Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Die Aktivität zur Azure Synapse Spark-Auftragsdefinition in einer Pipeline führt eine Synapse Spark-Auftragsdefinition in Ihrem Azure Synapse Analytics-Arbeitsbereich aus. Dieser Artikel baut auf dem Artikel zu Datentransformationsaktivitäten auf, der eine allgemeine Übersicht über die Datentransformation und die unterstützten Transformationsaktivitäten bietet.
Einrichten des Apache Spark-Auftragsdefinitionscanvas
Führen Sie die folgenden Schritte aus, um eine Spark-Auftragsdefinitionsaktivität für Synapse in einer Pipeline zu verwenden:
Allgemeine Einstellungen
Suchen Sie im Bereich „Aktivitäten“ der Pipeline nach Spark-Auftragsdefinition, und ziehen Sie eine Spark-Auftragsdefinitionsaktivität unter der Synapse auf die Pipelinecanvas.
Wählen Sie die neue Spark-Auftragsdefinitionsaktivität auf der Canvas aus, wenn sie nicht bereits ausgewählt ist.
Geben Sie auf der Registerkarte Allgemein ein Beispiel für Name ein.
Optional können Sie auch eine Beschreibung angeben.
Timeout: Der maximale Zeitraum für das Ausführen einer Aktivität. Als Standardwert ist der maximal zulässige Zeitrum von sieben Tagen eingestellt. Das Format ist „D.HH:MM:SS“.
Wiederholung: Die maximale Anzahl der Wiederholungsversuche.
Wiederholungsintervall: Die Anzahl von Sekunden zwischen den einzelnen Wiederholungsversuchen.
Sichere Ausgabe: Wenn diese Option aktiviert ist, werden Ausgaben der Aktivität nicht bei der Protokollierung erfasst.
Sichere Eingabe: Wenn diese Option aktiviert ist, werden Eingaben der Aktivität nicht bei der Protokollierung erfasst.
Azure Synapse Analytics-Einstellungen (Artefakte)
Wählen Sie die neue Spark-Auftragsdefinitionsaktivität auf der Canvas aus, wenn sie nicht bereits ausgewählt ist.
Wählen Sie die Registerkarte Azure Synapse Analytics (Artefakte) aus, um einen verknüpften Azure Synapse Analytics-Dienst auszuwählen oder zu erstellen, der die Spark-Auftragsdefinitionsaktivität ausführt.
Registerkarte "Einstellungen"
Wählen Sie die neue Spark-Auftragsdefinitionsaktivität auf der Canvas aus, wenn sie nicht bereits ausgewählt ist.
Wählen Sie die Registerkarte Einstellungen aus.
Erweitern Sie die Liste der Spark-Auftragsdefinition, und Sie können eine vorhandene Apache Spark-Auftragsdefinition im verknüpften Azure Synapse Analytics-Arbeitsbereich auswählen.
(Optional) Sie können die Informationen für die Apache Spark-Auftragsdefinition eingeben. Wenn die folgenden Einstellungen leer sind, werden die Einstellungen der Spark-Auftragsdefinition selbst zum Ausführen verwendet. Wenn die folgenden Einstellungen nicht leer sind, ersetzen diese Einstellungen die Einstellungen der Spark-Auftragsdefinition selbst.
Eigenschaft BESCHREIBUNG Hauptdefinitionsdatei Die für den Auftrag verwendete Hauptdatei. Wählen Sie eine PY/JAR/ZIP-Datei aus Ihrem Speicher. Sie können Datei hochladen auswählen, um die Datei in ein Speicherkonto hochzuladen.
Beispiel:abfss://…/path/to/wordcount.jarReferenzen aus Unterordnern Beim Durchsuchen der Unterordner des Stammordners der Hauptdefinitionsdatei werden diese Dateien als Referenzdateien hinzugefügt. Die Ordner mit den Namen „jars“, „pyFiles“, „files“ oder „archives“ werden überprüft, wobei die Groß-/Kleinschreibung beachtet wird. Name der Hauptklasse Der vollständig qualifizierte Bezeichner oder die Hauptklasse, die in der Hauptdefinitionsdatei enthalten ist.
Beispiel:WordCountBefehlszeilenargumente Sie können Befehlszeilenargumente hinzufügen, indem Sie auf die Schaltfläche Neu klicken. Beachten Sie, dass durch das Hinzufügen von Befehlszeilenargumenten die Befehlszeilenargumente außer Kraft gesetzt werden, die durch die Spark-Auftragsdefinition definiert sind.
Beispiel:abfss://…/path/to/shakespeare.txtabfss://…/path/to/resultApache Spark-Pool Sie können den Apache Spark-Pool aus der Liste auswählen. Python-Codeverweis Zusätzliche Python-Codedateien, die als Referenz in der Hauptdefinitionsdatei verwendet werden.
Es unterstützt das Übergeben von Dateien (.py, .py3, .zip) an die Eigenschaft „pyFiles“. Die in der Spark-Auftragsdefinition definierte Eigenschaft „pyFiles“ wird überschrieben.Referenzdateien Zusätzliche Dateien, die zu Referenzzwecken in der Hauptdefinitionsdatei verwendet werden. Apache Spark-Pool Sie können den Apache Spark-Pool aus der Liste auswählen. Executors dynamisch zuordnen Diese Einstellung entspricht der dynamischen Zuordnungseigenschaft in der Spark-Konfiguration für die Executorzuteilung der Spark-Anwendung. Min. Executors Dies ist die min. Anzahl von Executors, die im angegebenen Spark-Pool für den Auftrag zugeordnet werden sollen. Max. Executors Dies ist die max. Anzahl von Executors, die im angegebenen Spark-Pool für den Auftrag zugeordnet werden sollen. „Driver size“ (Treibergröße) Die Anzahl von Kernen und die Menge an Arbeitsspeicher, die für Treiber im angegebenen Apache Spark-Pool für den Auftrag verwendet werden sollen. Spark-Konfiguration Geben Sie Werte für die Spark-Konfigurationseigenschaften an, die im Thema Spark-Konfiguration – Anwendungseigenschaften aufgeführt sind. Benutzer können die Standardkonfiguration und die angepasste Konfiguration verwenden. Authentifizierung Vom Benutzer zugewiesene verwaltete Identitäten oder vom System zugewiesene verwaltete Identitäten, die bereits in Spark-Auftragsdefinitionen unterstützt werden. 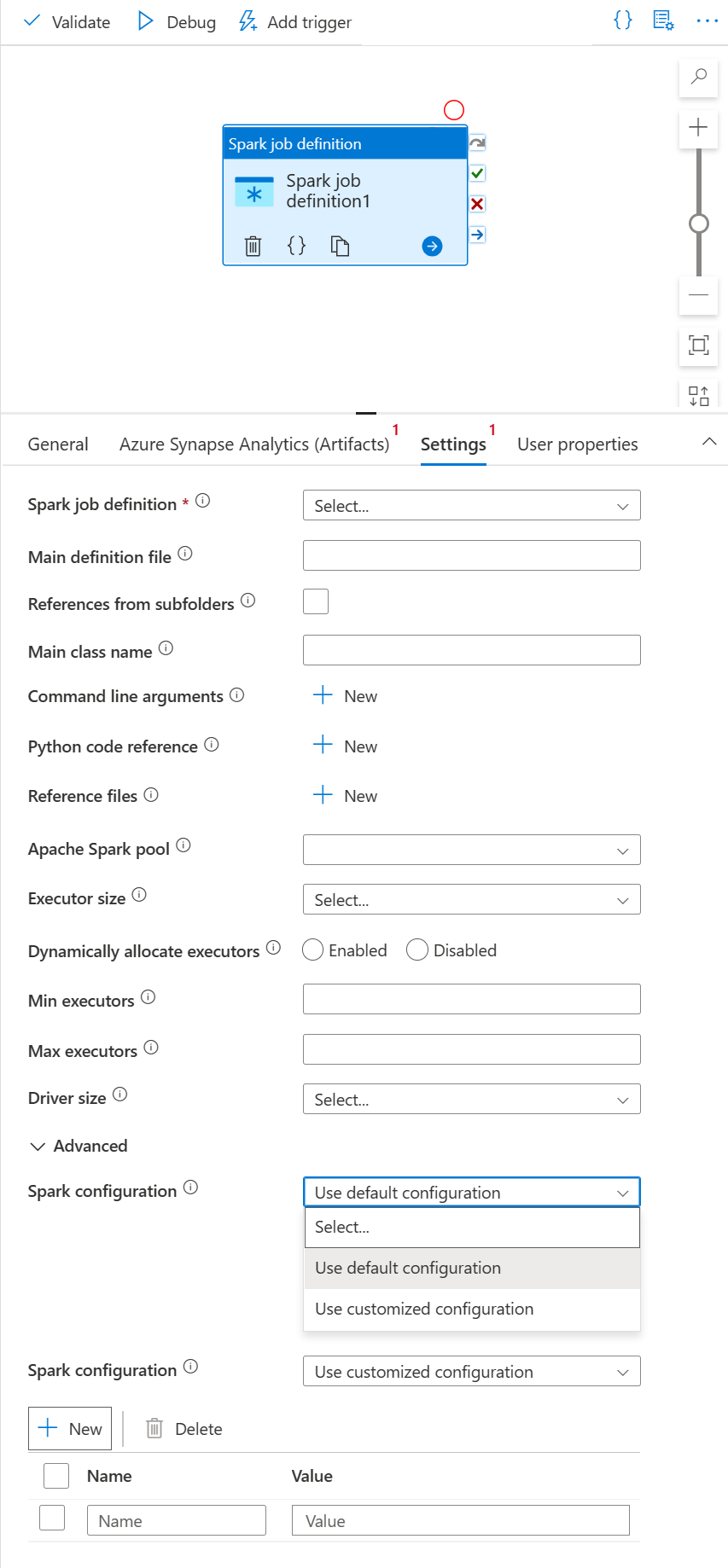
Sie können dynamische Inhalte hinzufügen, indem Sie auf die Schaltfläche Dynamischen Inhalt hinzufügen klicken oder die Tastenkombination Alt+Umschalt+D drücken. Auf der Dynamischen Inhalt hinzufügen-Seite können Sie eine beliebige Kombination aus Ausdrücken, Funktionen und Systemvariablen verwenden, um dynamische Inhalte hinzuzufügen.
Benutzereigenschaften-Tab
In diesem Bereich können Sie Eigenschaften für Apache Spark-Auftragsdefinitionsaktivitäten hinzufügen.
Spark-Definition der Auftragsdefinitionsaktivität für Azure Synapse
Hier sehen Sie die JSON-Beispieldefinition einer Azure Synapse Analytics-Notebookaktivität:
{
"activities": [
{
"name": "Spark job definition1",
"type": "SparkJob",
"dependsOn": [],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"typeProperties": {
"sparkJob": {
"referenceName": {
"value": "Spark job definition 1",
"type": "Expression"
},
"type": "SparkJobDefinitionReference"
}
},
"linkedServiceName": {
"referenceName": "AzureSynapseArtifacts1",
"type": "LinkedServiceReference"
}
}
],
}
Eigenschaften der Spark-Auftragsdefinition in Azure Synapse
Die folgende Tabelle beschreibt die JSON-Eigenschaften, die in der JSON-Definition verwendet werden:
| Eigenschaft | BESCHREIBUNG | Erforderlich |
|---|---|---|
| Name | Der Name der Aktivität in der Pipeline. | Ja |
| Beschreibung | Ein Text, der beschreibt, was mit der Aktivität ausgeführt wird. | Nein |
| Typ | Für die Spark-Auftragsdefinitionsaktivität von Azure Synapse lautet der Aktivitätstyp „SparkJob“. | Ja |
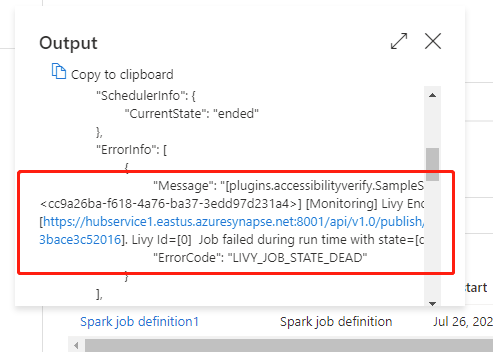
Weitere Informationen finden Sie im Ausführungsverlauf zur Spark-Auftragsdefinitionsaktivität von Azure Synapse
Unter „Pipelineausführungen“ auf der Registerkarte Überwachen werden die ausgelösten Pipelines aufgeführt. Öffnen Sie die Pipeline, die die Spark-Auftragsdefinitionsaktivität von Azure Synapse enthält, um den Ausführungsverlauf anzuzeigen.
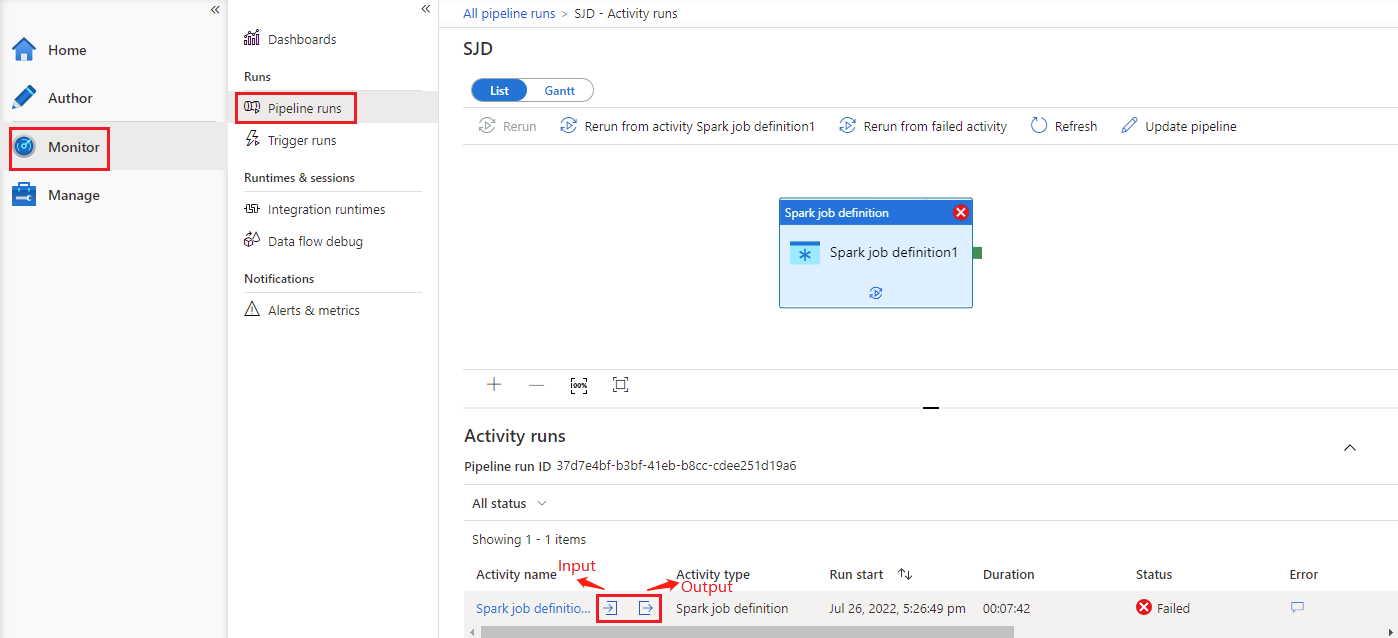
Wählen Sie die Schaltfläche Eingabe oder Ausgabe aus, um die Eingaben oder Ausgaben der Notebookaktivität anzuzeigen. Wenn Ihre Pipeline aufgrund eines Benutzerfehlers fehlgeschlagen ist, wählen Sie Ausgabe aus, um das Feld Ergebnis zu überprüfen und die detaillierte Rückverfolgung des Benutzerfehlers zu sehen.