Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisiert werden, um auf neue Funktionen in der Datenwissenschaft, Echtzeitanalysen und Berichterstellung zuzugreifen.
Wenn Sie neu bei Azure Data Factory sind, lesen Sie Einführung in Azure Data Factory.
In diesem Lernprogramm verwenden Sie den Datenflussbereich, um Datenflüsse zu erstellen, mit denen Sie Daten in Azure Data Lake Storage (ADLS) Gen2 analysieren und transformieren und in Delta Lake speichern können.
Voraussetzungen
- Azure-Abonnement. Wenn Sie kein Azure-Abonnement haben, erstellen Sie ein free Azure Konto, bevor Sie beginnen.
- Azure Speicherkonto. Sie verwenden den ADLS-Speicher als Quelldatenspeicher und Senkendatenspeicher. Wenn Sie nicht über ein Speicherkonto verfügen, lesen Sie Erstellen eines Azure-Speicherkontos, um die Schritte zur Erstellung eines solchen Kontos zu erfahren.
Die Datei, die wir in diesem Tutorial transformieren, heißt „moviesDB.csv“ und ist hier zu finden. Um die Datei aus GitHub abzurufen, kopieren Sie den Inhalt in einen Text-Editor Ihrer Wahl, um lokal als .csv Datei zu speichern. Informationen zum Hochladen der Datei in Ihr Speicherkonto finden Sie unter Upload-Blobs mit dem Azure Portal. In den Beispielen wird auf einen Container mit dem Namen „sample-data“ verwiesen.
Erstellen einer Data Factory
In diesem Schritt erstellen Sie eine Data Factory und öffnen die Data Factory-Benutzeroberfläche, um eine Pipeline in der Data Factory zu erstellen.
Öffnen Sie Microsoft Edge oder Google Chrome. Derzeit wird data Factory UI nur in den Webbrowsern Microsoft Edge und Google Chrome unterstützt.
Wählen Sie im Menü auf der linken Seite Ressource erstellen>Integration>Data Factory aus.
Geben Sie auf der Seite Neue Data Factory unter Name den Namen ADFTutorialDataFactory ein.
Wählen Sie das Azure Abonnement aus, in dem Sie die Data Factory erstellen möchten.
Führen Sie unter Ressourcengruppe einen der folgenden Schritte aus:
a) Wählen Sie Use existing (Vorhandene verwenden) aus und wählen Sie dann eine vorhandene Ressourcengruppe aus der Dropdown-Liste aus.
b. Wählen Sie Neu erstellen, und geben Sie den Namen einer Ressourcengruppe ein.
Weitere Informationen zu Ressourcengruppen finden Sie unter Ressourcengruppen zum Verwalten Ihrer Azure Ressourcen.
Wählen Sie unter Version die Option V2.
Wählen Sie unter Standort einen Standort für die Data Factory aus. In der Dropdownliste werden nur unterstützte Standorte angezeigt. Datenspeicher (z. B. Azure Storage und SQL-Datenbank) und Berechnungen (z. B. Azure HDInsight), die von der Datenfactory verwendet werden, können sich in anderen Regionen befinden.
Klicken Sie auf Erstellen.
Nach Abschluss der Erstellung wird der Hinweis im Benachrichtigungscenter angezeigt. Wählen Sie Zu Ressource wechseln aus, um zur Data Factory-Seite zu navigieren.
Wählen Sie Erstellen und überwachen aus, um die Data Factory-Benutzeroberfläche auf einer separaten Registerkarte zu starten.
Erstellen einer Pipeline mit einer Datenflussaktivität
In diesem Schritt erstellen Sie eine Pipeline mit einer Datenflussaktivität.
Wählen Sie auf der Startseite die Option Orchestrieren aus.
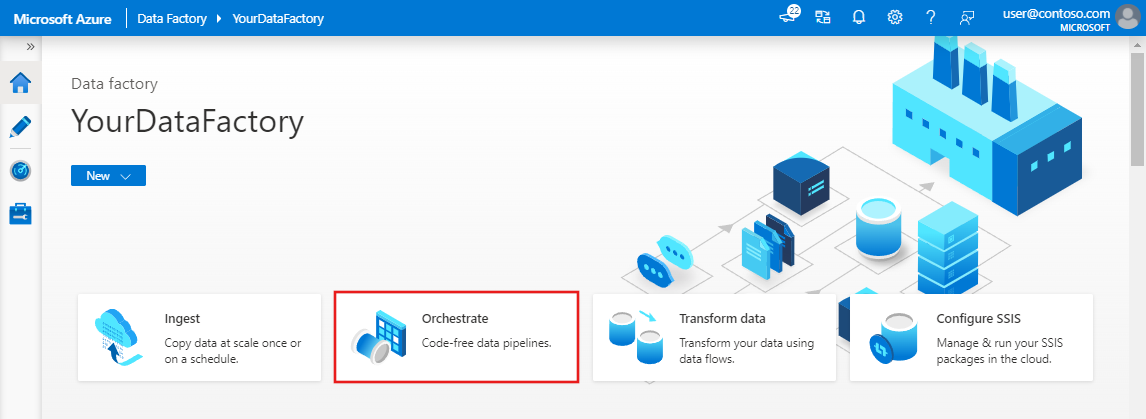
Geben Sie auf der Registerkarte Allgemein für den Namen der Pipeline DeltaLake ein.
Erweitern Sie im Bereich Aktivitäten das Akkordeon-Element Verschieben und transformieren. Ziehen Sie die Datenfluss-Aktivität per Drag & Drop aus dem Bereich auf die Pipelinecanvas.
Setzen Sie den Schieberegler Datenfluss debuggen in der oberen Pipeline-Canvas-Leiste auf „ein“. Der Debugmodus ermöglicht das interaktive Testen von Transformationslogik mit einem aktiven Spark-Cluster. Data Flow-Cluster benötigen 5 bis 7 Minuten zum Aufwärmen, und es wird empfohlen, dass die Benutzer zuerst das Debuggen aktivieren, wenn sie eine Data Flow-Entwicklung durchführen möchten. Weitere Informationen finden Sie unter Debugmodus.
Erstellen Sie Transformationslogik auf der Datenflussoberfläche
In diesem Tutorial generieren Sie zwei Datenflüsse. Der erste Datenfluss verläuft einfach von der Quelle zur Senke, um aus der CSV-Datei mit Filmen eine neue Delta Lake-Instanz zu generieren. Abschließend erstellen Sie den Datenflussentwurf, um Daten in Delta Lake zu aktualisieren.

Ziele des Tutorials
- Verwenden Sie als Quelle das Dataset „MoviesCSV“ aus den Voraussetzungen, und erstellen Sie damit eine neue Delta Lake-Instanz.
- Erstellen Sie die Logik zum Aktualisieren der Bewertungen für Filme aus dem Jahr 1988 auf „1“.
- Löschen Sie alle Filme aus dem Jahr 1950.
- Fügen Sie neue Filme für das Jahr 2021 hinzu, indem Sie die Filme aus dem Jahr 1960 duplizieren.
Beginnen Sie mit einer leeren Datenflussleinwand
Wählen Sie die Quelltransformation oben im Fenster des Datenfluss-Editors und dann + Neu neben der Eigenschaft Dataset im Fenster Quelleinstellungen aus:
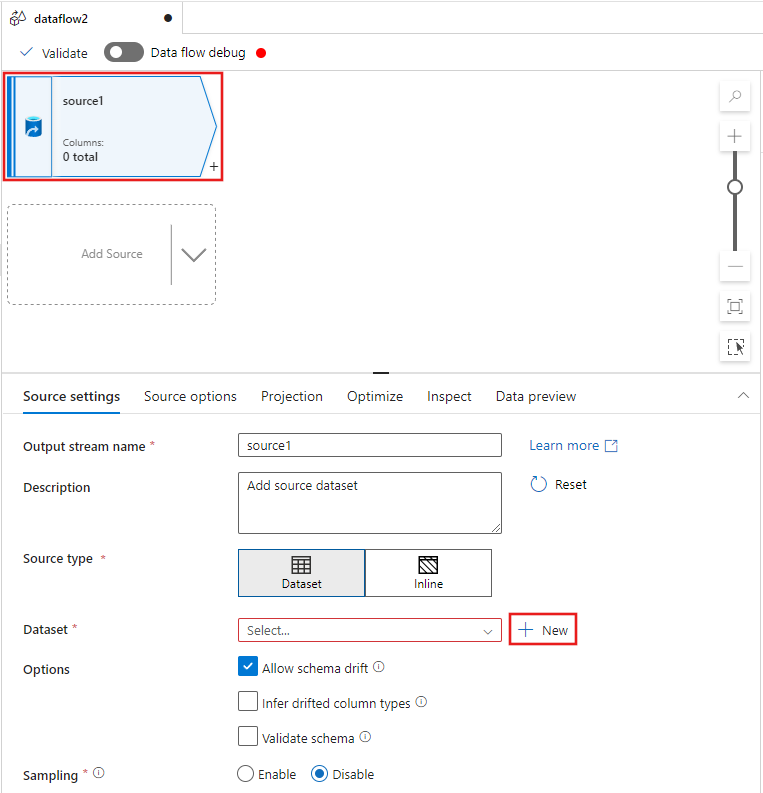
Wählen Sie Azure Data Lake Storage Gen2 aus dem angezeigten Neues Datasetfenster aus, und wählen Sie dann Continue aus.
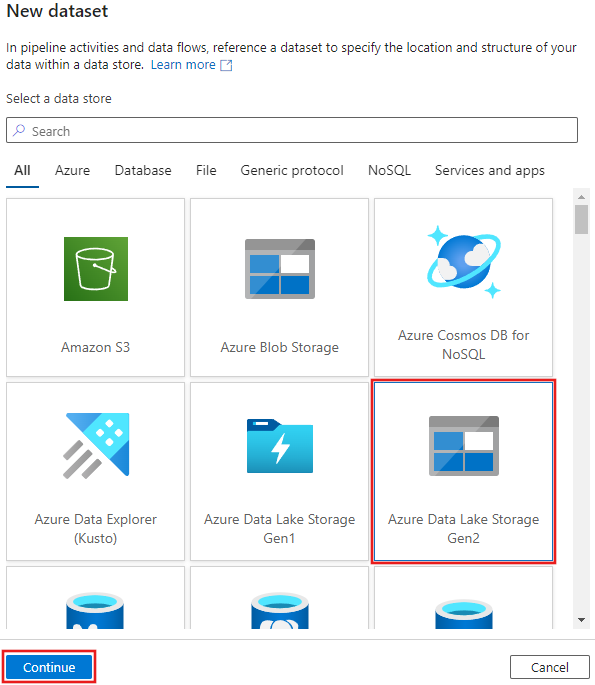
Wählen Sie DelimitedText als Datasettyp und dann erneut Weiter aus.

Geben Sie dem Dataset den Namen „MoviesCSV“, und wählen Sie unter Verknüpfter Dienst die Option + Neu aus, um einen neuen verknüpften Dienst für die Datei zu erstellen.
Geben Sie die Details für Ihr Speicherkonto an, das zuvor im Abschnitt „Voraussetzungen“ erstellt wurde, suchen Sie die hochgeladene Datei „MoviesCSV“, und wählen Sie sie aus.
Nachdem Sie Ihren verknüpften Dienst hinzugefügt haben, aktivieren Sie das Kontrollkästchen Erste Zeile als Überschrift, und wählen Sie dann OK aus, um die Quelle hinzuzufügen.
Navigieren Sie zur Registerkarte Projektion des Fensters mit den Datenflusseinstellungen, und wählen Sie dann Erkennen von Datentypen aus.
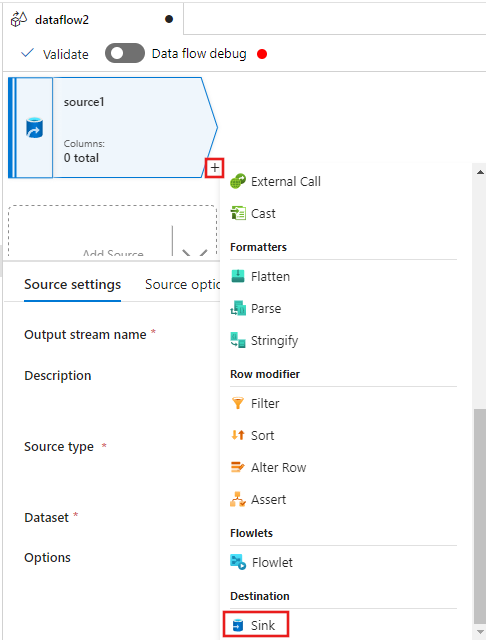
Wählen Sie nun das Pluszeichen (+) nach der Quelle im Fenster des Datenfluss-Editors aus, und scrollen Sie nach unten, um im Abschnitt Ziel die Option Senke auszuwählen. Dadurch fügen Sie dem Datenfluss eine neue Senke hinzu.
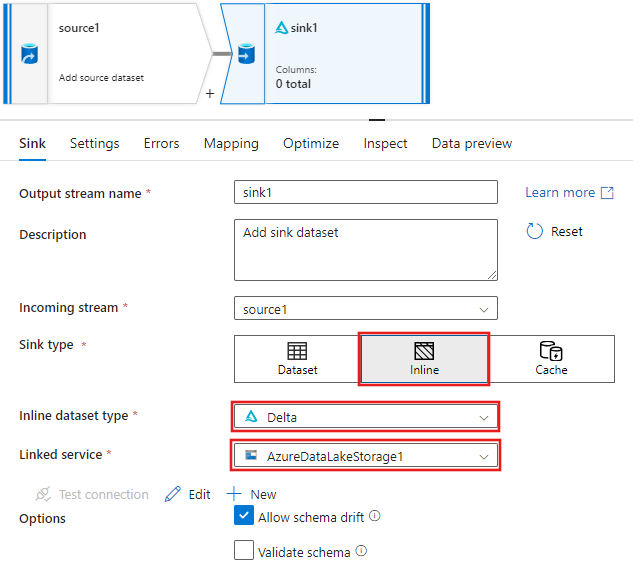
Wählen Sie auf der Registerkarte Senke für die Senkeneinstellungen, die nach dem Hinzufügen der Senke angezeigt werden, die Option Inline für Senkentyp und die Option Delta für Inlinedatasettyp aus. Wählen Sie dann Ihre Azure Data Lake Storage Gen2 für den Linked-Dienst aus.
Wählen Sie einen Ordnernamen in Ihrem Speichercontainer aus, in dem der Dienst die Delta Lake-Instanz erstellen soll.
Navigieren Sie schließlich zurück zum Pipeline-Designer, und wählen Sie Debuggen aus, um die Pipeline im Debugmodus mit nur dieser Datenflussaktivität auf der Canvas auszuführen. Dadurch wird Ihr neuer Delta Lake in Azure Data Lake Storage Gen2 generiert.
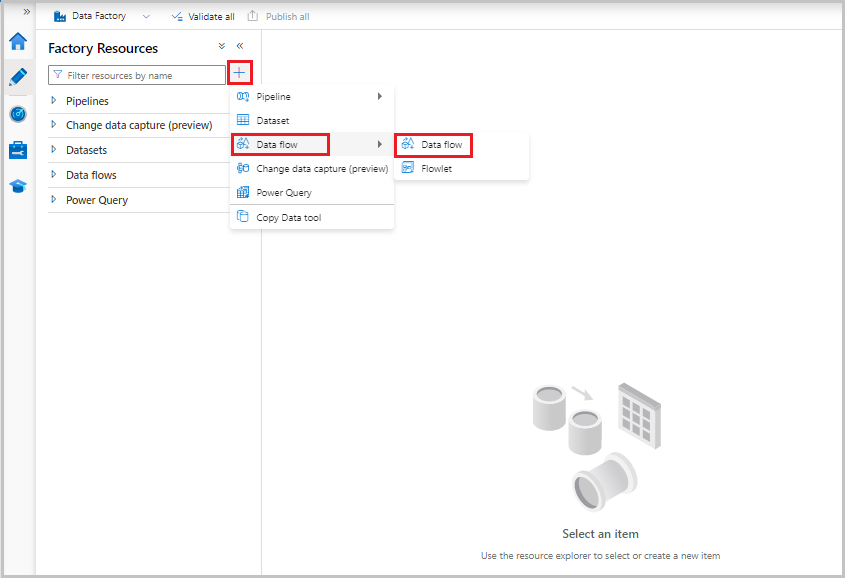
Wählen Sie nun im Menü „Factoryressourcen“ auf der linken Seite des Bildschirms + aus, um eine neue Ressource hinzuzufügen, und wählen Sie dann Datenfluss aus.
Wählen Sie wie zuvor erneut die Datei „MoviesCSV“ als Quelle aus, und wählen Sie dann wieder Erkennen von Datentypen auf der Registerkarte Projektion aus.
Wählen Sie dieses Mal nach dem Erstellen der Quelle + im Fenster des Datenfluss-Editors aus, und fügen Sie Ihrer Quelle eine Filtertransformation hinzu.
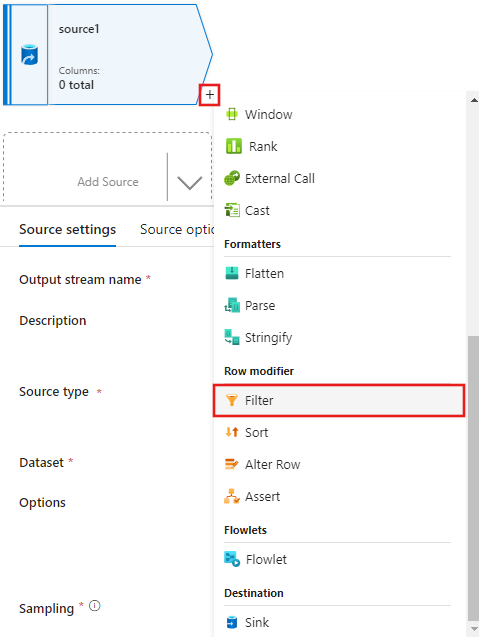
Fügen Sie die Bedingung Filtern nach im Fenster Filtereinstellungen hinzu, die nur Filmzeilen mit den Jahreszahlen 1950, 1960 und 1988 zulässt.
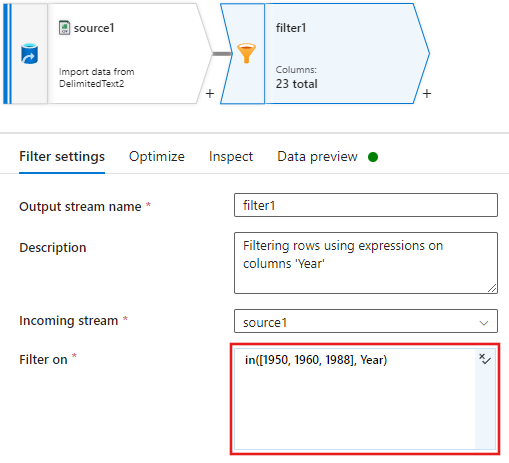
Fügen Sie nun eine Transformation vom Typ Abgeleitete Spalte hinzu, um Bewertungen für jeden Film aus dem Jahr 1988 in „1“ zu ändern.
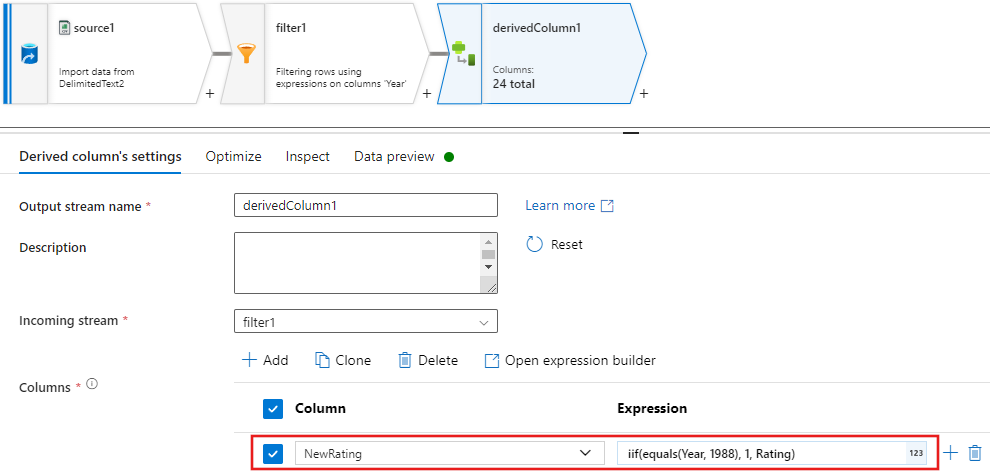
Die Richtlinien
Update, insert, delete, and upsertwerden in der Transformation zum Ändern von Zeilen erstellt. Fügen Sie nach der abgeleiteten Spalte eine Transformation zum Ändern von Zeilen hinzu.Die Richtlinien für Zeilenänderungen sollten wie folgt aussehen:

Nachdem Sie die richtige Richtlinie für jeden Zeilenänderungstyp festgelegt haben, überprüfen Sie, ob die richtigen Aktualisierungsregeln für die Senkentransformation festgelegt wurden.
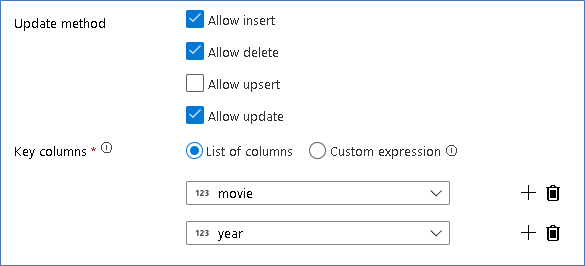
Hier verwenden Sie die Delta Lake-Senke für Ihre Data Lake-Instanz von Azure Data Lake Storage Gen2 und erlauben Einfügungen, Aktualisierungen und Löschungen.
Beachten Sie, dass es sich bei den Schlüsselspalten um einen zusammengesetzten Schlüssel handelt, der sich aus der Primärschlüsselspalte „movie“ und der Spalte „year“ zusammensetzt. Dies liegt daran, dass Sie „gefälschte“ Filme für das Jahr 2021 erstellt haben, indem Sie die Zeilen für das Jahr 1960 dupliziert haben. Dadurch werden Konflikte beim Suchen vorhandener Zeilen vermieden, da die Eindeutigkeit sichergestellt ist.
Herunterladen des vollständigen Beispiels
Hier finden Sie eine Beispiellösung für die Delta-Pipeline mit einem Datenfluss für das Aktualisieren/Löschen von Zeilen im Lake.
Zugehöriger Inhalt
Erfahren Sie mehr über die Ausdruckssprache für Datenflüsse.