Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Mit der Power Query-Aktivität können Sie Power Query-Mashups erstellen und ausführen, um so Data Wrangling im großen Stil in einer Data Factory-Pipeline vorzunehmen. Sie können ein neues Power Query-Mashup über die Menüoption „Neue Ressourcen“ erstellen oder durch Hinzufügen einer Power Query-Aktivität zur Pipeline.
Sie können direkt im Power Query-Mashup-Editor arbeiten, um eine interaktive Datenuntersuchung vorzunehmen und dann Ihre Arbeit zu speichern. Sobald der Vorgang beendet ist, können Sie die Power Query-Aktivität übernehmen und zu einer Pipeline hinzufügen. Azure Data Factory nimmt automatisch eine horizontale Hochskalierung vor und operationalisiert das Data Wrangling mithilfe der Spark-Umgebung für Datenflüsse in Azure Data Factory.
Erstellen einer Power Query-Aktivität mit der Benutzeroberfläche
Führen Sie die folgenden Schritte aus, um eine Power Query-Aktivität in einer Pipeline zu verwenden:
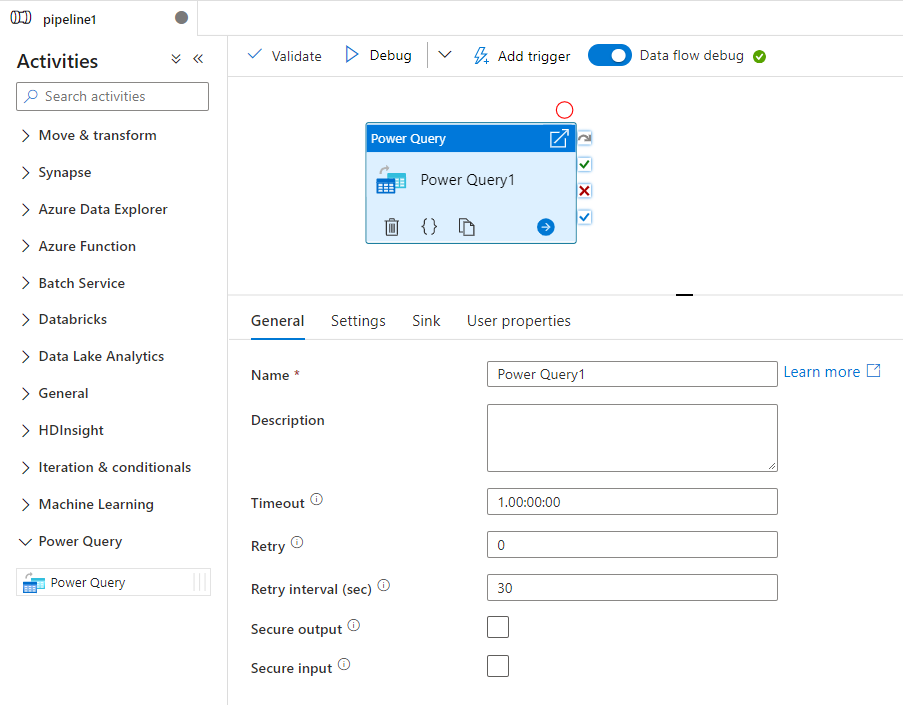
Suchen Sie im Bereich mit den Pipelineaktivitäten nach Power Query, und ziehen Sie eine Power Query-Aktivität in den Pipelinebereich.
Wählen Sie auf der Canvas die neue Power Query-Aktivität aus, sofern sie noch nicht ausgewählt ist, und wählen Sie anschließend die Registerkarte Einstellungen aus, um die Details zu bearbeiten.
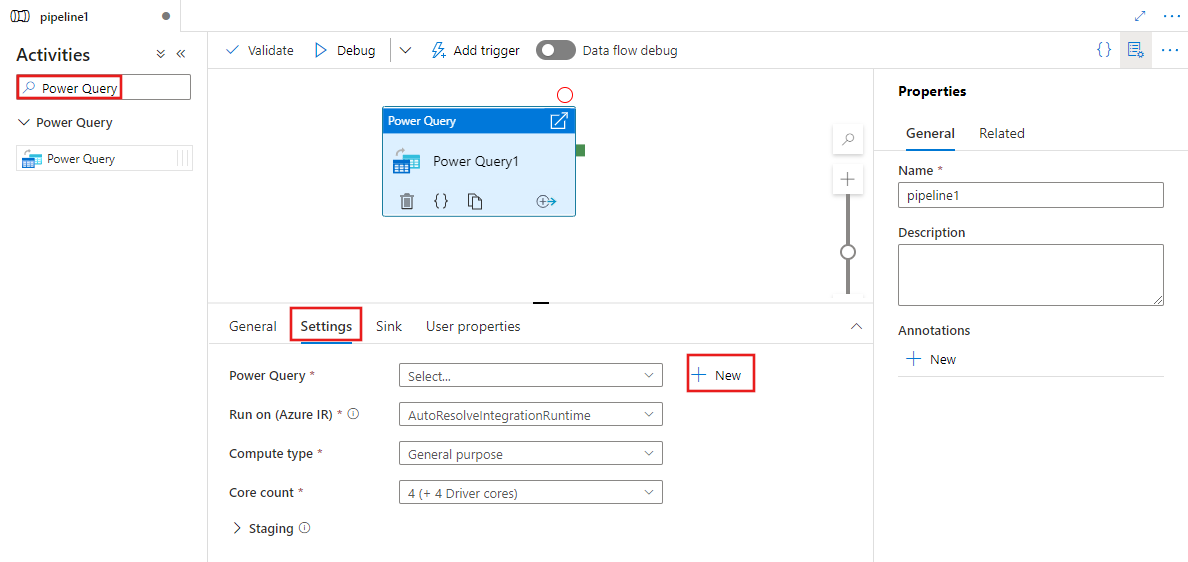
Wählen Sie eine vorhandene Power Query aus, und wählen Sie „Öffnen“ aus, oder wählen Sie die Schaltfläche „Neu“ aus, um eine neue Power Query zu erstellen, und öffnen Sie den Power Query-Editor.
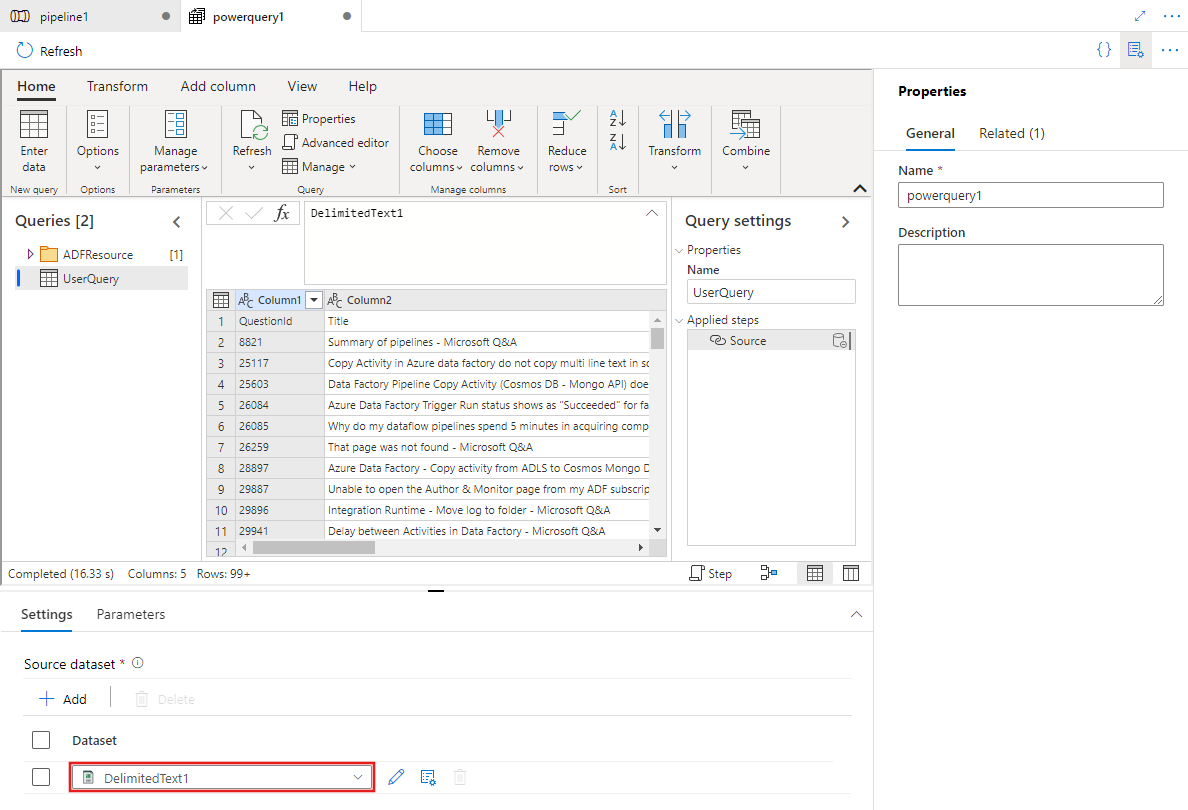
Wählen Sie ein vorhandenes Dataset aus, oder wählen Sie „Neu“ aus, um ein neues Dataset zu definieren. Verwenden Sie die umfassenden Features von Power Query direkt in der Pipeline-Bearbeitungserfahrung, um das Dataset nach Ihrem Bedarf anzupassen. Sie können mehrere Abfragen aus mehreren Datasets im Editor hinzufügen und anschließend verwenden.
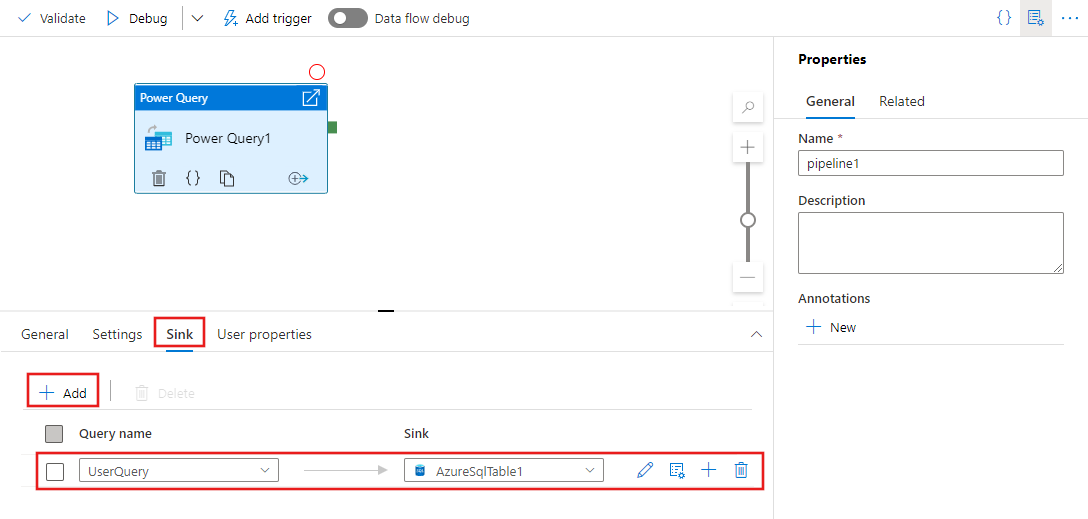
Nachdem Sie im vorherigen Schritt eine oder mehrere Power Queries definiert haben, können Sie auch Senkenspeicherorte für einen/alle/keine davon festlegen, und zwar auf der Registerkarte „Senke“ für die Power Query-Aktivität.
Sie können auch die Ausgabe Ihrer Power Query-Aktivität als Eingaben für andere Aktivitäten verwenden. Hier finden Sie ein Beispiel einer „ForEach“-Aktivität, die auf die Ausgabe der zuvor definierten Power Query für die Element-Eigenschaft verweist. Die Elemente unterstützen dynamischen Inhalte, in denen Sie auf alle Ausgaben der Power Query verweisen können, die als Eingabe verwendet werden.
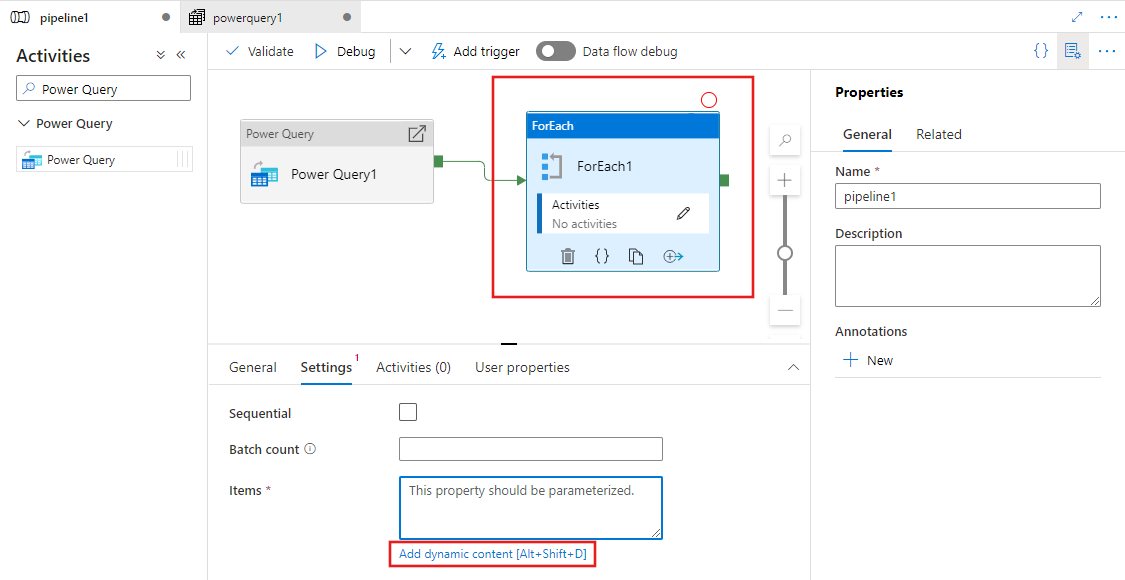
Alle Aktivitätsausgaben werden angezeigt und können verwendet werden, wenn Sie Ihre dynamischen Inhalte definieren, indem Sie sie im Bereich Pipeline-Ausdrucksgenerator auswählen.
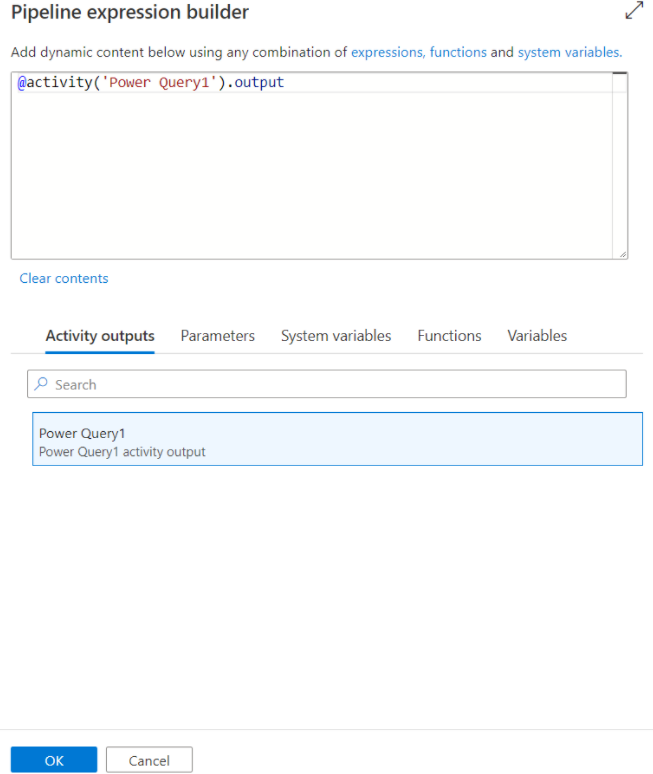
Übersetzung in Datenflussskript
Zur Skalierung für die Power Query-Aktivität übersetzt Azure Data Factory das M-Skript in ein Datenflussskript, sodass Sie Power Query im großen Stil mithilfe der Spark-Umgebung für Azure Data Factory-Datenflüsse ausführen können. Erstellen Sie den Wranglingdatenfluss mithilfe der codefreien Datenvorbereitung. Die Liste der verfügbaren Funktionen finden Sie unter Transformationsfunktionen.
Einstellungen
- Power Query: Wählen Sie eine vorhandene Power Query-Instanz für die Ausführung aus, oder erstellen Sie eine neue.
- Ausführen auf Azure IR: Wählen Sie eine vorhandene Azure Integration Runtime aus, um die Compute-Umgebung für Power Query zu definieren, oder erstellen Sie eine neue.
- Computetyp: Wenn Sie die Standard-Integration Runtime für die automatische Auflösung auswählen, können Sie den Computetyp auswählen, der auf das Spark-Clustercomputing für die Power Query-Ausführung angewandt werden soll.
- Anzahl der Kerne: Wenn Sie die Standard-Integration Runtime für die automatische Auflösung auswählen, können Sie die Anzahl der Kerne auswählen, die auf das Spark-Clustercomputing für die Power Query-Ausführung angewandt werden soll.
Senke
Wählen Sie das Dataset aus, das Sie als Ausgangspunkt Ihrer transformierten Daten verwenden möchten, nachdem das Power Query M-Skript in Spark ausgeführt wurde. Weitere Informationen zum Konfigurieren von Senken finden Sie in der Dokumentation zu Datenflusssenken.
Sie haben die Möglichkeit, die Ausgabe an mehrere Ziele zu senken. Klicken Sie auf die Plus-Schaltfläche (+), um weitere Senken zu Ihrer Abfrage hinzuzufügen. Sie können auch jede einzelne Abfrageausgabe ihrer Wrangling-Power Query-Aktivität an verschiedene Ziele leiten.
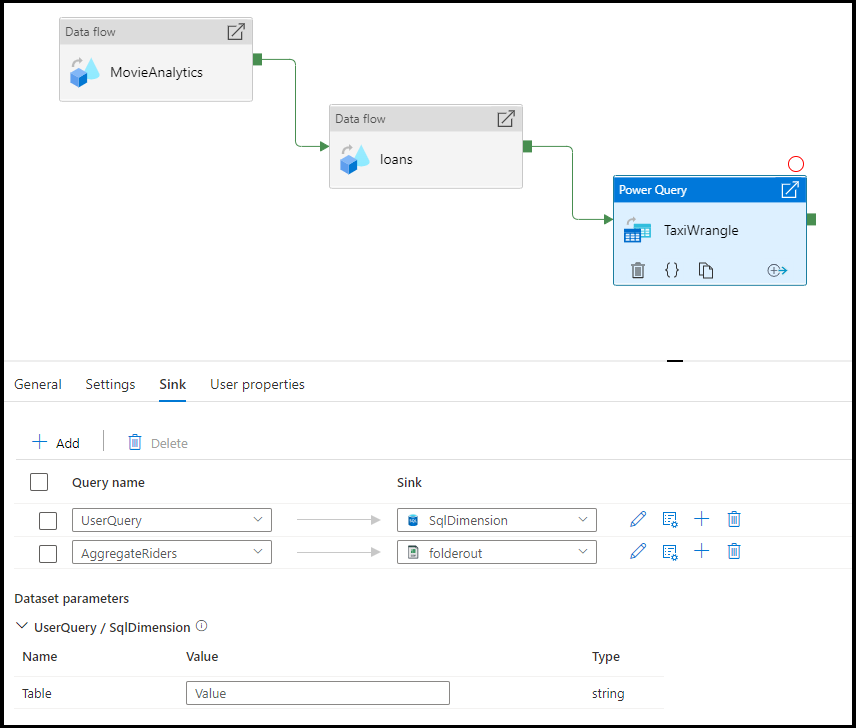
Zuordnung
Auf der Registerkarte „Zuordnung“ können Sie die Spaltenzuordnung von der Ausgabe Ihrer Power Query-Aktivität zum Zielschema der ausgewählten Senke konfigurieren. Weitere Informationen zur Spaltenzuordnung finden Sie in der Dokumentation zur Zuordnung von Datenflusssenken.
Zugehöriger Inhalt
Erfahren Sie mehr über Data Wrangling-Konzepte mithilfe von Power Query in Azure Data Factory.