Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Mithilfe von Codeausschnitten in Zuordnungsdatenflüssen können Sie häufige Aufgaben wie die Datendeduplizierung oder die Filterung nach NULL-Werten problemlos durchführen. In diesem Artikel wird beschrieben, wie Sie diese Funktionen problemlos Ihren Pipelines hinzufügen können, indem Sie Codeausschnitte von Datenflussskripts verwenden.
Erstellen einer Pipeline
Wählen Sie Neue Pipeline aus.
Fügen Sie eine Datenflussaktivität hinzu.
Wählen Sie die Registerkarte Quelleinstellungen aus, fügen Sie eine Quelltransformation hinzu, und verbinden Sie diese dann mit einem Ihrer Datasets.
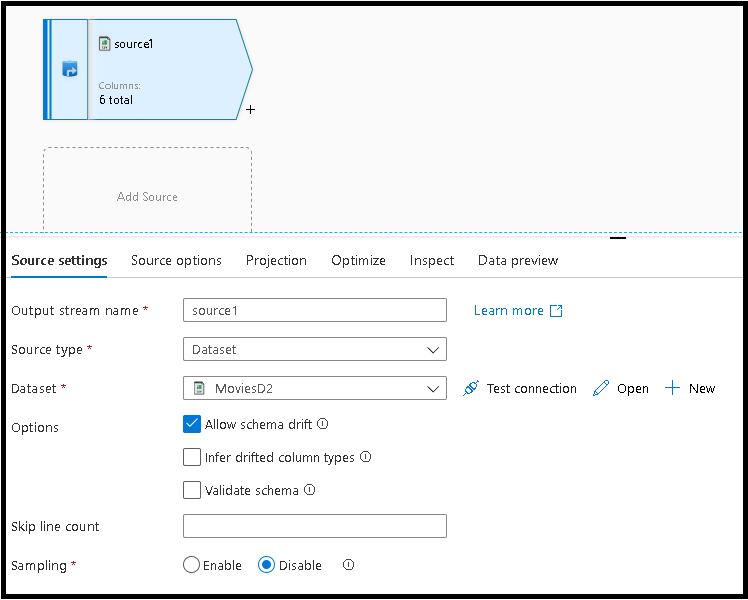
In den Codeausschnitten für das Deduplizieren und das Prüfen auf NULL-Werte werden generische Muster verwendet, die die Datendrift des Datenflussschemas nutzen. Sie können die Codeausschnitte mit jedem beliebigen Schema aus Ihrem Dataset und sogar mit Datasets verwenden, die nicht über ein vordefiniertes Schema verfügen.
Kopieren Sie im Abschnitt „Eindeutige Zeile mit allen Spalten“ im Datenflussskript (DFS) den Codeausschnitt für DistinctRows.
-
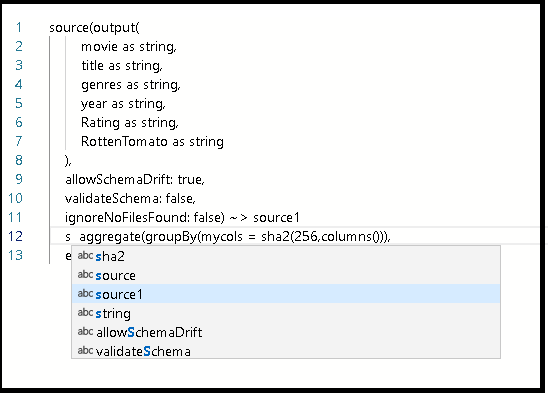
Drücken Sie nach der Definition für
source1in Ihrem Skript die EINGABETASTE, und fügen Sie den Codeausschnitt ein.Führen Sie eine der folgenden Aktionen aus:
Verbinden Sie diesen eingefügten Codeausschnitt mit der Quelltransformation, die Sie im Graphen erstellt haben, indem Sie vor dem eingefügten Code source1 eingeben.
Alternativ können Sie für die neue Transformation im Designer eine Verbindung herstellen, indem Sie über den neuen Transformationsknoten im Graphen den eingehenden Datenstrom auswählen.
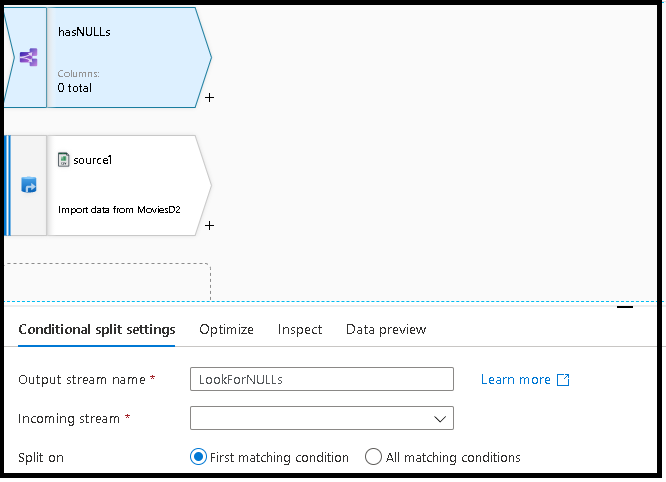
In Ihrem Datenfluss werden nun doppelte Zeilen mithilfe der Aggregattransformation aus Ihrer Quelle entfernt. Damit wird nach allen Zeilen gruppiert, indem übergreifend für alle Spaltenwerte ein allgemeiner Hash genutzt wird.
Fügen Sie einen Codeausschnitt zum Aufteilen Ihrer Daten in einen Datenstrom mit NULL-Werten und einen anderen Datenstrom ohne NULL-Werte hinzu. Gehen Sie folgendermaßen vor:
-
b. Wählen Sie im Datenfluss-Designer erneut Skript aus, und fügen Sie dann ganz unten den neuen Transformationscode unten ein. Durch diese Aktion wird das Skript mit der vorherigen Transformation verbunden, indem der Name dieser Transformation vor dem eingefügten Codeausschnitt eingefügt wird.
Ihr Datenflussgraph sollte jetzt in etwa wie folgt aussehen:
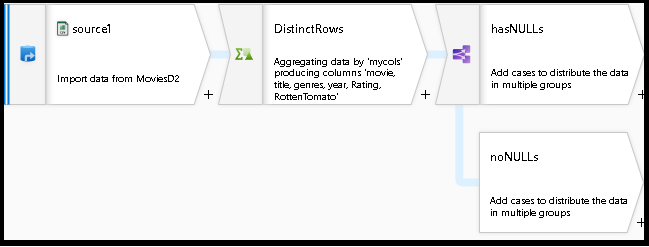
Sie haben damit einen funktionierenden Datenfluss mit generischer Deduplizierung und einer Überprüfung auf NULL-Werte erstellt, indem Sie vorhandene Codeausschnitte aus der Datenflussskript-Bibliothek in Ihren vorhandenen Entwurf eingefügt haben.
Zugehöriger Inhalt
- Erstellen Sie die restliche Datenflusslogik mithilfe von Mapping Data Flow-Transformationen.