Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisiert werden, um auf neue Funktionen in der Datenwissenschaft, Echtzeitanalysen und Berichterstellung zuzugreifen.
Eine Schemaabweichung liegt vor, wenn Ihre Quellen Metadaten häufig ändern. Felder, Spalten und Typen können bei laufendem Betrieb hinzugefügt, entfernt oder geändert werden. Ohne Vorkehrungen bei Schemaabweichungen wird Ihr Datenfluss anfällig für Änderungen an vorgelagerten Datenquellen. Wenn sich eingehende Spalten und Felder ändern, treten bei typischen ETL-Mustern Fehler auf, da sie dazu neigen, an diesen Quellennamen gebunden zu sein.
Um vor Schemaabweichungen zu schützen, ist es wichtig, die Einrichtungen in einem Datenflusstool zu haben, damit Sie als Data Engineer:
- Definieren von Quellen mit änderbaren Feldnamen, Datentypen, Werte und Größen
- Definieren von Transformationsparametern, die anstelle von hartcodierten Feldern und Werten mit Datenmustern arbeiten können
- Definieren von Ausdrücken, die Muster verstehen, um sie mit Eingangsfeldern abzugleichen, anstatt benannte Felder zu verwenden
Azure Data Factory unterstützt systemeigene Schemas, die sich von Ausführung zu Ausführung ändern, sodass Sie generische Datentransformationslogik erstellen können, ohne dass Die Datenflüsse neu kompiliert werden müssen.
Sie müssen eine architektonische Entscheidung in Ihrem Datenfluss treffen, um die Schemaabweichung in Ihrem Fluss zu akzeptieren. Wenn Sie dies tun, können Sie Schutz gegen Schemaänderungen aus den Quellen bieten. Allerdings verlieren Sie die frühzeitige Bindung Ihrer Spalten und Datentypen im gesamten Datenfluss. Azure Data Factory behandelt Schema-Drift-Flüsse als spät gebundene Flüsse. Wenn Sie also Ihre Transformationen erstellen, stehen Ihnen die driftenden Spaltennamen in den Schemaansichten während des gesamten Flusses nicht zur Verfügung.
Dieses Video bietet eine Einführung in einige komplexe Lösungen, die Sie einfach in Azure Data Factory- oder Synapse Analytics-Pipelines mit der Funktion schema drift erstellen können. In diesem Beispiel erstellen wir basierend auf flexiblen Datenbankschemas wiederverwendbare Muster:
Schemaabweichung in der Quelle
Spalten, die aus Ihrer Quelldefinition in Ihren Datenfluss kommen, werden als "driftend" bezeichnet, wenn sie in Ihrer Quellprojektion nicht vorhanden sind. Ihre Quellprojektion können Sie sich auf der Registerkarte „Projektion“ der Quelltransformation ansehen. Wenn Sie ein Dataset als Quelle auswählen, übernimmt der Dienst automatisch das Schema aus dem Dataset und erstellt eine Projektion aus dieser Schemadefinition des Datasets.
In einer Quellentransformation wird die Schemaabweichung als das Lesen von Spalten definiert, die in Ihrem Datasetschema nicht definiert sind. Um Schemaabweichung zu ermöglichen, wählen Sie in Ihrer Quellentransformation Allow Schema Drift (Schemaabweichung zulassen) aus.
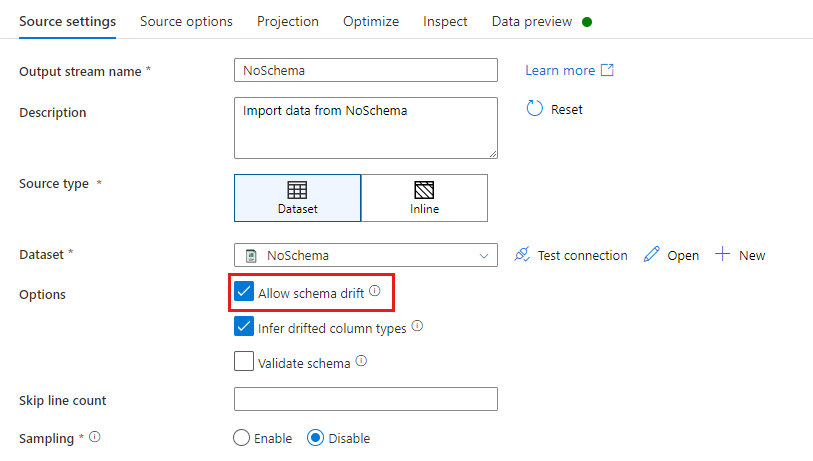
Bei aktivierter Schemaabweichung werden während der Ausführung alle eingehenden Felder aus Ihrer Quelle gelesen und durch den gesamten Datenfluss zur Senke geleitet. Alle neu erkannten Spalten (bekannt als driftete Spalten) werden standardmäßig mit dem Datentyp „String“ angezeigt. Wenn Sie möchten, dass der Datenfluss automatisch Datentypen abweichender Spalten ableiten kann, aktivieren Sie in Ihren Quelleinstellungen die Option Infer drifted column types (Abweichende Spaltentypen ableiten).
Schemaabweichung in Senke
Bei einer Senkentransformation erfolgt eine Schemabweichung, wenn Sie zusätzliche Spalten zusätzlich zu dem schreiben, was im Datenschema der Senke definiert ist. Um die Schemaabweichung zu ermöglichen, wählen Sie in Ihrer Senkentransformation Allow Schema Drift (Schemaabweichung zulassen) aus.
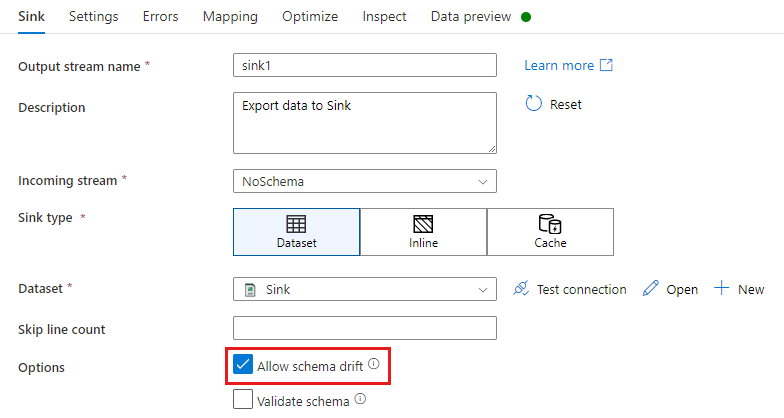
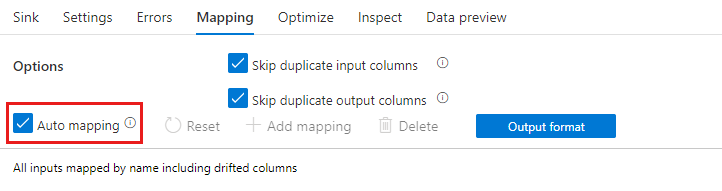
Wenn die Schemaabweichung aktiviert ist, stellen Sie sicher, dass der Schieberegler Auto-Mapping auf der Registerkarte „Mapping“ aktiviert ist. Wenn dieser Schieberegler eingeschaltet ist, werden alle eingehenden Spalten in Ihr Ziel geschrieben. Andernfalls müssen Sie die regelbasierte Zuordnung verwenden, um abweichende Spalten zu schreiben.
Transformieren abweichender Spalten
Wenn Ihr Datenfluss Spaltenabweichungen aufweist, können Sie in Ihren Transformationen mit den folgenden Methoden auf diese zugreifen:
- Verwenden der Ausdrücke
byPositionundbyName, um auf eine Spalte explizit über Name oder Positionsnummer zu verweisen - Füge ein Spaltenmuster in einer abgeleiteten Spalten- oder Aggregattransformation hinzu, um mit einer beliebigen Kombination von Name, Datenstrom, Position, Ursprung oder Typ übereinzustimmen.
- Hinzufügen einer regelbasierten Zuordnung in einer Auswahl- oder Senkentransformation, um abweichende Spalten über ein Muster mit Spaltenaliasen abzugleichen
Weitere Informationen zum Implementieren von Spaltenmustern finden Sie unter Spaltenmuster im Zuordnungsdatenfluss.
Schnellaktion zum Zuordnen abweichender Spalten
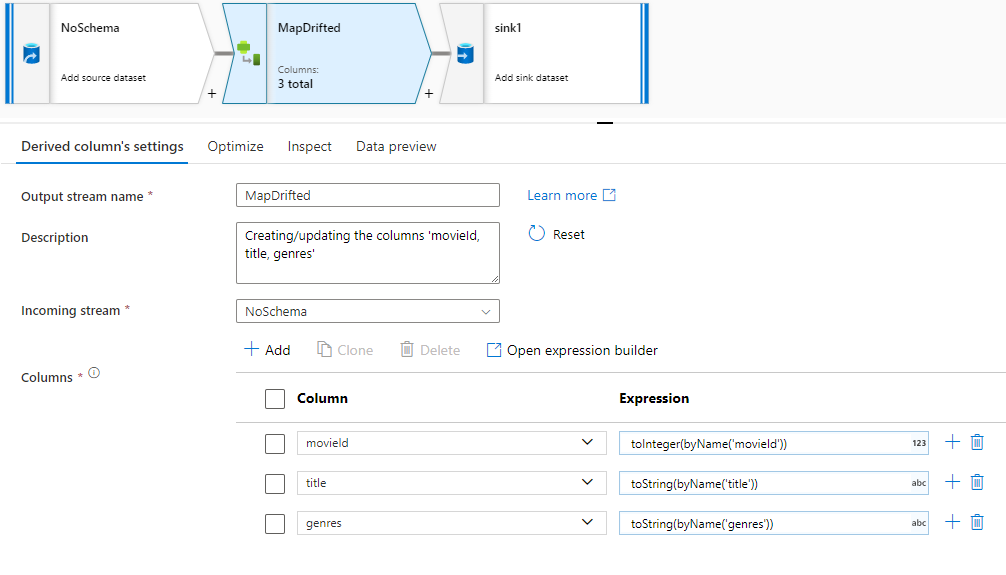
Um explizit auf abweichende Spalten zu verweisen, können Sie in kürzester Zeit Zuordnungen für diese Spalten über eine Schnellaktion zur Datenvorschau erzeugen. Nach Aktivierung des Debugmodus wechseln Sie zur Registerkarte „Datenvorschau“ und klicken auf Aktualisieren, um eine Datenvorschau abzurufen. Wenn Data Factory feststellt, dass abweichende Spalten vorhanden sind, können Sie auf Map Drifted (Abweichende zuordnen) klicken und eine abgeleitete Spalte erzeugen, mit der Sie in nachgelagerten Schemaansichten auf alle abweichenden Spalten verweisen können.
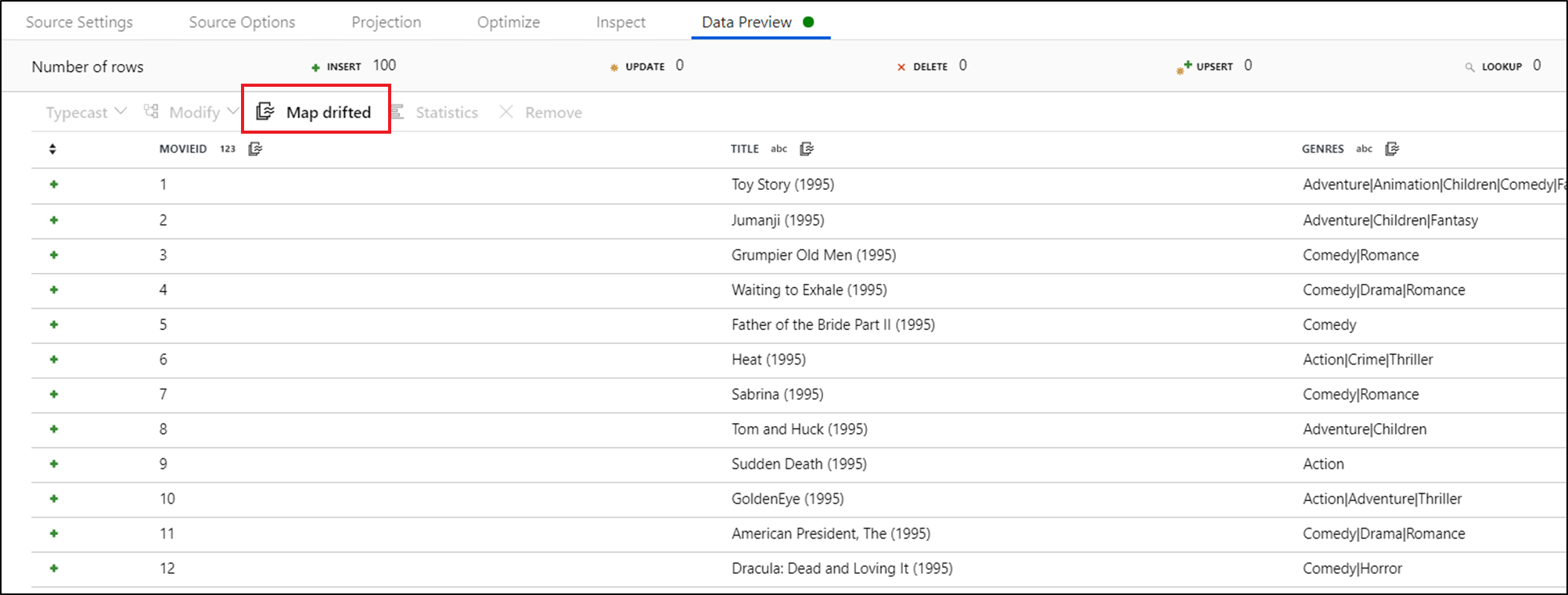
In der generierten Transformation des Typs „Abgeleitete Spalten“ werden alle abweichenden Spalten dem erkannten Namen und Datentyp zugeordnet. In der obigen Datenvorschau wird die Spalte „movieId“ als ganze Zahl erkannt. Nach Klicken auf Map Drifted (Abweichende zuordnen) wird movieId in der abgeleiteten Spalte als toInteger(byName('movieId')) definiert und bei nachgelagerten Transformationen in Schemaansichten berücksichtigt.
Zugehöriger Inhalt
In der Data Flow Expression Language finden Sie zusätzliche Möglichkeiten für Spaltenmuster und Schemaabweichungen, einschließlich "byName" und "byPosition".