Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Wichtig
Dieses Feature befindet sich in der Public Preview.
Wichtig
- Diese Dokumentation wurde eingestellt und wird unter Umständen nicht aktualisiert. Die in diesem Inhalt erwähnten Produkte, Dienste oder Technologien werden nicht mehr unterstützt.
- Die Anleitungen in diesem Artikel gelten für die Legacy-MLflow-Modellbereitstellung. Databricks empfiehlt, Ihre Modellbereitstellungsworkflows zu Modellbereitstellung zu migrieren, um die Bereitstellung und Skalierbarkeit der Modellendpunkte zu verbessern. Weitere Informationen finden Sie unter Bereitstellen von Modellen mit Mosaik AI Model Serving.
Mit der Legacy-MLflow-Modellbereitstellung können Sie Machine Learning-Modelle über die Modellregistrierung als REST-Endpunkte hosten, die basierend auf der Verfügbarkeit von Modellversionen und ihren Phasen automatisch aktualisiert werden. Sie verwendet einen Einzelknotencluster, der unter Ihrem eigenen Konto auf der sogenannten klassischen Computeebene ausgeführt wird. Diese Computeebene umfasst das virtuelle Netzwerk (VNet) und die zugehörigen Computeressourcen, wie z. B. Cluster für Notebooks und Aufträge, SQL-Warehouses der Modi „Pro“ und „klassisch“ und Endpunkte für die Legacymodellbereitstellung.
Wenn Sie die Modellbereitstellung eines bestimmten registrierten Modells aktivieren, erstellt Azure Databricks automatisch einen eindeutigen Cluster für das Modell und stellte alle nicht archivierten Versionen dieses Modells in diesem Cluster bereit. Azure Databricks startet den Cluster neu, wenn ein Fehler auftritt, und beendet den Cluster, wenn Sie die Modellbereitstellung des Modells deaktivieren. Die Modellbereitstellung wird automatisch mit der Modellregistrierung synchronisiert und stellt alle neu registrierten Modellversionen bereit. Bereitgestellte Modellversionen können mit der REST-API-Standardanforderung abgefragt werden. Azure Databricks authentifiziert Anforderungen an das Modell mithilfe der Standardauthentifizierung.
Es wird empfohlen, diesen Dienst für Anwendungen mit geringem Durchsatz oder nicht kritische Anwendungen zu verwenden, während er sich in der Vorschau befindet. Der Zieldurchsatz beträgt 200 QPS und die Zielverfügbarkeit beträgt 99,5 %, wobei für beides keine Garantie übernommen wird. Darüber hinaus gilt eine Nutzlastgrößenbeschränkung von 16 MB pro Anforderung.
Jede Modellversion wird mithilfe der MLflow-Modellbereitstellung bereitgestellt und wird in einer Conda-Umgebung ausgeführt, die durch ihre Abhängigkeiten angegeben wird.
Hinweis
- Der Cluster wird verwaltet, solange die Bereitstellung aktiviert ist, auch wenn keine aktive Modellversion existiert. Deaktivieren Sie die Modellbereitstellung des registrierten Modells, um den Bereitstellungscluster zu beenden.
- Der Cluster wird als universeller Cluster betrachtet. Es gelten die Preise für universelle Workloads.
- Globale Initialisierungsskripts können nicht in Modellbereitstellungsclustern ausgeführt werden.
Wichtig
Anaconda Inc. hat die Vertragsbedingungen für die Kanäle von anaconda.org aktualisiert. Basierend auf den neuen Nutzungsbedingungen benötigen Sie möglicherweise eine kommerzielle Lizenz, wenn Sie sich auf die Verpackung und Verteilung von Anaconda verlassen. Weitere Informationen finden Sie unter Anaconda Commercial Edition FAQ (Häufig gestellte Fragen zu Anaconda Commercial Edition). Jegliche Nutzung von Anaconda-Kanälen unterliegt den Anaconda-Vertragsbedingungen.
MLflow-Modelle, die vor v1.18 (Databricks Runtime 8.3 ML oder früher) wurden standardmäßig mit dem conda-defaults Kanal (https://repo.anaconda.com/pkgs/) als Abhängigkeit protokolliert. Aufgrund dieser Lizenzänderung hat Databricks die Verwendung des defaults-Kanals für Modelle beendet, die mit MLflow v1.18 und höher protokolliert werden. Der protokollierte Standardkanal ist jetzt conda-forge, der auf die verwaltete Community https://conda-forge.org/ verweist.
Wenn Sie ein Modell vor MLflow v1.18 protokolliert haben, ohne den Kanal defaults aus der conda-Umgebung für das Modell auszuschließen, hat dieses Modell möglicherweise eine Abhängigkeit vom Kanal defaults, den die Sie möglicherweise nicht beabsichtigt haben.
Um manuell zu überprüfen, ob ein Modell diese Abhängigkeit aufweist, können Sie den Wert von channel in der Datei conda.yaml untersuchen, die mit dem protokollierten Modell gepackt ist. Ein Modell conda.yaml mit einer defaults Kanalabhängigkeit kann z. B. wie folgt aussehen:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Da Databricks nicht bestimmen kann, ob Ihre Verwendung des Anaconda-Repositorys für die Interaktion mit Ihren Modellen gemäß Ihrer Beziehung mit Anaconda zulässig ist, erzwingt Databricks keine Änderungen von der Kundschaft. Wenn Ihre Nutzung des Anaconda.com Repo durch die Verwendung von Databricks unter den Bedingungen von Anaconda zulässig ist, müssen Sie keine Maßnahmen ergreifen.
Wenn Sie den in der Umgebung eines Modells verwendeten Kanal ändern möchten, können Sie das Modell mit einem neuen conda.yaml erneut im Modellregister registrieren. Dazu geben Sie den Kanal im conda_env-Parameter von log_model() an.
Weitere Informationen zur log_model()-API finden Sie in der MLflow-Dokumentation für die Modellvariante, mit der Sie arbeiten, zum Beispiel log_model für scikit-learn.
Weitere Informationen zu conda.yaml-Dateien finden Sie in der MLflow-Dokumentation.
Anforderungen
- Die Legacy-MLflow-Modellverarbeitung ist für Python-MLflow-Modelle verfügbar. Sie müssen alle Modellabhängigkeiten in der Conda-Umgebung deklarieren. Weitere Informationen finden Sie unter Protokollieren von Modellabhängigkeiten.
- Sie müssen über die Berechtigung zum Erstellen von Clustern verfügen, um die Modellbereitstellung zu aktivieren.
Modellbereitstellung über die Modellregistrierung
Die Modellbereitstellung ist in Azure Databricks über die Modellregistrierung verfügbar.
Aktivieren und Deaktivieren der Modellbereitstellung
Sie können ein Modell über die Seite des registrierten Modells zur Bereitstellung aktivieren.
Klicken Sie auf die Registerkarte Serving (Bereitstellung). Wenn das Modell noch nicht zur Bereitstellung aktiviert ist, wird die Schaltfläche Enable Serving (Bereitstellung aktivieren) angezeigt.
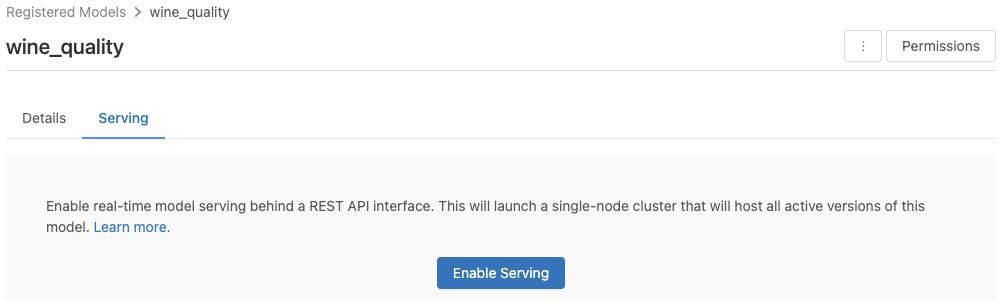
Klicken Sie auf Enable Serving (Bereitstellung aktivieren). Die Registerkarte „Serving“ (Bereitstellung) wird angezeigt, wobei der Status „Ausstehend“ lautet. Nach einigen Minuten ändert sich der Status in „Bereit“.
Klicken Sie auf Beenden, um die Bereitstellung eines Modells zu deaktivieren.
Überprüfen der Modellbereitstellung
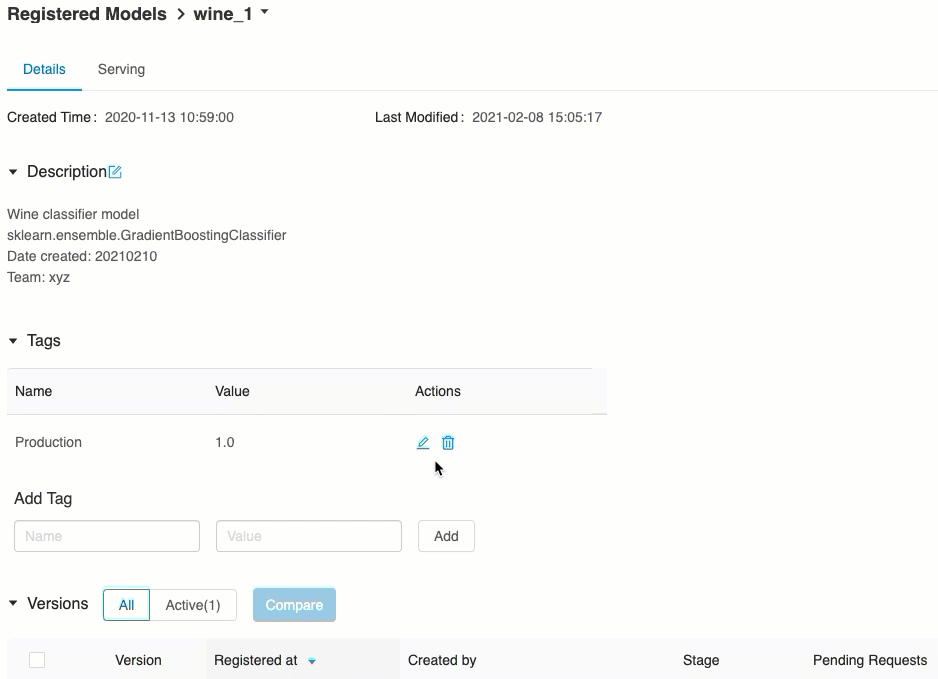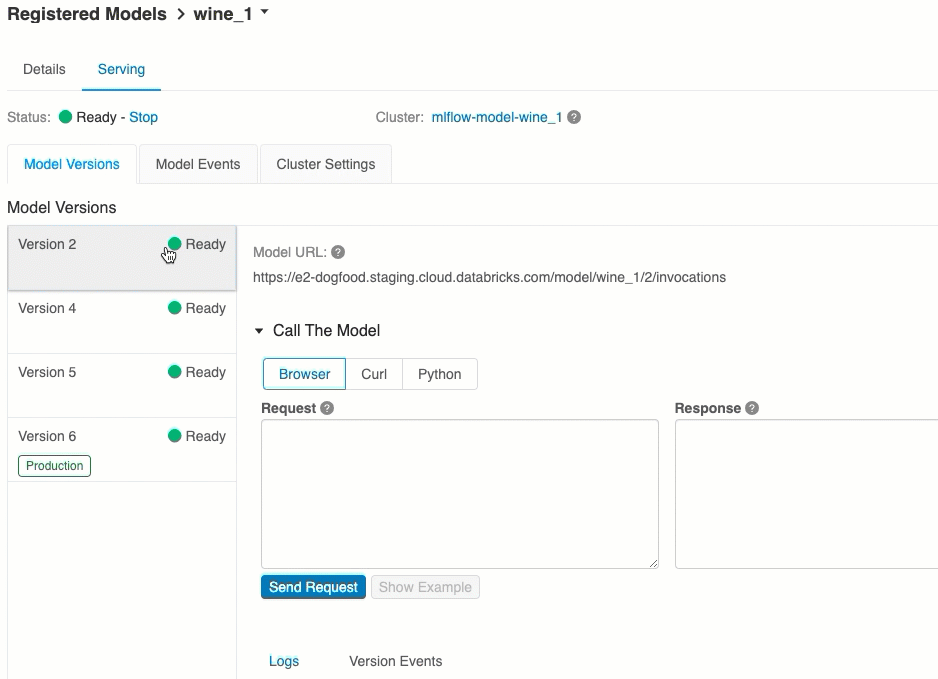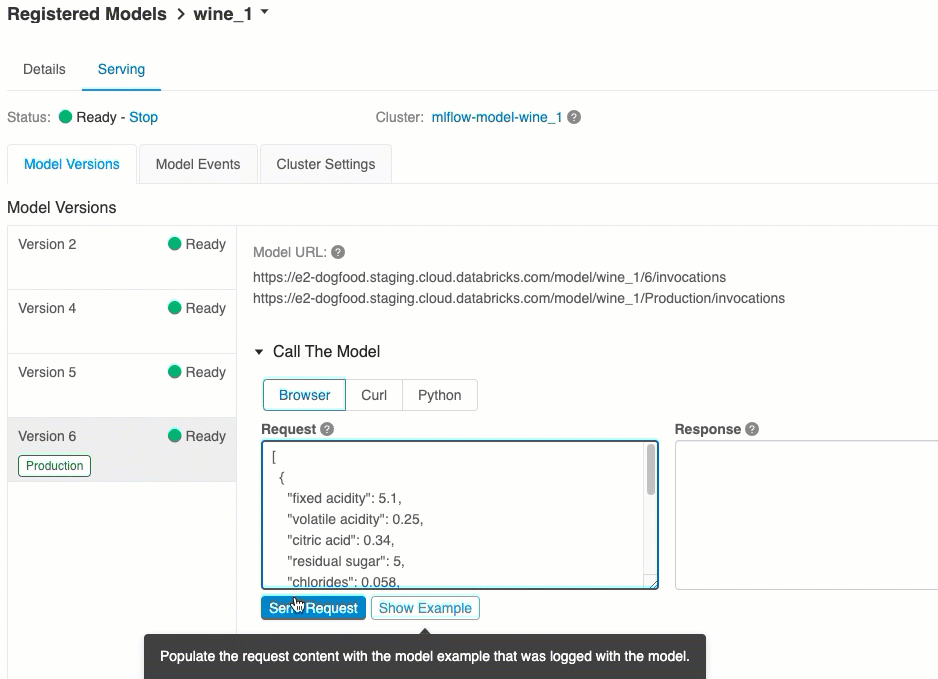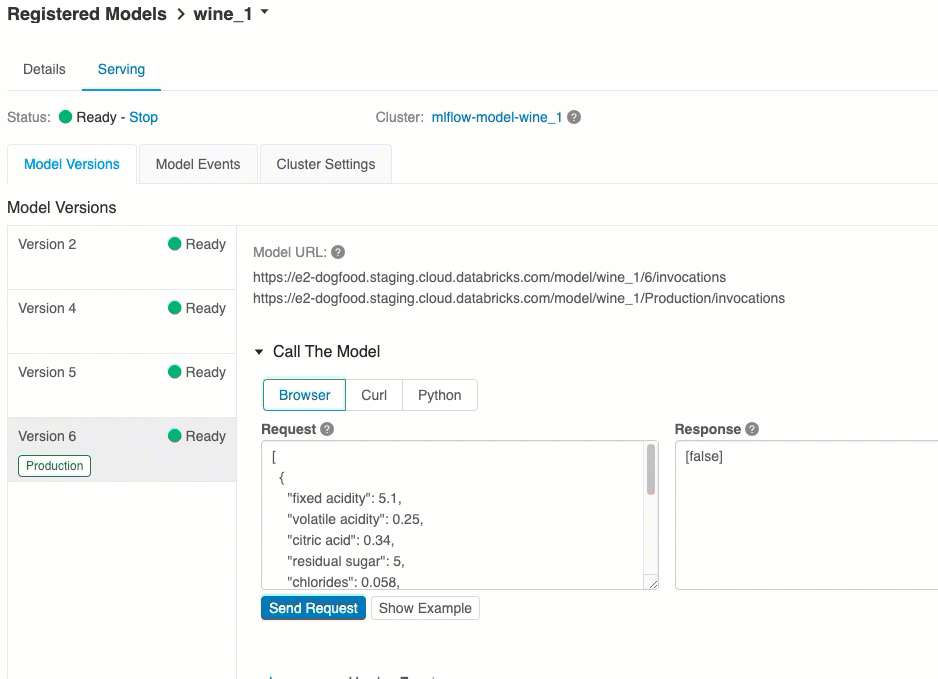
Auf der Registerkarte Serving können Sie eine Anforderung an das bereitgestellte Modell senden und die Antwort anzeigen.
Modellversions-URIs
Jeder bereitgestellten Modellversion wird ein eindeutiger URI oder mehrere eindeutige URIS zugewiesen. Jeder Modellversion wird mindestens ein URI zugewiesen, der wie folgt aufgebaut ist:
<databricks-instance>/model/<registered-model-name>/<model-version>/invocations
Verwenden Sie beispielsweise den folgenden URI, um Version 1 eines registrierten Modells als iris-classifier aufzurufen:
https://<databricks-instance>/model/iris-classifier/1/invocations
Sie können eine Modellversion auch anhand ihrer Phase abrufen. Wenn sich Version 1 beispielsweise in der Phase Production (Produktion) befindet, kann sie auch mit diesem URI bewertet werden:
https://<databricks-instance>/model/iris-classifier/Production/invocations
Die Liste der verfügbaren Modell-URIs wird oben auf der Registerkarte „Modellversionen“ auf der Seite „Serving“ (Bereitstellung) angezeigt.
Verwalten bereitgestellter Versionen
Alle aktiven (nicht archivierten) Modellversionen sind bereitgestellt, und Sie können sie mithilfe der URIs abfragen. Azure Databricks stellt automatisch neue Modellversionen bereit, wenn sie registriert werden, und entfernt automatisch alte Versionen, wenn sie archiviert werden.
Hinweis
Alle bereitgestellten Versionen eines registrierten Modells verwenden denselben Cluster.
Verwalten von Modellzugriffsrechten
Modellzugriffsrechte werden von der Modellregistrierung geerbt. Das Aktivieren oder Deaktivieren des Dienstfeatures erfordert die Berechtigung "Verwalten" für das registrierte Modell. Jede*r Benutzer*in mit Leserechten kann jede bereitgestellte Version bewerten.
Bewertung bereitgestellter Modellversionen
Sie können ein bereitgestelltes Modell über die Benutzeroberfläche oder durch das Senden einer REST-API-Anforderung an den Modell-URI bewerten.
Bewertung über die Benutzeroberfläche
Dies ist die einfachste und schnellste Weise, das Modell zu testen. Sie können die Modelleingabedaten im JSON-Format einfügen und auf Anforderung senden klicken. Wenn das Modell mit einem Eingabebeispiel protokolliert wurde (wie in der obigen Grafik dargestellt), klicken Sie auf Load Example (Beispiel laden), um das Eingabebeispiel zu laden.
Bewertung per REST-API-Anforderung
Sie können eine Bewertungsanforderung über die REST-API senden, indem Sie die Databricks-Standardauthentifizierung verwenden. In den folgenden Beispielen wird die Authentifizierung mithilfe eines persönlichen Zugriffstokens mit MLflow 1.x veranschaulicht.
Hinweis
Als bewährte Methode für die Sicherheit empfiehlt Databricks, dass Sie bei der Authentifizierung mit automatisierten Tools, Systemen, Skripten und Anwendungen persönliche Zugriffstoken verwenden, die zu Dienstprinzipalen und nicht zu Benutzern des Arbeitsbereichs gehören. Informationen zum Erstellen von Token für Dienstprinzipale finden Sie unter Verwalten von Token für einen Dienstprinzipal.
Die folgenden Beispiele zeigen, wie Sie ein bereitgestelltes Modell abfragen können. Dabei wird MODEL_VERSION_URI als https://<databricks-instance>/model/iris-classifier/Production/invocations-Wert (wobei <databricks-instance> der Name Ihrer Databricks-Instanz ist) und ein REST-API-Token für Databricks mit dem Namen DATABRICKS_API_TOKEN verwendet:
In den folgenden Beispielen wird das Bewertungsformat für mit MLflow 1.x erstellte Modelle verwendet. Wenn Sie lieber MLflow 2.0 verwenden möchten, müssen Sie das Format Ihrer Anforderungsnutzdaten aktualisieren.
Schlagen
In diesem Schnipsel wird ein Modell abgefragt, das Dataframe-Eingaben akzeptiert.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '[
{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}
]'
In diesem Schnipsel wird ein Modell abgefragt, das Tensoreingaben akzeptiert. Tensor-Eingaben sollten wie in den API-Dokumenten von TensorFlow Serving beschrieben formatiert werden.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'
Python
import numpy as np
import pandas as pd
import requests
def create_tf_serving_json(data):
return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()}
def score_model(model_uri, databricks_token, data):
headers = {
"Authorization": f"Bearer {databricks_token}",
"Content-Type": "application/json",
}
data_json = data.to_dict(orient='records') if isinstance(data, pd.DataFrame) else create_tf_serving_json(data)
response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json)
if response.status_code != 200:
raise Exception(f"Request failed with status {response.status_code}, {response.text}")
return response.json()
# Scoring a model that accepts pandas DataFrames
data = pd.DataFrame([{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
# Scoring a model that accepts tensors
data = np.asarray([[5.1, 3.5, 1.4, 0.2]])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
PowerBI
Sie können ein Dataset in Power BI Desktop wie folgt bewerten:
Öffnen Sie das Dataset, das Sie bewerten möchten.
Wechseln Sie zu „Daten transformieren“.
Klicken Sie mit der rechten Maustaste in den linken Bereich, und wählen Sie Create New Query (Neue Abfrage erstellen) aus.
Wechseln Sie zu Ansicht >Erweiterter Editor.
Ersetzen Sie den Abfragetext durch den folgenden Codeschnipsel, nachdem Sie ein entsprechendes
DATABRICKS_API_TOKENund einen entsprechendenMODEL_VERSION_URIangegeben haben.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionGeben Sie der Abfrage den gewünschten Modellnamen.
Öffnen Sie den erweiterten Abfrage-Editor für Ihr Dataset, und wenden Sie die Modellfunktion an.
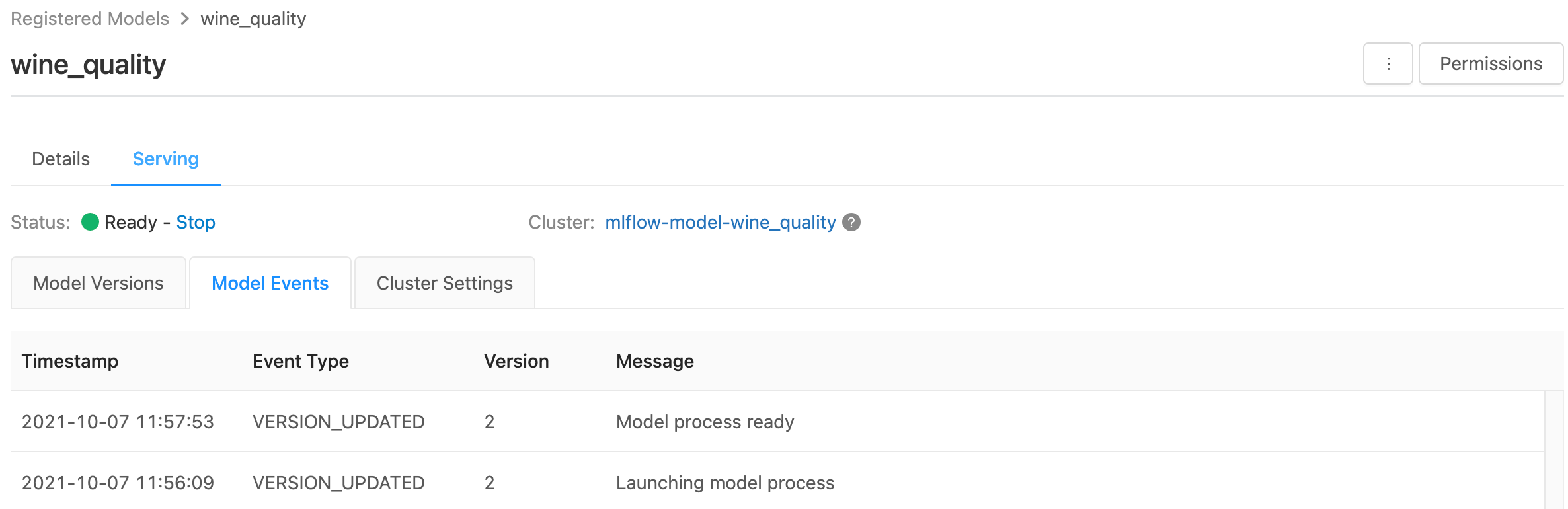
Überwachen bereitgestellter Modelle
Auf der Bereitstellungsseite werden Statusindikatoren des Bereitstellungsclusters sowie einzelne Modellversionen angezeigt.
- Um den Status des Bereitstellungsclusters zu überprüfen, verwenden Sie die Registerkarte Model Events (Modellereignisse), auf der eine Liste aller Bereitstellungsereignisse für dieses Modell angezeigt wird.
- Um den Status einer einzelnen Modellversion zu untersuchen, klicken Sie auf die Registerkarte Modellversionen, und scrollen Sie zu den Registerkarten Protokolle und Version Events (Versionsereignisse).
Anpassen des Bereitstellungsclusters
Verwenden Sie die Registerkarte Clustereinstellungen auf der Registerkarte Serving (Bereitstellung), um den Bereitstellungscluster anzupassen.
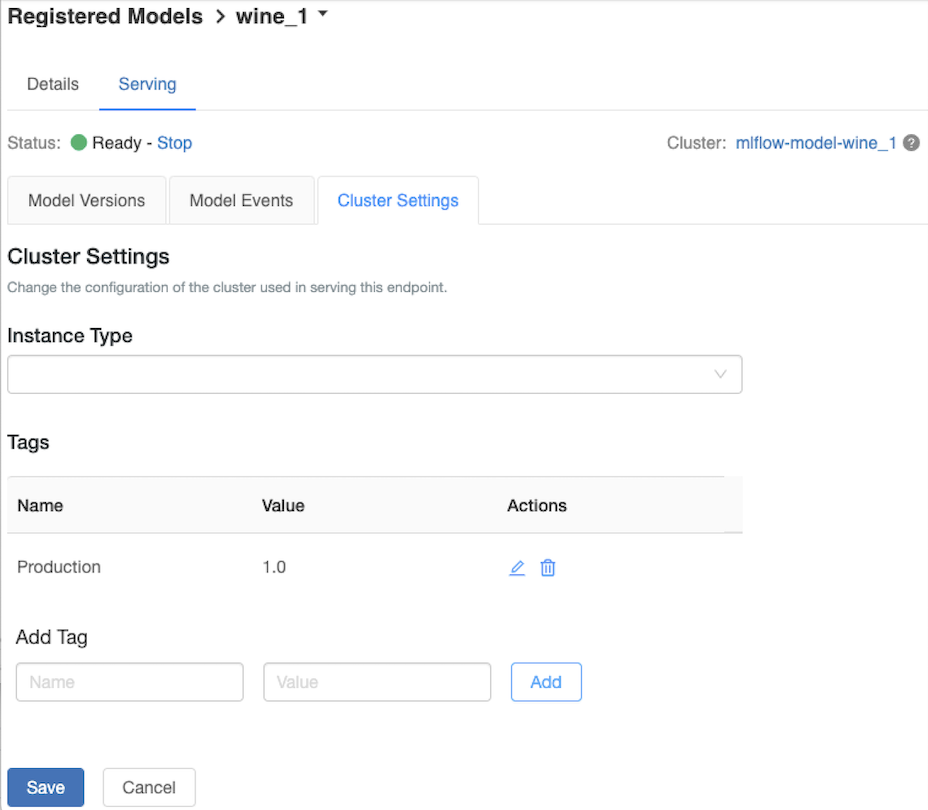
- Wenn Sie die Speichergröße und die Anzahl der Kerne eines Bereitstellungscluster ändern möchten, verwenden Sie das Dropdownmenü Instanzentyp, um die gewünschte Clusterkonfiguration auszuwählen. Wenn Sie auf Speichern klicken, wird der vorhandene Cluster gelöscht, und ein neuer Cluster wird mit den angegebenen Einstellungen erstellt.
- Geben Sie den Namen und den Wert im Feld Tag hinzufügen ein, und klicken Sie auf Hinzufügen, um einen Tag hinzuzufügen.
- Klicken Sie auf eines der Symbole in der Spalte Aktionen der Tabelle Tags, um ein vorhandenes Tag zu bearbeiten oder zu löschen.
Integration des Featurespeichers
Die Legacy-Modellbereitstellung kann automatisch Featurewerte aus veröffentlichten Onlinespeichern suchen.
Databricks Legacy MLflow Model Serving unterstützt die automatische Featureabfrage aus diesen Online-Datenspeichern.
- Azure Cosmos DB (v0.5.0 und höher)
- Azure-Datenbank für MySQL
Bekannte Fehler
ResolvePackageNotFound: pyspark=3.1.0
Dieser Fehler kann auftreten, wenn ein Model von pyspark abhängt und mithilfe von Databricks Runtime 8.x protokolliert wird.
Wenn dieser Fehler angezeigt wird, geben Sie die pyspark-Version beim Protokollieren des Modells mithilfe des conda_env-Parameters explizit an.
Unrecognized content type parameters: format
Dieser Fehler kann aufgrund des neuen MLflow 2.0-Bewertungsprotokollformats auftreten. Wenn dieser Fehler angezeigt wird, verwenden Sie wahrscheinlich ein veraltetes Bewertungsanforderungsformat. Zum Beheben des Fehlers haben Sie folgende Möglichkeiten:
Sie können Ihr Bewertungsanforderungsformat auf das neueste Protokoll aktualisieren.
Hinweis
Die folgenden Beispiele zeigen das in MLflow 2.0 eingeführte Bewertungsformat. Wenn Sie MLflow 1.x bevorzugen, können Sie Ihre
log_model()-API-Aufrufe so ändern, dass sie die gewünschte MLflow-Versionsabhängigkeit imextra_pip_requirements-Parameter enthalten. Dadurch wird sichergestellt, dass das geeignete Bewertungsformat verwendet wird.mlflow.<flavor>.log_model(..., extra_pip_requirements=["mlflow==1.*"])Schlagen
Fragen Sie ein Modell ab, das Pandas-Datenrahmeneingaben akzeptiert.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{ "dataframe_records": [{"sepal_length (cm)": 5.1, "sepal_width (cm)": 3.5, "petal_length (cm)": 1.4, "petal_width": 0.2}, {"sepal_length (cm)": 4.2, "sepal_width (cm)": 5.0, "petal_length (cm)": 0.8, "petal_width": 0.5}] }'Fragen Sie ein Modell ab, das Tensoreingaben akzeptiert. Tensor-Eingaben sollten wie in den API-Dokumenten von TensorFlow Serving beschrieben formatiert werden.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'Python
import numpy as np import pandas as pd import requests def create_tf_serving_json(data): return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()} def score_model(model_uri, databricks_token, data): headers = { "Authorization": f"Bearer {databricks_token}", "Content-Type": "application/json", } data_dict = {'dataframe_split': data.to_dict(orient='split')} if isinstance(data, pd.DataFrame) else create_tf_serving_json(data) data_json = json.dumps(data_dict) response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json) if response.status_code != 200: raise Exception(f"Request failed with status {response.status_code}, {response.text}") return response.json() # Scoring a model that accepts pandas DataFrames data = pd.DataFrame([{ "sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2 }]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data) # Scoring a model that accepts tensors data = np.asarray([[5.1, 3.5, 1.4, 0.2]]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)PowerBI
Sie können ein Dataset in Power BI Desktop wie folgt bewerten:
Öffnen Sie das Dataset, das Sie bewerten möchten.
Wechseln Sie zu „Daten transformieren“.
Klicken Sie mit der rechten Maustaste in den linken Bereich, und wählen Sie Create New Query (Neue Abfrage erstellen) aus.
Wechseln Sie zu Ansicht >Erweiterter Editor.
Ersetzen Sie den Abfragetext durch den folgenden Codeschnipsel, nachdem Sie ein entsprechendes
DATABRICKS_API_TOKENund einen entsprechendenMODEL_VERSION_URIangegeben haben.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionGeben Sie der Abfrage den gewünschten Modellnamen.
Öffnen Sie den erweiterten Abfrage-Editor für Ihr Dataset, und wenden Sie die Modellfunktion an.
Wenn Ihre Bewertungsanforderung den MLflow-Client verwendet, z. B.
mlflow.pyfunc.spark_udf(), aktualisieren Sie Ihren MLflow-Client auf Version 2.0 oder höher, um das neueste Format zu verwenden. Erfahren Sie mehr über das aktualisierte MLflow-Modellbewertungsprotokoll in MLflow 2.0.
Weitere Informationen zu Eingabedatenformaten, die vom Server akzeptiert werden (z. B. das split-orientierte Format von pandas) finden Sie in der Dokumentation zu MLflow.