Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisiert werden, um auf neue Funktionen in der Datenwissenschaft, Echtzeitanalysen und Berichterstellung zuzugreifen.
Azure Data Factory ist der Datenintegrations- und ETL-Dienst Microsoft in der Cloud. Dieses Dokument enthält Anleitungen für DataOps in Data Factory. Es ist nicht als vollständiges Tutorial für CI/CD, Git oder DevOps vorgesehen. Stattdessen finden Sie die Anleitung des Data Factory-Teams zum Erreichen von DataOps im Dienst mit Verweisen auf detaillierte Implementierungslinks für bewährte Methoden der Data Factory-Bereitstellung, Factory-Verwaltung und Governance. Am Ende dieses Artikels befindet sich ein Ressourcenabschnitt mit Links zu Tutorials.
Was ist DataOps?
DataOps ist ein Prozess, den Datenorganisationen für die kollaborative Datenverwaltung betreiben, um Entscheidungsträgern einen schnelleren Nutzen zu bieten.
Gartner bietet diese klare Definition von DataOps:
DataOps ist eine kollaborative Datenverwaltungspraxis, die sich auf die Verbesserung der Kommunikation, Integration und Automatisierung von Datenflüssen zwischen Datenmanagern und Datenverbrauchern in einer Organisation konzentriert. Das Ziel von DataOps ist es, durch die Erstellung einer vorhersagbaren Übermittlung und Änderungsverwaltung von Daten, Datenmodellen und verwandten Artefakten einen schnelleren Nutzen zu erzielen. DataOps verwendet Technologie zur Automatisierung von Entwurf, Bereitstellung und Verwaltung der Datenübermittlung mit entsprechenden Governanceebenen und verwendet Metadaten, um die Benutzerfreundlichkeit und den Wert von Daten in einer dynamischen Umgebung zu verbessern.
Wie erreichen Sie DataOps in Azure Data Factory?
Azure Data Factory bietet Datentechnikern ein visuell basiertes Datenpipelineparadigma zum einfachen Erstellen von Cloud-Skalierungsdatenintegrations- und ETL-Projekten. Die Data Factory basiert auf nativen Integrationen mit ausgereiften Versionskontrolltools wie GitHub und Azure DevOps sowie auf dem umfassenderen Azure Ökosystem, um viele integrierte Features bereitzustellen, um DataOps zu vereinfachen, die umfangreiche Zusammenarbeits-, Governance- und Artefaktbeziehungen umfassen.
Wenn Sie Ihre eigenen GitHub- oder Azure DevOps-Repositories in die Datenfabrik integrieren, bietet der Dienst intuitive integrierte Benutzeroberflächen-Optionen für allgemeine Befehle, z. B. Commits, Speichern von Artefakten und Versionsverwaltung. Der Dienst bietet auch die Möglichkeit, bewährte Methoden zum Einchecken von CI/CD und Code bereitzustellen, um die Integrität Ihrer Produktionsumgebung zu schützen.
„Code“ in Azure Data Factory
Alle Artefakte in Azure Data Factory, unabhängig davon, ob es sich um Pipelines, verknüpfte Dienste, Trigger usw. handelt, verfügen über entsprechende "Code"-Darstellungen in JSON hinter der visuellen UI-Integration. Diese Artefakte entsprechen den Standards der Azure Resource Manager Vorlagen. Sie finden den Code, indem Sie auf das Klammersymbol oben rechts auf dem Canvas klicken. JSON-„Beispielcode“ würde wie folgt aussehen:


Livemodus und Git-Versionskontrolle
Jede Factory verfügt über eine einzelne Quelle der Wahrheit: Pipelines, verknüpfte Dienste und Triggerdefinitionen, die im Dienst gespeichert sind. Diese Quelle der Wahrheit ist, was die Pipelineausführungen ausführen und was das Verhalten von Triggern bestimmt. Wenn Sie sich im Livemodus befinden, ändern Sie bei jeder Veröffentlichung direkt die einzelne Quelle der Wahrheit. Die folgende Abbildung zeigt, wie die Schaltfläche Alle veröffentlichen im Livemodus aussieht.

Der Livemodus kann für einzelne Personen, die an Nebenprojekten arbeiten, praktisch sein, da Entwickler die unmittelbaren Auswirkungen ihrer Codeänderungen sehen können. Von der Verwendung für ein Team von Entwicklern, die an Arbeitsprojekten auf Produktionsebene arbeiten, wird aber abgeraten. Zu den Gefahren gehören Fat-Finger-Fehler, versehentliches Löschen kritischer Ressourcen, Veröffentlichung von nicht getestetem Code usw., um nur einige zu nennen. Wenn Sie an unternehmenskritischen Projekten und Plattformen arbeiten, sollten Sie ein Git-Repository einbinden und den Git-Modus in Data Factory verwenden, um den Entwicklungsprozess zu optimieren. Versionskontrolle und Gated-Check-In-Funktionen des Git-Modus helfen Ihnen dabei, die meisten, wenn nicht alle Unfälle zu verhindern, die mit der direkten Arbeit im Livemodus verbunden sind.
Hinweis
Im Git-Modus wird die Schaltfläche Veröffentlichen oder Alle veröffentlichen durch Speichern oder Alle speichern ersetzt, und Ihre Änderungen werden an Ihre eigenen Branches committet (die Livecodebasen werden nicht direkt geändert).
Das Einrichten von GitHub und der Azure DevOps-Integration
In Azure Data Factory wird dringend empfohlen, Ihr Repository entweder in GitHub oder Azure DevOps zu speichern. Der Dienst unterstützt beide Methoden vollständig, und die Wahl des zu verwendenden Repositorys hängt von Ihren individuellen Organisationsstandards ab. Es gibt zwei Methoden zum Einrichten eines neuen Repositorys oder zum Herstellen einer Verbindung mit einem vorhandenen Repository: verwenden sie das Azure Portal oder erstellen über die benutzeroberfläche von Azure Data Factory Studio
Erstellen einer Factory über das Azure-Portal
Wenn Sie eine neue Datenfactory aus dem Azure-Portal erstellen, ist das Standard-Git-Repository Azure DevOps. Sie können auch GitHub als Repository auswählen und Ihre Repositoryeinstellungen konfigurieren.
Wählen Sie im Azure-Portal den Repositorytyp aus und geben Sie die Namen des Repositories und der Verzweigung ein, um eine neue Factory nativ in Git zu integrieren.

Erzwingen der Verwendung von Git mit Azure Policy in Ihrer Organisation
Die Verwendung von Git in Ihren Azure Data Factory Projekten ist eine dringend empfohlene bewährte Methode. Auch wenn Sie keinen vollständigen CI/CD-Prozess implementieren, ermöglicht die Git-Integration mit ADF das Speichern Ihrer Ressourcenartefakte in Ihrer eigenen Sandboxumgebung (Git-Branch), in der Sie Ihre Änderungen unabhängig von den restlichen Factory-Branches testen können. Sie können use Azure Policy verwenden, um die Verwendung von Git in der Fabrik Ihrer Organisation zu erzwingen.
Azure Data Factory Studio
Nachdem Sie Ihre Datenfactory erstellt haben, können Sie auch über das Azure Data Factory Studio eine Verbindung mit Ihrem Repository herstellen. Auf der Registerkarte Verwalten wird die Option zum Konfigurieren Ihres Repositorys und der Repositoryeinstellungen angezeigt.

Durch einen geführten Prozess werden Sie durch eine Reihe von Schritten geleitet, die Ihnen beim einfachen Konfigurieren und Herstellen einer Verbindung mit dem Repository Ihrer Wahl helfen. Nach der vollständigen Einrichtung können Sie mit der Zusammenarbeit beginnen und Ihre Ressourcen in Ihrem Repository speichern.

Continuous Integration und Continuous Delivery (CI/CD)
CI/CD ist ein Paradigma der Codeentwicklung, bei dem Änderungen überprüft und getestet werden, während sie sich durch verschiedene Phasen bewegen – Entwicklung, Test, Staging usw. Nachdem sie in jeder Phase überprüft und getestet wurden, werden sie schließlich in Livecodebasen in einer Produktionsumgebung veröffentlicht.
Continuous Integration (CI) ist die Praxis des automatischen Testens und Überprüfens bei jeder Änderung, die ein Entwickler an Ihrer Codebasis vornimmt. Continuous Delivery (CD) bedeutet, dass die Änderungen nach erfolgreichem Continuous Integration-Test kontinuierlich in die nächste Phase gebracht werden.
Wie kurz zuvor erläutert, liegt "Code" in Azure Data Factory in der Form von Azure Resource Manager Vorlage JSON vor. Daher umfassen die Änderungen, die durch den CI/CD-Prozess (Continuous Integration/Delivery) erfolgen, Ergänzungen, Löschungen und Bearbeitungen von JSON-Blobs.
Pipeline wird in Azure Data Factory ausgeführt
Bevor wir über CI/CD in Azure Data Factory sprechen, müssen wir zuerst darüber sprechen, wie der Dienst eine Pipeline ausführt. Bevor Data Factory eine Pipeline ausführt, werden folgende Schritte ausgeführt:
- Die neueste veröffentlichte Definition der Pipeline und der zugehörigen Ressourcen wird abgerufen, wie beispielsweise Datensätze, verknüpfte Dienste usw.
- Diese werden in Aktionen kompiliert; wenn Data Factory sie kürzlich ausgeführt hat, ruft es die Aktionen aus zwischengespeicherten Kompilierungen ab.
- Die Pipeline wird ausgeführt.
Das Ausführen der Pipeline umfasst die folgenden Schritte:
- Der Dienst übernimmt die Momentaufnahme der Pipelinedefinition.
- Während der gesamten Pipelinedauer ändern sich die Definitionen nicht.
- Auch wenn Ihre Pipelines lange ausgeführt werden, bleiben sie von nachfolgenden Änderungen, die nach dem Start vorgenommen wurden, unbetroffen. Wenn Sie während der Ausführung Änderungen am verknüpften Dienst, an Pipelines usw. veröffentlichen, wirken sich diese nicht auf laufende Ausführungen aus.
- Wenn Sie Änderungen veröffentlichen, verwenden nachfolgende Ausführungen, die nach der Veröffentlichung gestartet wurden, die aktualisierten Definitionen.
Veröffentlichen in Azure Data Factory
Unabhängig davon, ob Sie Pipelines mit Azure Releasepipeline bereitstellen, um die Veröffentlichung zu automatisieren, oder ob Sie die Bereitstellung manuell mit Resource Manager-Vorlagen durchführen, erfolgt die Veröffentlichung im Hintergrund durch eine Reihe von Erstellungs-/Aktualisierungsvorgängen an Datensätzen, verknüpften Diensten, Pipelines und Triggern für jedes der Artefakte. Der Effekt ist identisch mit dem direkten Ausführen der zugrunde liegenden Rest-API-Aufrufe.
Einige Dinge ergeben sich aus den Aktionen hier:
- Alle diese API-Aufrufe sind synchron, was bedeutet, dass der Aufruf nur zurückgegeben wird, wenn die Veröffentlichung erfolgreich ist/fehlschlägt. Für das Artefakt gibt es keinen Zustand der teilweisen Bereitstellung.
- API-Aufrufe sind weitgehend sequenziell. Wir versuchen, die Aufrufe zu parallelisieren, während die referenziellen Abhängigkeiten der Artefakte beibehalten werden. Die Reihenfolge der Bereitstellungen ist wie folgt: verknüpfter Dienst –> Dataset/Integration Runtime –> Pipeline –> Trigger. Diese Reihenfolge stellt sicher, dass abhängige Artefakte ordnungsgemäß auf ihre Abhängigkeiten verweisen können. Pipelines sind beispielsweise von Datasets abhängig, sodass Data Factory sie nach Datasets bereitstellt.
- Die Bereitstellung von verknüpften Diensten, Datasets usw. ist unabhängig von den Pipelines. Es gibt Situationen, in denen Data Factory verknüpfte Dienste aktualisiert, bevor eine Pipeline aktualisiert wird. Über diese Situation wird im Abschnitt Wann sollte ein Trigger gestoppt werden? eingegangen.
- Die Bereitstellung löscht keine Artefakte aus den Factorys. Sie müssen explizit Lösch-APIs für jeden Artefakttyp (Pipeline, Dataset, verknüpfter Dienst usw.) aufrufen, um eine Factory zu bereinigen. Beachten Sie als Beispiel das Beispielskript nach der Bereitstellung aus Azure Data Factory.
- Auch wenn Sie keine Pipeline, kein Dataset oder keinen verknüpften Dienst verändert haben, wird dennoch ein Aufruf der Schnellupdate-API für die Factory aufgerufen.
Veröffentlichen von Triggern
- Trigger haben Zustände: gestartet oder gestoppt.
- Sie können keine Änderungen an einem Trigger im Modus gestartet vornehmen. Sie müssen einen Trigger stoppen, bevor Sie Änderungen veröffentlichen.
- Sie können die API zum Erstellen oder Aktualisieren von Triggern für einen Trigger im Modus gestartet aufrufen.
- Wenn sich die Nutzdaten ändern, schlägt die API fehl.
- Wenn die Nutzdaten unverändert bleiben, ist die API erfolgreich.
- Dieses Verhalten hat tiefgreifende Auswirkungen darauf, wann ein Trigger gestoppt werden soll.
Wann sollte ein Trigger gestoppt werden?
Wenn es um die Bereitstellung in einer Produktions-Data Factory geht und Livetrigger andauernd Pipelineausführungen starten, stellt sich die Frage ob sie gestoppt werden sollten.
Die kurze Antwort lautet, dass Sie nur in den folgenden wenigen Szenarien erwägen sollten, den Trigger zu stoppen:
- Sie müssen den Trigger stoppen, wenn Sie die Triggerdefinitionen aktualisieren, einschließlich Feldern wie Enddatum, Häufigkeit und Pipelinezuordnung.
- Es wird empfohlen, den Trigger zu stoppen, wenn Sie die Datasets oder verknüpften Dienste aktualisieren, auf die in einer Livepipeline verwiesen wird. Wenn Sie beispielsweise die Anmeldeinformationen für SQL Server aktualisieren.
- Sie können den Trigger stoppen, wenn die zugeordnete Pipeline Fehler auslöst, fehlschlägt und Ihre Server belastet.
Dies sind die wenigen Punkte, die beim Stoppen von Triggern zu berücksichtigen sind:
- Wie im Abschnitt Pipelineausführungen in Azure Data Factory erklärt wird, wenn ein Trigger eine Pipeline-Ausführung startet, wird eine Momentaufnahme der Pipeline-, Dataset-, Integrationslaufzeit- und verknüpften Dienstdefinitionen erstellt. Wenn die Pipeline ausgeführt wird, bevor die Änderungen im Backend übernommen werden, startet der Trigger einen Lauf mit der alten Version. In den meisten Fällen sollte das kein Problem sein.
- Wie im Abschnitt Veröffentlichen von Triggern erläutert. Wenn sich ein Trigger im Status gestartet befindet, kann er nicht aktualisiert werden. Wenn Sie also Details zur Triggerdefinition ändern müssen, stoppen Sie den Trigger, bevor Sie die Änderungen veröffentlichen.
- Wie im Abschnitt Publishing in Azure Data Factory erläutert, werden Änderungen an den Datasets oder verknüpften Diensten vor Pipelineänderungen veröffentlicht. Um sicherzustellen, dass die Pipelineausführung die richtigen Anmeldeinformationen verwendet und mit den richtigen Servern kommuniziert, wird empfohlen, auch den zugeordneten Trigger zu stoppen.
Vorbereiten von „Code“-Änderungen
Es wird empfohlen, diese bewährten Methoden für die Pull Requests zu befolgen.
- Jeder Entwickler sollte an seinen eigenen einzelnen Branches arbeiten und letzten Endes Pull Requests für den Mainbranch des Repositorys erstellen. Weitere Informationen zu Pullanforderungen finden Sie in GitHub und DevOps.
- Wenn Gatekeeper die Pull Requests genehmigen und die Änderungen im Mainbranch zusammenführen, kann der CI/CD-Prozess gestartet werden. Es gibt zwei vorgeschlagene Methoden, um Änderungen in allen Umgebungen zu fördern: automatisiert und manuell.
- Sobald Sie bereit sind, CI/CD-Pipelines zu starten, können Sie dies im Allgemeinen mit Azure Pipeline Release oder Bereitstellungen bestimmter einzelner Pipelines mithilfe dieses open source Hilfsprogramms von Azure Player durchführen.
Automatisierte Bereitstellung von Änderungen
Um automatisierte Bereitstellungen zu unterstützen, empfehlen wir die Verwendung des npm-Pakets Azure Data Factory Utilities. Mithilfe des npm-Pakets können Sie alle Ressourcen in einer Pipeline überprüfen und die ARM-Vorlagen für den Benutzer generieren.
Informationen zu den ersten Schritten mit dem npm-Paket Azure Data Factory Dienstprogramme finden Sie unter Automatisierte Veröffentlichung für kontinuierliche Integration und Bereitstellung.
Manuelle Bereitstellung von Änderungen
Nachdem Sie Ihren Branch wieder mit dem Hauptbranch für die Zusammenarbeit in Ihrem Git-Repository zusammengeführt haben, können Sie Ihre Änderungen manuell im Azure Data Factory-Livedienst veröffentlichen. Der Dienst bietet mit der Option Veröffentlichung deaktivieren (aus ADF Studio) die Benutzeroberflächensteuerung für die Veröffentlichung aus Nichtentwicklungsfactorys.
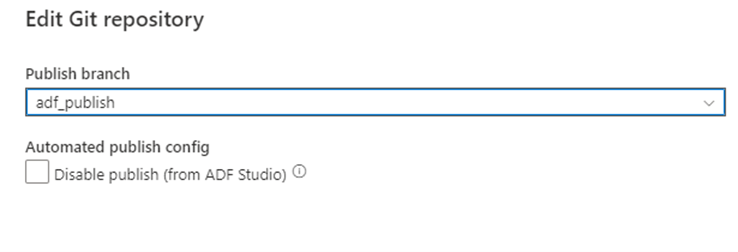
Selektive Bereitstellung
Die selektive Bereitstellung basiert auf einem Feature von GitHub und Azure DevOps, das als cherry Pick bezeichnet wird. Mit diesem Feature können Sie nur bestimmte Änderungen bereitstellen und andere ausschließen. Beispielsweise hat ein Entwickler Änderungen an mehreren Pipelines vorgenommen, aber für die heutige Bereitstellung möchten wir möglicherweise nur Änderungen an einer Pipeline bereitstellen.
Folgen Sie den Lernprogrammen von Azure DevOps und GitHub, um die für die benötigte Pipeline relevanten Commits auszuwählen. Stellen Sie sicher, dass alle Änderungen, einschließlich relevanter Änderungen an den Triggern, verknüpften Diensten und Abhängigkeiten, die der Pipeline zugeordnet sind, ausgewählt wurden.
Nachdem Sie die Änderungen selektiv ausgewählt und mit der Haupt-Zusammenarbeitspipeline zusammengeführt haben, können Sie den CI/CD-Prozess für die vorgeschlagenen Änderungen starten. Weitere Informationen zu Hotfixes, zur Auswahl oder Verwendung externer Frameworks für die selektive Bereitstellung finden Sie im Abschnitt Automatisierte Tests dieses Artikels.
Komponententest
Komponententests sind ein wichtiger Teil des Prozesses der Entwicklung neuer Pipelines oder der Bearbeitung vorhandener Data Factory-Artefakte, der sich auf das Testen von Codekomponenten konzentriert. Data Factory erlaubt Einzeltests sowohl auf Pipeline- als auch auf Datenfluss-Ebene mithilfe der Pipeline-Debugging-Funktion.

Beim Entwickeln von Datenflüssen können Sie Einblicke in jede einzelne Transformation und Codeänderung gewinnen, indem Sie die Daten-Previewfunktion verwenden, um Komponententests durchzuführen, bevor Sie Ihre Änderungen in der Produktion bereitstellen.

Der Dienst bietet Live- und interaktives Feedback zu Ihren Pipelineaktivitäten in der Benutzeroberfläche beim Debuggen und Komponententests in Azure Data Factory.
Automatisiertes Testen
Es stehen mehrere Tools für automatisierte Tests zur Verfügung, die Sie mit Azure Data Factory verwenden können. Da der Dienst Objekte im Dienst als JSON-Entitäten speichert, kann es praktisch sein, das Open-Source-.NET Komponententestframework NUnit mit Visual Studio zu verwenden. In diesem Beitrag Einrichtung automatisierter Testeinrichtungen für Azure Data Factory finden Sie eine ausführliche Erläuterung zur Einrichtung einer automatisierten Komponententestumgebung für Ihre Data Factory. (Besonderer Dank geht an Richard Swinbank für die Erlaubnis, diesen Blog zu nutzen.)
Kunden können auch TEST-Pipelines mit PowerShell oder AZ CLI als Teil des CI/CD-Prozesses für die Schritte vor und nach der Bereitstellung ausführen.
Eine wichtige Stärke der Data Factory liegt in der Parametrisierung von Datasets. Mit diesem Feature können Kunden dieselben Pipelines mit unterschiedlichen Datasets ausführen, um sicherzustellen, dass ihre neue Entwicklung alle Quell- und Zielanforderungen erfüllt.
Andere CI/CD-Frameworks für Azure Data Factory
Wie bereits beschrieben, ist die integrierte Git-Integration nativ über die Azure Data Factory-Benutzeroberfläche verfügbar, einschließlich Zusammenführung, Verzweigung, Vergleich und Veröffentlichung. Es gibt jedoch andere nützliche CI/CD-Frameworks, die in der Azure Community beliebt sind, die alternative Mechanismen bieten, um ähnliche Funktionen bereitzustellen. Die Azure Data Factory Git-Methodik basiert auf ARM-Vorlagen, während Frameworks wie ADFTools von Kamil Nowinski stattdessen auf einzelne JSON-Artefakte von Ihrer Factory basieren. Data Engineers, die in Azure DevOps versiert sind und lieber in dieser Umgebung arbeiten möchten (im Gegensatz zum ARM-basierten UI-Ansatz, den der Dienst sofort anbietet), können feststellen, dass dieses Framework gut für sie und für allgemeine Szenarien wie Teilbereitstellungen geeignet ist. Dieses Framework kann auch die Behandlung von Triggern beim Einsatz in Umgebungen mit laufenden Triggerzuständen vereinfachen.
Datenverwaltung in Azure Data Factory
Ein wichtiger Aspekt effektiver DataOps ist die Datenverwaltung. Bei ETL-Tools für die Datenintegration kann das Bereitstellen von Datenherkunfts- und Artefaktbeziehungen einem Dateningenieur wichtige Informationen liefern, um die Auswirkungen von nachgeschalteten Änderungen zu verstehen. Data Factory bietet integrierte Ansichten verwandter Artefakte, die Ihre Factory-Implementierung bilden.

Die systemeigene Integration in Microsoft Purview bietet außerdem Linien-, Auswirkungsanalysen und Datenkataloge.
Microsoft Purview bietet eine einheitliche Datengovernancelösung, mit der Sie Ihre lokalen, multicloud- und Software as a Service-Daten (SaaS) verwalten und steuern können. So können Sie mühelos eine ganzheitliche, aktuelle Übersicht über Ihre Datenlandschaft mit automatisierter Datenermittlung, Klassifizierung vertraulicher Daten und End-to-End-Datenherkunft erstellen. Diese Features ermöglichen Datenverbrauchern den Zugriff auf eine nützliche, vertrauenswürdige Datenverwaltung.

Mit der nativen Integration in Ihren Purview Data Catalog ermöglicht Data Factory eine einfache Suche und Ermittlung von Datenressourcen, die in Ihren Datenintegrationspipelines über die gesamte Bandbreite des Datenbestands Ihrer Organisation hinweg verwendet werden können.

Sie können die Hauptsuchleiste aus dem Azure Data Factory Studio verwenden, um Datenressourcen in Ihrem Purview-Katalog zu finden.
