Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisiert werden, um auf neue Funktionen in der Datenwissenschaft, Echtzeitanalysen und Berichterstellung zuzugreifen.
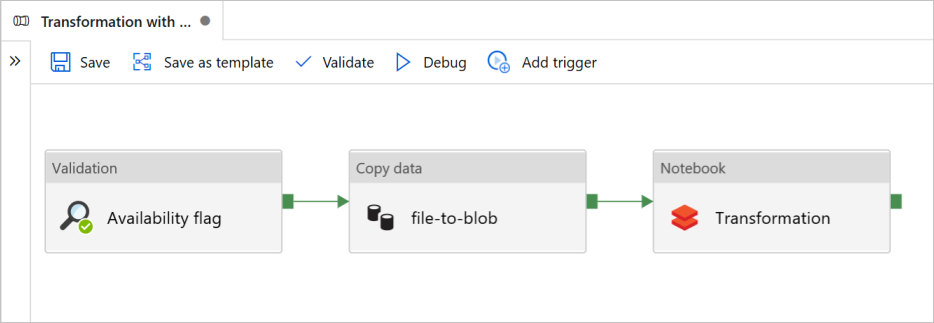
In diesem Lernprogramm erstellen Sie eine End-to-End-Pipeline, die die Validation, Copy data und NotebookAktivitäten in Azure Data Factory enthält.
Die Validierung stellt sicher, dass das Quelldataset für die nachgeschaltete Nutzung bereit ist, bevor der Kopier- und Analyseauftrag ausgelöst wird.
Mit Daten kopieren wird das Quelldataset im Senkenspeicher dupliziert, der im Azure Databricks-Notebook als DBFS eingebunden ist. Auf diese Weise kann das Dataset direkt von Spark genutzt werden.
Das Notebook löst das Databricks-Notebook aus, das das Dataset transformiert. Außerdem wird das Dataset einem verarbeiteten Ordner oder Azure Synapse Analytics hinzugefügt.
Der Einfachheit halber wird mit der Vorlage in diesem Tutorial kein geplanter Trigger erstellt. Sie können bei Bedarf einen solchen hinzufügen.
Voraussetzungen
Ein Azure Blob-Speicherkonto mit einem Container namens
sinkdatafür die Verwendung als Spüle.Notieren Sie sich den Speicherkontonamen, den Containernamen und den Zugriffsschlüssel. Sie benötigen diese Werte später in der Vorlage.
Ein Azure Databricks Arbeitsbereich.
Notebook für die Transformation importieren
So importieren Sie ein Transformation-Notebook in den Databricks-Arbeitsbereich:
Melden Sie sich bei Ihrem Azure Databricks Arbeitsbereich an.
Klicken Sie mit der rechten Maustaste auf einen Ordner in Ihrem Arbeitsbereich, und wählen Sie Importieren aus.
Wählen Sie URL-Import aus. Geben Sie im Textfeld
https://adflabstaging1.blob.core.windows.net/share/Transformations.htmlein.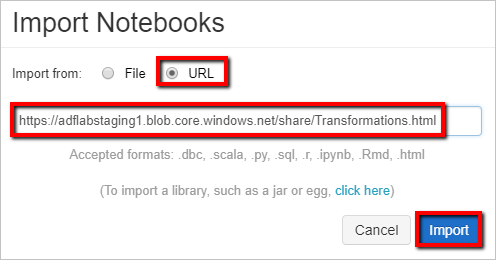
Jetzt aktualisieren wir das Notebook für die Transformation mit den Speicherverbindungsinformationen.
Wechseln Sie im importierten Notebook zu Befehl 5, wie im folgenden Codeausschnitt gezeigt.
- Ersetzen Sie
<storage name>und<access key>durch Ihre eigenen Speicherverbindungsinformationen. - Verwenden Sie das Speicherkonto mit dem Container
sinkdata.
# Supply storageName and accessKey values storageName = "<storage name>" accessKey = "<access key>" try: dbutils.fs.mount( source = "wasbs://sinkdata\@"+storageName+".blob.core.windows.net/", mount_point = "/mnt/Data Factorydata", extra_configs = {"fs.azure.account.key."+storageName+".blob.core.windows.net": accessKey}) except Exception as e: # The error message has a long stack track. This code tries to print just the relevant line indicating what failed. import re result = re.findall(r"\^\s\*Caused by:\s*\S+:\s\*(.*)\$", e.message, flags=re.MULTILINE) if result: print result[-1] \# Print only the relevant error message else: print e \# Otherwise print the whole stack trace.- Ersetzen Sie
Generieren Sie ein Databricks Zugriffstoken, damit Data Factory auf Databricks zugreifen kann.
- Wählen Sie in Ihrem Azure Databricks Arbeitsbereich Ihren Azure Databricks Benutzernamen in der oberen Leiste aus, und wählen Sie dann "Einstellungen" aus der Dropdownliste aus.
- Entwickler wählen
- Wählen Sie neben Zugriffstoken die Option Verwalten.
- Wählen Sie "Neuen Token generieren".
- (Optional) Geben Sie einen Kommentar ein, durch den Sie dieses Token in Zukunft identifizieren können, und ändern Sie die standardmäßige Lebensdauer des Tokens von 90 Tagen. Wenn Sie ein Token ohne Gültigkeitsdauer erstellen möchten (nicht empfohlen), lassen Sie das Feld Lebensdauer (Tage) leer.
- Wählen Sie Generieren aus.
- Kopieren Sie das angezeigte Token an einen sicheren Speicherort und wählen Sie Fertig.
Speichern Sie das Zugriffstoken für die spätere Verwendung beim Erstellen eines verknüpften Databricks-Diensts. Das Zugriffstoken lautet ungefähr dapi32db32cbb4w6eee18b7d87e45exxxxxx.
So verwenden Sie diese Vorlage
Wechseln Sie zur Vorlage Transformation mit Azure Databricks, und erstellen Sie neue verknüpfte Dienste für die folgenden Verbindungen.
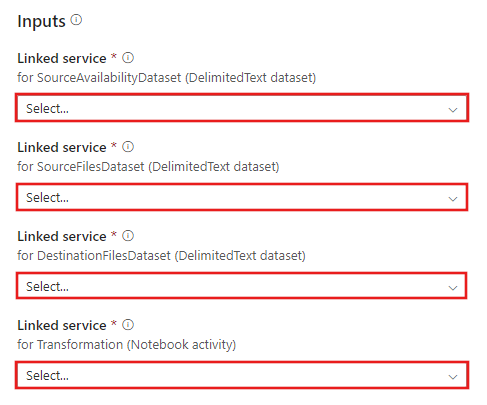
Quellblobverbindung: Für den Zugriff auf die Quelldatenbank.
Für diese Übung können Sie den öffentlichen Blobspeicher verwenden, der die Quelldateien enthält. Der folgende Screenshot dient als Referenz für die Konfiguration. Verwenden Sie die folgende SAS-URL zum Herstellen einer Verbindung mit dem Quellspeicher (schreibgeschützter Zugriff):
https://storagewithdata.blob.core.windows.net/data?sv=2018-03-28&si=read%20and%20list&sr=c&sig=PuyyS6%2FKdB2JxcZN0kPlmHSBlD8uIKyzhBWmWzznkBw%3D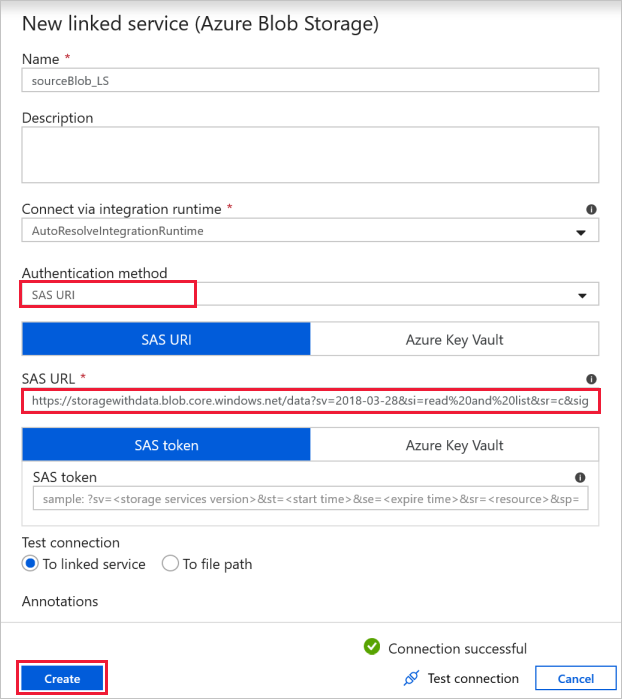
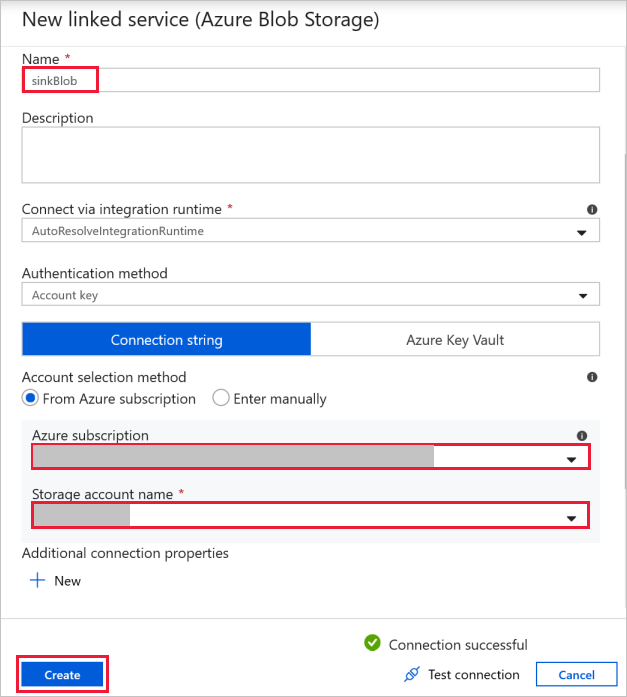
Zielblobverbindung: Zum Speichern der kopierten Daten.
Wählen Sie im Fenster Neuer verknüpfter Dienst den Senkenspeicherblob aus.
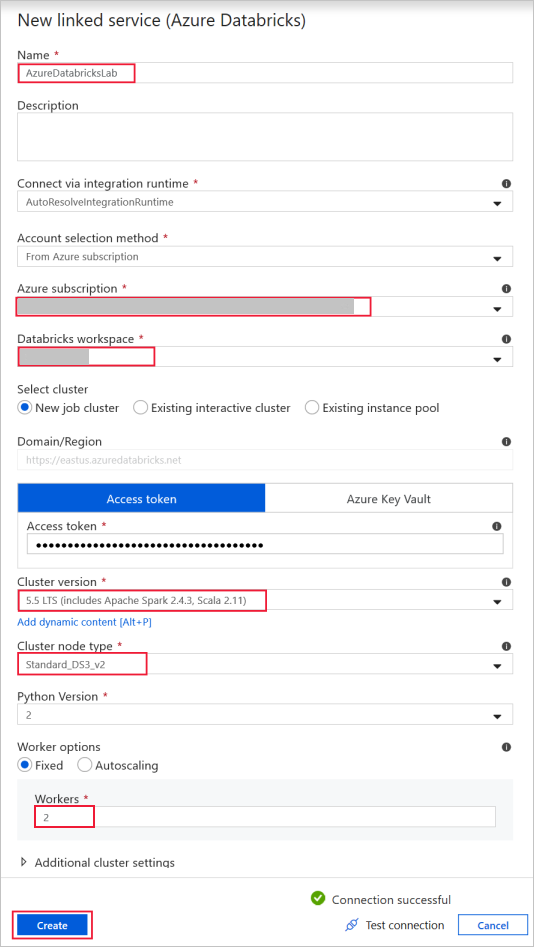
Azure Databricks – zum Herstellen einer Verbindung mit dem Databricks-Cluster.
Erstellen Sie einen mit Databricks verknüpften Dienst, indem Sie den zuvor generierten Zugriffsschlüssel verwenden. Sie können einen interaktiven Cluster auswählen, sofern vorhanden. In diesem Beispiel wird die Option Neuer Auftragscluster verwendet.
Klicken Sie auf Diese Vorlage verwenden. Sie sehen, eine Pipeline wird erstellt.
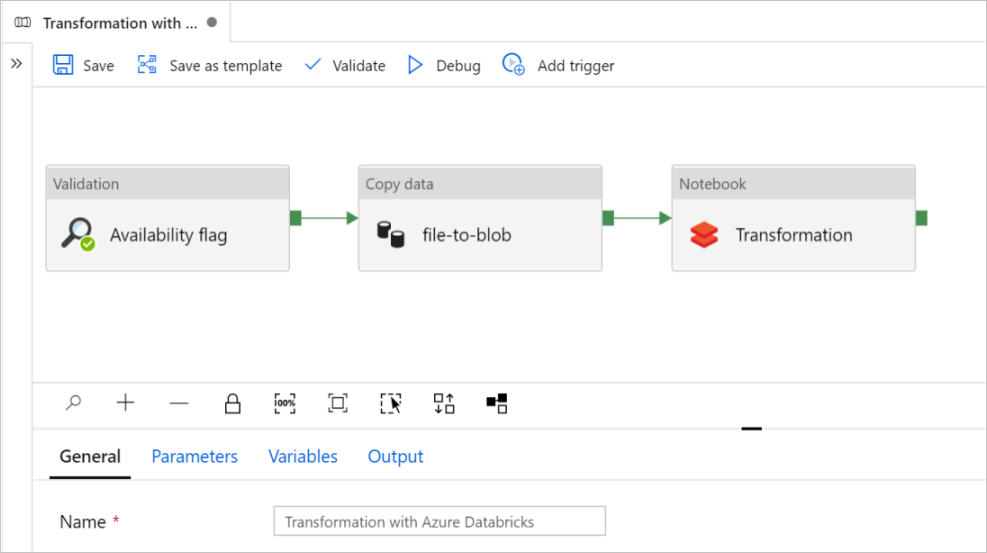
Einführung und Konfiguration der Pipeline
In der neuen Pipeline sind die meisten Einstellungen automatisch mit den jeweiligen Standardwerten konfiguriert. Überprüfen Sie die Konfigurationen der Pipeline, und nehmen Sie ggf. erforderliche Änderungen vor.
Überprüfen Sie, ob in der Aktivität Validierung mit dem Namen Availability flag der Wert für das Quell-Dataset auf das zuvor von Ihnen erstellte
SourceAvailabilityDatasetfestgelegt ist.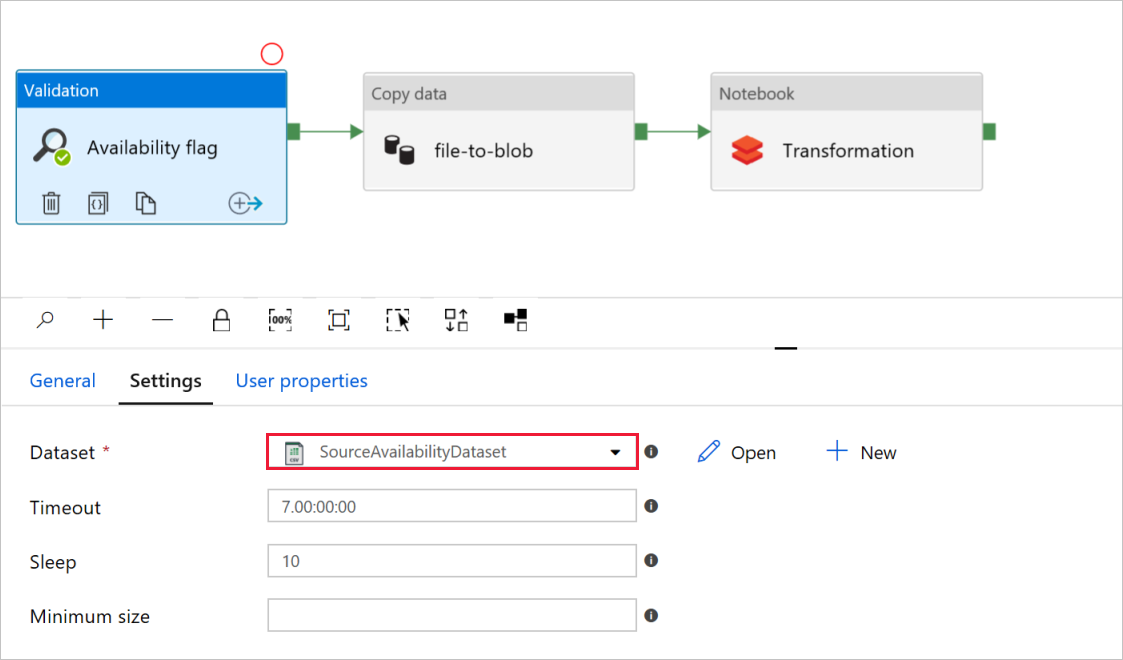
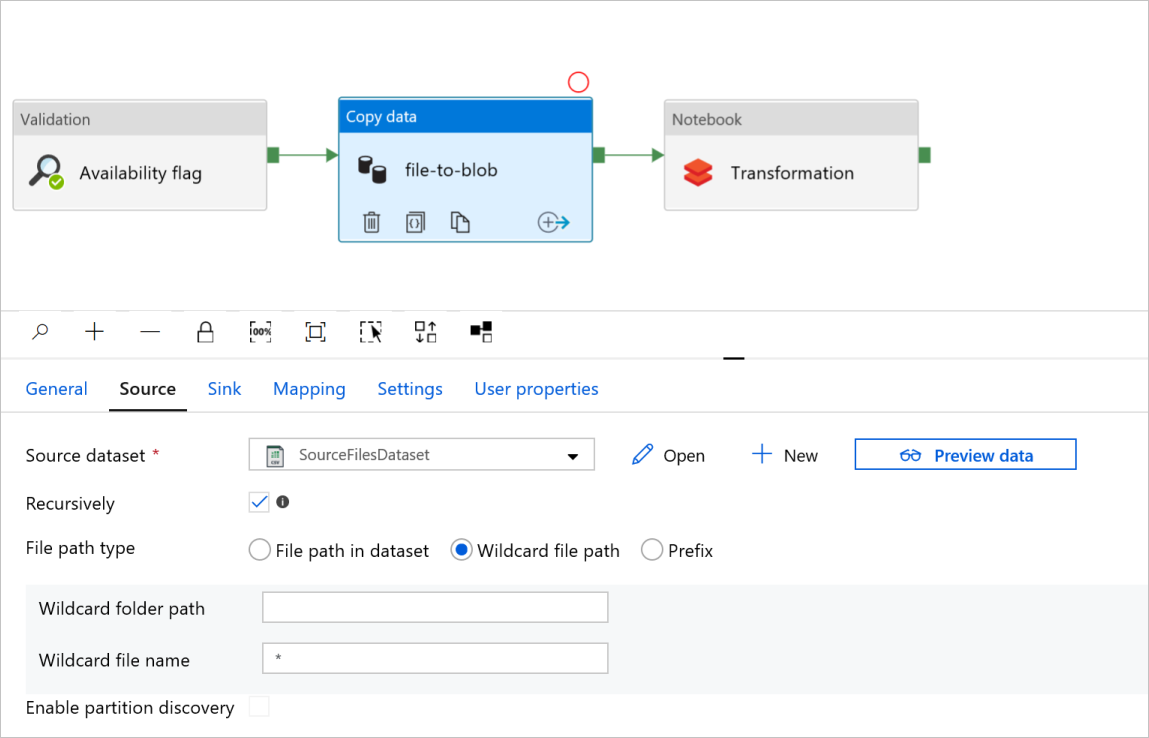
Überprüfen Sie in der Aktivität Daten kopieren mit dem Namen file-to-blob die Registerkarten Quelle und Senke. Ändern Sie die Einstellungen bei Bedarf.
Registerkarte Quelle
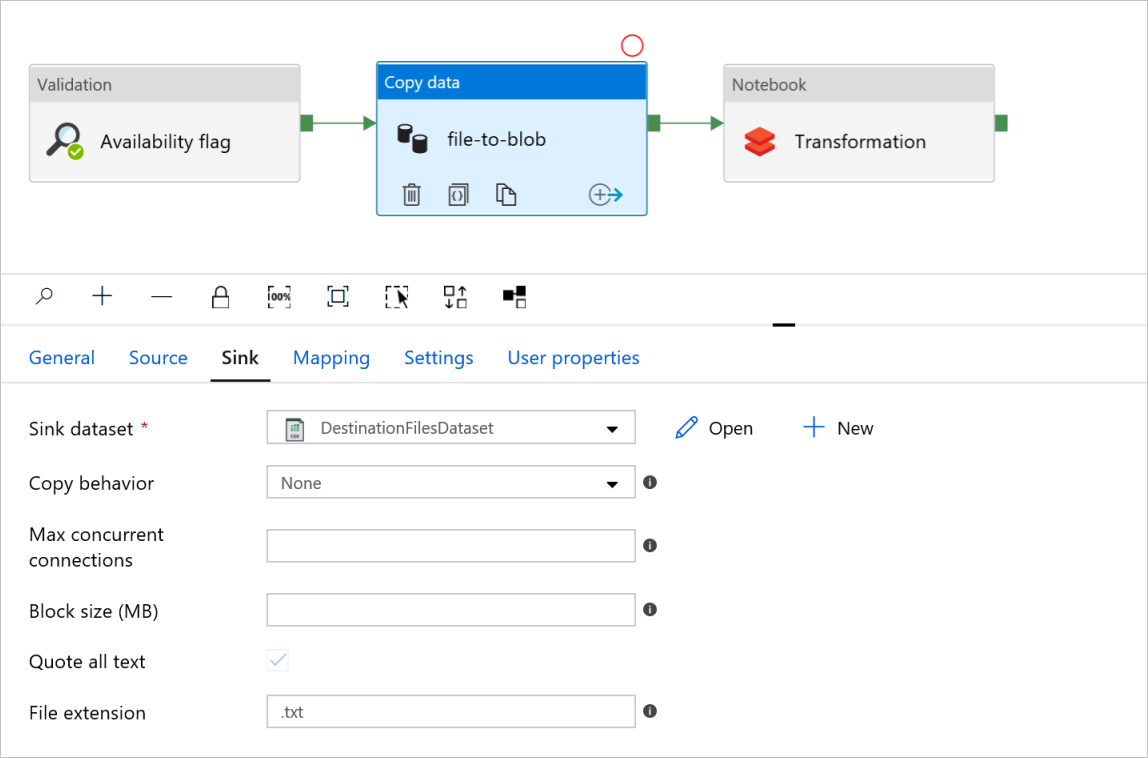
Registerkarte Senke
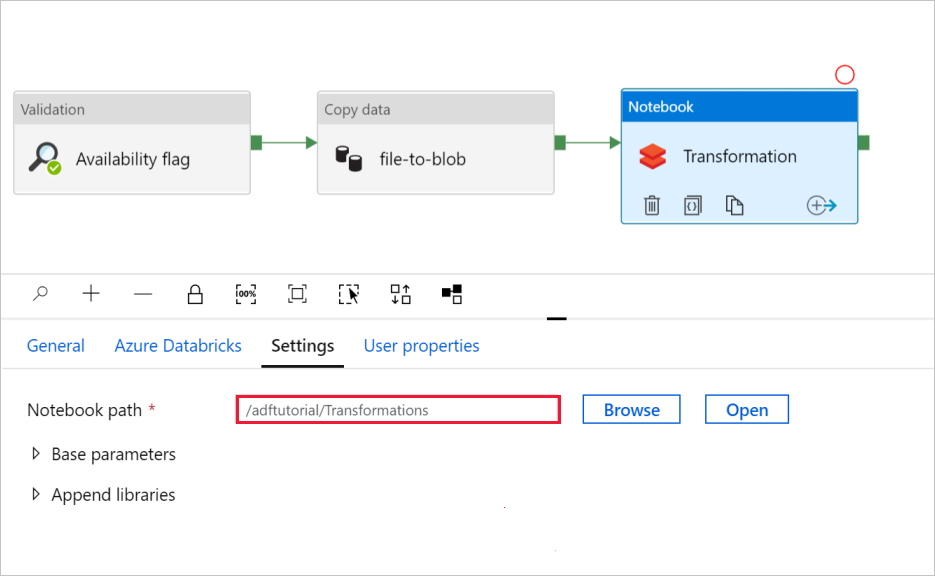
Überprüfen Sie in der Aktivität Notebook mit dem Namen Transformation die Pfade und Einstellungen, und aktualisieren Sie sie ggf.
Der verknüpfte Databricks-Dienst sollte bereits mit dem Wert aus einem vorherigen Schritt aufgefüllt sein, wie hier gezeigt:
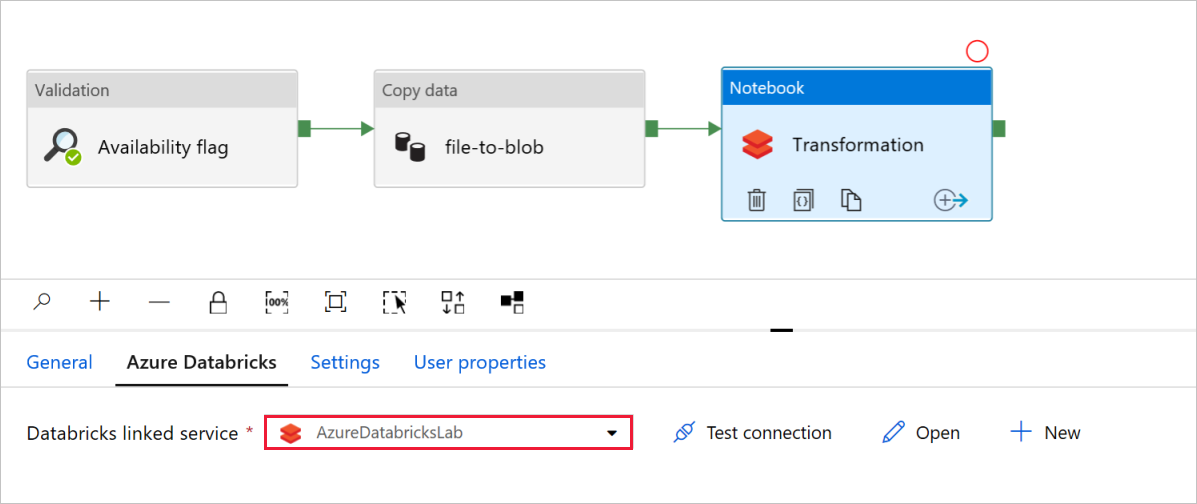
So überprüfen Sie die Notebook-Einstellungen:
Wählen Sie die Registerkarte Einstellungen aus. Überprüfen Sie für Notebook-Pfad, ob der Standardpfad richtig ist. Möglicherweise müssen Sie den richtigen Notebook-Pfad durchsuchen und auswählen.
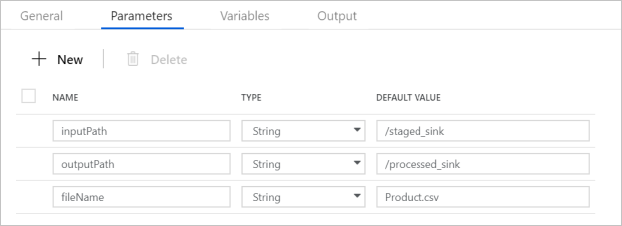
Erweitern Sie die Auswahl Basisparameter, und überprüfen Sie, ob die Parameter mit den im folgenden Screenshot gezeigten Parametern übereinstimmen. Diese Parameter werden von Data Factory an das Databricks-Notebook übergeben.

Überprüfen Sie, ob die Pipelineparameter mit der Anzeige im folgenden Screenshot übereinstimmen:
Stellen Sie eine Verbindung mit Ihren Datensätzen her.
Hinweis
In den folgenden Datasets wurde der Dateipfad in der Vorlage automatisch angegeben. Wenn Änderungen erforderlich sind, stellen Sie sicher, dass Sie den Pfad sowohl für Container als auch für Verzeichnis angeben, falls ein Verbindungsfehler auftreten sollte.
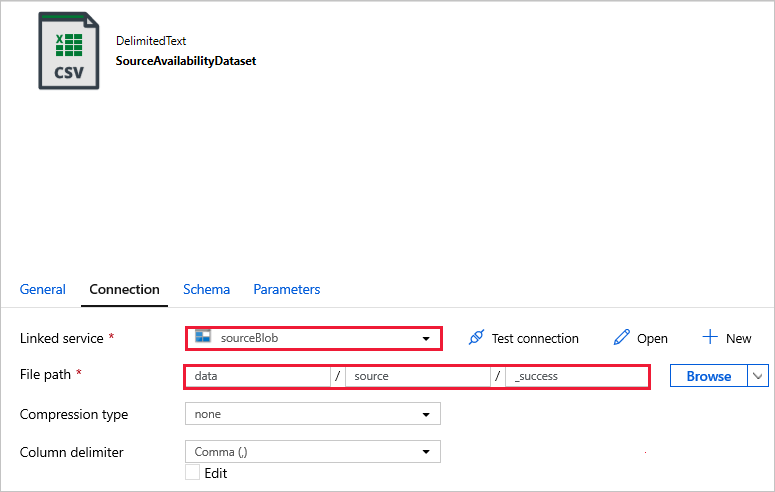
SourceAvailabilityDataset: Um zu überprüfen, ob die Quelldaten verfügbar sind.
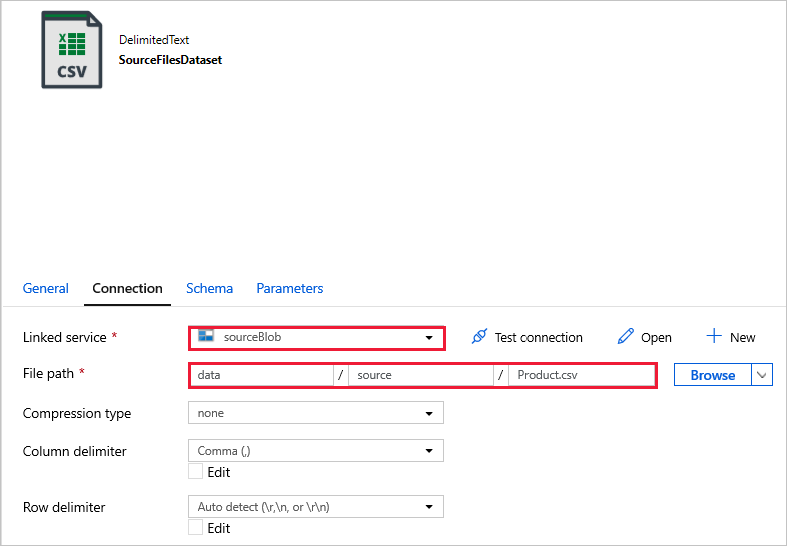
SourceFilesDataset: Für den Zugriff auf die Quelldaten.
DestinationFilesDataset: Zum Kopieren der Daten an den Senkenzielspeicherort. Verwenden Sie die folgenden Werte:
Verknüpfter Dienst -
sinkBlob_LS, in einem vorherigen Schritt erstellt.Dateipfad -
sinkdata/staged_sink.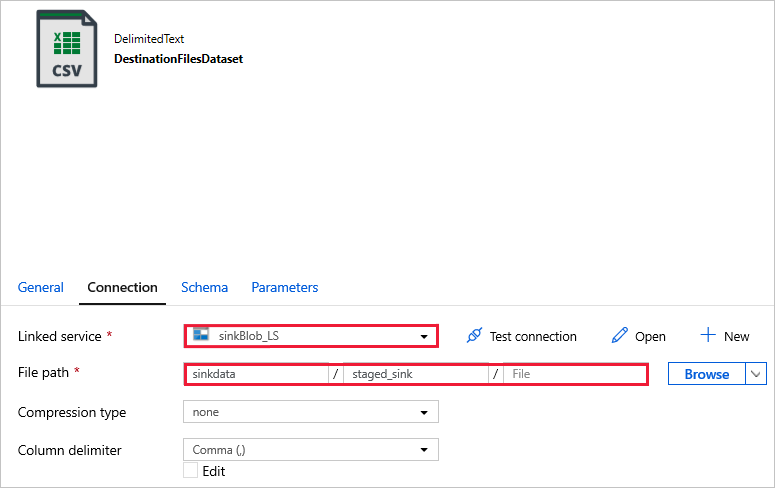
Wählen Sie Debuggen aus, um die Pipeline auszuführen. Hier finden Sie den Link zu Databricks-Protokollen, über den Sie ausführlichere Spark-Protokolle erhalten.
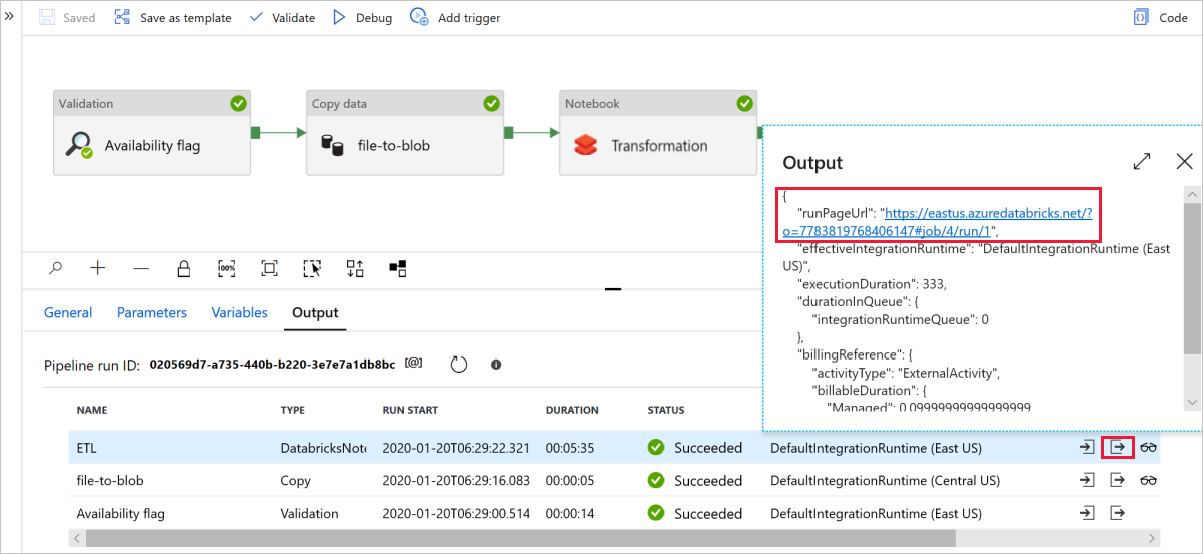
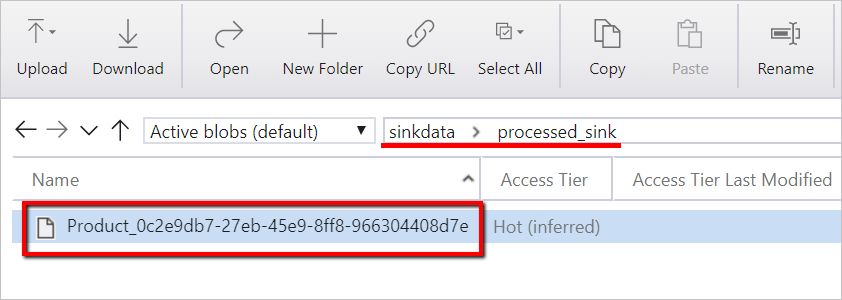
Sie können die Datendatei auch mithilfe von Azure Storage Explorer überprüfen.
Hinweis
Für die Korrelation mit Data Factory-Pipelineausführungen wird in diesem Beispiel die Pipelineausführungs-ID aus der Data Factory an den Ausgabeordner angefügt. Dies erleichtert die Nachverfolgung der durch jede Ausführung generierten Dateien.