Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Auf dieser Seite wird erläutert, wie Azure Databricks Lakeguard verwendet, um die Benutzerisolation in gemeinsam genutzten Computeumgebungen zu erzwingen und eine differenzierte Zugriffssteuerung im dedizierten Compute zu steuern.
Was ist Lakeguard?
Lakeguard ist eine Reihe von Technologien für Databricks, die Codeisolation und Datenfilterung erzwingen, sodass mehrere Benutzer dieselbe Recheneinheit sicher und kosteneffizient nutzen können und auf Daten mit feingranulierten Zugriffssteuerungen zugreifen können, die auf der Recheneinheit bereitgestellt werden, welche privilegierten Maschinenzugriff bietet.
Wie funktioniert Lakeguard?
In gemeinsam genutzten Computeumgebungen wie klassischen Compute-, serverlosen Compute- und SQL-Warehouses isoliert Lakeguard den Benutzercode vom Spark-Modul und von anderen Benutzern. Dieses Design ermöglicht es vielen Benutzern, dieselben Computeressourcen gemeinsam zu nutzen und gleichzeitig strenge Grenzen zwischen Benutzern, dem Spark-Treiber und Executoren beizubehalten.
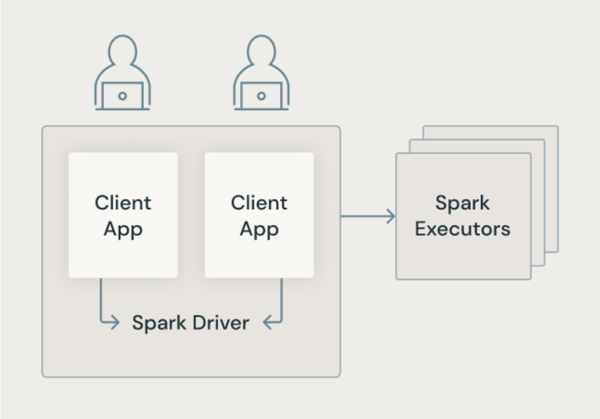
Klassische Spark-Architektur
Die folgende Abbildung zeigt, wie in der herkömmlichen Spark-Architektur Benutzeranwendungen einen JVM mit privilegiertem Zugriff auf den zugrunde liegenden Computer teilen.
Lakeguard-Architektur
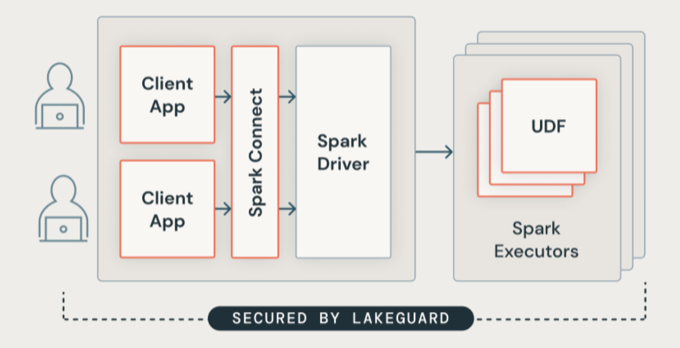
Lakeguard isoliert den gesamten Benutzercode mit sicheren Containern. Auf diese Weise können mehrere Workloads auf derselben Computeressource ausgeführt werden und gleichzeitig die strikte Isolation zwischen Benutzern beibehalten werden.
Spark-Clientisolation
Lakeguard isoliert Clientanwendungen vom Spark-Treiber und voneinander mit zwei Schlüsselkomponenten:
Spark Connect: Lakeguard verwendet Spark Connect (eingeführt mit Apache Spark 3.4), um Clientanwendungen vom Treiber zu entkoppeln. Clientanwendungen und Treiber teilen nicht mehr denselben JVM oder Klassenpfad. Diese Trennung verhindert nicht autorisierten Datenzugriff. Dieses Design verhindert auch, dass Benutzer auf Daten zugreifen, die sich aus dem Überholen ergeben, wenn Abfragen Filter auf Zeilen- oder Spaltenebene enthalten.
Hinweis
Spark Connect verschiebt die Analyse und Namensauflösung auf die Ausführungszeit, wodurch sich das Verhalten Ihres Codes ändern kann. Siehe "Vergleichen von Spark Connect" mit Spark Classic.
Container-Sandkasten: Jede Clientanwendung wird in einer eigenen isolierten Containerumgebung ausgeführt. Dadurch wird verhindert, dass Benutzercode auf die Daten anderer Benutzer oder den zugrunde liegenden Computer zugreift. Die Sandkastenumgebung verwendet containerbasierte Isolationstechniken, um sichere Grenzen zwischen Benutzern zu erstellen.
UDF-Isolation
Standardmäßig isolieren Spark-Executoren UDFs nicht. Dieser Mangel an Isolation kann UDFs das Schreiben von Dateien oder den Zugriff auf den zugrunde liegenden Computer ermöglichen.
Lakeguard isoliert benutzerdefinierten Code, einschließlich UDFs, auf Spark-Executoren durch:
- Sandkasten der Ausführungsumgebung für Spark-Executors.
- Isolieren des Netzwerkdatenverkehrs von UDFs, um nicht autorisierten externen Zugriff zu verhindern.
- Replizieren der Clientumgebung in die UDF-Sandbox, damit Benutzer auf erforderliche Bibliotheken zugreifen können.
Diese Isolation gilt für UDFs auf Standard compute und python UDFs auf serverlosen Compute- und SQL-Warehouses.