Verwalten des Lebenszyklus von Modellen mithilfe der Arbeitsbereichsmodellregistrierung
Wichtig
In dieser Dokumentation wird die Arbeitsbereichsmodellregistrierung behandelt. Wenn Ihr Arbeitsbereich für den Unity Catalog aktiviert ist, verwenden Sie die Verfahren auf dieser Seite nicht. Lesen Sie stattdessen Modelle im Unity Catalog.
Die Arbeitsbereichsmodellregistrierung wird in Zukunft eingestellt. Einen Leitfaden zum Upgrade der Arbeitsbereichsmodellregistrierung zu Unity Catalog finden Sie unter Migrieren von ML-Workflows und -Modellen zu Unity Catalog.
Wenn sich der Standardkatalog Ihres Arbeitsbereichs in Unity Catalog (und nicht in hive_metastore) befindet und Sie einen Cluster mit Databricks Runtime 13.3 LTS oder höher ausführen, werden Modelle automatisch im Standardkatalog des Arbeitsbereichs erstellt und geladen, ohne dass eine Konfiguration erforderlich ist. Um die Arbeitsbereichsmodellregistrierung in diesem Fall zu verwenden, müssen Sie sie explizit als Ziel festlegen, indem Sie import mlflow; mlflow.set_registry_uri("databricks") zu Beginn Ihrer Workload ausführen. Eine kleine Anzahl von Arbeitsbereichen, bei denen der Standardkatalog vor Januar 2024 als Katalog in Unity Catalog konfiguriert und die Arbeitsbereichsmodellregistrierung vor Januar 2024 verwendet wurde, sind von diesem Verhalten ausgenommen. Sie verwenden weiterhin standardmäßig die Arbeitsbereichsmodellregistrierung.
In diesem Artikel wird beschrieben, wie Sie die Arbeitsbereichsmodellregistrierung als Teil Ihres Machine Learning-Workflows verwenden, um den gesamten Lebenszyklus von ML-Modellen zu verwalten. Die Arbeitsbereichsmodellregistrierung ist eine von Databricks bereitgestellte, gehostete Version der MLflow-Modellregistrierung.
Die Arbeitsbereichsmodellregistrierung bietet Folgendes:
- Chronologische Modelllinie (das MLflow-Experiment ausgeführt und das Modell zu einem bestimmten Zeitpunkt produziert hat).
- Modellbereitstellung.
- Versionsverwaltung für Modelle:
- Phasenübergänge (z. B. von Staging zu Produktion oder archiviert).
- Webhooks, damit Sie Aktionen basierend auf Registrierungsereignissen automatisch auslösen können.
- E-Mail-Benachrichtigungen von Modellereignissen.
Sie können auch Modellbeschreibungen erstellen und anzeigen sowie Kommentare hinterlassen.
Dieser Artikel enthält Anleitungen für die Benutzeroberfläche und API der Arbeitsbereichsmodellregistrierung.
Eine Übersicht über Konzepte zur Arbeitsbereichsmodellregistrierung finden Sie unter ML-Lebenszyklusverwaltung mit MLflow.
Erstellen oder Registrieren eines Modells
Sie können ein Modell auf der Benutzeroberfläche erstellen oder registrieren oder ein Modell mithilfe der API registrieren.
Erstellen oder Registrieren eines Modells über die Benutzeroberfläche
Es gibt zwei Möglichkeiten, ein Modell in der Arbeitsbereichsmodellregistrierung zu registrieren. Sie können ein vorhandenes Modell registrieren, das in MLflow protokolliert wurde, oder ein neues, leeres Modell erstellen und registrieren und dafür dann ein zuvor protokolliertes Modell zuweisen.
Registrieren eines vorhandenen protokollierten Modells aus einem Notebook
Ermitteln Sie im Arbeitsbereich die MLflow-Ausführung mit dem Modell, das Sie registrieren möchten.
Klicken Sie auf das Experiment-Symbol
 in der rechten Randleiste des Notebooks.
in der rechten Randleiste des Notebooks.
Klicken Sie in der Seitenleiste für Experimentausführungen auf das
 -Symbol neben dem Datum der Ausführung. Die Seite für die MLflow-Ausführung wird angezeigt. Auf dieser Seite werden alle Ausführungsdetails angezeigt, z. B. Parameter, Metriken, Tags und eine Liste mit Artefakten.
-Symbol neben dem Datum der Ausführung. Die Seite für die MLflow-Ausführung wird angezeigt. Auf dieser Seite werden alle Ausführungsdetails angezeigt, z. B. Parameter, Metriken, Tags und eine Liste mit Artefakten.
Klicken Sie im Abschnitt „Artefakte“ auf das Verzeichnis mit dem Namen xxx-model.
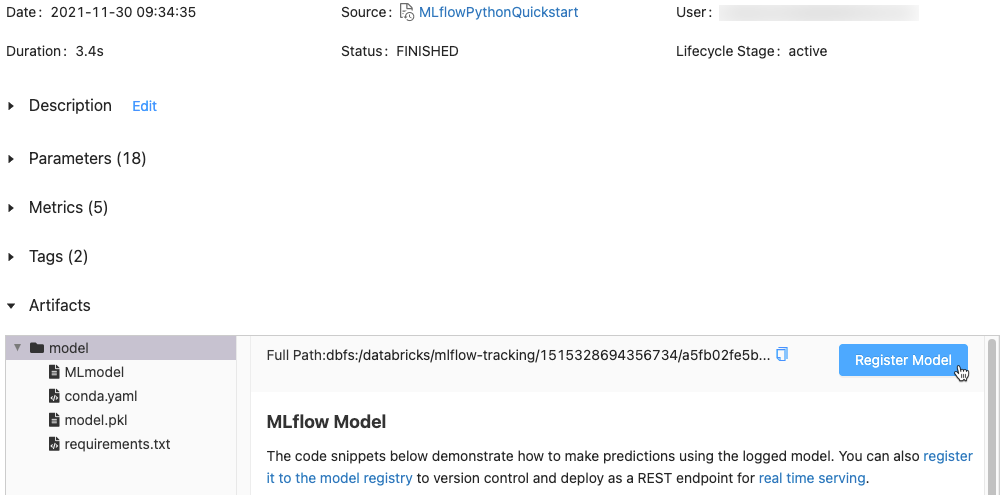
Klicken Sie ganz rechts auf die Schaltfläche Modell registrieren.
Klicken Sie im Dialogfeld auf das Feld Modell, und führen Sie einen der folgenden Schritte aus:
- Wählen Sie im Dropdownmenü die Option Neues Modell erstellen aus. Das Feld Modellname wird angezeigt. Geben Sie einen Modellnamen ein, z. B.
scikit-learn-power-forecasting. - Wählen Sie im Dropdownmenü ein vorhandenes Modell aus.
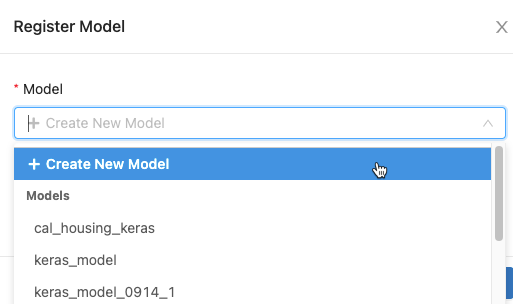
- Wählen Sie im Dropdownmenü die Option Neues Modell erstellen aus. Das Feld Modellname wird angezeigt. Geben Sie einen Modellnamen ein, z. B.
Klicken Sie auf Registrieren.
- Wenn Sie die Option Neues Modell erstellen ausgewählt haben, wird ein Modell mit dem Namen
scikit-learn-power-forecastingregistriert und an einen sicheren Speicherort kopiert, der von der Arbeitsbereichsmodellregistrierung verwaltet wird. Anschließend wird eine neue Version des Modells erstellt. - Wenn Sie ein vorhandenes Modell ausgewählt haben, wird eine neue Version des ausgewählten Modells registriert.
Nach einigen Augenblicken ändert sich die Schaltfläche Modell registrieren in einen Link zur neuen registrierten Modellversion.
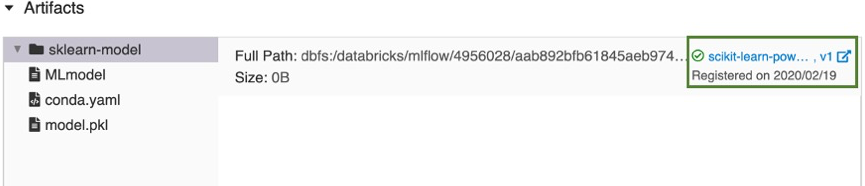
- Wenn Sie die Option Neues Modell erstellen ausgewählt haben, wird ein Modell mit dem Namen
Klicken Sie auf den Link, um die neue Modellversion auf der Benutzeroberfläche der Arbeitsbereichsmodellregistrierung zu öffnen. Sie können das Modell auch in der Arbeitsbereichsmodellregistrierung finden, indem Sie in der Seitenleiste auf
 Modelle klicken.
Modelle klicken.
Erstellen eines neuen registrierten Modells und Zuweisen eines protokollierten Modells
Sie können die Schaltfläche „Modell erstellen“ auf der Seite mit den registrierten Modellen verwenden, um ein neues, leeres Modell zu erstellen, und diesem dann ein protokolliertes Modell zuweisen. Führen Sie folgende Schritte aus:
Klicken Sie auf der Seite mit den registrierten Modellen auf Modell erstellen. Geben Sie einen Namen für das Modell ein, und klicken Sie auf Erstellen.
Führen Sie die Schritte 1 bis 3 unter Registrieren eines vorhandenen protokollierten Modells aus einem Notebook aus.
Wählen Sie im Dialogfeld „Modell registrieren“ den Namen des Modells aus, das Sie in Schritt 1 erstellt haben, und klicken Sie auf Registrieren. Es wird ein Modell mit dem von Ihnen angegebenen Namen registriert und an einen sicheren Speicherort kopiert, der von der Arbeitsbereichsmodellregistrierung verwaltet wird. Anschließend wird eine Modellversion erstellt:
Version 1.Nach einigen Augenblicken wird die Schaltfläche „Modell registrieren“ auf der Benutzeroberfläche der MLflow-Ausführung durch einen Link zur neuen registrierten Modellversion ersetzt. Sie können das Modell nun auf der Seite Experimentausführungen im Dialogfeld „Modell registrieren“ in der Dropdownliste Modell auswählen. Sie können auch neue Versionen des Modells registrieren, indem Sie den Namen in API-Befehlen wie Create ModelVersion angeben.
Registrieren eines Modells über die API
Es gibt drei programmgesteuerte Methoden zum Registrieren eines Modells in der Arbeitsbereichsmodellregistrierung. Bei allen Methoden wird das Modell an einen sicheren Speicherort kopiert, der von der Arbeitsbereichsmodellregistrierung verwaltet wird.
Verwenden Sie die Methode
mlflow.<model-flavor>.log_model(...), um ein Modell zu protokollieren und während eines MLflow-Experiments unter dem angegebenen Namen zu registrieren. Falls kein registriertes Modell mit dem angegebenen Namen vorhanden ist, wird mit der Methode ein neues Modell registriert, die erste Version erstellt und das MLflow-ObjektModelVersionzurückgegeben. Wenn bereits ein registriertes Modell mit dem Namen vorhanden ist, erstellt die Methode eine neue Modellversion und gibt das Versionsobjekt zurück.with mlflow.start_run(run_name=<run-name>) as run: ... mlflow.<model-flavor>.log_model(<model-flavor>=<model>, artifact_path="<model-path>", registered_model_name="<model-name>" )Verwenden Sie die Methode
mlflow.register_model(), um ein Modell mit dem angegebenen Namen zu registrieren, nachdem alle Experimentausführungen abgeschlossen sind und Sie die Entscheidung getroffen haben, welches Modell für das Hinzufügen zur Registrierung am besten geeignet ist. Für diese Methode benötigen Sie die Ausführungs-ID für das Argumentmlruns:URI. Falls kein registriertes Modell mit dem angegebenen Namen vorhanden ist, wird mit der Methode ein neues Modell registriert, die erste Version erstellt und das MLflow-ObjektModelVersionzurückgegeben. Wenn bereits ein registriertes Modell mit dem Namen vorhanden ist, erstellt die Methode eine neue Modellversion und gibt das Versionsobjekt zurück.result=mlflow.register_model("runs:<model-path>", "<model-name>")Verwenden Sie die Methode
create_registered_model()der MLflow-Client-API, um ein neues registriertes Modell mit dem angegebenen Namen zu erstellen. Wenn der Modellname vorhanden ist, wird bei dieser Methode eineMLflowExceptionausgelöst.client = MlflowClient() result = client.create_registered_model("<model-name>")
Sie können auch ein Modell beim Databricks-Terraform-Anbieter und mit databricks_mlflow_model registrieren.
Anzeigen von Modellen auf der Benutzeroberfläche
Die Seite „Registrierte Modelle“
Die Seite „Registrierte Modelle“ wird angezeigt, wenn Sie auf das ![]() Modelle auf der Randleiste klicken. Auf dieser Seite werden alle Modelle in der Registrierung angezeigt.
Modelle auf der Randleiste klicken. Auf dieser Seite werden alle Modelle in der Registrierung angezeigt.
Auf dieser Seite können Sie ein neues Modell erstellen.
Außerdem können Arbeitsbereichsadministrator*innen auf dieser Seite Berechtigungen für alle Modelle in der Arbeitsbereichsmodellregistrierung festlegen.

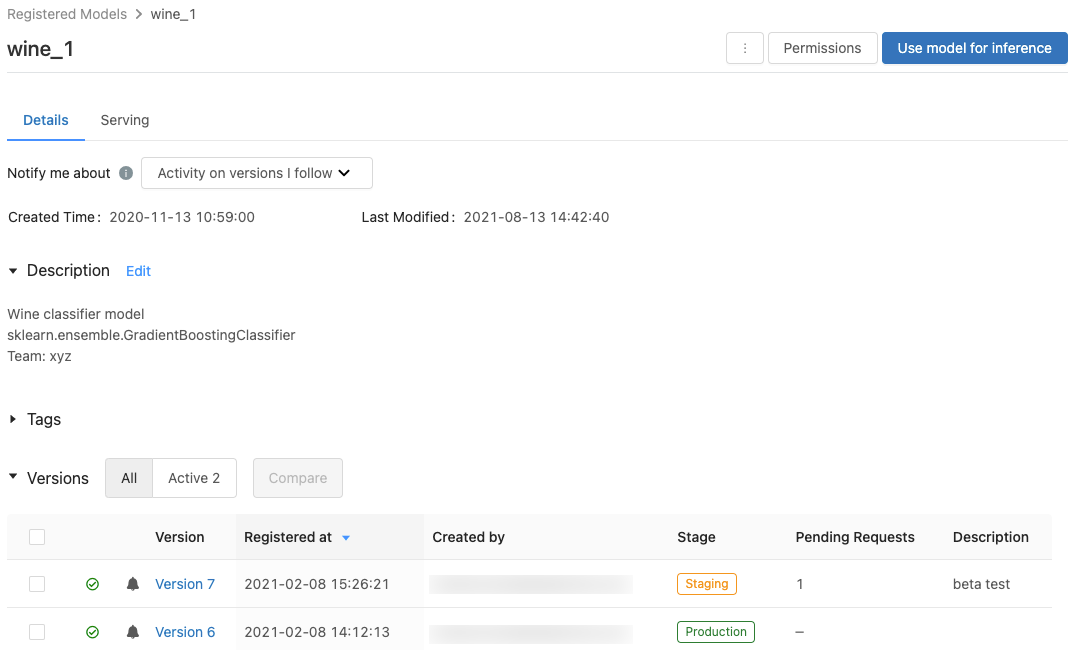
Die Seite „Registriertes Modell“
Wenn Sie die Seite „Registriertes Modell“ für ein Modell anzeigen möchten, klicken Sie auf der Seite „Registrierte Modelle“ auf einen Modellnamen. Auf der Seite „Registriertes Modell“ werden Informationen zum ausgewählten Modell sowie eine Tabelle mit Informationen zu den einzelnen Versionen des Modells angezeigt. Auf dieser Seite können Sie ebenfalls Folgendes tun:
- Einrichten der Modellbereitstellung.
- Automatisches Generieren eines Notebooks, um das Modell für Rückschlüsse zu verwenden
- Konfigurieren von E-Mail-Benachrichtigungen
- Vergleichen von Modellversionen
- Legen Sie Berechtigungen für das Modell fest.
- Löschen eines Modells
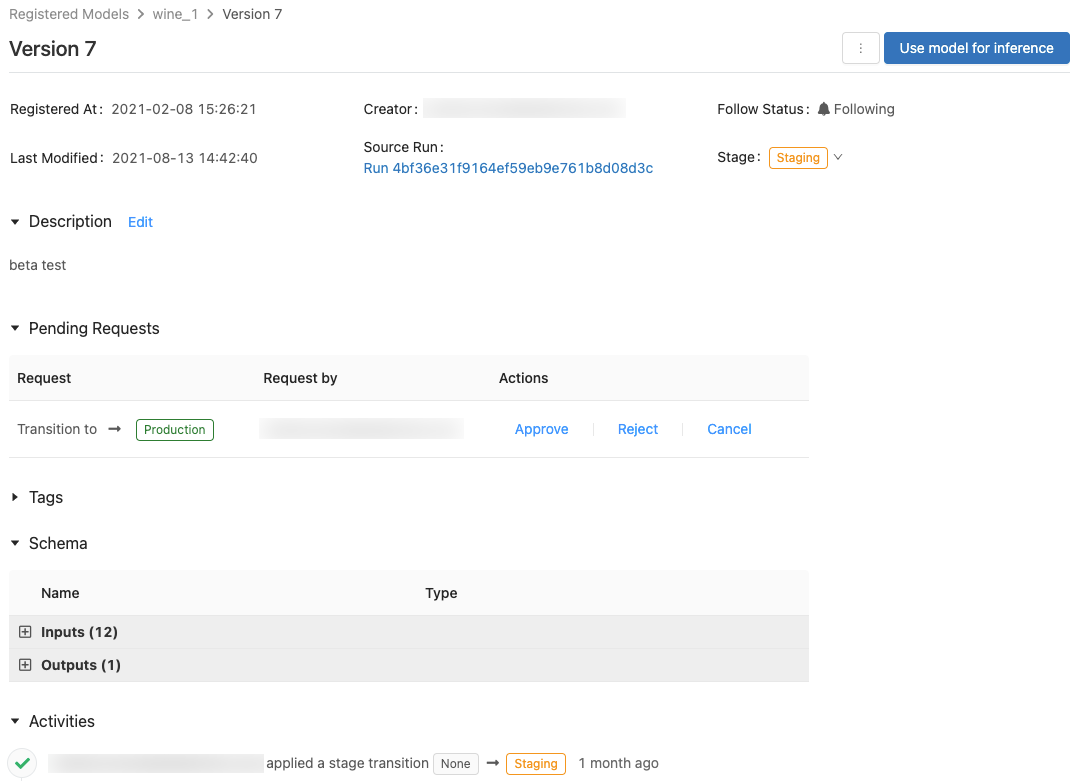
Die Seite „Modellversion“
Führen Sie eine der folgenden Aktionen aus, um die Seite „Modellversion“ anzuzeigen:
- Klicken Sie in der Spalte Aktuelle Version auf der Seite „Registrierte Modelle“ auf einen Versionsnamen.
- Klicken Sie in der Spalte Version auf der Seite „Registriertes Modell“ auf einen Versionsnamen.
Auf dieser Seite werden Informationen zu einer bestimmten Version eines registrierten Modells sowie ein Link zur Quellausführung (der Version des Notebooks, die zum Erstellen des Modells ausgeführt wurde) angezeigt. Auf dieser Seite können Sie ebenfalls Folgendes tun:
- Automatisches Generieren eines Notebooks, um das Modell für Rückschlüsse zu verwenden
- Löschen eines Modells
Steuern des Zugriffs auf Modelle
Sie müssen mindestens über die Berechtigung KANN VERWALTEN verfügen, um Berechtigungen für ein Modell zu konfigurieren. Informationen zu Modellberechtigungsstufen finden Sie unter Zugriffssteuerungslisten für MLFlow-Modelle. Eine Modellversion erbt die Berechtigungen vom übergeordneten Modell. Sie können keine Berechtigungen für Modellversionen festlegen.
Klicken Sie auf der Randleiste auf
Modelle.Wählen Sie einen Modellnamen aus.
Klicken Sie auf Berechtigungen. Das Dialogfeld „Berechtigungseinstellungen“ wird angezeigt.

Wählen Sie im Dialogfeld das Dropdownmenü Benutzer, Gruppe oder Dienstprinzipal auswählen… und dann einen Benutzer, eine Gruppe oder einen Dienstprinzipal aus.
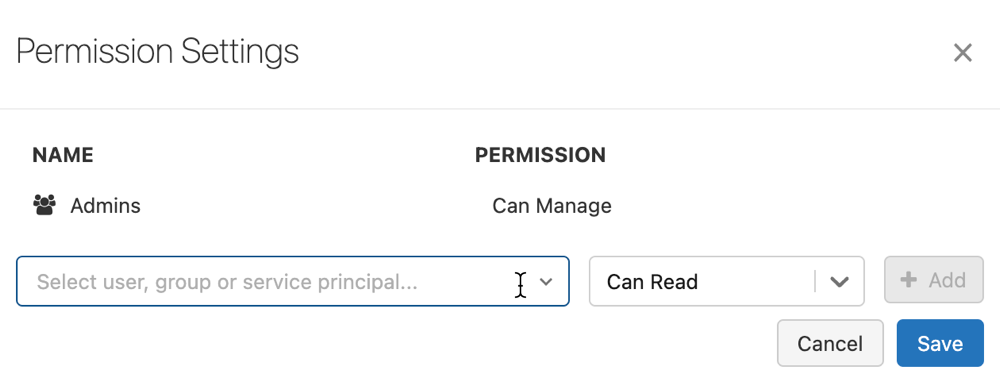
Wählen Sie im Dropdownmenü eine Berechtigung aus.
Wählen Sie Hinzufügen und dann Speichern aus.
Arbeitsbereichsadministratoren und Benutzer mit der Berechtigung KANN VERWALTEN für die gesamte Registrierung können Berechtigungsstufen für alle Modelle im Arbeitsbereich festlegen, indem sie auf der Seite „Modelle“ die Option Berechtigungen auswählen.
Durchführen des Modellphasenübergangs
Eine Modellversion verfügt über eine der folgenden Phasen: Keine, Staging, Produktion oder Archiviert. Die Phase Staging ist für das Testen und Überprüfen des Modells bestimmt, und die Phase Production (Produktion) gilt für Modellversionen, für die die Tests oder Überprüfungsprozesse abgeschlossen und die zur Livebewertung in Anwendungen bereitgestellt wurden. Bei einer archivierten Modellversion wird davon ausgegangen, dass sie inaktiv ist, und Sie können sie bei Bedarf löschen. Unterschiedliche Versionen eines Modells können sich in unterschiedlichen Phasen befinden.
Ein Benutzer mit einer entsprechenden Berechtigung kann für eine Modellversion den Übergang von einer Phase zur anderen durchführen. Wenn Sie zum Durchführen des Übergangs für eine Modellversion in eine bestimmte Phase berechtigt sind, können Sie diesen Schritt direkt selbst ausführen. Falls Sie nicht über die Berechtigung verfügen, können Sie einen Phasenübergang anfordern. Diese Anforderung kann dann von einem Benutzer mit der Berechtigung für Phasenübergänge von Modellversionen genehmigt, abgelehnt oder storniert werden.
Sie können einen Modellphasenübergang auf der Benutzeroberfläche oder über die API durchführen.
Durchführen eines Modellphasenübergangs über die Benutzeroberfläche
Befolgen Sie die unten angegebene Anleitung zum Durchführen eines Phasenübergangs für ein Modell.
Um die Liste der verfügbaren Modellphasen und Ihre verfügbaren Optionen anzuzeigen, klicken Sie auf einer Modellversionsseite auf das Dropdownmenü neben Phase: und fordern Sie einen Übergang zur einer anderen Phase an oder wählen Sie einen aus.
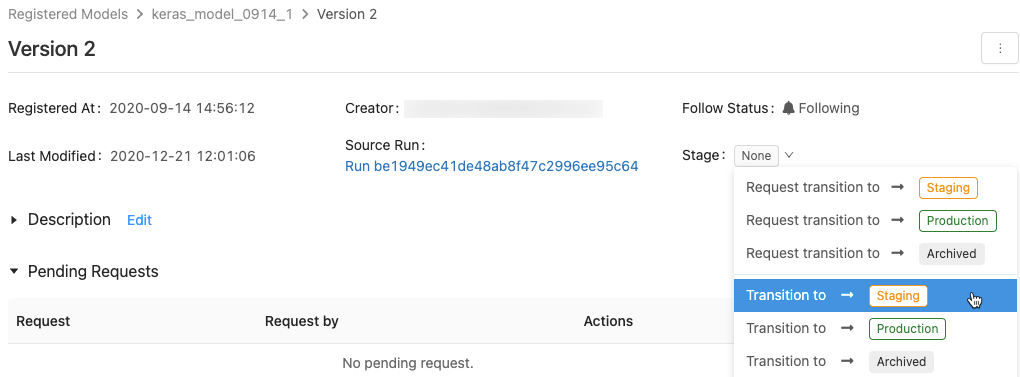
Geben Sie optional einen Kommentar ein, und klicken Sie auf OK.
Durchführen des Übergangs zur Phase „Production“ (Produktion) für eine Modellversion
Nach dem Testen und Überprüfen können Sie den Übergang zur Phase „Production“ (Produktion) durchführen bzw. anfordern.
In der Arbeitsbereichsmodellregistrierung ist in jeder Phase mehr als eine Version des registrierten Modells zulässig. Falls sich bei Ihnen nur eine Version in der Phase „Production“ (Produktion) befinden soll, können Sie für alle Versionen des Modells, die sich in der Phase „Production“ (Produktion) befinden, den Übergang zu „Archived“ (Archiviert) durchführen, indem Sie die Option Transition existing Production model versions to Archived (Vorhandene Modellversionen von „Produktion“ auf „Archiviert“ umstellen) aktivieren.
Genehmigen, Ablehnen oder Stornieren einer Anforderung zum Modellversion-Phasenübergang
Ein Benutzer ohne Berechtigung für Phasenübergänge kann einen Phasenübergang anfordern. Die Anforderung wird auf der Seite der Modellversion im Abschnitt Ausstehende Anforderungen angezeigt:

Klicken Sie zum Genehmigen, Ablehnen oder Stornieren der Anforderung eines Phasenübergangs auf den Link Genehmigen, Ablehnen oder Stornieren.
Der Ersteller einer Übergangsanforderung kann die Anforderung auch stornieren.
Anzeigen von Aktivitäten einer Modellversion
Navigieren Sie zum Abschnitt „Aktivitäten“, um alle Übergänge anzuzeigen, die angefordert oder genehmigt wurden, ausstehen oder auf eine Modellversion angewendet wurden. In dieser Liste mit den Aktivitäten sind die Herkunftsinformationen zum Modelllebenszyklus für die Überprüfung bzw. Untersuchung angegeben.
Durchführen eines Modellphasenübergangs über die API
Benutzer mit entsprechenden Berechtigungen können für eine Modellversion den Übergang zu einer neuen Phase durchführen.
Verwenden Sie die Methode transition_model_version_stage() der MLflow-Client-API, um die Phase einer Modellversion auf eine neue Phase zu aktualisieren.
client = MlflowClient()
client.transition_model_version_stage(
name="<model-name>",
version=<model-version>,
stage="<stage>",
description="<description>"
)
Zulässige Werte für <stage> sind: "Staging"|"staging", "Archived"|"archived" (Archiviert), "Production"|"production" (Produktion) und "None"|"none" (Keine).
Verwenden des Modells für Rückschlüsse
Wichtig
Dieses Feature befindet sich in der Public Preview.
Nachdem ein Modell in der Arbeitsbereichsmodellregistrierung registriert wurde, können Sie automatisch ein Notebook generieren, um das Modell für Batch- oder Streamingrückschlüsse zu verwenden. Alternativ können Sie einen Endpunkt erstellen, um das Modell für die Echtzeitbereitstellung mit Modellbereitstellung zu verwenden.
Klicken Sie in der oberen rechten Ecke der Seite mit dem registrierten Modell oder der Seite mit der Modellversion auf  . Das Dialogfeld zur Konfiguration von Modellrückschlüssen wird angezeigt, in dem Sie Batch-, Streaming- oder Echtzeitrückschlüsse konfigurieren können.
. Das Dialogfeld zur Konfiguration von Modellrückschlüssen wird angezeigt, in dem Sie Batch-, Streaming- oder Echtzeitrückschlüsse konfigurieren können.
Wichtig
Anaconda Inc. hat die Vertragsbedingungen für die Kanäle von anaconda.org aktualisiert. Gemäß den neuen Vertragsbedingungen benötigen Sie nun möglicherweise eine kommerzielle Lizenz für die Nutzung der Paket- und Verteilungslösung von Anaconda. Weitere Informationen finden Sie unter Anaconda Commercial Edition FAQ (Häufig gestellte Fragen zu Anaconda Commercial Edition). Jegliche Nutzung von Anaconda-Kanälen unterliegt den Anaconda-Vertragsbedingungen.
MLflow-Modelle, die vor v1.18 (Databricks Runtime 8.3 ML oder früher) wurden standardmäßig mit dem conda-defaults Kanal (https://repo.anaconda.com/pkgs/) als Abhängigkeit protokolliert. Aufgrund dieser Lizenzänderung hat Databricks die Verwendung des defaults-Kanals für Modelle beendet, die mit MLflow v1.18 und höher protokolliert werden. Der protokollierte Standardkanal ist jetzt conda-forge, der auf die verwaltete Community https://conda-forge.org/ verweist.
Wenn Sie ein Modell vor MLflow v1.18 protokolliert haben, ohne den Kanal defaults aus der conda-Umgebung für das Modell auszuschließen, hat dieses Modell möglicherweise eine Abhängigkeit vom Kanal defaults, den die Sie möglicherweise nicht beabsichtigt haben.
Um manuell zu überprüfen, ob ein Modell diese Abhängigkeit aufweist, können Sie den Wert von channel in der Datei conda.yaml untersuchen, die mit dem protokollierten Modell gepackt ist. Beispielsweise sieht die Datei conda.yaml eines Modells mit einer Abhängigkeit vom Kanal defaults wie folgt aus:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Da Databricks nicht bestimmen kann, ob Ihre Verwendung des Anaconda-Repositorys für die Interaktion mit Ihren Modellen gemäß Ihrer Beziehung mit Anaconda zulässig ist, erzwingt Databricks keine Änderungen von der Kundschaft. Wenn Ihre Nutzung des Anaconda.com-Repositorys über die Verwendung von Databricks unter den Bedingungen von Anaconda zulässig ist, müssen Sie keine Maßnahmen ergreifen.
Wenn Sie den Kanal ändern möchten, der in der Umgebung eines Modells verwendet wird, können Sie das Modell mit einer neuen Datei conda.yaml erneut bei der Arbeitsbereichsmodellregistrierung registrieren. Dazu geben Sie den Kanal im conda_env-Parameter von log_model() an.
Weitere Informationen zur log_model()-API finden Sie in der MLflow-Dokumentation für die Modellvariante, mit der Sie arbeiten, zum Beispiel log_model für scikit-learn.
Weitere Informationen zu conda.yaml-Dateien finden Sie in der MLflow-Dokumentation.
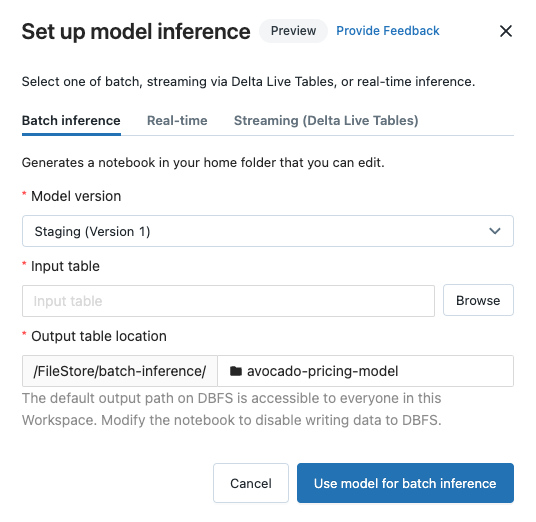
Konfigurieren von Batchrückschlüssen
Wenn Sie diese Schritte befolgen, um ein Notebook für Batchrückschlüsse zu erstellen, wird das Notebook in Ihrem Benutzerordner unter dem Ordner Batch-Inference in einem Ordner mit dem Namen des Modells gespeichert. Sie können das Notebook nach Bedarf bearbeiten.
Klicken Sie auf die Registerkarte Batchrückschluss.
Wählen Sie in der Dropdownliste Modellversion die zu verwendende Modellversion aus. Die ersten beiden Elemente in der Dropdownliste sind die aktuelle Produktions- und Stagingversion des Modells (falls vorhanden). Wenn Sie eine dieser Optionen auswählen, verwendet das Notebook automatisch die Produktions- oder Stagingversion, die zum Zeitpunkt der Ausführung vorliegt. Sie brauchen das Notebook nicht zu aktualisieren, wenn Sie das Modell weiterentwickeln.
Klicken Sie auf die Schaltfläche Durchsuchen neben Eingabetabelle. Das Dialogfeld Eingabedaten auswählen wird angezeigt. Falls erforderlich, können Sie den Cluster in der Dropdownliste Compute ändern.
Hinweis
Bei Arbeitsbereichen mit Unity Catalog-Unterstützung stehen im Dialogfeld Eingabedaten auswählen drei Ebenen zur Auswahl:
<catalog-name>.<database-name>.<table-name>.Wählen Sie die Datenbank und die Tabelle mit den Eingabedaten für das Modell aus, und klicken Sie auf Auswählen. Das generierte Notebook importiert diese Daten automatisch und sendet sie an das Modell. Sie können das generierte Notebook bearbeiten, falls die Daten vor der Eingabe in das Modell transformiert werden müssen.
Vorhersagen werden in einem Ordner im Verzeichnis
dbfs:/FileStore/batch-inferencegespeichert. Standardmäßig werden Vorhersagen in einem Ordner mit demselben Namen wie das Modell gespeichert. Bei jeder Ausführung des generierten Notebooks wird eine neue Datei in dieses Verzeichnis geschrieben, wobei der Zeitstempel an den Namen angehängt wird. Sie können den Zeitstempel auch weglassen und die Datei bei späteren Ausführungen des Notebooks überschreiben. Anweisungen dazu finden Sie im generierten Notebook.Sie können den Ordner, in dem die Vorhersagen gespeichert werden, ändern, indem Sie einen neuen Ordnernamen in das Feld Speicherort der Ausgabetabelle eingeben oder auf das Ordnersymbol klicken, um das Verzeichnis zu durchsuchen und einen anderen Ordner auszuwählen.
Um Vorhersagen an einem Speicherort im Unity Catalog zu speichern, müssen Sie das Notebook bearbeiten. Ein Beispiel-Notebook, das das Trainieren eines Machine Learning-Modells veranschaulicht, das Daten in Unity Catalog verwendet und die Ergebnisse zurück in Unity Catalog schreibt, finden Sie unter Trainieren und Registrieren eines Machine Learning-Modells mit Unity Catalog.
Konfigurieren von Streamingrückschlüssen mithilfe von Delta Live Tables
Wenn Sie diese Schritte befolgen, um ein Notebook für Streamingrückschlüsse zu erstellen, wird das Notebook in Ihrem Benutzerordner unter dem Ordner DLT-Inference in einem Ordner mit dem Namen des Modells gespeichert. Sie können das Notebook nach Bedarf bearbeiten.
Klicken Sie auf die Registerkarte Streaming (Delta Live Tables).
Wählen Sie in der Dropdownliste Modellversion die zu verwendende Modellversion aus. Die ersten beiden Elemente in der Dropdownliste sind die aktuelle Produktions- und Stagingversion des Modells (falls vorhanden). Wenn Sie eine dieser Optionen auswählen, verwendet das Notebook automatisch die Produktions- oder Stagingversion, die zum Zeitpunkt der Ausführung vorliegt. Sie brauchen das Notebook nicht zu aktualisieren, wenn Sie das Modell weiterentwickeln.
Klicken Sie auf die Schaltfläche Durchsuchen neben Eingabetabelle. Das Dialogfeld Eingabedaten auswählen wird angezeigt. Falls erforderlich, können Sie den Cluster in der Dropdownliste Compute ändern.
Hinweis
Bei Arbeitsbereichen mit Unity Catalog-Unterstützung stehen im Dialogfeld Eingabedaten auswählen drei Ebenen zur Auswahl:
<catalog-name>.<database-name>.<table-name>.Wählen Sie die Datenbank und die Tabelle mit den Eingabedaten für das Modell aus, und klicken Sie auf Auswählen. Das generierte Notebook erstellt eine Datentransformation, die die Eingabetabelle als Quelle verwendet und die benutzerdefinierte PySpark-Funktion für Rückschlüsse von MLflow zur Durchführung von Modellvorhersagen integriert. Sie können das generierte Notebook bearbeiten, wenn die Daten vor oder nach Anwenden des Modells zusätzliche Transformationen erfordern.
Geben Sie den ausgegebenen Delta Live Table-Namen an. Das Notebook erstellt eine Livetabelle mit dem angegebenen Namen und nutzt sie zum Speichern der Modellvorhersagen. Sie können das generierte Notebook ändern, um das Zieldataset nach Bedarf anzupassen. Beispiel: Definieren Sie eine Streaminglivetabelle als Ausgabe, und fügen Sie Schemainformationen oder Datenqualitätseinschränkungen hinzu.
Sie können dann entweder eine neue Delta Live Tables-Pipeline mit diesem Notebook erstellen oder es als zusätzliche Notebookbibliothek zu einer vorhandenen Pipeline hinzufügen.
Konfigurieren von Echtzeitrückschlüssen
Modellbereitstellung verarbeitet Ihre Machine Learning-Modelle mithilfe von MLflow und stellt sie als REST-API-Endpunkte bereit. Informationen zum Erstellen eines Model Serving-Endpunkts finden Sie unter Erstellen von benutzerdefinierten Model Serving-Endpunkten.
Feedback geben
Diese Funktion befindet sich in der Vorschau, und wir würden uns über Ihr Feedback freuen. Um Feedback zu geben, klicken Sie im Dialogfeld zur Konfiguration des Modellrückschlusses auf Provide Feedback.
Vergleichen von Modellversionen
Sie können Modellversionen in der Arbeitsbereichsmodellregistrierung vergleichen.
- Wählen Sie auf der Seite mit den registrierten Modellen zwei oder mehr Modellversionen aus, indem Sie auf das Kontrollkästchen links neben der Modellversion klicken.
- Klicken Sie auf Vergleichen.
- Sie gelangen auf den Bildschirm zum Vergleich der
<N>-Versionen, auf dem eine Tabelle angezeigt wird, in der die Parameter, das Schema und die Metriken der ausgewählten Modellversionen verglichen werden. Am unteren Rand des Bildschirms können Sie die Art der Darstellung (Streuung, Kontur oder parallele Koordinaten) und die Parameter oder Metriken für die Darstellung auswählen.
Steuern von Benachrichtigungseinstellungen
Sie können die Arbeitsbereichsmodellregistrierung so konfigurieren, dass Sie per E-Mail über Aktivitäten bei registrierten Modellen und Modellversionen benachrichtigt werden, die Sie angeben.
Auf der Seite für das registrierte Modell werden im Menü Benachrichtigungen senden zu drei Optionen angezeigt:
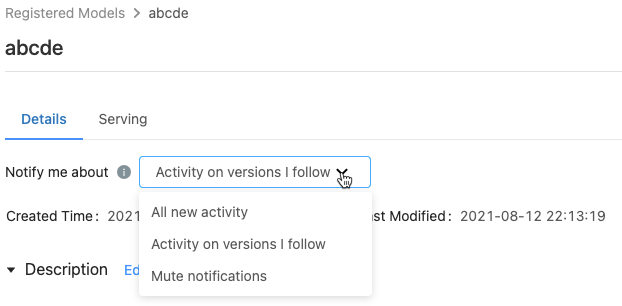
- All new activity (Alle neuen Aktivitäten): E-Mail-Benachrichtigungen werden zu allen Aktivitäten für alle Modellversionen dieses Modells gesendet. Wenn Sie das registrierte Modell erstellt haben, ist dies die Standardeinstellung.
- Activity on versions I follow (Aktivität für Versionen, denen ich folge): E-Mail-Benachrichtigungen werden nur zu Modellversionen gesendet, denen Sie folgen. Mit dieser Auswahl erhalten Sie Benachrichtigungen zu allen Modellversionen, denen Sie folgen. Benachrichtigungen zu einer bestimmten Modellversion können nicht deaktiviert werden.
- Mute notifications (Benachrichtigungen unterdrücken): Es werden keine E-Mail-Benachrichtigungen zu Aktivitäten für dieses registrierte Modell gesendet.
Die folgenden Ereignisse lösen eine E-Mail-Benachrichtigung aus:
- Erstellung einer neuen Modellversion
- Anforderung für einen Phasenübergang
- Phasenübergang
- Neue Kommentare
Wenn Sie eine der folgenden Aktionen ausführen, abonnieren Sie automatisch Modellbenachrichtigungen:
- Kommentieren dieser Modellversion
- Durchführen des Phasenübergangs einer Modellversion
- Senden einer Anforderung für den Phasenübergang des Modells
Ob Sie einer Modellversion folgen, sehen Sie im Feld „Follow Status“ (Folgestatus) auf der Seite für die Modellversion oder in der Tabelle mit den Modellversionen auf der Seite für das registrierte Modell.
Deaktivieren aller E-Mail-Benachrichtigungen
Sie können E-Mail-Benachrichtigungen im Menü „Benutzereinstellungen“ auf der Registerkarte mit den Einstellungen für die Arbeitsbereichsmodellregistrierung deaktivieren:
- Wählen Sie in der oberen rechten Ecke des Azure Databricks-Arbeitsbereichs Ihren Benutzernamen und anschließend im Dropdownmenü Einstellungen aus.
- Wählen Sie in der Randleiste Einstellungen die Option Benachrichtigungen aus.
- Deaktivieren Sie die Option Model Registry email notifications (E-Mail-Benachrichtigungen zur Modellregistrierung).
Kontoadministrator*innen können E-Mail-Benachrichtigungen für die gesamte Organisation auf der Seite mit den Administratoreinstellungen deaktivieren.
Maximale Anzahl gesendeter E-Mails
Bei der Arbeitsbereichsmodellregistrierung ist die Anzahl der E-Mails beschränkt, die pro Tag und Aktivität an Benutzer*innen gesendet werden. Beispiel: Wenn Sie an einem Tag 20 E-Mails zu neuen Modellversionen erhalten, die für ein registriertes Modell erstellt wurden, sendet die Arbeitsbereichsmodellregistrierung eine E-Mail mit dem Hinweis, dass der tägliche Grenzwert erreicht wurde. Bis zum nächsten Tag werden keine weiteren E-Mails zu diesem Ereignis gesendet.
Wenden Sie sich an Ihr Azure Databricks-Kontoteam, um den Grenzwert für die zulässige Anzahl von E-Mails zu erhöhen.
Webhooks
Wichtig
Dieses Feature befindet sich in der Public Preview.
Mit Webhooks können Sie auf Ereignisse der Arbeitsbereichsmodellregistrierung lauschen, damit Ihre Integrationen automatisch Aktionen auslösen können. Sie können Webhooks verwenden, um Ihre Pipeline für maschinelles Lernen zu automatisieren und in vorhandene CI/CD-Tools und Workflows zu integrieren. Beispielsweise können Sie CI-Builds auslösen, wenn eine neue Modellversion erstellt wird, oder Ihre Teammitglieder immer dann über Slack benachrichtigen, wenn ein Modellübergang in die Produktion angefordert wird.
Hinzufügen einer Anmerkung zu einem Modell oder einer Modellversion
Sie können Informationen zu einem Modell oder einer Modellversion angeben, indem Sie eine Anmerkung anfügen. Beispielsweise können Sie eine Übersicht über das Problem oder Informationen zur verwendeten Methodik und zum Algorithmus angeben.
Versehen eines Modells oder einer Modellversion mit einer Anmerkung über die Benutzeroberfläche
Die Azure Databricks-Benutzeroberfläche bietet mehrere Möglichkeiten, Modelle und Modellversionen mit Anmerkungen zu versehen. Sie können Textinformationen in Form einer Beschreibung oder eines Kommentars hinzufügen und durchsuchbare Schlüssel-Wert-Tags hinzufügen. Beschreibungen und Tags sind für Modelle und Modellversionen verfügbar. Kommentare sind nur für Modellversionen verfügbar.
- Beschreibungen sind zum Bereitstellen von Informationen zum Modell vorgesehen.
- Kommentare ermöglichen eine fortlaufende Diskussion über Aktivitäten für eine Modellversion.
- Mithilfe von Tags können Sie die Modellmetadaten anpassen, um das Auffinden bestimmter Modelle zu erleichtern.
Hinzufügen oder Aktualisieren der Beschreibung für ein Modell oder eine Modellversion
Klicken Sie auf der Seite für das registrierte Modell oder die Modellversion auf Bearbeiten neben Beschreibung. Ein Bearbeitungsfenster wird angezeigt.
Geben Sie im Bearbeitungsfenster die Beschreibung ein, oder bearbeiten Sie sie.
Klicken Sie auf Speichern, um die Änderungen zu speichern, oder auf Abbrechen, um das Fenster zu schließen.
Wenn Sie eine Beschreibung einer Modellversion eingegeben haben, wird sie in der Tabelle auf der Seite für das registrierte Modell in der Spalte Beschreibung angezeigt. In der Spalte werden maximal 32 Zeichen oder eine Textzeile angezeigt – je nachdem, was kürzer ist.
Hinzufügen von Kommentaren für eine Modellversion
- Scrollen Sie auf der Seite Modellversion nach unten, und klicken Sie neben Aktivitäten auf den Pfeil nach unten.
- Geben Sie im Bearbeitungsfenster Ihren Kommentar ein, und klicken Sie auf Kommentar hinzufügen.
Hinzufügen von Tags für ein Modell oder eine Modellversion
Klicken Sie auf der Seite für das registrierte Modell oder die Modellversion auf
 , falls es noch nicht geöffnet ist. Die Tabelle „Tags“ wird angezeigt.
, falls es noch nicht geöffnet ist. Die Tabelle „Tags“ wird angezeigt.
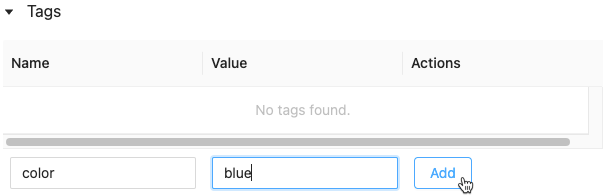
Klicken Sie in die Felder Name und Wert, und geben Sie den Schlüssel und Wert für Ihr Tag ein.
Klicken Sie auf Hinzufügen.
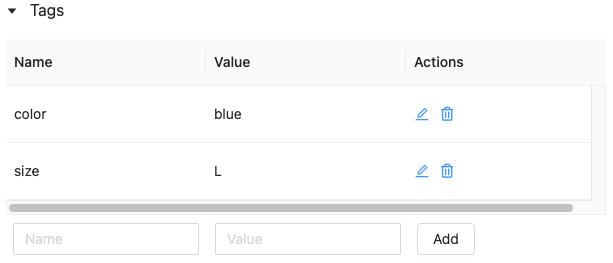
Bearbeiten oder Löschen von Tags für ein Modell oder eine Modellversion
Um ein vorhandenes Tag zu bearbeiten oder zu löschen, verwenden Sie die Symbole in der Spalte Aktionen.
Versehen einer Modellversion mit einer Anmerkung über die API
Verwenden Sie die Methode update_model_version() der MLflow-Client-API, um die Beschreibung einer Modellversion zu aktualisieren:
client = MlflowClient()
client.update_model_version(
name="<model-name>",
version=<model-version>,
description="<description>"
)
Um ein Tag für ein registriertes Modell oder eine registrierte Modellversion festzulegen oder zu aktualisieren, verwenden Sie die set_registered_model_tag()- oder set_model_version_tag()-Methode der MLflow-Client-API:
client = MlflowClient()
client.set_registered_model_tag()(
name="<model-name>",
key="<key-value>",
tag="<tag-value>"
)
client = MlflowClient()
client.set_model_version_tag()(
name="<model-name>",
version=<model-version>,
key="<key-value>",
tag="<tag-value>"
)
Umbenennen eines Modells (nur API)
Verwenden Sie die Methode rename_registered_model() der MLflow-Client-API, um ein registriertes Modell umzubenennen:
client=MlflowClient()
client.rename_registered_model("<model-name>", "<new-model-name>")
Hinweis
Sie können ein registriertes Modell nur umbenennen, wenn es keine Versionen enthält oder wenn sich alle Versionen in der Phase „None“ (Keine) oder „Archived“ (Archiviert) befinden.
Suchen nach einem Modell
Sie können über die Benutzeroberfläche oder die API nach Modellen in der Arbeitsbereichsmodellregistrierung suchen.
Hinweis
Wenn Sie nach einem Modell suchen, werden nur Modelle zurückgegeben, für die Sie mindestens über die Berechtigung KANN LESEN verfügen.
Suchen nach einem Modell über die Benutzeroberfläche
Um registrierte Modelle anzuzeigen, klicken Sie in der Seitenleiste auf ![]() Modelle.
Modelle.
Geben Sie zum Suchen nach einem bestimmten Modell im Suchfeld den Modellnamen ein. Sie können den Namen eines Modells oder einen beliebigen Teil des Namens eingeben:
Sie können auch nach Tags suchen. Geben Sie Tags in diesem Format ein: tags.<key>=<value>. Um nach mehreren Tags zu suchen, verwenden Sie den AND Operator.
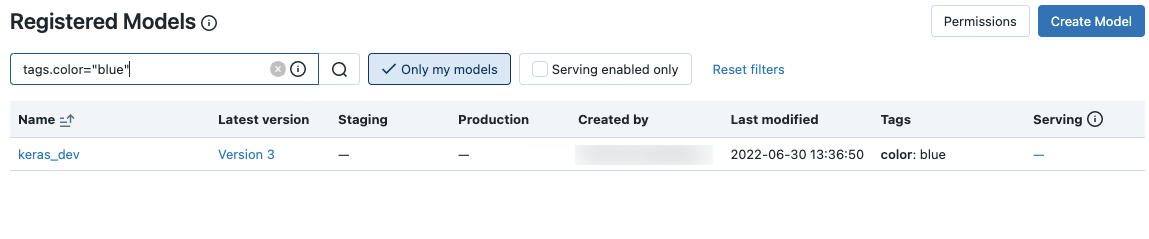
Sie können sowohl den Modellnamen als auch die Tags mithilfe der MLflow-Suchsyntax durchsuchen. Zum Beispiel:

Suchen nach einem Modell über die API
Sie können mit der Client-API-Methode search_registered_models() von MLflow in der Arbeitsbereichsmodellregistrierung nach registrierten Modellen suchen.
Wenn Sie für Ihre Modelle Tags festgelegt haben, können Sie auch mit search_registered_models() anhand dieser Tags suchen.
print(f"Find registered models with a specific tag value")
for m in client.search_registered_models(f"tags.`<key-value>`='<tag-value>'"):
pprint(dict(m), indent=4)
Sie können auch nach einem bestimmten Modellnamen suchen und die zugehörigen Versionsdetails auflisten, indem Sie die Methode search_model_versions() der MLflow-Client-API verwenden:
from pprint import pprint
client=MlflowClient()
[pprint(mv) for mv in client.search_model_versions("name='<model-name>'")]
Folgendes wird ausgegeben:
{ 'creation_timestamp': 1582671933246,
'current_stage': 'Production',
'description': 'A random forest model containing 100 decision trees '
'trained in scikit-learn',
'last_updated_timestamp': 1582671960712,
'name': 'sk-learn-random-forest-reg-model',
'run_id': 'ae2cc01346de45f79a44a320aab1797b',
'source': './mlruns/0/ae2cc01346de45f79a44a320aab1797b/artifacts/sklearn-model',
'status': 'READY',
'status_message': None,
'user_id': None,
'version': 1 }
{ 'creation_timestamp': 1582671960628,
'current_stage': 'None',
'description': None,
'last_updated_timestamp': 1582671960628,
'name': 'sk-learn-random-forest-reg-model',
'run_id': 'd994f18d09c64c148e62a785052e6723',
'source': './mlruns/0/d994f18d09c64c148e62a785052e6723/artifacts/sklearn-model',
'status': 'READY',
'status_message': None,
'user_id': None,
'version': 2 }
Löschen eines Modells oder einer Modellversion
Sie können ein Modell über die Benutzeroberfläche oder die API löschen.
Löschen einer Modellversion oder eines Modells über die Benutzeroberfläche
Warnung
Dieser Vorgang lässt sich nicht rückgängig machen. Sie können für eine Modellversion den Übergang in die Phase „Archived“ (Archiviert) durchführen, anstatt sie aus der Registrierung zu löschen. Wenn Sie ein Modell löschen, werden alle Modellartefakte, die in der Arbeitsbereichsmodellregistrierung gespeichert sind, und alle zugehörigen Metadaten des registrierten Modells gelöscht.
Hinweis
Sie können nur Modelle und Modellversionen löschen, die sich in der Phase „None“ (Keine) oder „Archived“ (Archiviert) befinden. Wenn ein registriertes Modell über Versionen in der Phase „Staging“ oder „Production“ (Produktion) verfügt, müssen Sie dafür den Übergang in die Phase „None“ (Keine) oder „Archived“ (Archiviert) durchführen, bevor Sie das Modell löschen.
Löschen Sie eine Modellversion wie folgt:
- Klicken Sie auf der Seitenleiste auf Modelle.
- Klicken Sie auf einen Modellnamen.
- Klicken Sie auf eine Modellversion.
- Klicken Sie auf
 in der oberen rechten Ecke des Bildschirms und wählen Sie Löschen aus dem Dropdownmenü aus.
in der oberen rechten Ecke des Bildschirms und wählen Sie Löschen aus dem Dropdownmenü aus.
Löschen Sie ein Modell wie folgt:
- Klicken Sie auf der Seitenleiste auf Modelle.
- Klicken Sie auf einen Modellnamen.
- Klicken Sie auf in der oberen rechten Ecke des Bildschirms und wählen Sie Löschen aus dem Dropdownmenü aus.
Löschen einer Modellversion oder eines Modells über die API
Warnung
Dieser Vorgang lässt sich nicht rückgängig machen. Sie können für eine Modellversion den Übergang in die Phase „Archived“ (Archiviert) durchführen, anstatt sie aus der Registrierung zu löschen. Wenn Sie ein Modell löschen, werden alle Modellartefakte, die in der Arbeitsbereichsmodellregistrierung gespeichert sind, und alle zugehörigen Metadaten des registrierten Modells gelöscht.
Hinweis
Sie können nur Modelle und Modellversionen löschen, die sich in der Phase „None“ (Keine) oder „Archived“ (Archiviert) befinden. Wenn ein registriertes Modell über Versionen in der Phase „Staging“ oder „Production“ (Produktion) verfügt, müssen Sie dafür den Übergang in die Phase „None“ (Keine) oder „Archived“ (Archiviert) durchführen, bevor Sie das Modell löschen.
Löschen einer Modellversion
Verwenden Sie zum Löschen einer Modellversion die Methode delete_model_version() der MLflow-Client-API:
# Delete versions 1,2, and 3 of the model
client = MlflowClient()
versions=[1, 2, 3]
for version in versions:
client.delete_model_version(name="<model-name>", version=version)
Löschen eines Modells
Verwenden Sie zum Löschen eines Modells die Methode delete_registered_model() der MLflow-Client-API:
client = MlflowClient()
client.delete_registered_model(name="<model-name>")
Arbeitsbereichsübergreifendes Freigeben von Modellen
Databricks empfiehlt die Verwendung von Modellen in Unity Catalog, um Modelle arbeitsbereichübergreifend gemeinsam zu nutzen. Unity Catalog bietet vorgefertigte Unterstützung für arbeitsbereichsübergreifenden Modellzugriff, Governance und Überwachungsprotokollierung.
Wenn Sie jedoch die Arbeitsbereichsmodellregistrierung verwenden, können Sie mit einem gewissen Setup Modelle auch für mehrere Arbeitsbereiche freigeben. Sie können beispielsweise ein Modell in Ihrem eigenen Arbeitsbereich entwickeln und protokollieren und dann in einem anderen Arbeitsbereich über eine Remote-Arbeitsbereichsmodellregistrierung darauf zugreifen. Dies ist hilfreich, wenn mehrere Teams gemeinsam auf Modelle zugreifen. Sie können mehrere Arbeitsbereiche erstellen und Modelle in diesen Umgebungen verwenden und verwalten.
Kopieren von MLflow-Objekten zwischen Arbeitsbereichen
Um MLflow-Objekte in oder aus Ihrem Azure Databricks-Arbeitsbereich zu importieren oder zu exportieren, können Sie das communitygesteuerte Open-Source-Projekt MLflow Export-Import verwenden, um MLflow-Experimente, -Modelle und -Ausführungen zwischen Arbeitsbereichen zu migrieren.
Mit diesen Tools können Sie folgende Aktionen ausführen:
- Teilen und Zusammenarbeiten mit anderen wissenschaftlichen Fachkräften für Daten auf demselben oder einem anderen Nachverfolgungsserver. Sie können beispielsweise ein Experiment von einem anderen Benutzer in Ihren Arbeitsbereich klonen.
- Kopieren eines Modells von einem Arbeitsbereich in einen anderen, z. B. aus einem Entwicklungs- in einen Produktionsarbeitsbereich.
- Kopieren von MLflow-Experimenten und Ausführen dieser Experimente auf Ihrem lokalen Nachverfolgungsserver in Ihren Databricks-Arbeitsbereich.
- Sichern von unternehmenskritischen Experimenten und Modellen in einem anderen Databricks-Arbeitsbereich.
Beispiel
In diesem Beispiel wird veranschaulicht, wie Sie die Arbeitsbereichsmodellregistrierung zum Erstellen einer Machine Learning-Anwendung verwenden.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für