Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisiert werden, um auf neue Funktionen in der Datenwissenschaft, Echtzeitanalysen und Berichterstellung zuzugreifen.
Eine Pipeline in einem Azure Data Factory- oder Synapse Analytics-Arbeitsbereich verarbeitet Daten in verknüpften Speicherdiensten mithilfe verknüpfter Computedienste. Sie enthält eine Abfolge von Aktivitäten, wobei jede Aktivität einen bestimmten Verarbeitungsvorgang ausführt. In diesem Artikel werden die Data Lake Analytics U-SQL-Aktivität beschrieben, die ein U-SQLSkript für einen Azure Data Lake Analytics compute linked service ausführt.
Erstellen Sie ein Azure Data Lake Analytics Konto, bevor Sie eine Pipeline mit einer Data Lake Analytics U-SQL-Aktivität erstellen. Weitere Informationen zu Azure Data Lake Analytics finden Sie unter Get started with Azure Data Lake Analytics.
Hinzufügen einer U-SQL-Aktivität für Azure Data Lake Analytics zu einer Pipeline mit Benutzeroberfläche
Führen Sie die folgenden Schritte aus, um eine U-SQL-Aktivität für Azure Data Lake Analytics in einer Pipeline zu verwenden:
Suchen Sie im Pipelineaktivitätenbereich nach Data Lake, und ziehen Sie eine U-SQL-Aktivität in den Pipelinebereich.
Wählen Sie die neue U-SQL-Aktivität im Canvas aus, wenn sie noch nicht ausgewählt ist.
Wählen Sie die Registerkarte ADLA-Konto aus, um einen neuen Azure Data Lake Analytics verknüpften Dienst auszuwählen oder zu erstellen, der zum Ausführen der U-SQL-Aktivität verwendet wird.
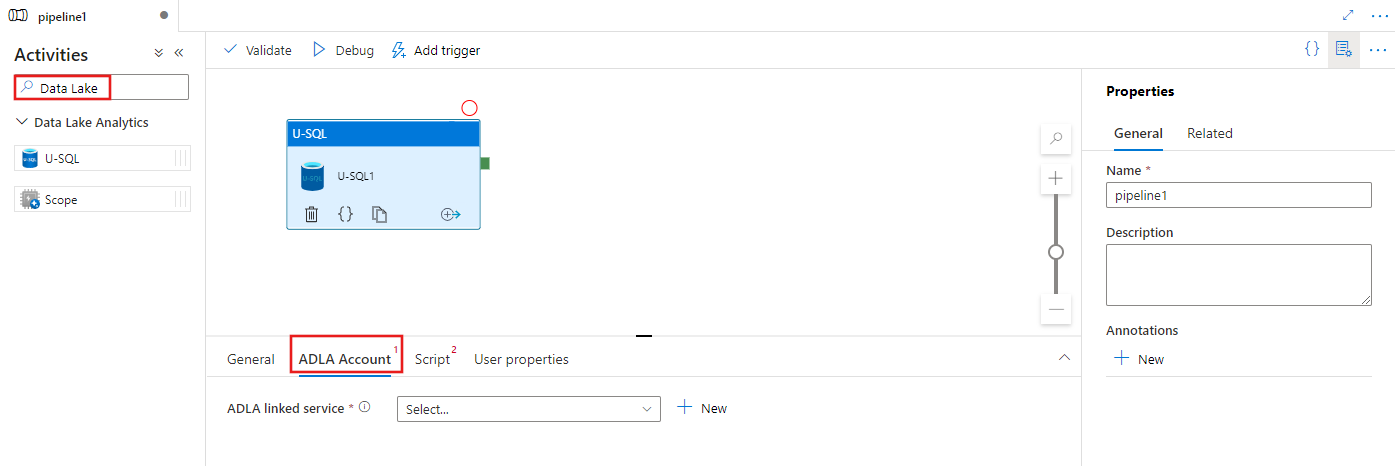
Wählen Sie die Registerkarte Skript aus, um einen neuen verknüpften Speicherdienst und einen Pfad innerhalb des Speicherorts auszuwählen oder zu erstellen, der das Skript hosten soll.
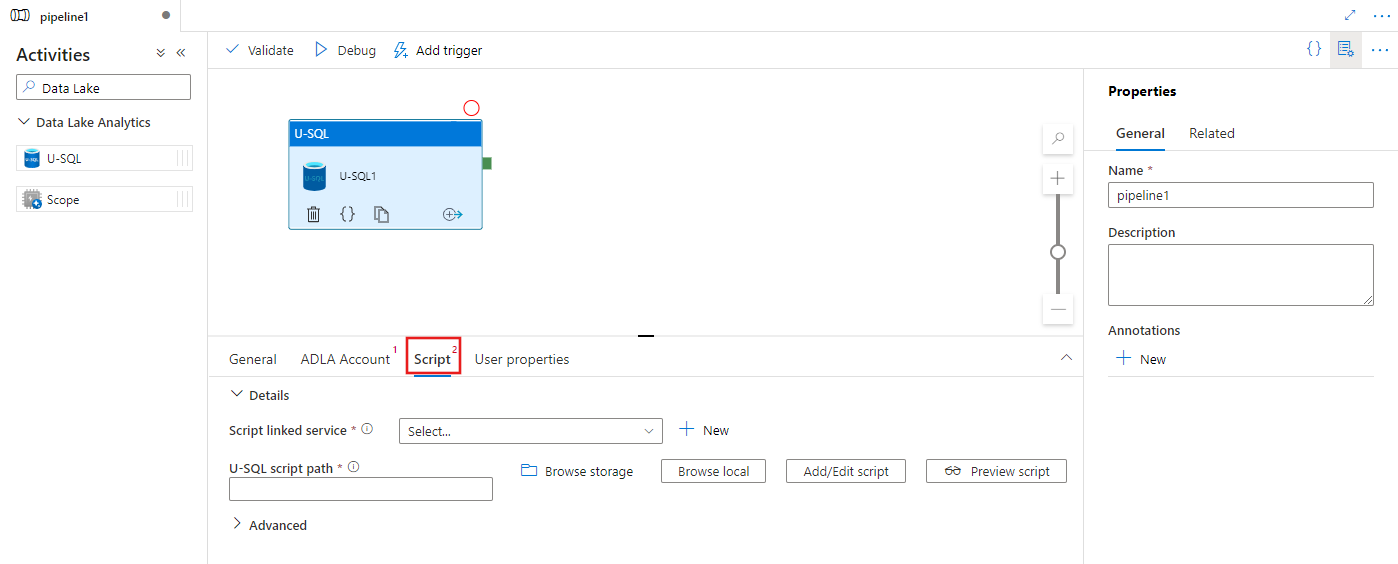
Azure Data Lake Analytics verknüpfter Dienst
Sie erstellen einen Azure Data Lake Analytics verknüpften Dienst, um einen Azure Data Lake Analytics Computedienst mit einem Azure Data Factory- oder Synapse Analytics-Arbeitsbereich zu verknüpfen. Die Data Lake Analytics U-SQL-Aktivität in der Pipeline bezieht sich auf diesen verknüpften Dienst.
Die folgende Tabelle enthält Beschreibungen der allgemeinen Eigenschaften, die in der JSON-Definition verwendet werden.
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Legen Sie die type-Eigenschaft auf AzureDataLakeAnalytics fest. | Ja |
| accountName | Azure Data Lake Analytics Kontoname. | Ja |
| dataLakeAnalyticsUri | Azure Data Lake Analytics URI. | Nein |
| subscriptionId | Azure Abonnement-ID | Nein |
| resourceGroupName | Azure Ressourcengruppenname | Nein |
Service Principal-Authentifizierung
Der mit Azure Data Lake Analytics verknüpfte Dienst erfordert eine Dienstprinzipal-Authentifizierung, um eine Verbindung mit dem Azure Data Lake Analytics-Dienst herzustellen. Wenn Sie die Dienstprinzipalauthentifizierung verwenden möchten, registrieren Sie in Microsoft Entra ID eine Anwendungsentität und gewähren ihr Zugriff auf Data Lake Analytics und den verwendeten Data Lake Store. Eine ausführliche Anleitung finden Sie unter Dienst-zu-Dienst-Authentifizierung. Notieren Sie sich die folgenden Werte, die Sie zum Definieren des verknüpften Diensts verwenden:
- Anwendungs-ID
- Anwendungsschlüssel
- Mandanten-ID
Verwenden Sie den Assistenten für das Hinzufügen von Benutzern, um Azure Data Lake Analytics die Dienstprinzipalberechtigung zu erteilen.
Verwenden Sie die Dienstprinzipalauthentifizierung, indem Sie die folgenden Eigenschaften angeben:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| servicePrincipalId | Geben Sie die Client-ID der Anwendung an. | Ja |
| servicePrincipalKey | Geben Sie den Schlüssel der Anwendung an. | Ja |
| Mandant | Geben Sie die Mandanteninformationen (Domänenname oder Mandanten-ID) für Ihre Anwendung an. Diese können Sie abrufen, indem Sie im Azure-Portal mit der Maus auf den Bereich oben rechts zeigen. | Ja |
Beispiel: Authentifizierung des Dienstprincipals
{
"name": "AzureDataLakeAnalyticsLinkedService",
"properties": {
"type": "AzureDataLakeAnalytics",
"typeProperties": {
"accountName": "<account name>",
"dataLakeAnalyticsUri": "<azure data lake analytics URI>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"subscriptionId": "<optional, subscription id of ADLA>",
"resourceGroupName": "<optional, resource group name of ADLA>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Weitere Informationen zu dem verknüpften Dienst finden Sie unter Berechnen von verknüpften Diensten.
Data Lake Analytics U-SQL-Aktivität
Der folgende JSON-Codeausschnitt definiert eine Pipeline mit einer Data Lake Analytics U-SQL-Aktivität. Die Aktivitätsdefinition weist einen Verweis auf den zuvor erstellten Azure Data Lake Analytics verknüpften Dienst auf. Zum Ausführen eines Data Lake Analytics U-SQL-Skripts sendet der Dienst das skript, das Sie an die Data Lake Analytics angegeben haben, und die erforderlichen Eingaben und Ausgaben werden im Skript definiert, damit Data Lake Analytics abrufen und ausgeben können.
{
"name": "ADLA U-SQL Activity",
"description": "description",
"type": "DataLakeAnalyticsU-SQL",
"linkedServiceName": {
"referenceName": "<linked service name of Azure Data Lake Analytics>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptLinkedService": {
"referenceName": "<linked service name of Azure Data Lake Store or Azure Storage which contains the U-SQL script>",
"type": "LinkedServiceReference"
},
"scriptPath": "scripts\\kona\\SearchLogProcessing.txt",
"degreeOfParallelism": 3,
"priority": 100,
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
}
}
Die folgende Tabelle beschreibt die Namen und Eigenschaften, die für diese Aktivität spezifisch sind.
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Name | Name der Aktivität in der Pipeline | Ja |
| Beschreibung | Ein Text, der beschreibt, was mit der Aktivität ausgeführt wird. | Nein |
| Typ | Für Data Lake Analytics U-SQL-Aktivität ist der Aktivitätstyp DataLakeAnalyticsU-SQL. | Ja |
| verknüpfterDienstname | Verknüpfter Dienst mit Azure Data Lake Analytics. Weitere Informationen zu diesem verknüpften Dienst finden Sie im Artikel Verknüpfte Compute-Dienste. | Ja |
| scriptPath | Der Pfad zum Ordner, der das U-SQL-Skript enthält. Beim Dateinamen wird Groß-/Kleinschreibung unterschieden. | Ja |
| scriptLinkedService | Verknüpfter Dienst, der den Azure Data Lake Store oder Azure Storage verknüpft, der das Skript enthält | Ja |
| Parallelitätsgrad | Die maximale Anzahl von Knoten, die zum Ausführen des Auftrags gleichzeitig verwendet werden. | Nein |
| Priorität | Bestimmt, welche der in der Warteschlange befindlichen Aufträge als erstes ausgeführt werden. Je niedriger die Zahl, desto höher die Priorität. | Nein |
| parameters | Parameter, die an das U-SQL-Skript übergeben werden sollen. | Nein |
| Laufzeitversion | Die Runtimeversion der zu verwendenden U-SQL-Engine. | Nein |
| Kompilierungsmodus | Der Kompilierungsmodus von U-SQL. Muss einen der folgenden Werte aufweisen: Semantic: Es werden nur Semantiküberprüfungen und erforderliche Integritätsprüfungen durchgeführt. Full: Es wird die vollständige Kompilierung ausgeführt, einschließlich Syntaxprüfung, Optimierung, Codegenerierung usw. SingleBox: Es wird die vollständige Kompilierung durchgeführt, wobei die TargetType-Einstellung auf „SingleBox“ festgelegt ist. Wenn Sie für diese Eigenschaft keinen Wert angeben, bestimmt der Server den optimalen Kompilierungsmodus. |
Nein |
Die Skriptdefinition finden Sie unter SearchLogProcessing.txt.
U-SQL-Beispielskript
@searchlog =
EXTRACT UserId int,
Start DateTime,
Region string,
Query string,
Duration int,
Urls string,
ClickedUrls string
FROM @in
USING Extractors.Tsv(nullEscape:"#NULL#");
@rs1 =
SELECT Start, Region, Duration
FROM @searchlog
WHERE Region == "en-gb";
@rs1 =
SELECT Start, Region, Duration
FROM @rs1
WHERE Start <= DateTime.Parse("2012/02/19");
OUTPUT @rs1
TO @out
USING Outputters.Tsv(quoting:false, dateTimeFormat:null);
Im obigem Skriptbeispiel wird die Ein- und Ausgabe des Skripts in den Parametern @in und @out definiert. Die Werte für die Parameter @in und @out im U-SQL-Skript werden vom Dienst dynamisch mithilfe des Abschnitts „parameters“ übergeben.
Sie können in Ihrer Pipelinedefinition auch andere Eigenschaften wie "degreeOfParallelism" und "priority" für die Aufträge angeben, die auf dem Azure Data Lake Analytics-Dienst ausgeführt werden.
Dynamische Parameter
In der beispielhaften Pipelinedefinition werden die Eingabe- und Ausgabeparameter mit hartcodierten Werten zugewiesen.
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
Es ist möglich, stattdessen dynamische Parameter zu verwenden. Beispiel:
"parameters": {
"in": "/datalake/input/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/data.tsv",
"out": "/datalake/output/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/result.tsv"
}
In diesem Fall werden die Eingabedateien weiterhin aus dem Ordner „/datalake/input“ abgerufen und die Ausgabedateien im Ordner „datalake/output“ generiert. Die Dateinamen sind dynamisch und basieren auf dem Start des Zeitfensters, der übergeben wird, wenn die Pipeline ausgelöst wird.
Zugehöriger Inhalt
In den folgenden Artikeln erfahren Sie, wie Daten auf andere Weisen transformiert werden: