Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel werden die wichtigsten Unterschiede zwischen Batch und Streaming beschrieben, zwei verschiedene Datenverarbeitungssemantiken, die für Data-Engineering-Workloads verwendet werden, einschließlich Aufnahme, Transformation und Echtzeitverarbeitung.
Streaming ist in der Regel mit geringer Latenz und kontinuierlicher Verarbeitung von Nachrichtenbussen wie Apache Kafka verbunden.
In Azure Databricks hat es jedoch eine umfangreichere Definition. Das zugrunde liegende Modul von Lakeflow Spark Declarative Pipelines (Apache Spark und Structured Streaming) verfügt über eine einheitliche Architektur für die Batch- und Streamingverarbeitung:
- Das Modul kann Quellen wie Cloudobjektspeicher und Delta Lake als Streamingquellen für eine effiziente inkrementelle Verarbeitung behandeln.
- Die Streamingverarbeitung kann sowohl ausgelöst als auch kontinuierlich ausgeführt werden, sodass Sie die Flexibilität haben, Kosten und Leistungsanforderungen für Ihre Streaming-Arbeitslasten anzupassen.
Nachfolgend finden Sie die grundlegenden semantischen Unterschiede, die Batch- und Streaming unterscheiden, einschließlich deren Vor- und Nachteile sowie Überlegungen zur Auswahl für Ihre Workloads.
Batchsemantik
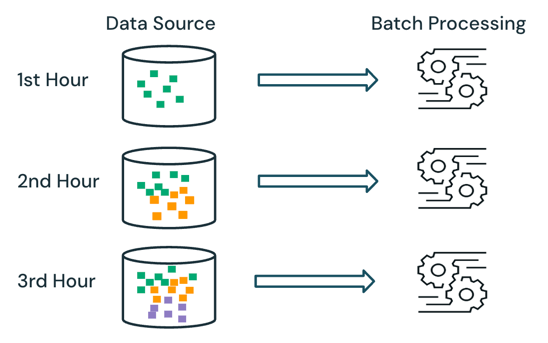
Bei der Batchverarbeitung verfolgt das Modul nicht, welche Daten bereits in der Quelle verarbeitet werden. Alle derzeit in der Quelle verfügbaren Daten werden zum Zeitpunkt der Verarbeitung verarbeitet. In der Praxis wird eine Batchdatenquelle in der Regel logisch partitioniert, z. B. nach Tag oder Region, um die Datenverarbeitung einzuschränken.
Beispielsweise kann die Berechnung des durchschnittlichen Artikelverkaufspreises, stündlich aggregiert für ein von einem E-Commerce-Unternehmen durchgeführtes Verkaufsereignis, als Batchverarbeitung geplant werden, um jede Stunde den durchschnittlichen Verkaufspreis zu berechnen. Bei Batch werden Daten aus früheren Stunden jede Stunde neu verarbeitet, und die zuvor berechneten Ergebnisse werden überschrieben, um die neuesten Ergebnisse widerzuspiegeln.
Streamingsemantik
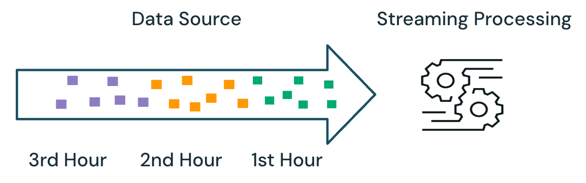
Mit der Streamingverarbeitung verfolgt das Modul, welche Daten verarbeitet werden, und verarbeitet nur neue Daten in nachfolgenden Ausführungen. Im obigen Beispiel können Sie die Streamingverarbeitung anstelle der Batchverarbeitung planen, um den durchschnittlichen Verkaufspreis jede Stunde zu berechnen. Beim Streaming werden nur neue Daten, die der Quelle seit der letzten Ausführung hinzugefügt wurden, verarbeitet. Die neu berechneten Ergebnisse müssen an die zuvor berechneten Ergebnisse angefügt werden, um die vollständigen Ergebnisse zu überprüfen.
Batch im Vergleich zum Streaming
Im obigen Beispiel ist Streaming besser als die Batchverarbeitung, da sie nicht dieselben Daten verarbeitet, die in früheren Ausführungen verarbeitet wurden. Die Streamingverarbeitung wird jedoch komplexer mit Szenarien wie unsortierten und verspätet eintreffenden Daten in der Datenquelle.
Ein Beispiel für späte Ankunftsdaten ist, wenn einige Umsatzdaten aus der ersten Stunde erst nach der zweiten Stunde an der Quelle ankommen:
- Bei der Batchverarbeitung werden die Spätankunftsdaten aus der ersten Stunde mit Daten aus der zweiten Stunde und vorhandenen Daten aus der ersten Stunde verarbeitet. Die vorherigen Ergebnisse aus der ersten Stunde werden überschrieben und mit den Verspäteten Ankunftsdaten korrigiert.
- Bei der Streamingverarbeitung werden die verspätet eintreffenden Daten aus der ersten Stunde ohne die bereits verarbeiteten anderen Daten der ersten Stunde verarbeitet. Die Verarbeitungslogik muss die Summen- und Zählungsinformationen aus den Durchschnittsberechnungen der ersten Stunde speichern, um die vorherigen Ergebnisse ordnungsgemäß zu aktualisieren.
Diese Komplexitäten des Streamings werden in der Regel eingeführt, wenn die Verarbeitung zustandsbehaftet ist, z. B. Verknüpfungen, Aggregationen und Deduplizierungen.
Für die zustandslose Streamingverarbeitung, wie das Anfügen neuer Daten aus der Quelle, ist die Verarbeitung von Out-of-Order- und Spätankunftsdaten weniger komplex, da die spät eingehenden Daten beim Eintreffen in der Quelle an die vorherigen Ergebnisse angefügt werden können.
In der folgenden Tabelle sind die Vor- und Nachteile der Batch- und Streamingverarbeitung sowie die verschiedenen Produktfeatures aufgeführt, die diese beiden Verarbeitungsemantik in Databricks Lakeflow unterstützen.
| Verarbeiten der Semantik | Vorteile | Nachteile | Data Engineering-Produkte |
|---|---|---|---|
| Stapel |
|
|
|
| Streamen |
|
|
|
Empfehlungen
Die folgende Tabelle enthält die empfohlene Verarbeitungsemantik basierend auf den Merkmalen der Datenverarbeitungsworkloads auf jeder Ebene der Medallion-Architektur.
| Medaillonschicht | Arbeitsauslastungsmerkmale | Empfehlung |
|---|---|---|
| Bronze |
|
|
| Silber |
|
|
| Gold |
|
|