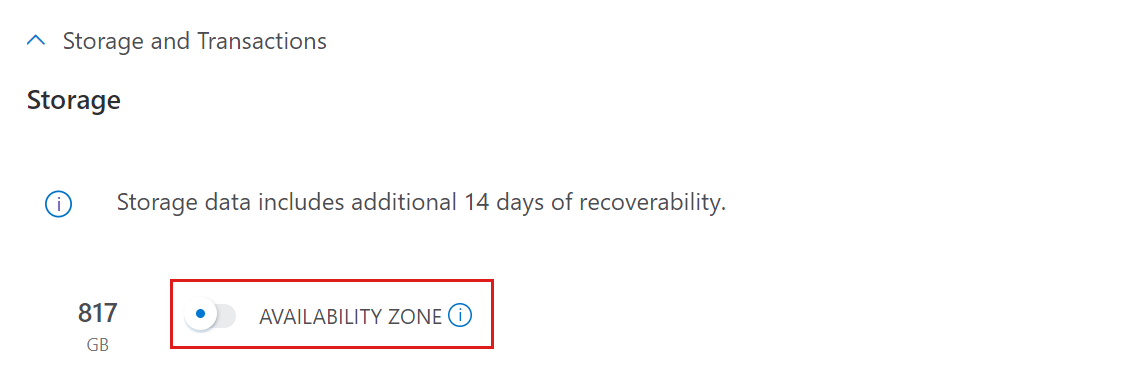
Speicher und Transaktionen
Die Speicherkomponente ist die persistente Ebene, auf der alle Daten komprimiert und als Standard LRS oder als Standard ZRS abgerechnet werden. Der Speicher wird basierend auf der Gesammelten Datenmenge, den gesamten Aufbewahrungstagen und der geschätzten Datenkomprimierung berechnet.
So erhalten Sie eine Schätzung für Speicher und Transaktionen:
- Wenn Sie Unterstützung für die Verfügbarkeitszone benötigen, aktivieren Sie DIE VERFÜGBARKEITSZONE. Wenn sie aktiviert ist, wird der Speicher als ZRS bereitgestellt. Andernfalls wird Speicher als LRS bereitgestellt.
Netzwerk
Diese Komponente wird mithilfe des Bandbreitendiensts konfiguriert.
So erhalten Sie eine Bandbreitendienstschätzung:
- Scrollen zum Anfang der Seite
- Geben Sie im Suchfeld "Bandbreite" ein.
- Auswählen des Bandbreitenprodukt-Widgets
- Scrollen Sie nach unten zur Bandbreitenkomponente der Schätzung.
- Auswählen eines Datenübertragungstyps
- Auswählen eines Quellbereichs
- Auswählen einer Zielregion
- Geben Sie die geschätzte Menge ausgehender Daten in GB ein.
Hinweis
Wählen Sie dieselbe Region aus, in der Protokolle generiert werden, um regionsübergreifende Kosten zu vermeiden und die Latenz zu reduzieren. Es gibt keine Kosten für die Datenübertragung zwischen Azure-Diensten, die in derselben Region bereitgestellt werden.
Azure Data Explorer-Markup
Das Azure Data Explorer-Markup wird für die Premium-Supportoption berechnet, die mit Ihren Datenaufnahme- und Modulclustern bereitgestellt wird. Es wird basierend auf der Anzahl der Modul-vCPUs im Cluster abgerechnet und wird für Dev-Cluster nicht in Rechnung gestellt. Ihre Kosten ändern sich basierend auf der Anzahl der Stunden, Tage oder Monate, die in der Modulinstanzkomponente konfiguriert sind. Wählen Sie optional einen Sparoptionenplan aus. Weitere Informationen finden Sie unter Azure Data Explorer-Preise – Häufig gestellte Fragen .For more information, see Azure Data Explorer pricing - FAQ.
Unterstützung
Wählen Sie einen Supportplan aus:
Entwickler: Wählen Sie diese Option aus, wenn Sie Azure Data Explorer in einer Nichtproduktionsumgebung oder für Testversionen und Auswertungen konfigurieren. Weitere Informationen finden Sie auf der Seite "Azure-Support: Entwickler" .
Standard: Wählen Sie diese Option aus, wenn Sie azure Data Explorer konfigurieren, wenn Sie eine minimale geschäftliche kritische Abhängigkeit benötigen. Weitere Informationen finden Sie auf der Seite "Azure Support: Standard ".
Professional Direct: Wählen Sie diese Option aus, wenn Sie eine erhebliche geschäftskritische Nutzung von Azure Data Explorer benötigen. Weitere Informationen finden Sie auf der Seite "Azure Support: Professional Direct ".
Was mit Ihrer Schätzung zu tun ist
- Exportieren der Schätzung nach Excel
- Speichern der Schätzung für zukünftige Referenz
- Teilen Sie die Schätzung – Anmeldung ist erforderlich.