Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisiert werden, um auf neue Funktionen in der Datenwissenschaft, Echtzeitanalysen und Berichterstellung zuzugreifen.
Datenflüsse sind sowohl in Azure Data Factory Pipelines als auch in Azure Synapse Analytics Pipelines verfügbar. Dieser Artikel gilt für Datenfluss-Mapping. Wenn Sie mit Transformationen noch nicht fertig sind, lesen Sie den einführungsartikel Transformieren von Daten mithilfe von Zuordnungsdatenflüssen.
Tipp
Informationen zur entsprechenden Transformation (Parse) in Dataflow Gen2 finden Sie in einer Anleitung zu Dataflow Gen2 zum Zuordnen von Datenflussbenutzern.
Verwenden Sie die Analysetransformation zum Analysieren von Textspalten in Ihren Daten, die Zeichenfolgen in Dokumentform sind. Aktuell werden die folgenden Typen eingebetteter Dokumente zur Analyse unterstützt: JSON, XML und durch Trennzeichen getrennter Text.
Konfiguration
Im Konfigurationspanel für Analysetransformation wählen Sie zuerst den Datentyp aus, der in den Spalten enthalten ist, die Sie inline analysieren möchten. Die Analysetransformation enthält auch die folgenden Konfigurationseinstellungen.

Spalte
Ähnlich wie abgeleitete Spalten und Aggregate ändert die Spalteneigenschaft entweder eine vorhandene Spalte, indem Sie sie aus der Dropdownauswahl auswählen. Sie können hier aber auch den Namen einer neuen Spalte eingeben. ADF speichert die analysierten Quelldaten in dieser Spalte. In den meisten Fällen müssen Sie eine neue Spalte definieren, die das eingehende eingebettete Dokumentzeichenfolgenfeld analysiert.
Ausdruck
Verwenden Sie den Ausdrucks-Generator zum Festlegen der Quelle für Ihre Analyse. Das Festlegen der Quelle kann so einfach sein, wie das Auswählen der Quellspalte mit den eigenständigen Daten, die Sie analysieren möchten, oder Sie können komplexe Ausdrücke zum Analysieren erstellen.
Beispielausdrücke
Quelldatenzeichenfolge:
chrome|steel|plastic- Ausdruck:
(desc1 as string, desc2 as string, desc3 as string)
- Ausdruck:
Quell-JSON-Daten:
{"ts":1409318650332,"userId":"309","sessionId":1879,"page":"NextSong","auth":"Logged In","method":"PUT","status":200,"level":"free","itemInSession":2,"registration":1384448}- Ausdruck:
(level as string, registration as long)
- Ausdruck:
Geschachtelte JSON-Quelldaten:
{"car" : {"model" : "camaro", "year" : 1989}, "color" : "white", "transmission" : "v8"}- Ausdruck:
(car as (model as string, year as integer), color as string, transmission as string)
- Ausdruck:
Quell-XML-Daten:
<Customers><Customer>122</Customer><CompanyName>Great Lakes Food Market</CompanyName></Customers>- Ausdruck:
(Customers as (Customer as integer, CompanyName as string))
- Ausdruck:
Quell-XML mit Attributdaten:
<cars><car model="camaro"><year>1989</year></car></cars>- Ausdruck:
(cars as (car as ({@model} as string, year as integer)))
- Ausdruck:
Ausdrücke mit reservierten Zeichen:
{ "best-score": { "section 1": 1234 } }- Der obige Ausdruck funktioniert nicht, da das Zeichen „-“ in
best-scoreals Subtraktionsvorgang interpretiert wird. Verwenden Sie eine Variable mit Klammernotation in diesen Fällen, um dem JSON-Modul mitzuteilen, dass der Text wörtlich interpretiert wird:var bestScore = data["best-score"]; { bestScore : { "section 1": 1234 } }
- Der obige Ausdruck funktioniert nicht, da das Zeichen „-“ in
Hinweis: Wenn beim Extrahieren von Attributen Fehler auftreten – insbesondere @model) eines komplexen Typs – können Sie dies umgehen, indem Sie den komplexen Typ in eine Zeichenfolge konvertieren, das @-Symbol entfernen, insbesondere durch „replace(toString(your_xml_string_parsed_column_name.cars.car),'@','')“, und dann die Transformationsaktivität zum Parsen von JSON verwenden.
Typ der Ausgabespalte
Hier konfigurieren Sie das Zielausgabeschema aus der Analyse, das in eine einzelne Spalte geschrieben wird. Die einfachste Möglichkeit, ein Schema für die Ausgabe der Analyse festzulegen, besteht darin, rechts oben im Ausdrucks-Generator die Schaltfläche „Typ erkennen“ auszuwählen. ADF versucht, das Schema automatisch im Zeichenfolgenfeld zu finden, das Sie analysieren, und es im Ausgabeausdruck für Sie festzulegen.
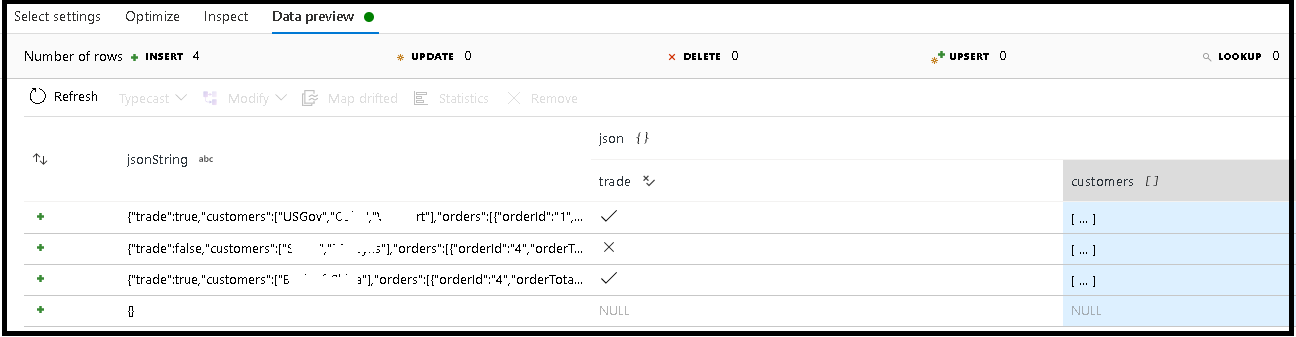
In diesem Beispiel haben wir die Analyse des eingehenden Felds "jsonString" definiert, das Nur-Text ist, aber als JSON-Struktur formatiert wurde. Wir werden die analysierten Ergebnisse als JSON in der neuen Spalte „json“ mit folgendem Schema speichern:
(trade as boolean, customers as string[])
Überprüfen Sie sowohl auf der Registerkarte „Inspektieren“ als auch in der Datenvorschau, ob Ihre Ausgabe richtig abgebildet ist.
Verwenden Sie die Aktivität „Abgeleitete Spalte“, um hierarchische Daten zu extrahieren. Das heißt, „your_complex_column_name.car.model“ befindet sich im Ausdrucksfeld.
Beispiele
source(output(
name as string,
location as string,
satellites as string[],
goods as (trade as boolean, customers as string[], orders as (orderId as string, orderTotal as double, shipped as (orderItems as (itemName as string, itemQty as string)[]))[])
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
documentForm: 'documentPerLine') ~> JsonSource
source(output(
movieId as string,
title as string,
genres as string
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false) ~> CsvSource
JsonSource derive(jsonString = toString(goods)) ~> StringifyJson
StringifyJson parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json',
documentForm: 'arrayOfDocuments') ~> ParseJson
CsvSource derive(csvString = 'Id|name|year\n\'1\'|\'test1\'|\'1999\'') ~> CsvString
CsvString parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
ParseJson select(mapColumn(
jsonString,
json
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedJson
ParseCsv select(mapColumn(
csvString,
csv
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedCsv
Datenflussskript
Syntax
Beispiele
parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json|XML|delimited',
documentForm: 'singleDocument') ~> ParseJson
parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
Zugehöriger Inhalt
- Verwenden Sie die Flatten-Transformation, um Zeilen zu Spalten umzuwandeln.
- Verwenden Sie die Transformation für abgeleitete Spalten zum Transformieren von Zeilen.