Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Suchen Sie nach einer einfachen Möglichkeit zum Verschieben von Daten? Kopierauftrag in Microsoft Fabric bietet eine einfache, skalierbare Möglichkeit zum Laden von Daten, ohne eine Pipeline zu erstellen. Erfahren Sie, wie Sie eins erstellen.
In diesem Tutorial verwenden Sie das Azure-Portal, um eine Data Factory zu erstellen. Anschließend erstellen Sie mithilfe des Tools zum Kopieren von Daten eine Pipeline, die Daten aus Azure Blob Storage in eine SQL-Datenbank kopiert.
Hinweis
Falls Sie noch nicht mit Azure Data Factory vertraut sind, ist es ratsam, den Artikel Einführung in Azure Data Factory zu lesen.
In diesem Tutorial führen Sie die folgenden Schritte aus:
- Erstellen einer Data Factory.
- Verwenden Sie das Tool zum Kopieren von Daten, um eine Pipeline zu erstellen.
- Überwachen der Pipeline- und Aktivitätsausführungen.
Voraussetzungen
- Azure-Abonnement: Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
- Azure Storage-Konto: Verwenden Sie Blob Storage als Quelldatenspeicher. Falls Sie noch nicht über ein Azure Storage-Konto verfügen, finden Sie hier eine Anleitung zum Erstellen eines Speicherkontos.
- Azure SQL-Datenbank: Verwenden Sie eine SQL-Datenbank als Senkendatenspeicher. Sollten Sie über keine SQL-Datenbank verfügen, lesen Sie die Anweisungen unter Erstellen einer SQL-Datenbank.
Vorbereiten der SQL-Datenbank
Ermöglichen Sie Azure-Diensten den Zugriff auf den logischen SQL Server Ihrer Azure SQL-Datenbank.
Vergewissern Sie sich, dass für den Server, auf dem SQL-Datenbank ausgeführt wird, die Einstellung Anderen Azure-Diensten und -Ressourcen den Zugriff auf diesen Server gestatten aktiviert ist. Diese Einstellung ermöglicht der Data Factory das Schreiben von Daten in Ihre Datenbankinstanz. Navigieren Sie zum Überprüfen und Aktivieren dieser Einstellung zu „Logischer SQL Server“ > „Sicherheit“ > „Firewalls und virtuelle Netzwerke“, und legen Sie die Option > auf EIN fest.
Hinweis
Die Option Anderen Azure-Diensten und -Ressourcen den Zugriff auf diesen Server gestatten ermöglicht den Netzwerkzugriff auf Ihre SQL Server-Instanz über jede Azure-Ressource, nicht nur über die Ressourcen in Ihrem Abonnement. Es ist möglicherweise nicht für alle Umgebungen geeignet, ist aber für dieses eingeschränkte Lernprogramm geeignet. Weitere Informationen finden Sie unter Azure SQL Server Firewall-Regeln. Stattdessen können Sie private Endpunkte verwenden, um eine Verbindung mit Azure-PaaS-Diensten herzustellen, ohne öffentliche IP-Adressen zu verwenden.
Erstellen eines Blobs und einer SQL-Tabelle
Bereiten Sie Ihre Blob Storage-Instanz und Ihre SQL-Datenbank wie folgt für das Tutorial vor:
Erstellen eines Quellblobs
Starten Sie Notepad. Kopieren Sie den folgenden Text, und speichern Sie ihn in einer Datei namens inputEmp.txt auf einem Datenträger:
FirstName|LastName John|Doe Jane|DoeErstellen Sie einen Container namens adfv2tutorial, und laden Sie die Datei „inputEmp.txt“ in den Container hoch. Sie können für diese Aufgaben das Azure-Portal oder verschiedene Tools verwenden, etwa Azure Storage-Explorer.
Erstellen einer SQL-Senkentabelle
Verwenden Sie das folgende SQL-Skript, um eine Tabelle namens
dbo.empin Ihrer SQL-Datenbank zu erstellen:CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);
Erstellen einer Data Factory
Wählen Sie im oberen Menü die Option "Resource>Analytics>Data Factory erstellen" aus:
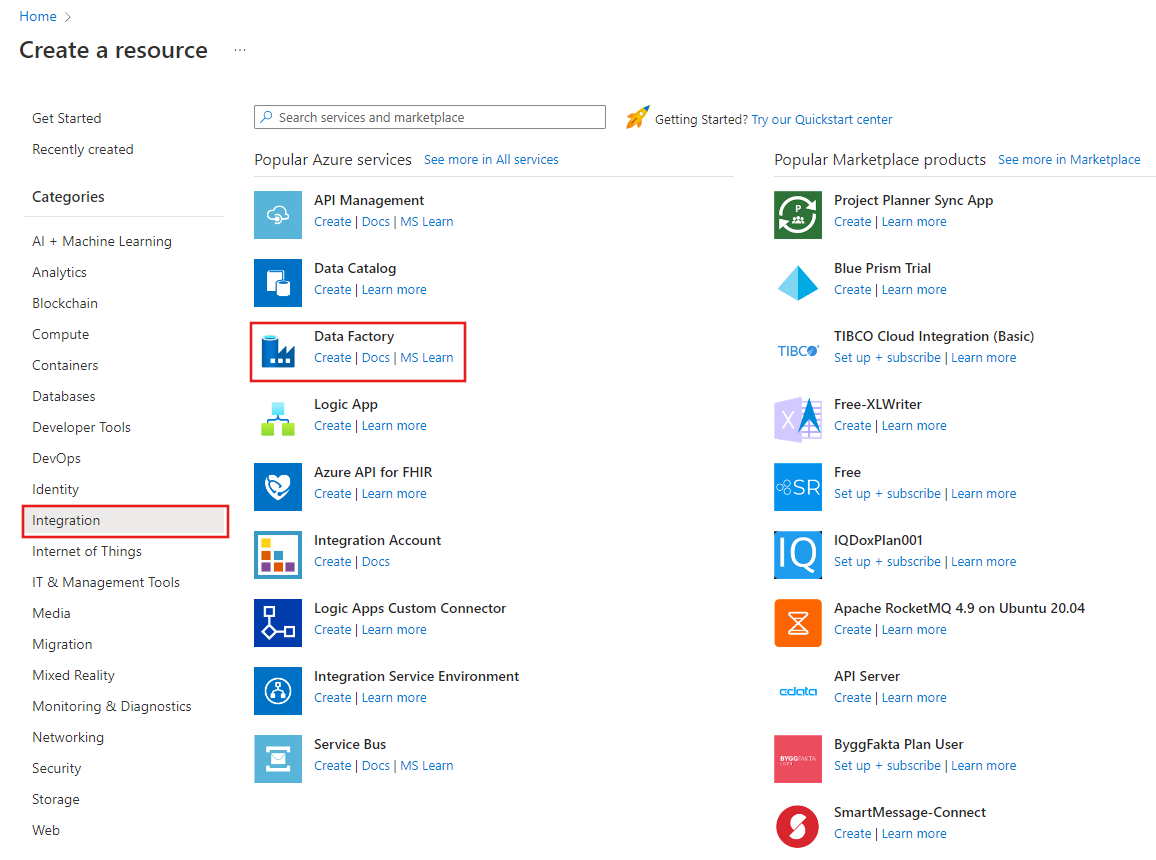
Geben Sie auf der Seite Neue Data Factory unter Name den Namen ADFTutorialDataFactory ein.
Der Name der Data Factory muss global eindeutig sein. Sie erhalten unter Umständen die folgende Fehlermeldung:
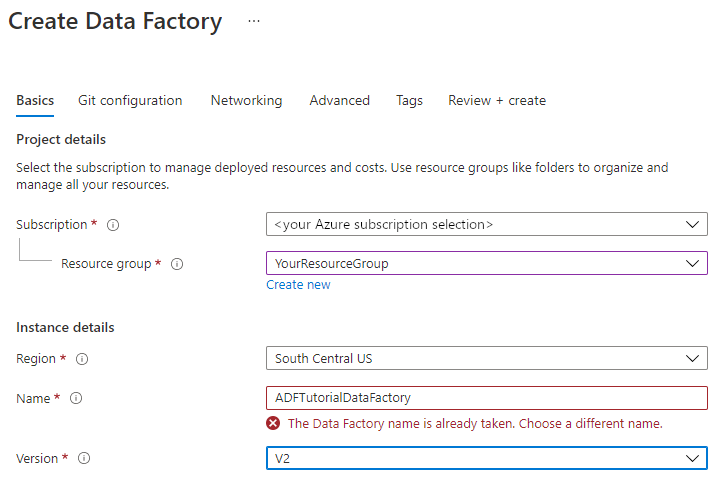
Wenn eine Fehlermeldung zum Namenswert angezeigt wird, geben Sie einen anderen Namen für die Data Factory ein. Verwenden Sie beispielsweise den Namen IhrNameADFTutorialDataFactory. Benennungsregeln für Data Factory-Artefakte finden Sie im Thema Data Factory – Benennungsregeln.
Wählen Sie das Azure-Abonnement aus, in dem die neue Data Factory erstellt werden soll.
Führen Sie unter Ressourcengruppe einen der folgenden Schritte aus:
a) Wählen Sie Use existing (Vorhandene verwenden) aus und dann eine vorhandene Ressourcengruppe aus der Dropdownliste.
b. Wählen Sie Neu erstellen, und geben Sie den Namen einer Ressourcengruppe ein.
Weitere Informationen zu Ressourcengruppen finden Sie unter Verwenden von Ressourcengruppen zum Verwalten von Azure-Ressourcen.
Wählen Sie unter Version die Option V2.
Wählen Sie unter Standort den Standort für die Data Factory aus. In der Dropdownliste werden nur unterstützte Standorte angezeigt. Die Datenspeicher (etwa Azure Storage und SQL-Datenbank) und Computeeinheiten (etwa Azure HDInsight), die von der Data Factory genutzt werden, können sich an anderen Standorten und in anderen Regionen befinden.
Klicken Sie auf Erstellen.
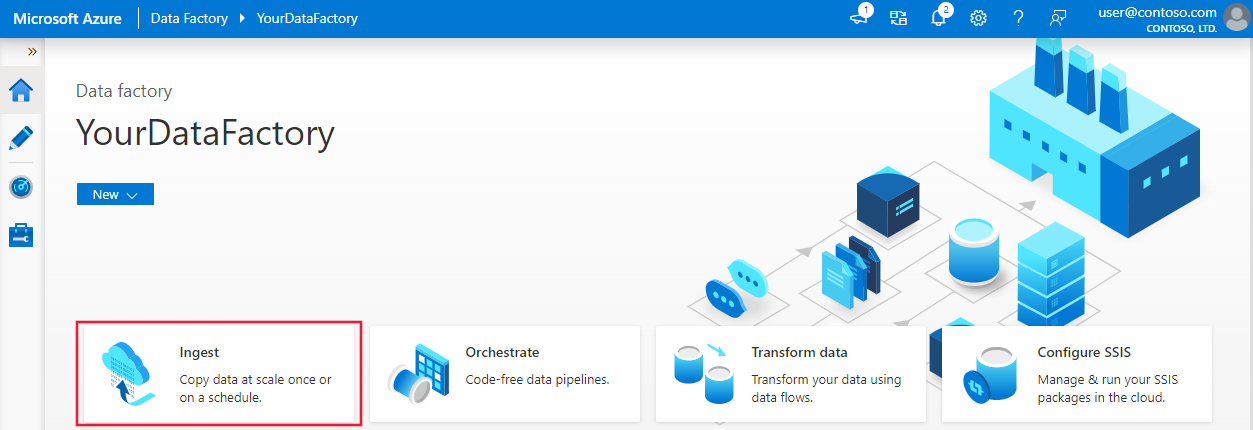
Nach Abschluss der Erstellung wird die Startseite von Data Factory angezeigt.

Um die Benutzeroberfläche (UI) von Azure Data Factory in einem separaten Tab zu starten, wählen Sie auf der Kachel Open Azure Data Factory Studio die Option Öffnen.
Erstellen einer Pipeline mithilfe des Tools zum Kopieren von Daten
Wählen Sie auf der Homepage von Azure Data Factory die Kachel Erfassung aus, um das Tool „Daten kopieren“ zu starten.
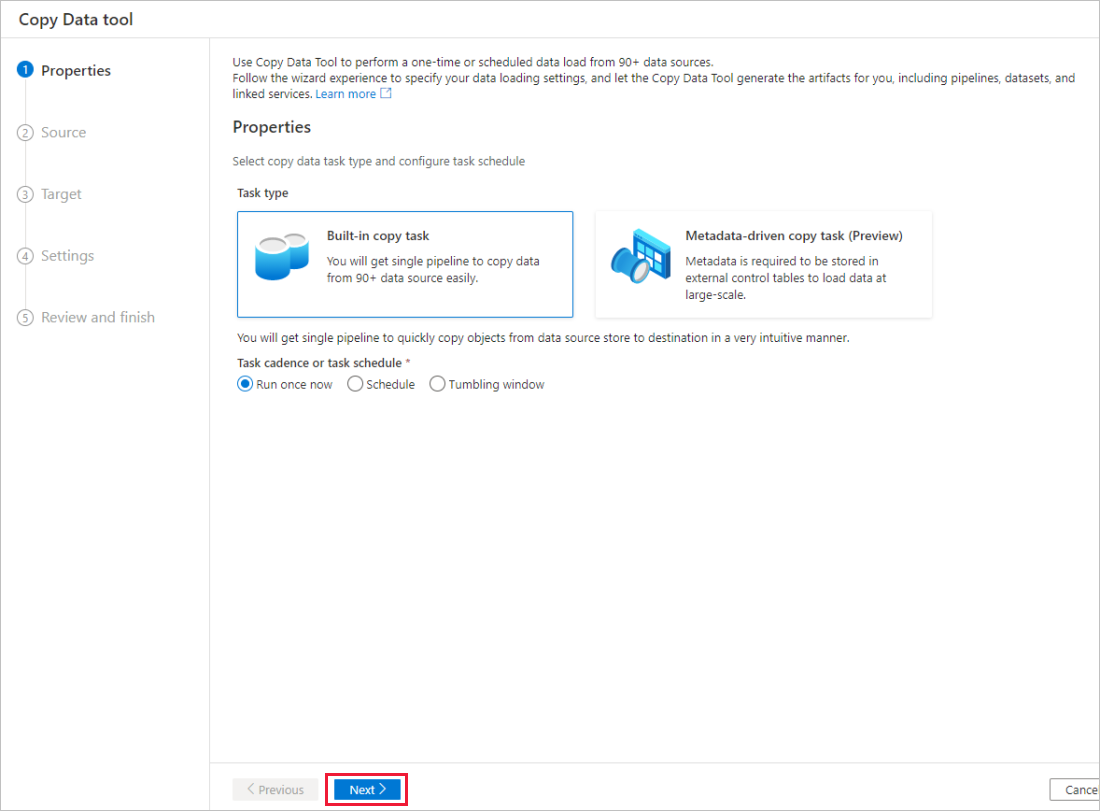
Wählen Sie auf der Seite Eigenschaften des Tools zum Kopieren von Daten unter Aufgabentyp den Typ Integrierte Kopieraufgabe aus, und wählen Sie dann Weiter aus.
Führen Sie auf der Seite Quelldatenspeicher die folgenden Schritte aus:
a) Wählen Sie + Neue Verbindung erstellen aus, um eine Verbindung hinzuzufügen.
b. Wählen Sie im Katalog Azure Blob Storage aus, und klicken Sie dann auf Fortsetzen.
c. Wählen Sie auf der Seite Neue Verbindung (Azure Blob Storage) in der Liste Azure-Abonnement Ihr Azure-Abonnement und in der Liste Speicherkontoname Ihr Speicherkonto aus. Testen Sie die Verbindung, und wählen Sie Fertig stellen aus.
d. Wählen Sie m Block Verbindung den neu erstellten verknüpften Dienst als Quelle aus.
e. Wählen Sie im Abschnitt Datei oder Ordner die Option Durchsuchen aus, um zum Ordner adfv2tutorial zu navigieren, wählen Sie die Datei inputEmp.txt aus, und klicken Sie dann auf OK.
f. Wählen Sie Weiter aus, um mit dem nächsten Schritt fortzufahren.
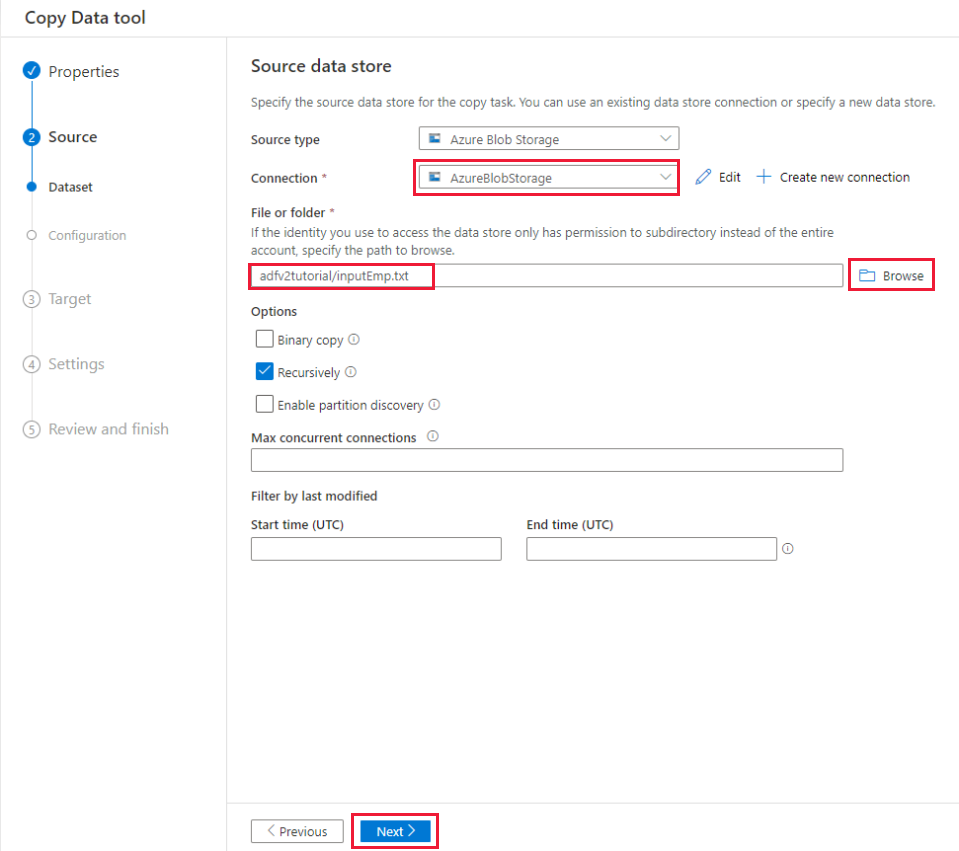
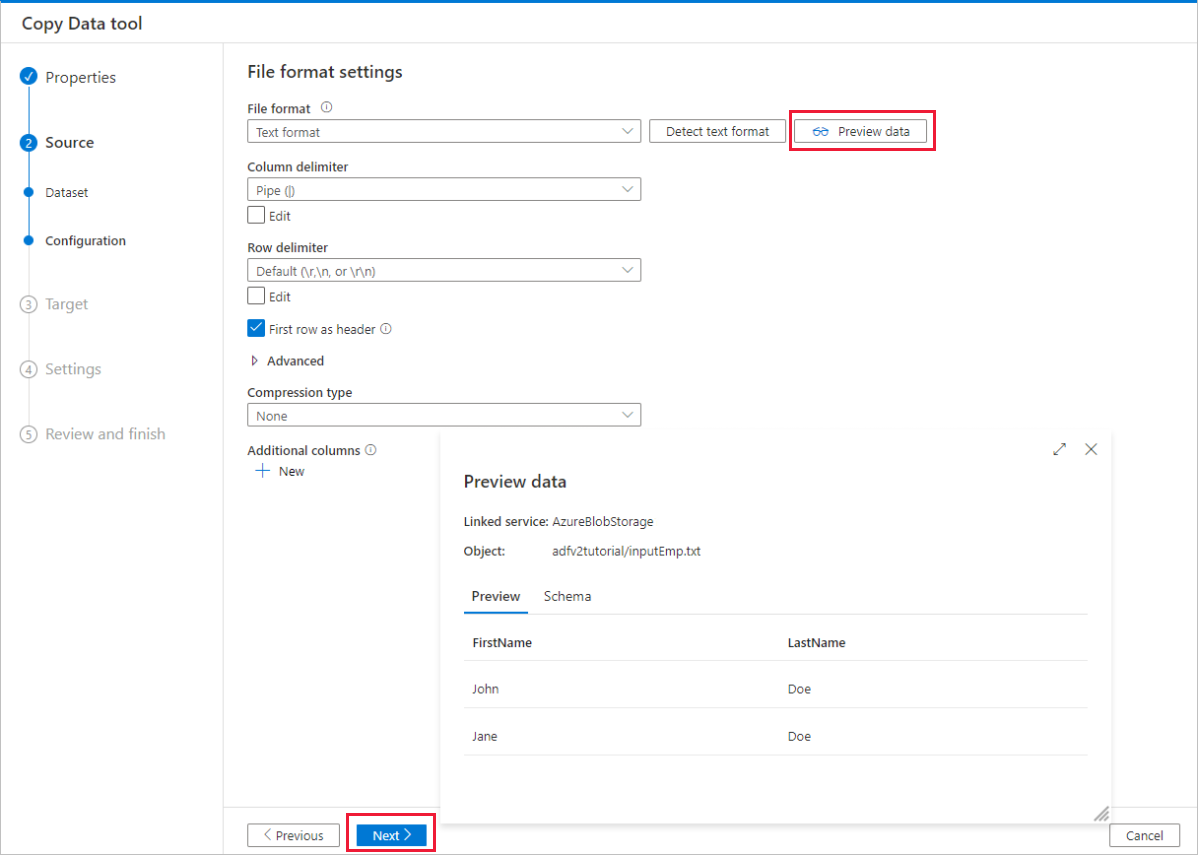
Aktivieren Sie auf der Seite File format settings (Dateiformateinstellungen) das Kontrollkästchen Erste Zeile als Header verwenden. Beachten Sie, dass das Tool die Spalten- und Zeilentrennzeichen automatisch erkennt, und Sie eine Vorschau der Daten und das Schema der Eingabedaten anzeigen können, indem Sie auf dieser Seite die Schaltfläche Datenvorschau auswählen. Wählen Sie Weiteraus.
Führen Sie auf der Seite Zieldatenspeicher die folgenden Schritte aus:
a) Wählen Sie + Neue Verbindung erstellen aus, um eine Verbindung hinzuzufügen.
b. Wählen Sie im Katalog Azure SQL-Datenbank und dann Weiter aus.
c. Wählen Sie auf der Seite Neue Verbindung (Azure SQL-Datenbank) in der Dropdownliste Ihr Azure-Abonnement, den Servernamen und den Datenbanknamen aus. Wählen Sie dann unter SQL Authentifizierungstyp die Option SQL-Authentifizierung aus, und geben Sie den Benutzernamen und das Kennwort an. Testen Sie die Verbindung, und wählen Sie Erstellen aus.
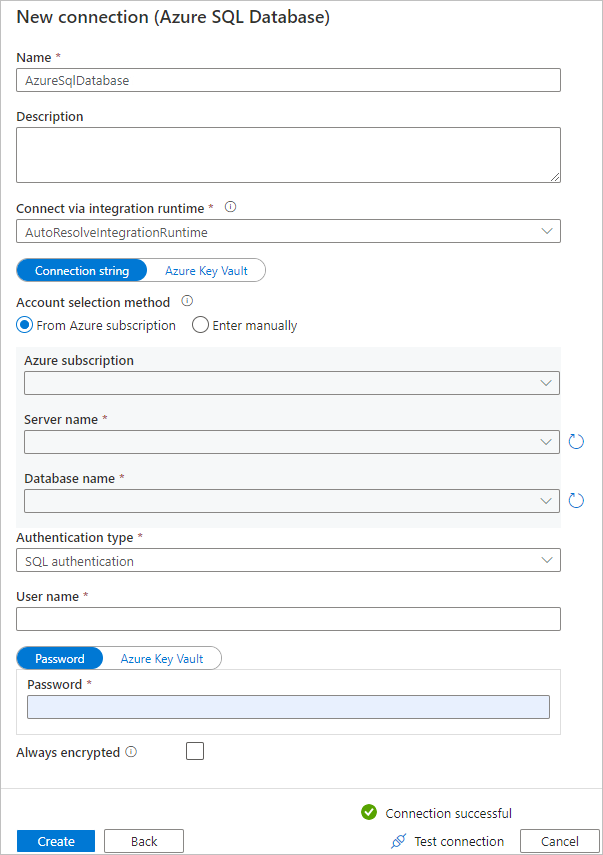
d. Wählen Sie den neu erstellten verknüpften Dienst als Senke und anschließend Weiter aus.
Wählen Sie auf der Seite ZieldatenspeichersVorhandene Tabelle verwenden aus und wählen Sie die
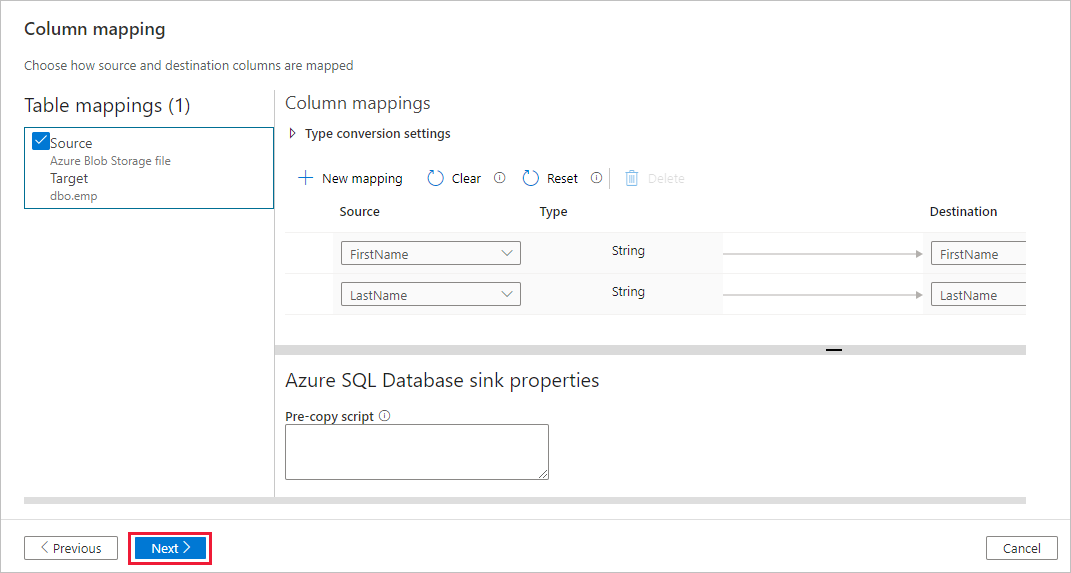
dbo.empTabelle aus. Wählen Sie Weiteraus.Auf der Seite Spaltenzuordnung sehen Sie, dass die zweite und dritte Spalte in der Eingabedatei den Spalten FirstName und LastName der Tabelle emp zugeordnet werden. Passen Sie die Zuordnung an, um sicherzustellen, dass sie keine Fehler enthält, und wählen Sie anschließend Weiter aus.
Geben Sie auf der Seite Einstellungen unter Taskname den Namen CopyFromBlobToSqlPipeline ein, und klicken Sie dann auf Weiter.
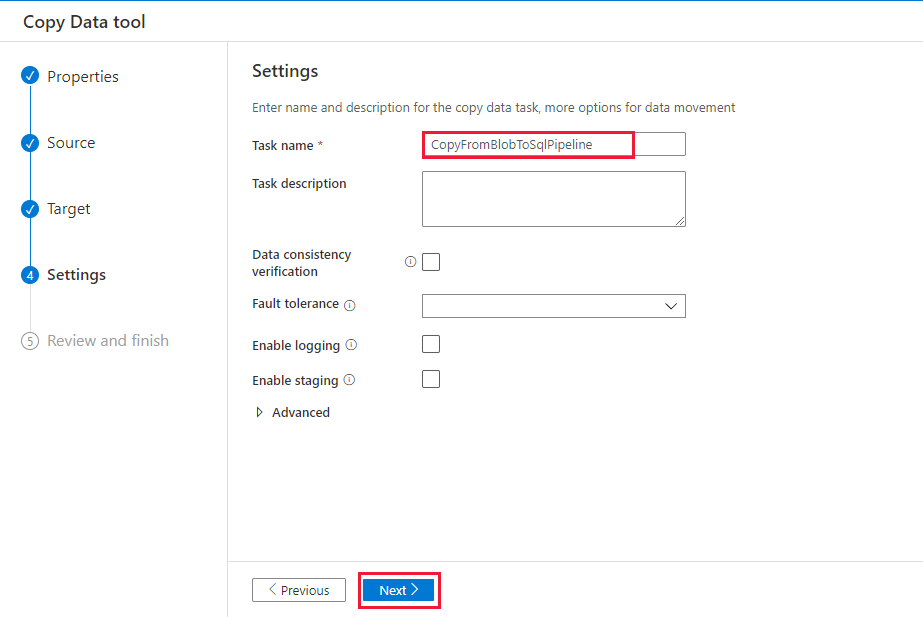
Überprüfen Sie auf der Seite Zusammenfassung die Einstellungen, und klicken Sie anschließend auf Weiter.
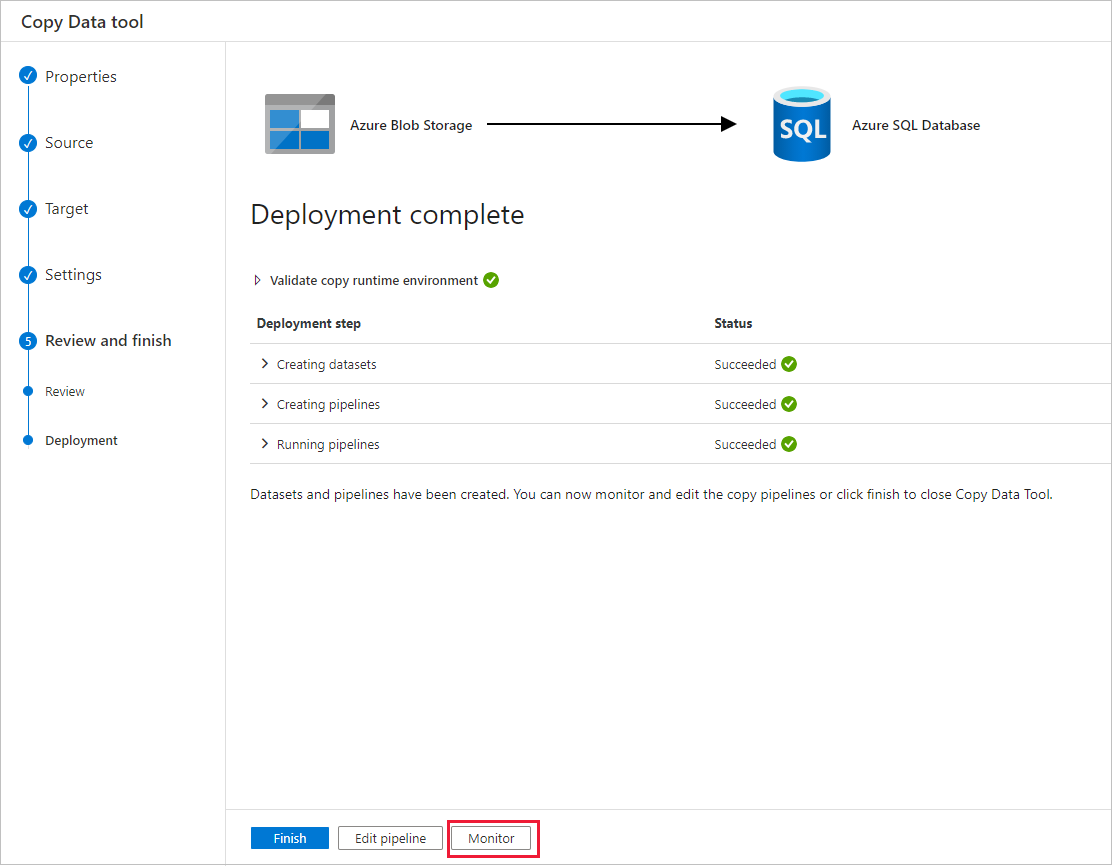
Klicken Sie auf der Seite Bereitstellung auf Überwachen, um die Pipeline (Task) zu überwachen.
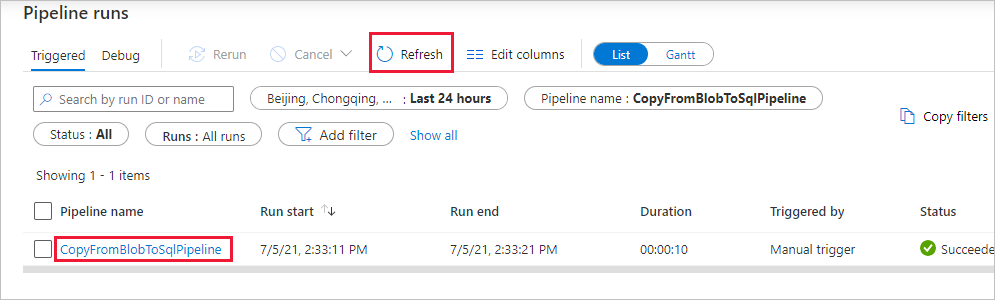
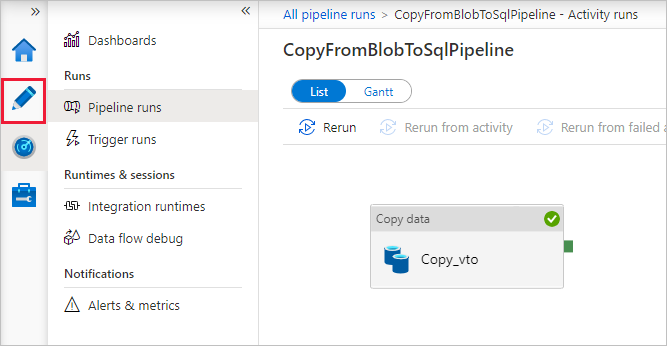
Wählen Sie auf der Seite „Pipelineausführungen“ die Option Aktualisieren aus, um die Liste zu aktualisieren. Wählen Sie den Link unter Pipelinename aus, um Details zur Aktivitätsausführung anzuzeigen oder die Pipeline erneut auszuführen.
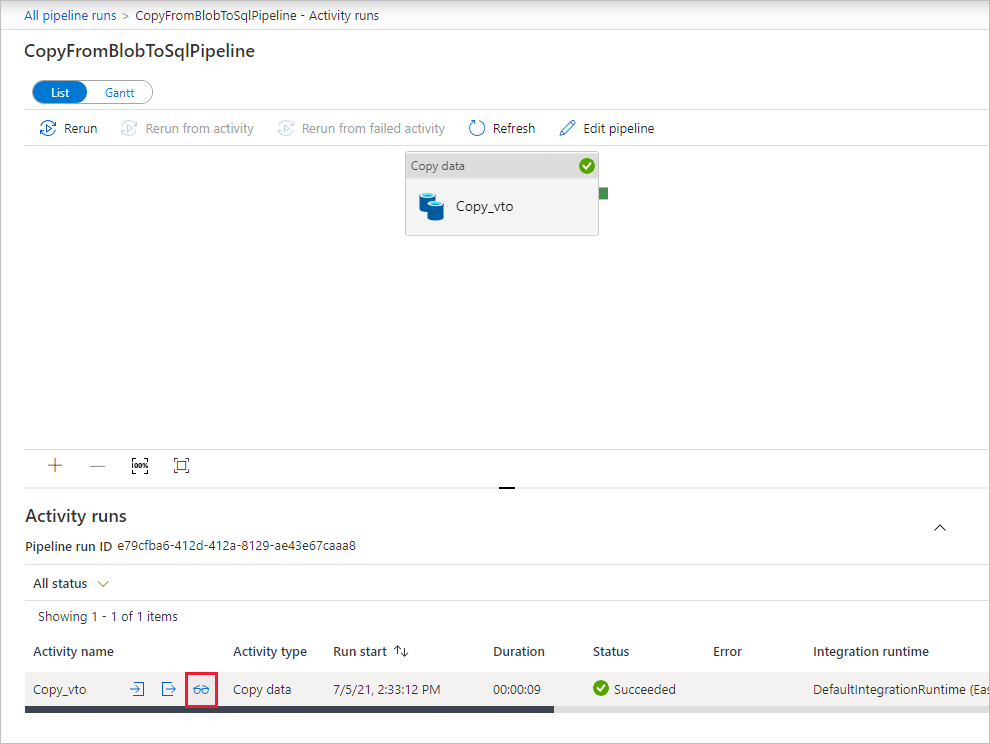
Wählen Sie auf der Seite „Aktivitätsausführungen“ unter der Spalte Aktivitätsname den Link Details (Brillensymbol) aus, um weitere Details zum Kopiervorgang anzuzeigen. Wählen Sie im Breadcrumb-Menü den Link Alle Pipelineausführungen aus, um zur Ansicht „Pipelineausführungen“ zurückzukehren. Klicken Sie zum Aktualisieren der Ansicht auf Aktualisieren.
Vergewissern Sie sich, dass die Daten in die Tabelle dbo.emp in Ihrer SQL-Datenbank eingefügt werden.
Klicken Sie im linken Bereich auf die Registerkarte Autor, um in den Bearbeitungsmodus zu wechseln. Sie können die vom Tool erstellten verknüpften Dienste, Datasets und Pipelines mit dem Editor aktualisieren. Ausführliche Informationen zum Bearbeiten dieser Entitäten über die Data Factory-Benutzeroberfläche finden Sie in der Azure-Portal-Version dieses Tutorials.
Zugehöriger Inhalt
Die Pipeline in diesem Beispiel kopiert Daten aus Blob Storage in eine SQL-Datenbank. Sie haben Folgendes gelernt:
- Erstellen einer Data Factory.
- Verwenden Sie das Tool zum Kopieren von Daten, um eine Pipeline zu erstellen.
- Überwachen der Pipeline- und Aktivitätsausführungen.
Fahren Sie mit dem folgenden Tutorial fort, um zu erfahren, wie Sie Daten von einem lokalen Speicherort in die Cloud kopieren: