Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisiert werden, um auf neue Funktionen in der Datenwissenschaft, Echtzeitanalysen und Berichterstellung zuzugreifen.
Manchmal möchten Sie eine umfangreiche Datenmigration von einem Data Lake oder Enterprise Data Warehouse (EDW) nach Azure durchführen. Manchmal möchten Sie große Datenmengen aus verschiedenen Quellen in Azure aufnehmen, um Big Data-Analysen durchzuführen. In jedem Fall ist es wichtig, eine optimale Leistung und Skalierbarkeit zu erzielen.
Azure Data Factory und Azure Synapse Analytics Pipelines bieten einen Mechanismus zum Aufnehmen von Daten mit den folgenden Vorteilen:
- Verarbeitet große Datenmengen
- Ist äußerst leistungsfähig
- Ist kostenwirksam
Diese Vorteile eignen sich hervorragend für Dateningenieure, die skalierbare und leistungsstarke Pipelines zur Datenerfassung erstellen möchten.
Nach Lesen dieses Artikels können Sie die folgenden Fragen beantworten:
- Welche Leistung und Skalierbarkeit kann ich mit der Kopieraktivität in Datenmigrations- und Datenerfassungsszenarios erzielen?
- Welche Schritte muss ich ausführen, um die Leistung der Kopieraktivität zu optimieren?
- Welche Leistungsoptimierungen kann ich für eine einzelne Kopieraktivitätsausführung nutzen?
- Welche anderen externen Faktoren müssen bei der Optimierung der Kopierleistung berücksichtigt werden?
Note
Falls Sie mit dem grundlegenden Konzept der Kopieraktivität nicht vertraut sind, finden Sie weitere Informationen unter Kopieraktivität – Übersicht, bevor Sie sich mit diesem Artikel beschäftigen.
Mit Azure Data Factory- und Synapse-Pipelines erreichbare Kopierleistung und Skalierbarkeit
Azure Data Factory- und Synapse-Pipelines bieten eine serverlose Architektur, die Parallelität auf verschiedenen Ebenen zulässt.
Diese Architektur ermöglicht es Ihnen, Pipelines zu entwickeln, die den Datenverschiebungsdurchsatz für Ihre Umgebung maximieren. Diese Pipelines nutzen die folgenden Ressourcen vollständig:
- Netzwerkbandbreite zwischen den Quell- und Zieldatenspeichern
- Eingabe/Ausgabe-Vorgänge pro Sekunde (IOPS) und Bandbreite des Quell- oder Zieldatenspeichers
Diese volle Auslastung bedeutet, dass Sie den Gesamtdurchsatz durch Messung des Mindestdurchsatzes einschätzen können, der mit den folgenden Ressourcen zur Verfügung steht:
- Quelldatenspeicher
- Zieldatenspeicher
- Netzwerkbandbreite zwischen den Quell- und Zieldatenspeichern
Die folgende Tabelle zeigt die Berechnung der Dauer der Datenverschiebung. Die Dauer in jeder Zelle wird basierend auf einer bestimmten Netzwerk- und Datenspeicherbandbreite und einer bestimmten Größe der Datennutzlast berechnet.
Note
Die unten angegebene Dauer soll die erreichbare Leistung in einer umfassenden Datenintegrationslösung darstellen. Dazu wird mindestens eine der Leistungsoptimierungstechniken verwendet, die unter Features für die Leistungsoptimierung von Kopiervorgängen beschrieben sind, einschließlich der Verwendung von ForEach zum Partitionieren und Erzeugen mehrerer gleichzeitiger Kopieraktivitäten. Es wird empfohlen, die Schritte unter Schritte zur Optimierung der Leistung zu befolgen, um die Kopierleistung für Ihr spezifisches Dataset und Ihre Systemkonfiguration zu optimieren. Sie sollten die in den Leistungsoptimierungstests ermittelten Zahlen für die Planung der Produktionsbereitstellung, die Kapazitätsplanung und die Abrechnungsprognose verwenden.
| Datengröße/ bandwidth |
50 MBit/s | 100 MBit/s | 500 MBit/s | 1 GBit/s | 5 GBit/s | 10 Gbit/s | 50 GBit/s |
|---|---|---|---|---|---|---|---|
| 1 GB | 2,7 Min. | 1,4 Min. | 0,3 Min. | 0,1 Min. | 0,03 Min. | 0,01 Min. | 0,0 Min. |
| 10 GB | 27,3 Min. | 13,7 Min. | 2,7 Min. | 1,3 Min. | 0,3 Min. | 0,1 Min. | 0,03 Min. |
| 100 GB | 4,6 Stunden | 2.3 Stunden | 0,5 Stunden | 0,2 Stunden | 0.05 Uhr | 0.02 Uhr | 0,0 h |
| 1 TB | 46.6 Stunden | 23.3 Stunden | 4.7 Stunden | 2.3 Stunden | 0,5 Stunden | 0,2 Stunden | 0.05 Uhr |
| 10 TB | 19,4 Tage | 9,7 Tage | 1,9 Tage | 0,9 Tage | 0,2 Tage | 0,1 Tage | 0,02 Tage |
| 100 TB | 194.2 Tage | 97,1 Tage | 19,4 Tage | 9,7 Tage | 1,9 Tage | 1 Tag | 0,2 Tage |
| 1 PB | 64,7 Monate | 32,4 Monate | 6,5 Monate | 3,2 mo | 0.6 Monate | 0,3 Monate | 0,06 Monate |
| 10 PB | 647,3 Monate | 323.6 Monate | 64,7 Monate | 31.6 Monate | 6,5 Monate | 3,2 mo | 0.6 Monate |
Die Kopieraktivität kann auf verschiedenen Ebenen skaliert werden:
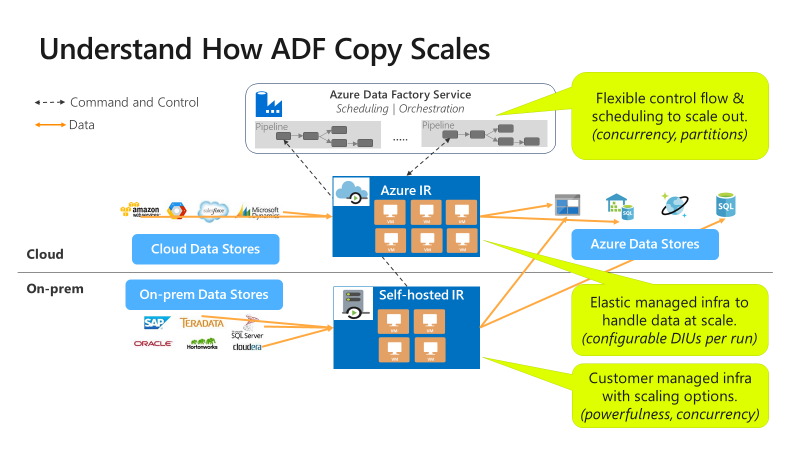
Mit der Ablaufsteuerung können mehrere Kopieraktivitäten parallel gestartet werden (z. B. per For Each-Schleife).
Eine einzelne Kopieraktivität kann skalierbare Computeressourcen nutzen.
- Wenn Sie Azure Integrationslaufzeit (IR) verwenden, können Sie bis zu 256 Datenintegrationseinheiten (DATA Integration Units, DIUs) für jede Kopieraktivität auf serverlose Weise angeben.
- Bei der Verwendung einer selbst gehosteten IR können Sie einen der folgenden Ansätze verfolgen:
- Skalieren Sie den Computer manuell hoch.
- Skalieren Sie auf mehrere Computer ( bis zu 4 Knoten) auf, und eine einzelne Kopieraktivität partitioniert ihre Dateigruppe über alle Knoten.
Eine einzelne Kopieraktivität liest aus dem und schreibt in den Datenspeicher mithilfe mehrerer Threads, die parallel arbeiten.
Schritte zur Optimierung der Leistung
Führen Sie die folgenden Schritte aus, um die Leistung Ihres Diensts mit der Kopieraktivität zu verbessern:
Wählen Sie ein Testdataset aus, und legen Sie eine Baseline fest.
Testen Sie Ihre Pipeline mit der Kopieraktivität während der Entwicklung mit repräsentativen Beispieldaten. Das von Ihnen gewählte Dataset sollte Ihre typischen Datenmuster zusammen mit den folgenden Attributen darstellen:
- Ordnerstruktur
- Dateimuster
- Datenschema
Und Ihr Dataset sollte groß genug sein, um die Kopierleistung auszuwerten. Bei einer geeigneten Größe dauert es mindestens 10 Minuten, bis die Kopieraktivität abgeschlossen ist. Sammeln Sie Ausführungsdetails und Leistungsmerkmale bei der Überwachung der Kopieraktivität.
So maximieren Sie die Leistung einer einzelnen Kopieraktivität:
Wir empfehlen, dass Sie zunächst die Leistung mit einer einzelnen Kopieraktivität maximieren.
Wenn die Kopieraktivität auf einer Integrationslaufzeit von Azure ausgeführt wird:
Beginnen Sie mit den Standardwerten für Datenintegrationseinheiten (DIU) und Paralleles Kopieren.
Bei Ausführung der Kopieraktivität in einer selbstgehosteten Integration Runtime:
Es wird empfohlen, IR auf einem dedizierten Computer zu hosten. Der Computer sollte vom Server, auf dem sich der Datenspeicher befindet, getrennt sein. Beginnen Sie mit den Standardwerten für Paralleles Kopieren, und verwenden Sie einen einzelnen Knoten für die selbstgehostete Integration Runtime.
Führen Sie einen Leistungstestlauf durch. Notieren Sie sich die erzielte Leistung. Schließen Sie die tatsächlich verwendeten Werte ein, z. B. DIUs und parallele Kopien. Einzelheiten zum Erfassen von Testlaufergebnissen und zu verwendeten Leistungseinstellungen finden Sie unter Überwachen der Kopieraktivität. Erfahren Sie, wie Sie Probleme bei der Leistung der Kopieraktivität beheben können, um den Engpass zu identifizieren und zu beheben.
Führen Sie wiederholt Leistungstestläufe durch, gemäß der Anleitungen zur Fehlerbehebung und Anpassung. Wenn die Ausführung einzelner Kopieraktivitäten keinen besseren Durchsatz erzielen kann, überlegen Sie, ob sie den Aggregatdurchsatz maximieren möchten, indem Sie mehrere Kopien gleichzeitig ausführen. Diese Option wird im nächsten nummerierten Aufzählungspunkt erörtert.
So maximieren Sie den aggregierten Durchsatz durch paralleles Ausführen mehrerer Kopiervorgänge:
Mittlerweile haben Sie die Leistung einer einzelnen Kopieraktivität maximiert. Wenn Sie die Durchsatzobergrenzen Ihrer Umgebung noch nicht erreicht haben, können Sie mehrere Kopieraktivitäten parallel ausführen. Sie können parallel ausführen, indem Sie Ablaufsteuerungskonstrukte verwenden. Ein solches Konstrukt ist die „For Each“-Schleife. Weitere Informationen finden Sie in den folgenden Artikeln über Lösungsvorlagen:
Erweitern Sie die Konfiguration auf das gesamte Dataset.
Wenn Sie mit den Ausführungsergebnissen und mit der Leistung zufrieden sind, können Sie die Definition und die Pipeline auf Ihr gesamtes Dataset erweitern.
Problembehebung der Kopieraktivitätsleistung
Führen Sie die Schritte zur Optimierung der Leistung aus, um den Leistungstest für Ihr Szenario zu planen und durchzuführen. Erfahren Sie im Abschnitt Problembehandlung für die Leistung der Kopieraktivität, wie Sie Performanceprobleme bei jedem Kopiervorgang beheben können.
Features für die Leistungsoptimierung von Kopiervorgängen
Der Dienst bietet die folgenden Leistungsoptimierungsfeatures:
- Datenintegrationseinheiten
- Skalierbarkeit der selbstgehosteten Integration Runtime
- Parallele Kopie
- Mehrstufige Kopie
Datenintegrationseinheiten
Eine Datenintegrationseinheit (DIU) ist eine Maßeinheit, die die Leistung einer einzelnen Einheit in Azure Data Factory- und Synapse-Pipelines repräsentiert. Leistung ist eine Kombination aus CPU-, Arbeitsspeicher- und Netzwerkressourcenzuordnung. DIU gilt nur für Azure Integrationslaufzeit. DIU gilt nicht für selbst gehostete Integrationslaufzeiten. Hier erhalten Sie weitere Informationen.
Skalierbarkeit der selbstgehosteten Integration Runtime (IR)
Vielleicht möchten Sie eine zunehmende gleichzeitige Workload hosten. Oder Sie möchten vielleicht eine höhere Leistung bei Ihrer derzeitigen Workload erreichen. Sie können den Umfang der Verarbeitung durch die folgenden Ansätze erweitern:
- Sie können die selbst gehostete IR hochskalieren, indem Sie die Anzahl der gleichzeitigen Aufträge erhöhen, die auf einem Knoten ausgeführt werden können.
Das Hochskalieren funktioniert nur, wenn der Prozessor und der Arbeitsspeicher des Knotens nicht voll ausgelastet sind. - Sie können die selbst gehostete IR aufskalieren, indem Sie weitere Knoten (Computer) hinzufügen.
Weitere Informationen finden Sie unter
- Features für die Leistungsoptimierung bei Kopieraktivitäten: Skalierbarkeit der selbstgehosteten Integration Runtime (IR)
- Erstellen und Konfigurieren einer selbstgehosteten Integration Runtime: Aspekte der Skalierung
Parallele Kopie
Sie können die parallelCopies-Eigenschaft festlegen, um die Parallelität anzugeben, die für die Kopieraktivität verwendet werden soll. Betrachten Sie diese Eigenschaft als die maximale Anzahl von Threads innerhalb der Kopieraktivität. Die Threads arbeiten parallel. Die Threads lesen entweder aus Ihrer Quelle oder schreiben in Ihre Senkendatenspeicher.
Erfahren Sie mehr.
gestaffeltem Kopieren
Ein Datenkopiervorgang kann die Daten direkt an den Senkendatenspeicher senden. Alternativ können Sie Blobspeicher auch als Zwischenlagerungsspeicher verwenden. Erfahren Sie mehr.
Verwandte Inhalte
Weitere Informationen finden Sie in den anderen Artikeln zur Kopieraktivität:
- Übersicht über die Kopieraktivität
- Fehlerbehebung bei der Kopierleistung
- Features für die Leistungsoptimierung bei Kopieraktivitäten
Use Azure Data Factory, um Daten aus Ihrem Data Lake oder Data Warehouse zu Azure - Daten von Amazon S3 zu Azure Storage migrieren