Massenkopieren von Dateien in eine Datenbank
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Artikel wird eine Lösungsvorlage beschrieben, die Sie zum Massenkopieren von Daten aus Azure Data Lake Storage Gen2 nach Azure Synapse Analytics/Azure SQL-Datenbank verwenden können.
Informationen zu dieser Lösungsvorlage
Mit dieser Vorlage werden Dateien aus der Azure Data Lake Storage Gen2-Quelle abgerufen. Anschließend wird jede Datei in der Quelle durchlaufen, und die Daten werden in den Zieldatenspeicher kopiert.
Diese Vorlage unterstützt derzeit nur das Kopieren von Daten im DelimitedText-Format. Dateien mit anderen Datenformaten können ebenfalls aus dem Quelldatenspeicher abgerufen werden, sie können jedoch nicht in den Zieldatenspeicher kopiert werden.
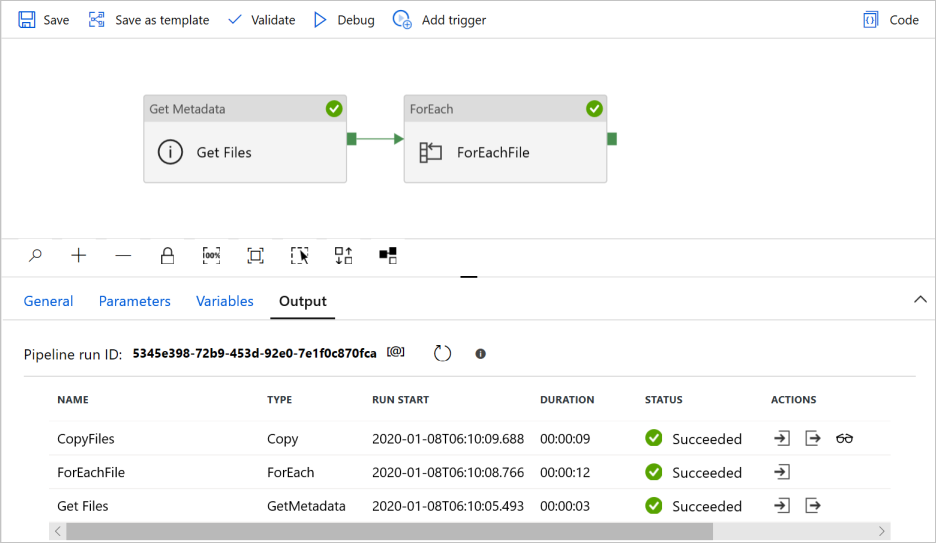
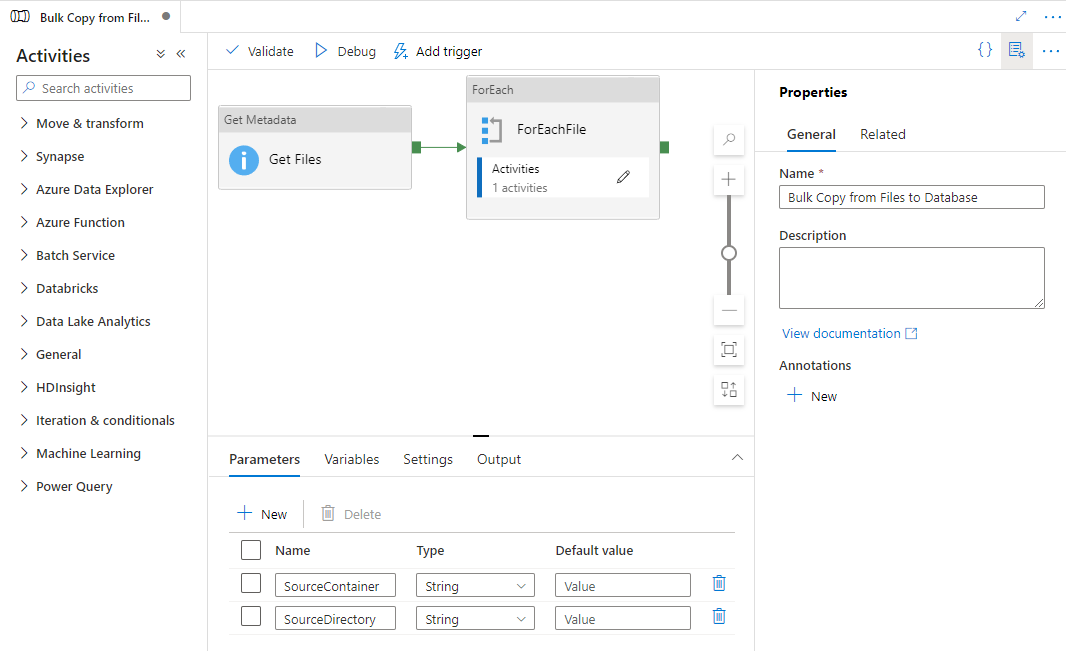
Die Vorlage enthält drei Aktivitäten:
- Die Aktivität Metadaten abrufen ruft Dateien aus Azure Data Lake Storage Gen2 ab und übergibt sie an die nachfolgende ForEach-Aktivität.
- Die ForEach-Aktivität ruft Dateien aus der Aktivität Metadaten abrufen ab und durchläuft jede Datei mit der Aktivität Kopieren.
- Die Aktivität Kopieren befindet sich innerhalb der ForEach-Aktivität, damit jede Datei aus dem Quelldatenspeicher in den Zieldatenspeicher kopiert werden kann.
Die Vorlage definiert die folgenden beiden Parameter:
- SourceContainer ist der Stammcontainerpfad, in den die Daten in Ihrer Azure Data Lake Storage Gen2-Instanz kopiert werden.
- SourceDirectory ist der Verzeichnispfad im Stammcontainer, in den die Daten aus Ihrer Azure Data Lake Storage Gen2-Instanz kopiert werden.
So verwenden Sie diese Lösungsvorlage
Öffnen Sie Azure Data Factory Studio, und wählen Sie die Registerkarte Autor mit dem Stiftsymbol aus.
Zeigen Sie auf den Abschnitt Pipelines, und wählen Sie die Auslassungspunkte aus, die auf der rechten Seite angezeigt werden. Wählen Sie dann Pipeline aus Vorlage aus.
Wählen Sie die Vorlage Massenkopieren aus Dateien in die Datenbank und dann Weiter aus.
Stellen Sie eine neue Verbindung mit dem Gen2-Quellspeicher als Ihre Quelle her und eine Verbindung mit der Datenbank für Ihre Senke. Wählen Sie dann Diese Vorlage verwenden aus.
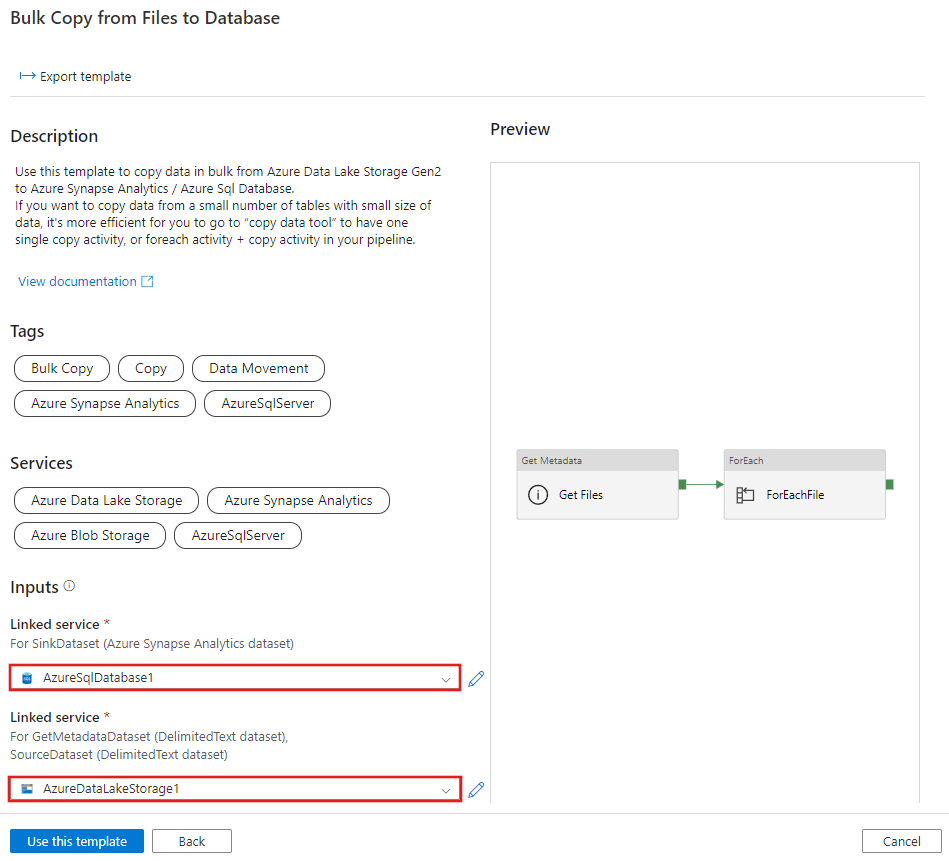
Eine neue Pipeline wird erstellt, wie im nachstehenden Beispiel gezeigt:
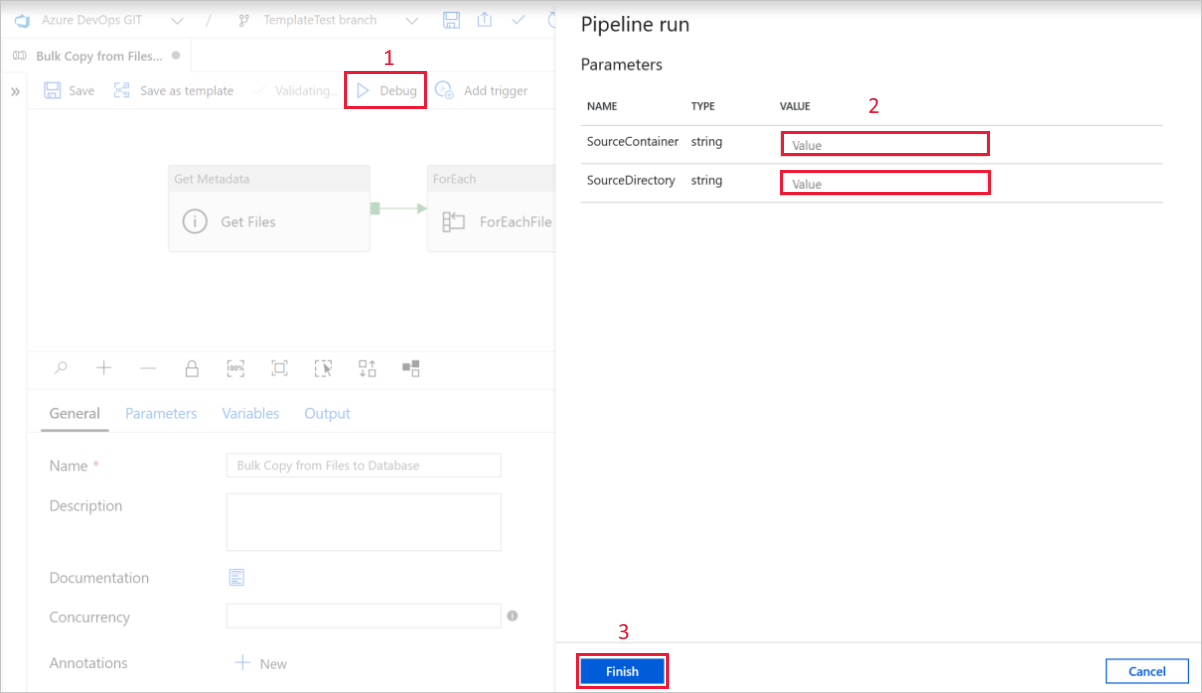
Klicken Sie auf Debuggen, geben Sie die Parameter ein, und klicken Sie dann auf Fertig stellen.
Wenn die Pipelineausführung erfolgreich abgeschlossen wurde, werden Ergebnisse ähnlich wie im nachstehenden Beispiel angezeigt: