Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Automatisiertes maschinelles Lernen (AutoML) wird in Machine Learning-Projekten zum automatisierten Trainieren, Optimieren und Modellieren mithilfe von Zielmetriken verwendet, die Sie für die Klassifizierung, Regression und Zeitreihenvorhersage angeben.
Eine Herausforderung für AutoML besteht darin, dass die Rohdaten aus einem Data Warehouse oder einer Transaktionsdatenbank möglicherweise ein riesiges Dataset von 10 GB Größe darstellen können. Da große Datasets zum Trainieren von Modellen mehr Zeit benötigen, wird empfohlen, die Datenverarbeitung vor dem Trainieren von Azure Machine Learning-Modellen zu optimieren. In diesem Tutorial erfahren Sie, wie Sie mithilfe von Azure Data Factory ein Dataset in AutoML-Dateien für ein Machine Learning-Dataset partitionieren.
Das AutoML-Projekt umfasst die folgenden drei Datenverarbeitungsszenarios:
Partitionieren von großen Datenmengen in AutoML-Dateien vor dem Trainieren von Modellen
Häufig werden Daten vor dem Trainieren von Modellen mit dem Pandas-Datenrahmen verarbeitet. Der Pandas-Datenrahmen ist für einen Datenumfang von weniger als 1 GB geeignet. Bei größeren Datenmengen wird die Verarbeitung der Daten durch den Pandas-Datenrahmen verlangsamt. Dies kann sogar zu einem Fehler wegen unzureichendem Arbeitsspeicher führen. Es wird empfohlen, für Machine Learning das Dateiformat Parquet zu verwenden, da es sich dabei um ein binäres Spaltenformat handelt.
Die Zuordnungsdatenflüsse in Data Factory sind visuell gestaltete Datentransformationen, die es Data Engineers ermöglichen, ohne das Schreiben von Code auszukommen. Mit Zuordnungsdatenflüssen können große Datenmengen effektiv verarbeitet werden, da die Pipeline horizontal hochskalierte Spark-Cluster nutzt.
Teilen des Trainings- und Testdatasets
Das Trainingsdataset wird für ein Trainingsmodell verwendet. Das Testdataset wird zum Auswerten von Modellen in einem Machine Learning-Projekt genutzt. Die Aktivität für bedingtes Teilen für Zuordnungsdatenflüsse ist für das Aufteilen in Trainingsdaten und Testdaten zuständig.
Entfernen nicht qualifizierter Daten
Angenommen, Sie möchten nicht qualifizierte Daten entfernen, wie z. B. eine Parquet-Datei ohne Zeilen. In diesem Tutorial rufen Sie die Anzahl der Zeilen mithilfe der Aggregataktivität ab. Die Zeilenanzahl stellt eine Bedingung zum Entfernen nicht qualifizierter Daten dar.
Vorbereitung
Verwenden Sie die folgende Azure SQL-Datenbanktabelle.
CREATE TABLE [dbo].[MyProducts](
[ID] [int] NULL,
[Col1] [char](124) NULL,
[Col2] [char](124) NULL,
[Col3] datetime NULL,
[Col4] int NULL
)
Konvertieren der Daten in das Parquet-Format
Mit dem folgenden Datenfluss wird eine SQL-Datenbanktabelle in das Parquet-Dateiformat konvertiert:
- Quelldataset: Transaktionstabelle aus SQL-Datenbank
- Senkendataset: Blobspeicher im Parquet-Format
Entfernen nicht qualifizierter Daten basierend auf der Zeilenanzahl
Angenommen, Sie möchten Daten mit einer Zeilenanzahl kleiner als zwei entfernen.
Rufen Sie mithilfe der Aggregataktivität die Anzahl der Zeilen ab. Verwenden Sie für Gruppiert nach die Option „Col2“ und für Aggregate die Option
count(1), um die Zeilenanzahl abzurufen.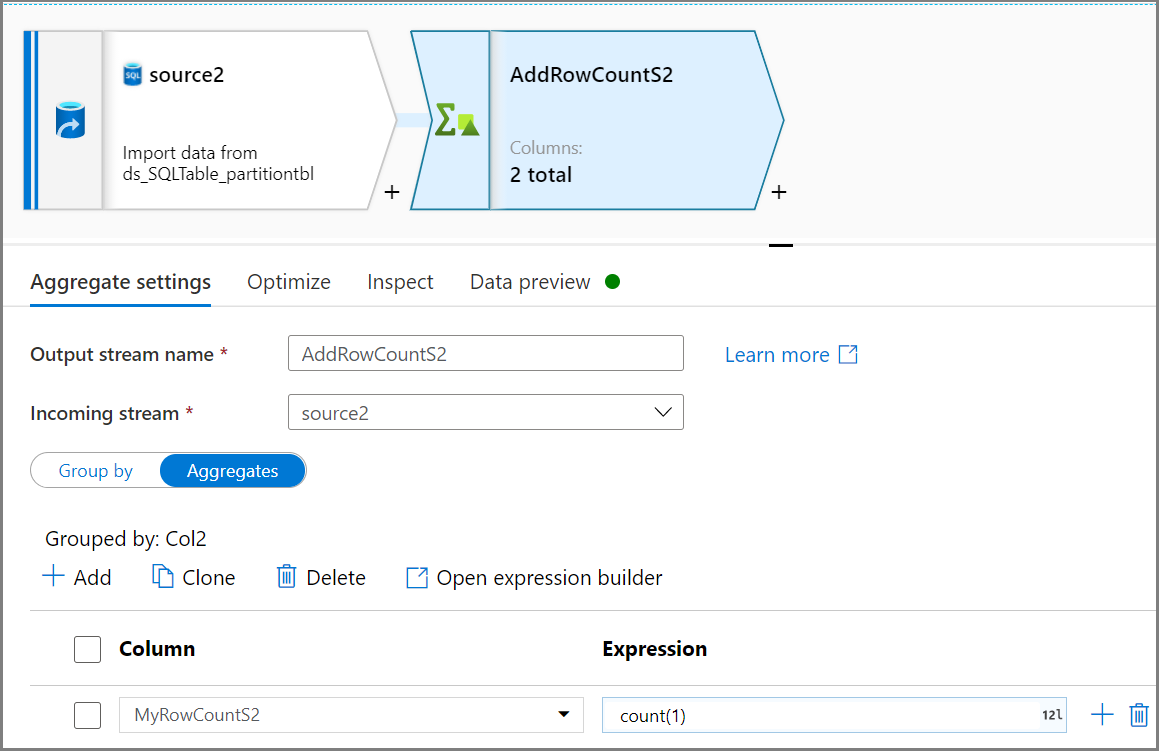
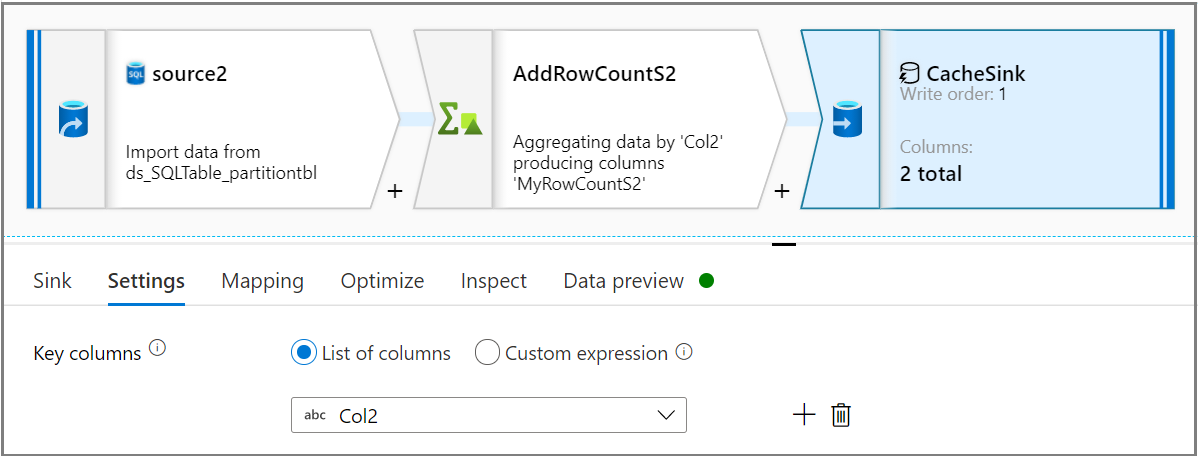
Indem Sie die Senk-Aktivität verwenden, wählen Sie den Senk-Typals Cache auf der Registerkarte Senken aus. Wählen Sie dann die gewünschte Spalte aus der Schlüsselspalten-Dropdown-Liste auf der Einstellungen-Registerkarte aus.
Fügen Sie mithilfe der Aktivität für abgeleitete Spalten dem Quelldatenstrom eine Spalte mit der Zeilenanzahl hinzu. Rufen Sie auf der Registerkarte Einstellungen der abgeleiteten Spalte mithilfe des Ausdrucks
CacheSink#lookupdie Zeilenanzahl aus CacheSink ab.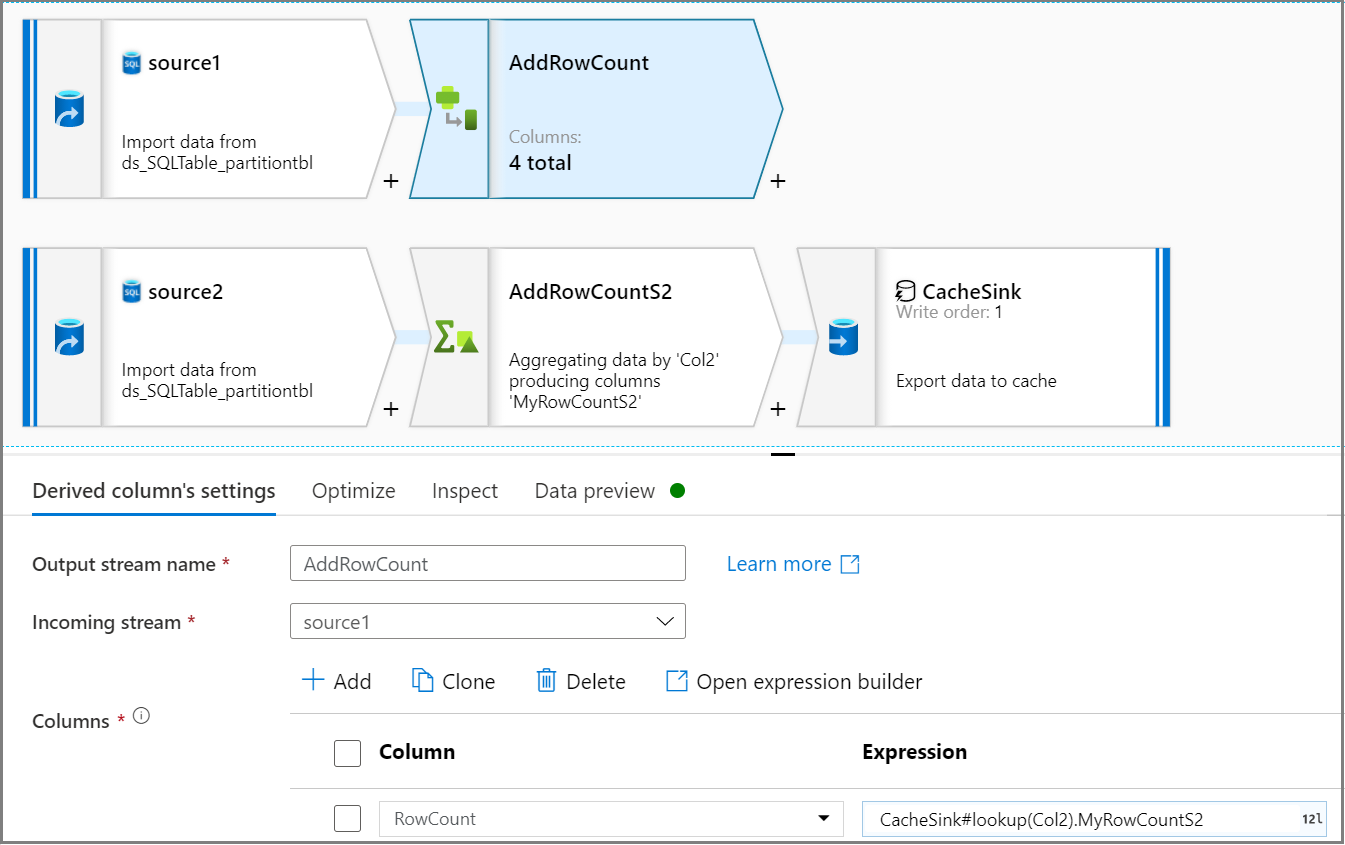
Entfernen Sie mithilfe der Aktivität für bedingtes Teilen nicht qualifizierte Daten. In diesem Beispiel basiert die Zeilenanzahl auf der Spalte „Col2“. Laut Bedingung werden Daten mit einer Zeilenanzahl kleiner als zwei entfernt: Es werden also zwei Zeilen (ID=2 und ID=7) entfernt. Sie sollten nicht qualifizierte Daten für die Datenverwaltung in einem Blobspeicher speichern.
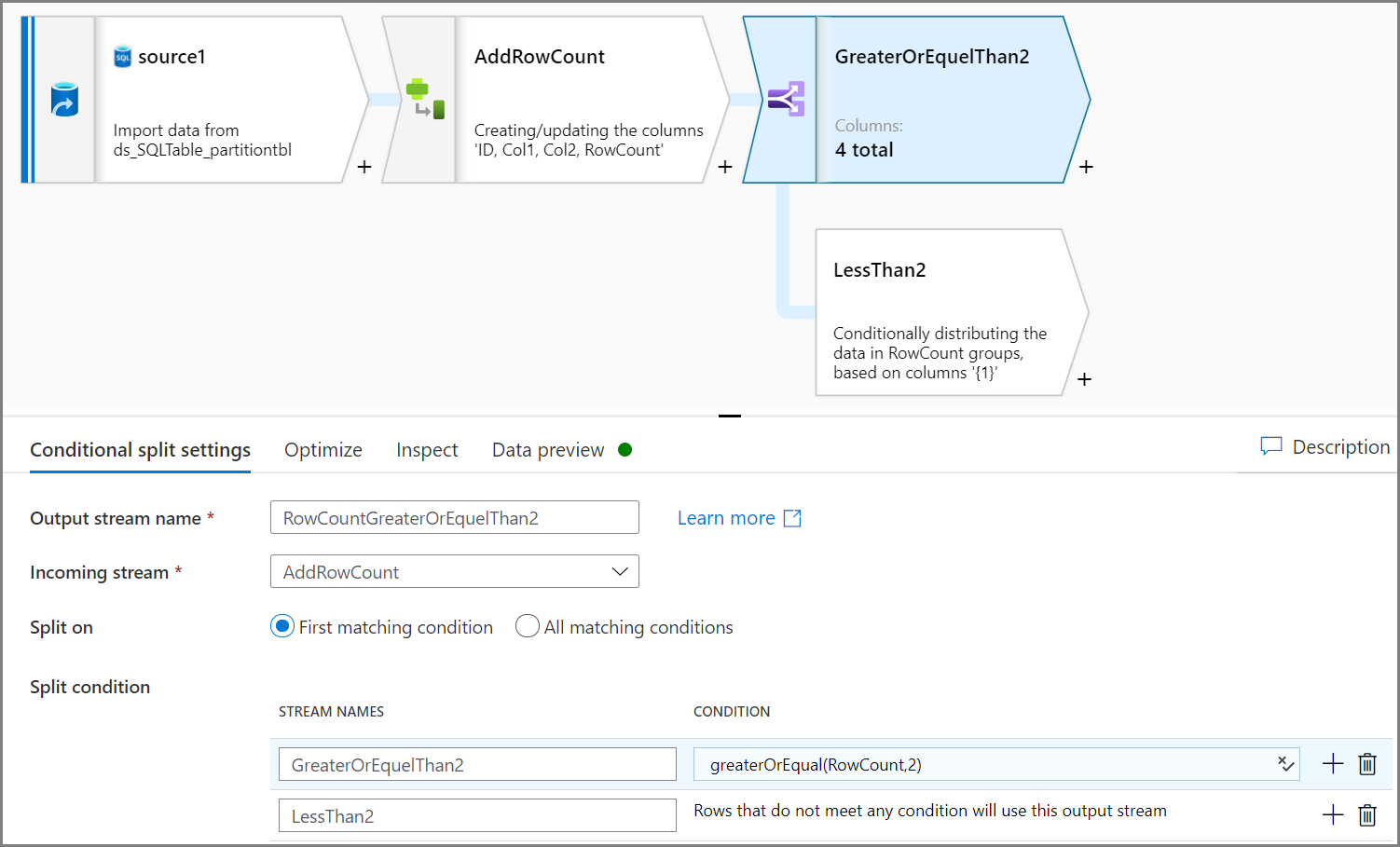
Hinweis
- Erstellen Sie eine neue Quelle, um die Zeilenanzahl der ursprünglichen Quelle später in diesem Modul abrufen zu können.
- Verwenden Sie aus Leistungsgründen CacheSink.
Teilen von Trainings- und Testdaten
Nun sollen die Trainings- und Testdaten für jede Partition geteilt werden. In diesem Beispiel rufen Sie für denselben Wert von „Col2“ die ersten beiden Zeilen als Testdaten und die übrigen Zeilen als Trainingsdaten ab.
Fügen Sie mithilfe der Fensteraktivität für jede Partition eine Spalte mit der Zeilennummer hinzu. Wählen Sie auf der Registerkarte Über eine Spalte für die Partition aus (in diesem Tutorial die Spalte „Col2“). Geben Sie auf der Registerkarte Sortieren eine Reihenfolge an (in diesem Tutorial soll anhand der ID sortiert werden). Geben Sie auf der Registerkarte Fensterspalten an, dass für jede Partition eine Spalte mit der Zeilennummer hinzugefügt wird.
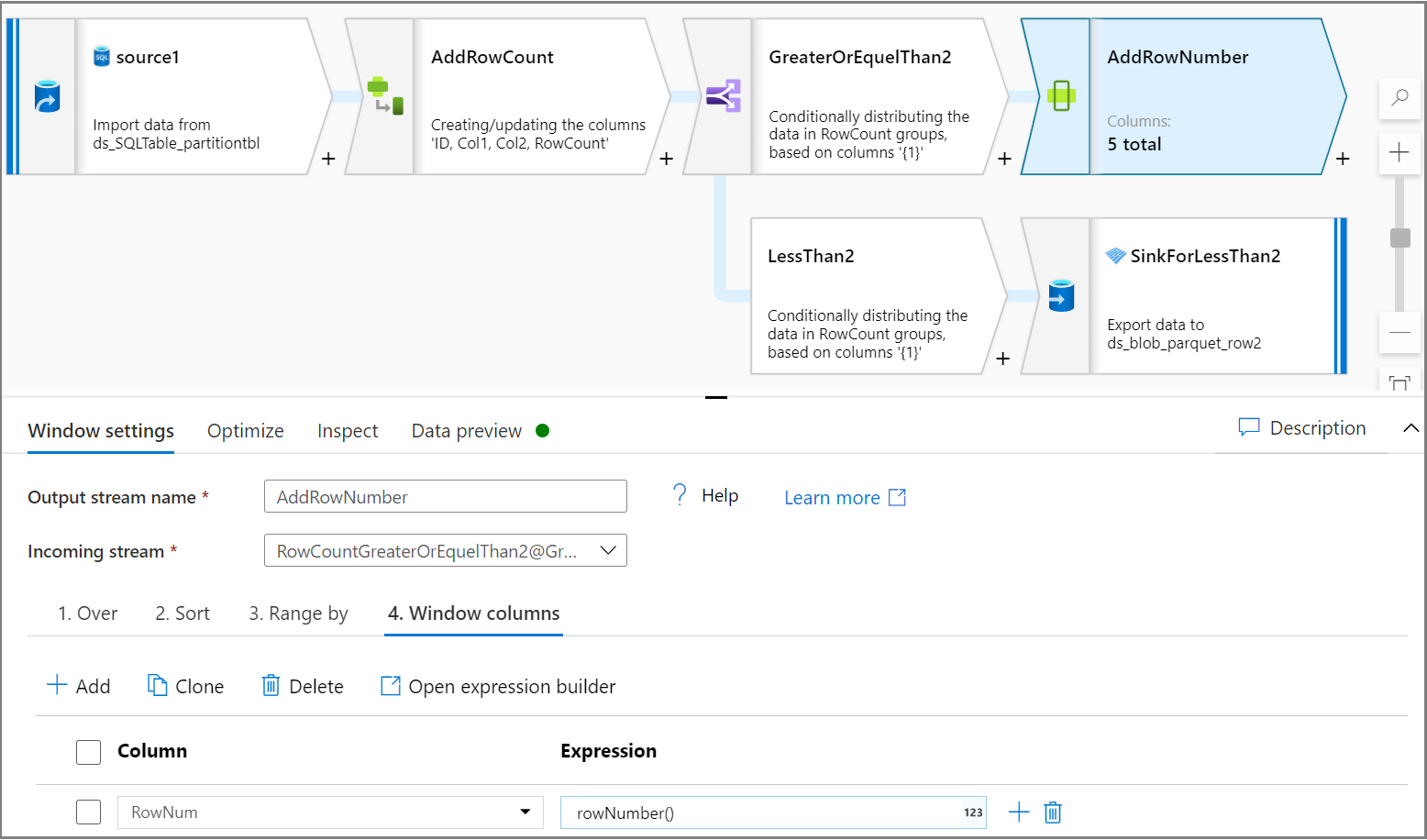
Teilen Sie mithilfe der Aktivität für bedingtes Teilen die Zeilen folgendermaßen auf: die ersten beiden Zeilen jeder Partition als Testdataset, die restlichen Zeilen als Trainingsdataset. Geben Sie auf der Registerkarte Einstellungen für bedingtes Teilen den Ausdruck
lesserOrEqual(RowNum,2)als Bedingung an.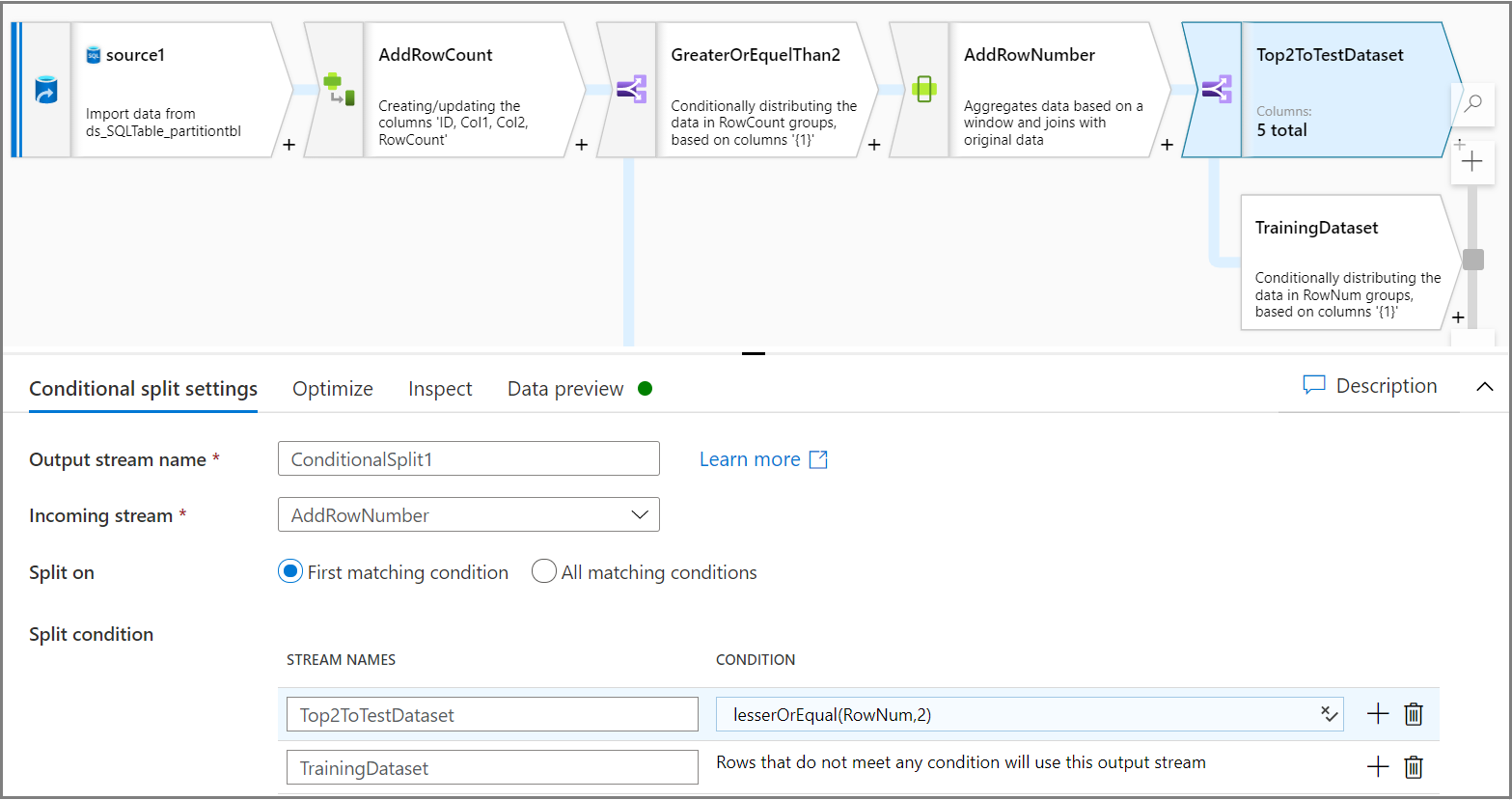
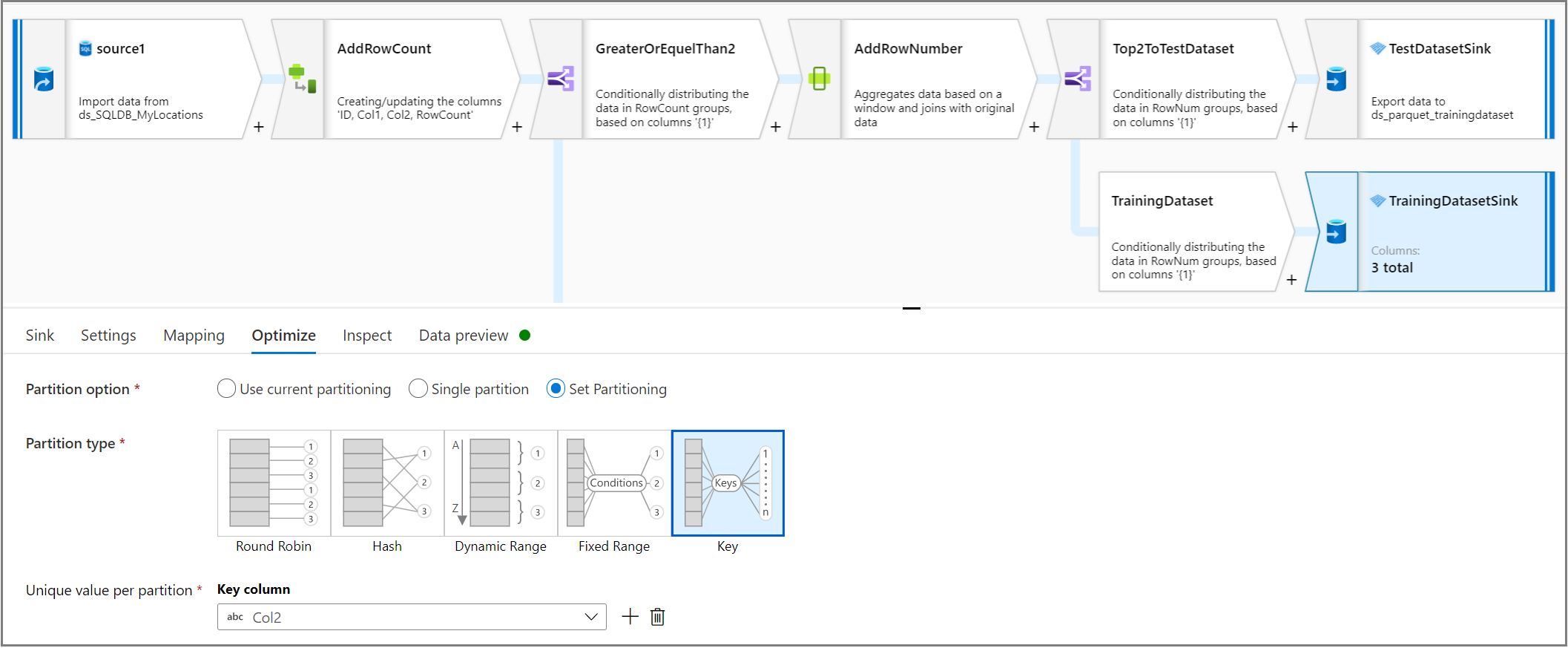
Partitionieren des Trainings- und Testdatasets im Parquet-Format
Legen Sie mithilfe der Senkenaktivität auf der Registerkarte Optimieren im Feld Eindeutiger Wert pro Partition eine Spalte als Spaltenschlüssel für die Partition fest.
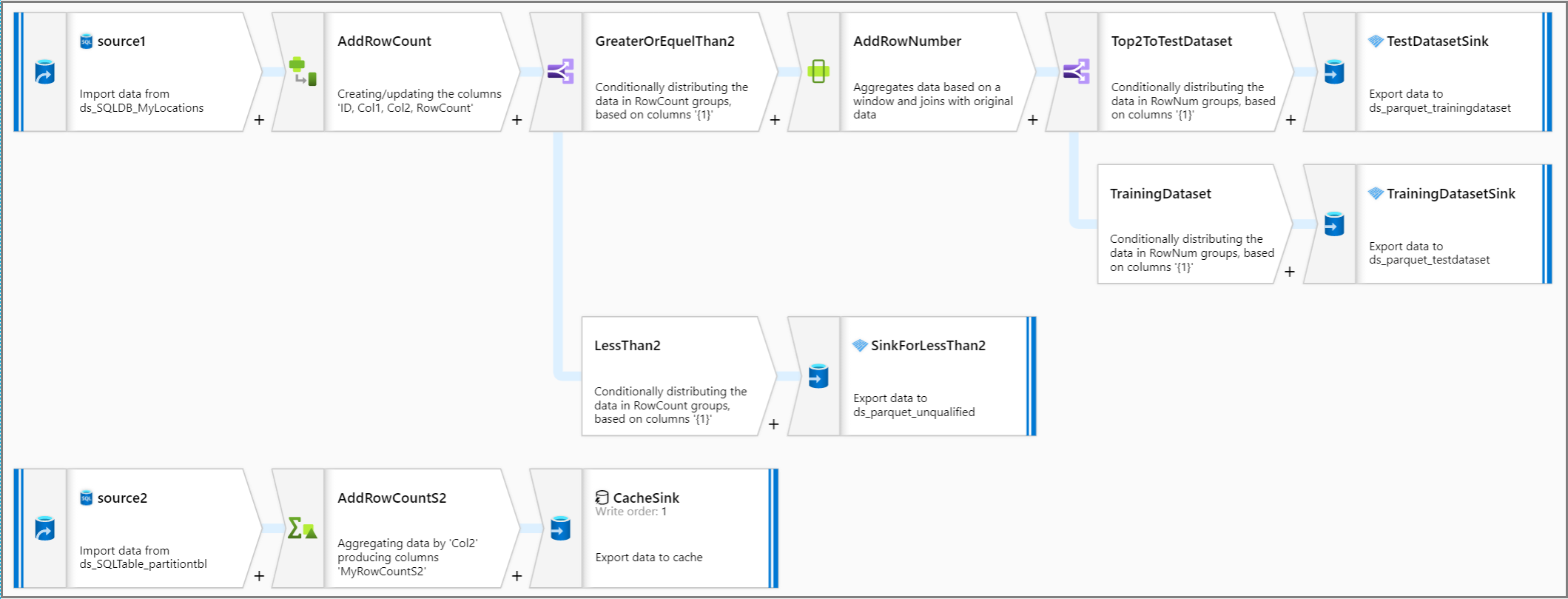
Sehen Sie sich nun die gesamte Pipelinelogik an.
Zugehöriger Inhalt
Erstellen Sie die restliche Datenflusslogik mithilfe von Transformationen der Zuordnungsdatenflüsse.