Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Tutorial verwenden Sie das Azure-Portal, um eine Data Factory zu erstellen. Anschließend verwenden Sie das Tool zum Kopieren von Daten, um eine Pipeline zu erstellen, die neue und geänderte Dateien inkrementell von einem in den anderen Azure-Blobspeicher kopiert. Hierbei wird LastModifiedDate verwendet, um die zu kopierenden Dateien zu bestimmen.
Nachdem Sie die hier beschriebenen Schritte ausgeführt haben, überprüft Azure Data Factory alle Dateien im Quellspeicher, wendet den Filter über LastModifiedDate an und kopiert nur diejenigen Dateien in den Zielspeicher, die seit dem letzten Mal neu erstellt oder aktualisiert wurden. Beachten Sie, dass Data Factory zum Überprüfen einer großen Anzahl von Dateien dennoch sehr viel Zeit benötigt. Die Dateiüberprüfung ist sehr zeitintensiv – selbst dann, wenn die Menge der kopierten Daten verringert wird.
Hinweis
Falls Sie noch nicht mit Data Factory vertraut sind, ist es ratsam, den Artikel Einführung in Azure Data Factory zu lesen.
Dieses Tutorial umfasst folgende Aufgaben:
- Erstellen einer Data Factory.
- Erstellen einer Pipeline mithilfe des Tools zum Kopieren von Daten
- Überwachen der Pipeline- und Aktivitätsausführungen.
Voraussetzungen
- Azure-Abonnement: Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
- Azure Storage-Konto: Verwenden Sie den Blobspeicher als Quell- und als Senkendatenspeicher. Falls Sie noch nicht über ein Azure Storage-Konto verfügen, finden Sie hier eine Anleitung zum Erstellen eines Speicherkontos.
Erstellen von zwei Containern im Blobspeicher
Bereiten Sie Ihren Blobspeicher folgendermaßen für das Tutorial vor:
Erstellen Sie einen Container mit dem Namen source (Quelle). Sie können für diese Aufgabe verschiedene Tools verwenden, z. B. Azure Storage-Explorer.
Erstellen Sie einen Container mit dem Namen destination (Ziel).
Erstellen einer Data Factory
Wählen Sie im oberen Menü die Option "Resource>Analytics>Data Factory erstellen" aus:
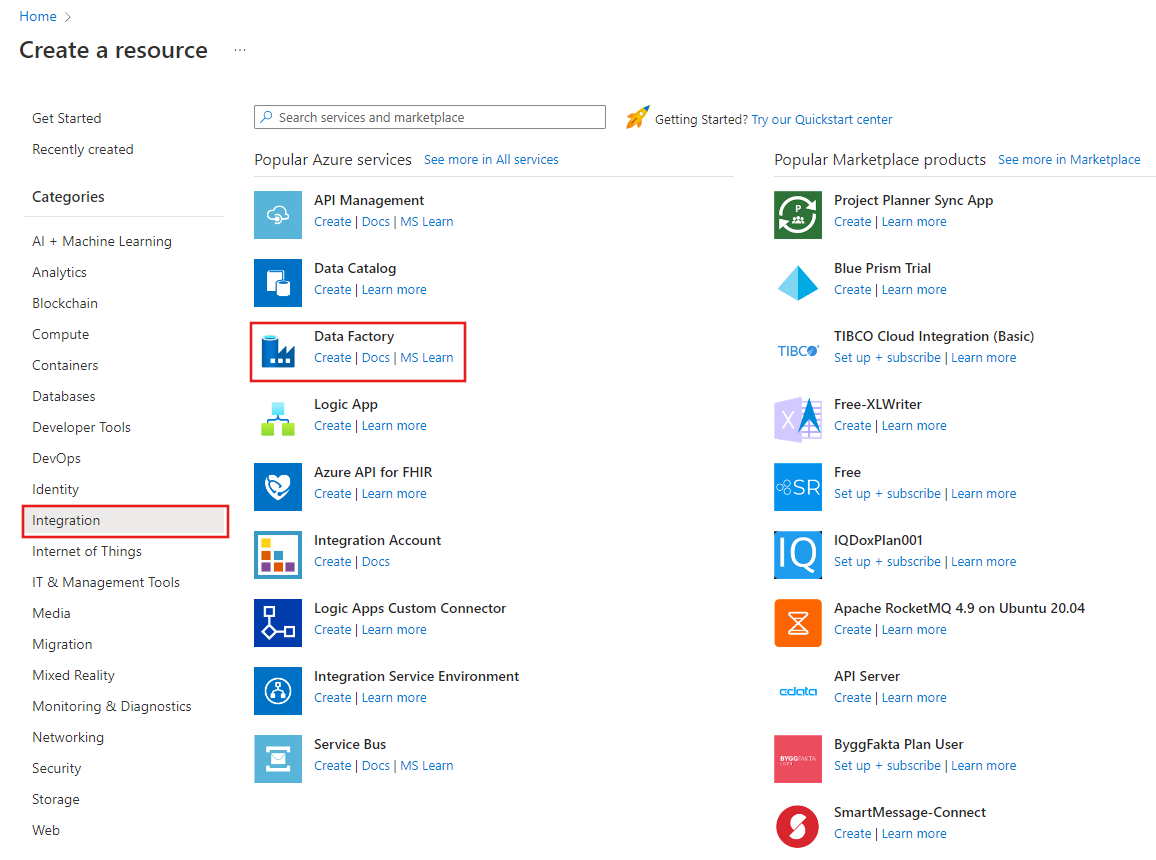
Geben Sie auf der Seite Neue Data Factory unter Name den Namen ADFTutorialDataFactory ein.
Der Name der Data Factory muss global eindeutig sein. Möglicherweise wird diese Fehlermeldung angezeigt:
Wenn eine Fehlermeldung zum Namenswert angezeigt wird, geben Sie einen anderen Namen für die Data Factory ein. Verwenden Sie beispielsweise den Namen IhrNameADFTutorialDataFactory. Benennungsregeln für Data Factory-Artefakte finden Sie im Thema Data Factory – Benennungsregeln.
Wählen Sie unter Abonnement das Azure-Abonnement aus, in dem Sie die neue Data Factory erstellen werden.
Führen Sie unter Ressourcengruppe einen der folgenden Schritte aus:
Wählen Sie die Option Vorhandene verwenden und dann in der Liste eine vorhandene Ressourcengruppe aus.
Wählen Sie Neu erstellen aus, und geben Sie einen Namen für die Ressourcengruppe ein.
Weitere Informationen zu Ressourcengruppen finden Sie unter Verwenden von Ressourcengruppen zum Verwalten von Azure-Ressourcen.
Wählen Sie unter Version die Option V2.
Wählen Sie unter Standort den Standort für die Data Factory aus. In der Liste werden nur unterstützte Standorte angezeigt. Die von der Data Factory genutzten Datenspeicher (z. B. Azure Storage und Azure SQL-Datenbank) und Computeressourcen (z. B. Azure HDInsight) können sich an anderen Standorten und in anderen Regionen befinden.
Klicken Sie auf Erstellen.
Nachdem die Data Factory erstellt wurde, wird die Startseite für die Data Factory angezeigt.
Zum Öffnen der Azure Data Factory-Benutzeroberfläche wählen Sie auf der Kachel Open Azure Data Factory Studio die Option Öffnen aus.

Erstellen einer Pipeline mithilfe des Tools zum Kopieren von Daten
Wählen Sie auf der Azure Data Factory-Homepage die Kachel Erfassen, um das Tool zum Kopieren der Daten zu öffnen.
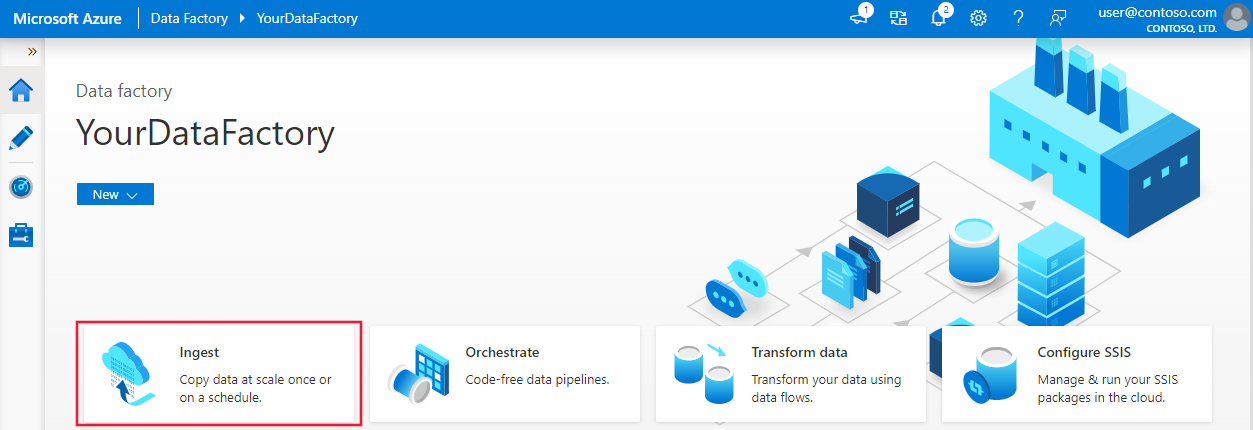
Gehen Sie auf der Seite Properties (Eigenschaften) wie folgt vor:
Wählen Sie unter Task type (Aufgabentyp) Built-in copy task (Integrierte Kopieraufgabe) aus.
Wählen Sie unter Task cadence or task schedule (Aufgabenhäufigkeit oder Aufgabenzeitplan) Tumbling window (Rollierendes Fenster) aus.
Geben Sie unter Wiederholung den Wert 15 Minuten ein.
Wählen Sie Weiter aus.
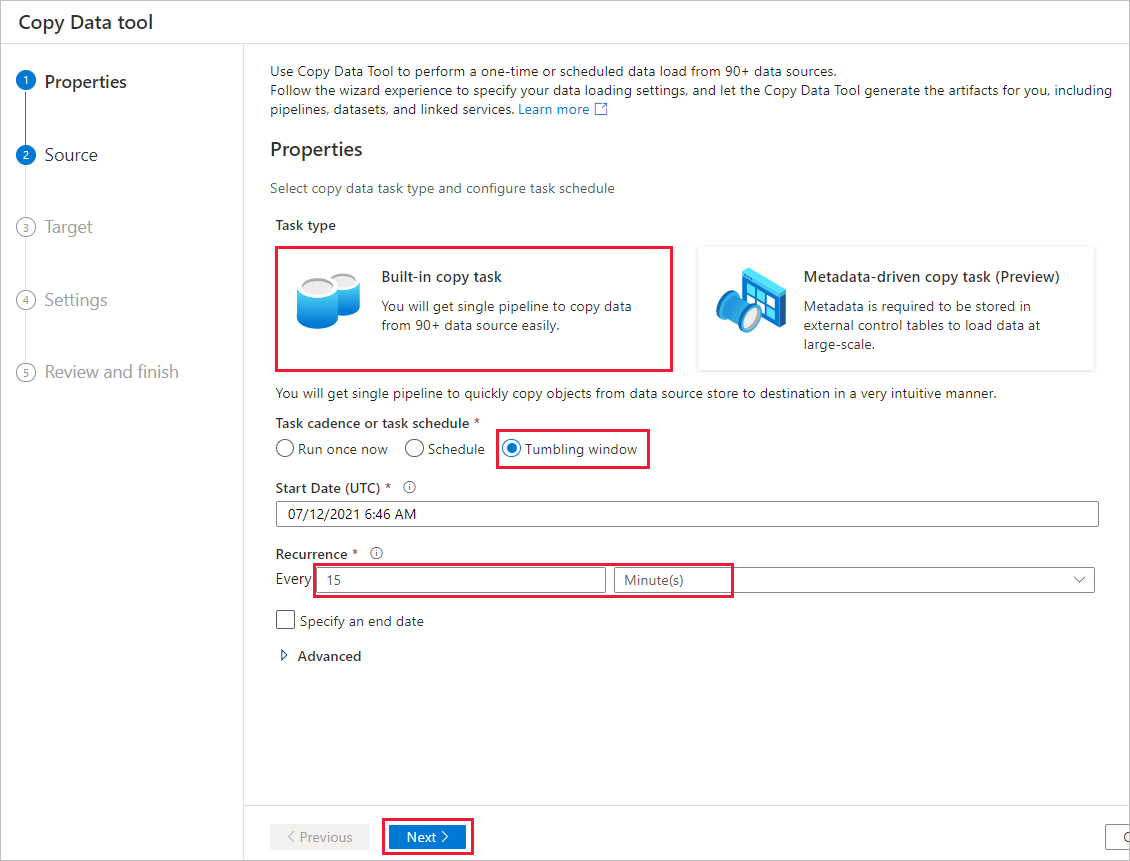
Führen Sie auf der Seite Quelldatenspeicher die folgenden Schritte aus:
Wählen Sie + Neue Verbindung aus, um eine Verbindung hinzuzufügen.
Wählen Sie im Katalog Azure Blob Storage aus, und klicken Sie dann auf Weiter:

Wählen Sie auf der Seite Neue Verbindung (Azure Blob Storage) in der Liste Azure-Abonnement Ihr Azure-Abonnement und in der Liste Speicherkontoname Ihr Speicherkonto aus. Testen Sie die Verbindung, und klicken Sie auf Erstellen.
Wählen Sie im Block Verbindung die neu erstellte Verbindung aus.
Wählen Sie im Abschnitt File or folder (Datei oder Ordner) Browse (Durchsuchen) und wählen sie den Ordner source (Quelle) aus. Wählen Sie anschließend OK.
Wählen Sie unter File loading behavior (Dateiladeverhalten) Incremental load: LastModifiedDate (Inkrementelles Laden: LastModifiedDate) aus und wählen Sie anschließend Binary copy (Binärkopie) aus.
Wählen Sie Weiter aus.
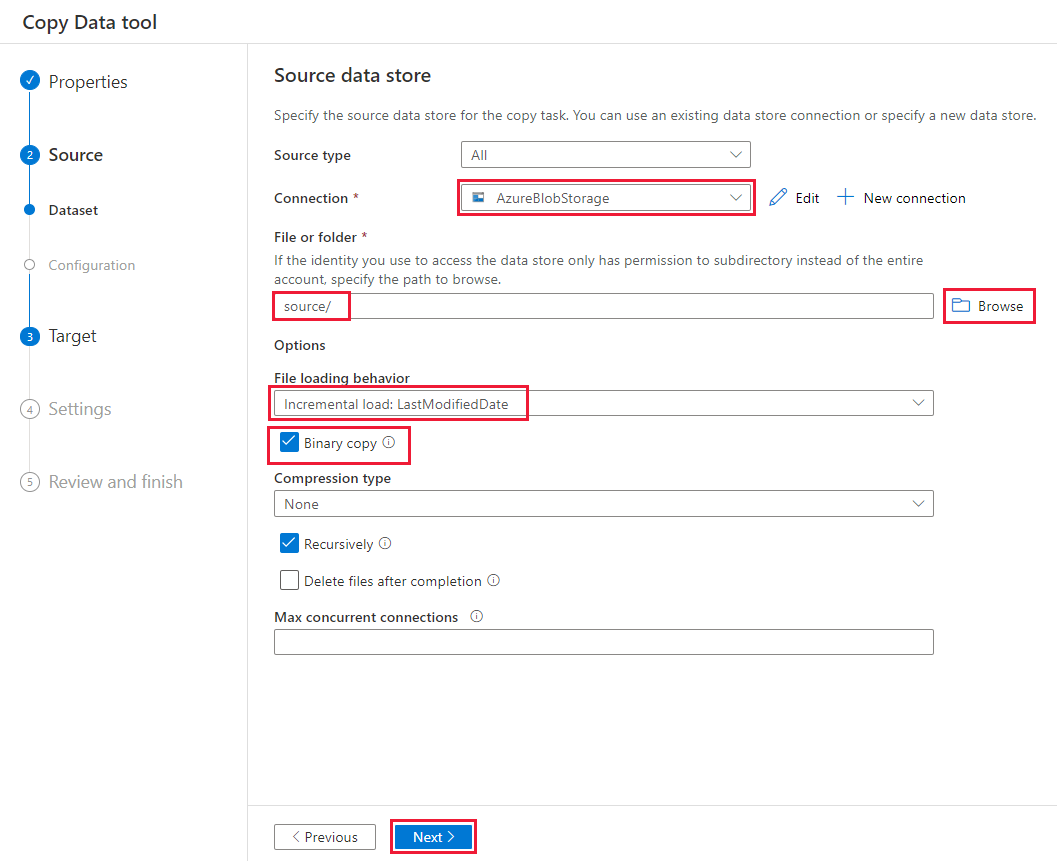
Führen Sie auf der Seite Destination data store (Zieldatenspeicher) die folgenden Schritte aus:
Wählen Sie die AzureBlobStorage-Verbindung aus, die Sie erstellt haben. Dies ist dasselbe Speicherkonto wie der Quelldatenspeicher.
Suchen Sie im Abschnitt Folder path (Ordnerpfad) nach dem Ordner destination (Ziel), wählen Sie ihn aus und klicken Sie anschließend auf OK.
Wählen Sie Weiter aus.
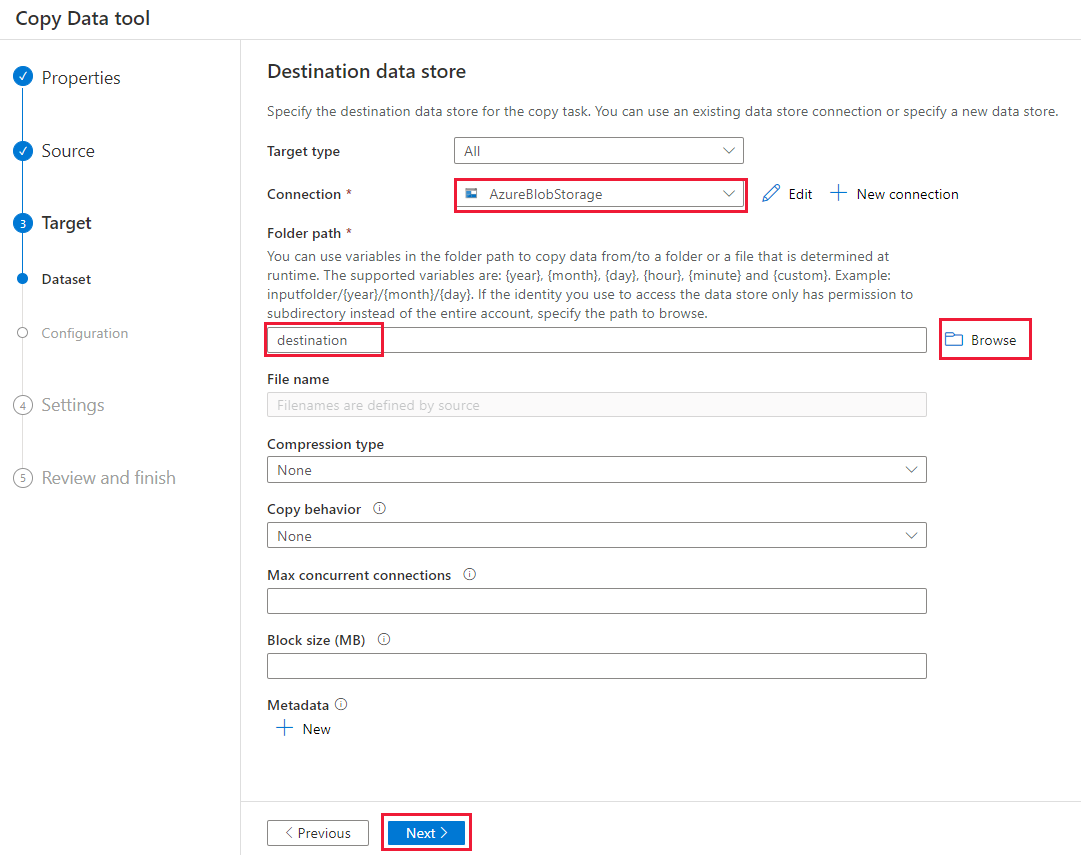
Geben Sie auf der Seite Einstellungen unter Taskname den Namen DeltaCopyFromBlobPipeline ein, und klicken Sie dann auf Weiter. Über die Data Factory-Benutzeroberfläche wird eine Pipeline mit dem angegebenen Aufgabennamen erstellt.
Überprüfen Sie auf der Seite Zusammenfassung die Einstellungen, und klicken Sie anschließend auf Weiter.
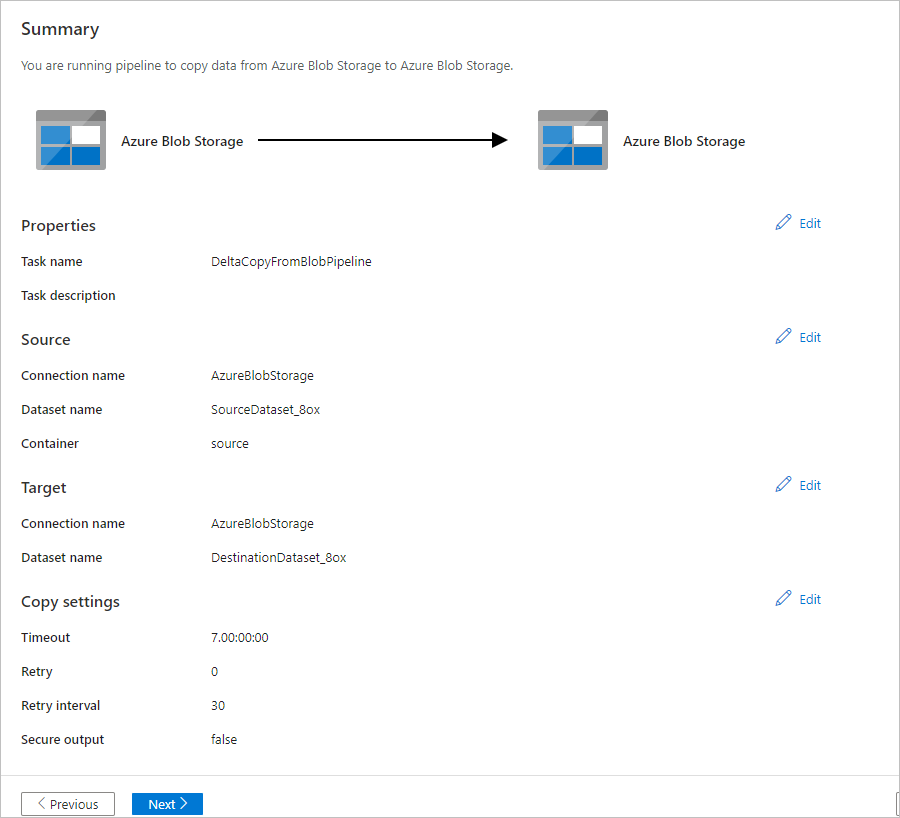
Wählen Sie auf der Seite Bereitstellung die OptionÜberwachen aus, um die Pipeline (Aufgabe) zu überwachen.
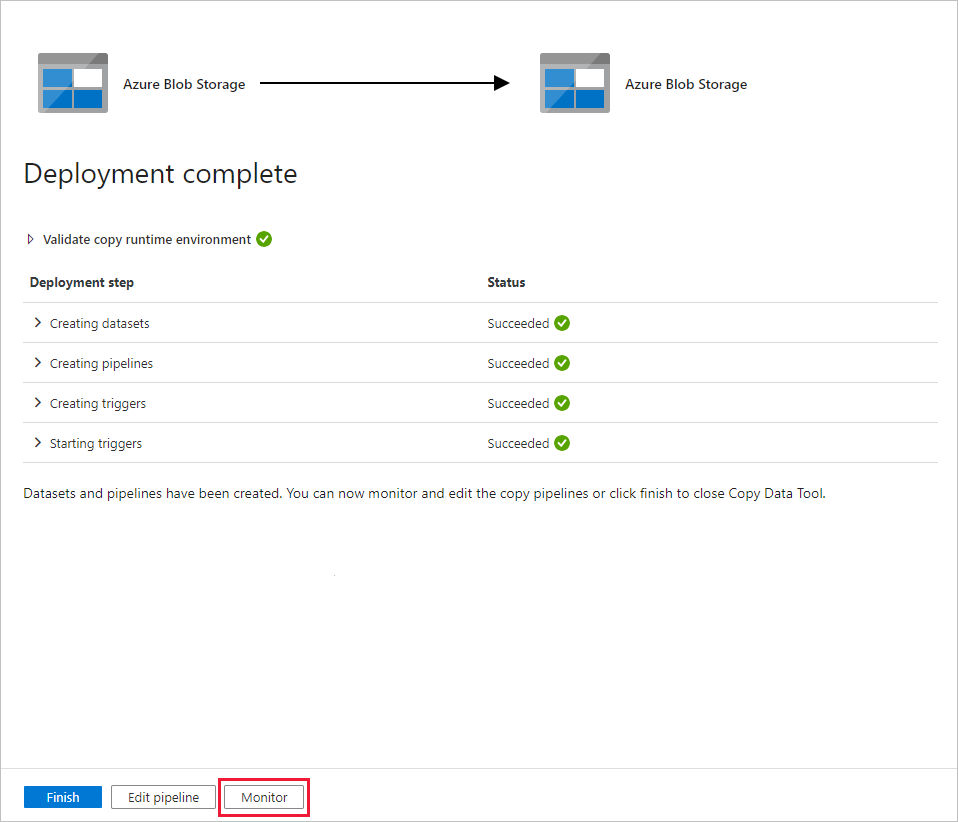
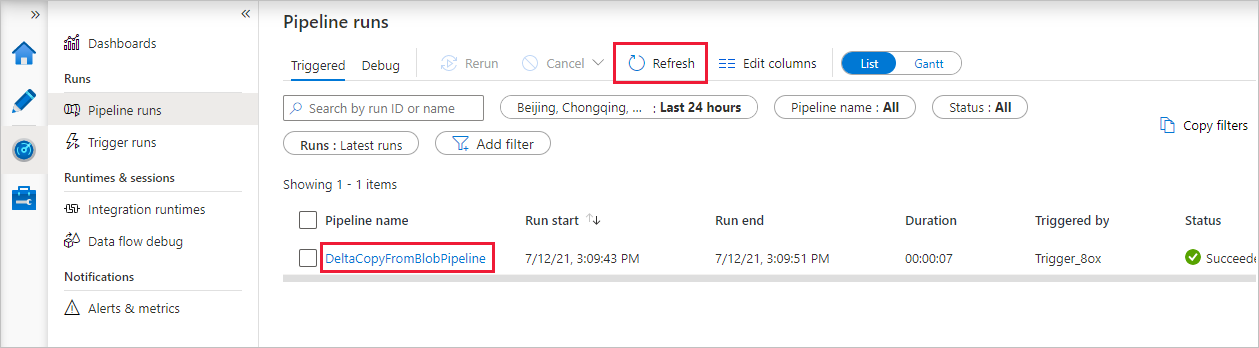
Beachten Sie, dass die Registerkarte Überwachen auf der linken Seite automatisch ausgewählt ist. Die Anwendung wechselt zur Registerkarte Überwachen. Dort wird der Status der Pipeline angezeigt. Klicken Sie zum Aktualisieren der Liste auf Aktualisieren. Klicken Sie auf den Link unter Pipelinename, um Details zur Aktivitätsausführung anzuzeigen oder die Pipeline erneut auszuführen.
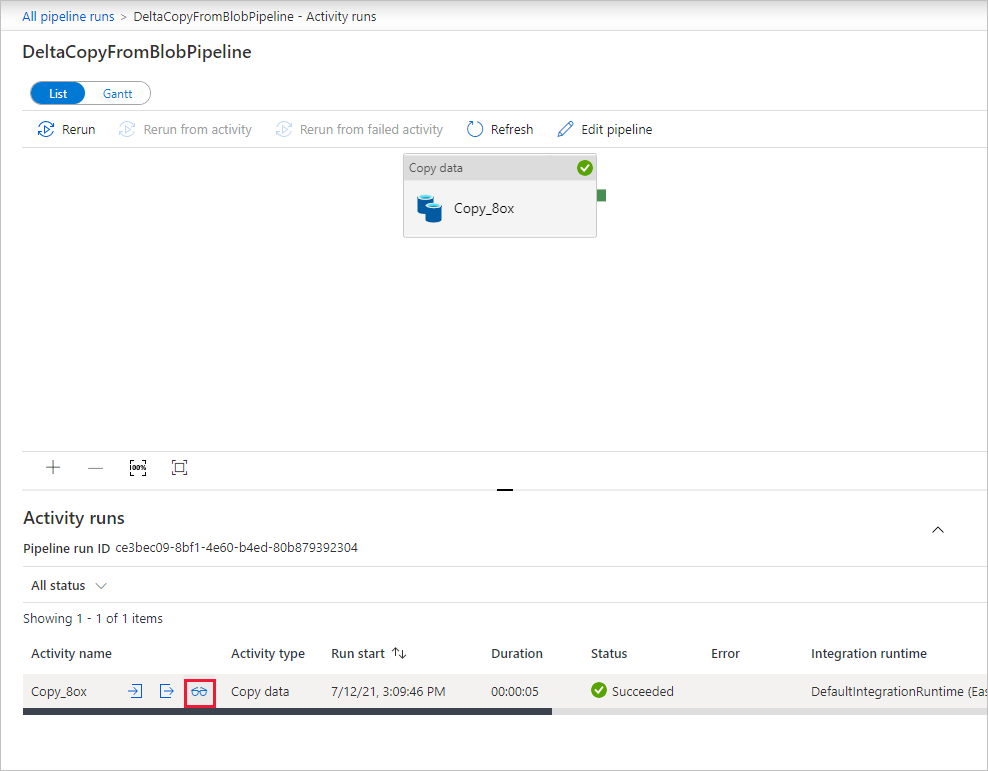
Da die Pipeline nur eine Aktivität (die Kopieraktivität) enthält, wird nur ein Eintrag angezeigt. Wenn Sie Details zum Kopiervorgang anzeigen möchten, wählen Sie auf der Seite Activity runs (Aktivitätsausführungen) den Link Details (das Brillensymbol) aus der Spalte Activity name (Aktivitätsname) aus. Einzelheiten zu den Eigenschaften finden Sie in der Übersicht zur Kopieraktivität.
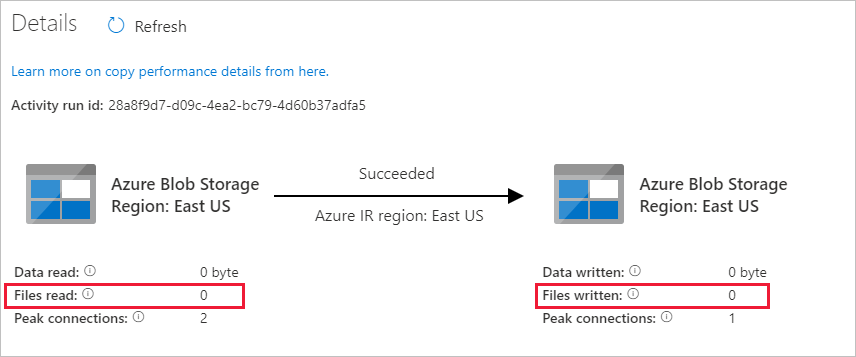
Da sich im Quellcontainer in Ihrem Blobspeicherkonto keine Datei befindet, wird in Ihrem Blobspeicherkonto keine Datei angezeigt, die in den Zielcontainer kopiert wurde:
Erstellen Sie eine leere Textdatei, und nennen Sie sie file1.txt. Laden Sie diese Textdatei in den Quellcontainer in Ihrem Speicherkonto hoch. Sie können für diese Aufgaben verschiedene Tools verwenden, beispielsweise Azure Storage-Explorer.
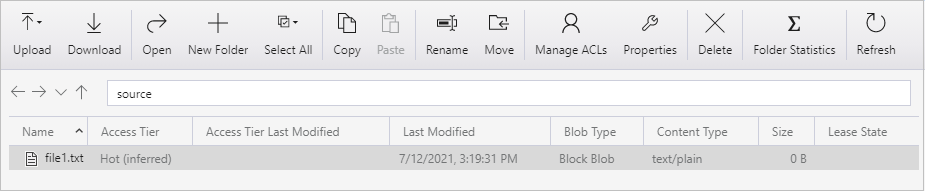
Wenn Sie zur Ansicht Pipelineausführungen zurückkehren möchten, wählen Sie den Link Alle Pipelineausführungen im Breadcrumb-Menü auf der Seite Aktivitätsausführungen aus, und warten Sie, bis dieselbe Pipeline erneut automatisch ausgelöst wird.
Wenn die zweite Pipelineausführung abgeschlossen ist, führen Sie die zuvor genannten Schritte aus, um die Details zur Aktivitätsausführung zu überprüfen.
Sie werden sehen, dass eine Datei („file1.txt“) aus dem Quellcontainer in den Zielcontainer Ihres Blobspeicherkontos kopiert wurde:
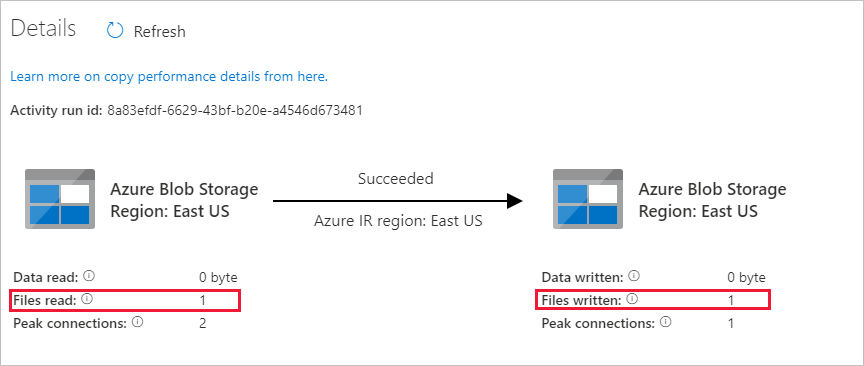
Erstellen Sie eine weitere leere Textdatei, und benennen Sie diese file2.txt. Laden Sie diese Textdatei in den Quellcontainer in Ihrem Blobspeicherkonto hoch.
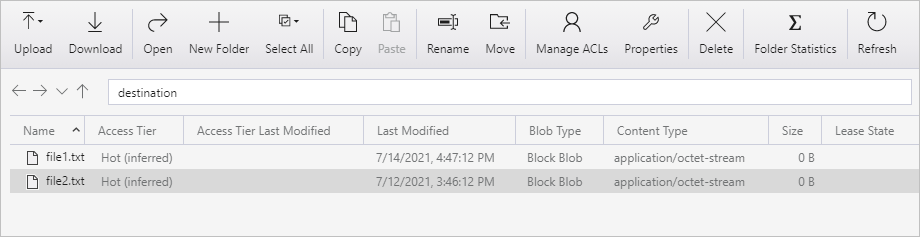
Wiederholen Sie die Schritte 11 und 12 für die zweite Textdatei. Sie werden bemerken, dass nur die neue Datei („file2.txt“) bei der nächsten Pipelineausführung vom Quellcontainer in den Zielcontainer Ihres Speicherkontos kopiert wurde.
Sie können dies auch bestätigen, indem Sie die Dateien mit dem Azure Storage-Explorer überprüfen:
Zugehöriger Inhalt
Fahren Sie mit dem nächsten Tutorial fort, um zu erfahren, wie Sie mithilfe eines Apache Spark-Clusters in Azure Daten transformieren: