Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Die Schemaentwicklung bezieht sich auf die Fähigkeit eines Systems, sich an Änderungen der Datenstruktur im Laufe der Zeit anzupassen. Diese Änderungen werden häufig verwendet, wenn sie mit halbstrukturierten Daten, Ereignisdatenströmen oder Quellen von Drittanbietern arbeiten, bei denen neue Felder hinzugefügt, Datentypen verschoben oder geschachtelte Strukturen weiterentwickelt werden.
Zu den allgemeinen Änderungen gehören:
- Neue Spalten: Zusätzliche Felder, die zuvor nicht definiert wurden, manchmal mit einem benutzerdefinierten Rückfüllwert.
-
Spaltenumbenennung: Ändern eines Spaltennamens, z. B. von
name" infull_name". - Verworfene Spalten: Entfernen von Spalten aus dem Tabellenschema.
-
Typweiterung: Ändern des Typs einer Spalte in einen breiteren. Beispiel: Ein
INTFeld wird .DOUBLE -
Andere Typänderungen: Ändern des Typs einer Spalte. Beispiel: Ein
INTFeld wird .STRING
Die Unterstützung der Schemaevolution ist wichtig für die Erstellung robuster, lang laufender Pipelines, die Änderungen berücksichtigen können, ohne häufige manuelle Updates zu erfordern.
Komponenten
Die Schemaentwicklung von Azure Databricks umfasst vier Hauptkomponentenkategorien, wobei jede Schemaänderung unabhängig voneinander behandelt wird:
- Connectors: Komponenten, die Daten aus externen Quellen aufnehmen. Dazu gehören Auto Loader-, Kafka-, Kinesis- und Lakeflow-Verbinder.
-
Formatparser: Funktionen, die unformatierte Formate decodieren, einschließlich
from_json,from_avro, ,from_xmlundfrom_protobuf. - Engines: Verarbeitungsmodule, die Abfragen ausführen, einschließlich strukturiertem Streaming.
- Datensätze: Streamingtabellen, materialisierte Ansichten, Delta-Tabellen und Ansichten, die Daten beibehalten und bereitstellen.
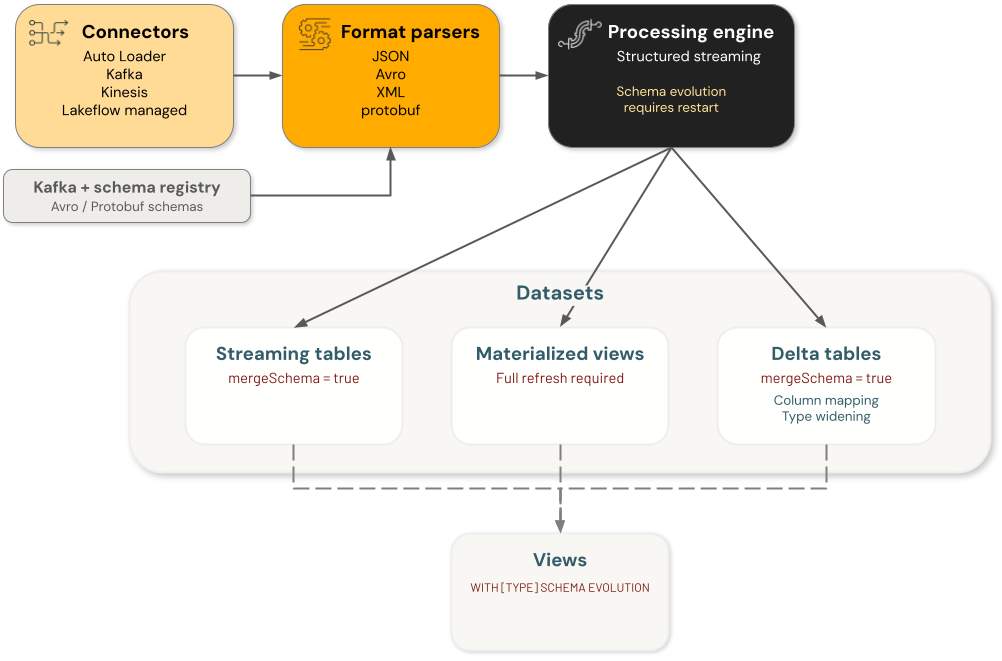
Jede Komponente in der Schemaentwicklung der Datentechnik ist unabhängig. Sie sind für die Konfiguration der Schemaentwicklung in einzelnen Komponenten verantwortlich, um das gewünschte Verhalten in Ihrem Datenverarbeitungsfluss zu erzielen.
Wenn Sie z. B. das automatische Ladeprogramm zum Aufnehmen von Daten in eine Delta-Tabelle verwenden, gibt es zwei beibehaltene Schemas – eines wird vom automatischen Laden an seinem Schemaspeicherort verwaltet, und das andere ist das Schema der Zieldelta-Tabelle. In einem stabilen Zustand sind diese beiden identisch. Wenn auto Loader sein Schema basierend auf eingehenden Daten weiterentwickelt, muss die Delta-Tabelle auch ihr Schema weiterentwickeln, oder die Abfrage schlägt fehl. In diesem Fall können Sie (a) das Ziel-Delta-Tabellenschema aktualisieren, indem Sie die Schemaentwicklung aktivieren oder einen direkten DDL-Befehl verwenden oder (b) eine vollständige Neuschreibung der Ziel-Delta-Tabelle durchführen.
Unterstützung der Schemaentwicklung durch den Connector
In den folgenden Abschnitten wird erläutert, wie jede Azure Databricks-Komponente verschiedene Arten von Schemaänderungen behandelt.
Automatischer Lader
Auto Loader unterstützt Spaltenänderungen und die Veränderung von Datentypen. Konfigurieren der automatischen Schemaentwicklung mit cloudFiles.schemaEvolutionMode und rescuedDataColumn. Sie können schemaHints manuell festlegen oder ein unveränderliches schema festlegen. Beim automatischen Entwickeln des Schemas schlägt der Datenstrom zunächst fehl. Beim Neustart wird das weiterentwickelte Schema verwendet. Erfahren Sie , wie funktioniert die Schemaentwicklung des automatischen Ladens?.
-
Neue Spalten: Unterstützt, abhängig von der Auswahl von
schemaEvolutionMode. Fehler bei einem manuellen Neustart, der zum Hinzufügen neuer Spalten zum Schema erforderlich ist. -
Spaltenumbenennung: Unterstützt, abhängig von der
schemaEvolutionModeAuswahl. Die umbenannte Spalte wird als neue Spalte behandelt, und die alte Spalte wird für neue Zeilen mitNULLausgefüllt. Fehler bei einem manuellen Neustart, der zum Aktualisieren des Schemas erforderlich ist. -
Entfernte Spalten: Unterstützt. Behandelt als weiche Löschungen, wobei neue Zeilen für die gelöschte Spalte auf
NULLfestgelegt werden. -
Typenerweiterung: Wird unterstützt in der Databricks Runtime 16.4 und höher, wenn
schemaEvolutionModeaufaddNewColumnsWithTypeWideninggesetzt ist. Unterstützte Änderungen von Datentypen werden automatisch verbreitert. Nicht unterstützte Typänderungen werden in demrescuedDataColumnerfasst. Siehe Automatisches Typen-Widening mit Auto Loader. -
Andere Typänderungen: Nicht unterstützt. Typänderungen werden in
rescuedDataColumnerfasst, wennrescueDataColumngesetzt ist undschemaEvolutionModeaufrescuefestgelegt ist. Andernfalls ist eine manuelle Schemaänderung erforderlich.
Delta-Anschluss
Der Delta-Connector kann die Schemaentwicklung unterstützen. Wenn Sie aus einer Delta-Tabelle lesen und die Spaltenzuordnung sowie schemaTrackingLocation aktiviert sind, wird die Schemaentwicklung für Spaltenumbenennung und entfernte Spalten unterstützt. Sie müssen die richtige Spark-Konfiguration für jede dieser jeweiligen Änderungen festlegen, um das Schema zu entwickeln, ohne den Datenstrom zu beenden. Andernfalls aktualisiert der Datenstrom das überwachte Schema, wenn eine Änderung erkannt wird, und stoppt dann. Anschließend müssen Sie die Streamingabfrage manuell neu starten, um die Verarbeitung fortzusetzen.
-
Neue Spalten: Unterstützt. Mit
mergeSchemaaktivierter Option werden neue Spalten automatisch hinzugefügt. Andernfalls schlägt die Abfrage fehl, und Sie müssen den Datenstrom neu starten, um die neuen Spalten zum Schema hinzuzufügen, die Delta-Tabelle erfordert jedoch keine Neuschreibung. - Spaltenumbenennung: Unterstützt. Bei
mergeSchemaaktivierter Option wird die Umbenennung automatisch behandelt. Andernfalls können Sie das Schema innerhalb einer Streamingabfrage mit der Spark-Konfigurationspark.databricks.delta.streaming.allowSourceColumnRenameweiterentwickeln. -
Entfernte Spalten: Unterstützt. Mit aktiviertem
mergeSchemawerden entfernte Spalten automatisch verwaltet. Andernfalls können Sie das Schema innerhalb einer Streamingabfrage mit der Spark-Konfigurationspark.databricks.delta.streaming.allowSourceColumnDropweiterentwickeln. -
Typweiterung: Unterstützt in Databricks Runtime 16.4 LTS und höher. Wenn
mergeSchemaaktiviert ist und die Typweiterung in der Zieltabelle aktiviert wurde, werden die Typänderungen automatisch behandelt. Sie können die Typweiterung mit dertype wideningTabelleneigenschaft aktivieren. - Andere Typänderungen: Nicht unterstützt.
SaaS- und CDC-Anschlüsse
Die SaaS- und CDC-Connectors entwickeln das Schema automatisch, wenn sich Spalten ändern. Dies wird durch einen automatischen Neustart behandelt, wenn eine Änderung erkannt wird. Typänderungen erfordern eine vollständige Aktualisierung.
- Neue Spalten: Unterstützt. Die Abfrage wird automatisch neu gestartet, um die Schemaabweichung zu beheben.
- Spaltenumbenennung: Unterstützt. Die Abfrage wird automatisch neu gestartet, um die Schemaabweichung zu beheben. Die umbenannte Spalte wird als neue Hinzugefügte Spalte behandelt.
-
Entfernte Spalten: Unterstützt. Gelöschte Spalten werden als sanft gelöscht behandelt, wobei neue Zeilen für die gelöschte Spalte auf
NULLfestgelegt werden. - Typweiterung: Nicht unterstützt. Zum Aktualisieren des Schemas ist eine vollständige Aktualisierung erforderlich.
- Andere Typänderungen: Nicht unterstützt. Zum Aktualisieren des Schemas ist eine vollständige Aktualisierung erforderlich.
Kinesis-, Kafka-, Pub/Sub- und Pulsar-Verbinder
Es wird keine systemeigene Schemaentwicklung unterstützt. Jede der Konnektor-Funktionen gibt ein binäres Blob zurück. Die Schemaentwicklung wird vom Formatparser behandelt.
- Neue Spalten: Vom Formatparser behandelt.
- Spaltenumbenennung: Wird vom Formatparser behandelt.
- Verworfene Spalten: Vom Formatparser behandelt.
- Type widening: Wird vom Formatparser verarbeitet.
- Andere Typänderungen: Vom Formatparser behandelt.
Unterstützung der Schema-Evolution durch einen Format-Parser
from_json Parser
Der from_json Parser unterstützt keine Schemaentwicklung. Sie müssen das Schema manuell aktualisieren. Wenn Sie in Lakeflow Spark Declarative Pipelines verwenden from_json , kann die automatische Schemaentwicklung mit schemaLocationKey und schemaEvolutionModeaktiviert werden.
- Neue Spalten: Wenn die automatische Schemaentwicklung aktiviert ist, verhält es sich wie das automatische Laden.
- Spaltenumbenennung: Wenn die automatische Schemaentwicklung aktiviert ist, funktioniert es wie Auto Loader.
- Verworfene Spalten: Wenn die automatische Schema-Evolution aktiviert ist, verhält es sich wie Auto Loader.
- Typverbreiterung: Wenn die automatische Schemaentwicklung aktiviert ist, verhält es sich wie Auto Loader.
- Andere Typänderungen: Wenn die automatische Schema-Evolution aktiviert ist, verhält sich das System wie der Auto Loader.
from_avro und from_protobuf Parser
Die from_avro Und from_protobuf Parser verhalten sich auf die gleiche Weise. Das Schema kann aus der Confluent-Schemaregistrierung abgerufen werden, oder der Benutzer kann ein Schema bereitstellen und muss das Schema manuell aktualisieren. Es gibt kein Konzept der Schemaentwicklung innerhalb der from_avro Oder from_protobuf Funktion. Sie muss vom Ausführungsmodul und der Schemaregistrierung behandelt werden.
- Neue Spalten: Unterstützt mit confluent Schema Registry. Andernfalls muss der Benutzer das Schema manuell aktualisieren.
- Spaltenumbenennung: Wird mit dem Confluent Schema Registry unterstützt. Andernfalls muss der Benutzer das Schema manuell aktualisieren.
- Entfernte Spalten: Unterstützt durch die Confluent Schema Registry. Andernfalls muss der Benutzer das Schema manuell aktualisieren.
- Type widening: Unterstützt durch Confluent Schema Registry. Andernfalls muss der Benutzer das Schema manuell aktualisieren.
- Andere Typänderungen: Unterstützt mit der Confluent Schema Registry. Andernfalls muss der Benutzer das Schema manuell aktualisieren.
from_csv und from_xml Parser
from_csv- und from_xml-Parser unterstützen keine Schemaentwicklung.
- Neue Spalten: Nicht unterstützt
- Spaltenumbenennung: Nicht unterstützt
- Verworfene Spalten: Nicht unterstützt
- Typweiterung: Nicht unterstützt
- Andere Typänderungen: Nicht unterstützt
Unterstützung der Schemaentwicklung durch Engine
Strukturiertes Streaming
Das Schema einer Streamingabfrage wird während der Planungsphase festgelegt, und alle Mikro-Batches verwenden diesen Plan ohne erneute Planung. Wenn sich das Quellschema in der Mitte der Ausführung ändert, schlägt die Abfrage fehl, und der Benutzer muss die Streamingabfrage neu starten, damit Spark das neue Schema neu planen kann.
Das Dataset, in das der Datenstrom schreibt, muss auch die Schemaentwicklung unterstützen.
- Neue Spalten: Unterstützt. Die Abfrage schlägt fehl, und Sie müssen den Datenstrom neu starten, um die Schemakonfliktigkeit zu beheben.
- Spaltenumbenennung: Unterstützt. Die Abfrage schlägt fehl, und Sie müssen den Datenstrom neu starten, um die Schemakonfliktigkeit zu beheben.
- Entfernte Spalten: Unterstützt. Die Abfrage schlägt fehl, und Sie müssen den Datenstrom neu starten, um die Schemakonfliktigkeit zu beheben.
- Typweiterung: Unterstützt. Die Abfrage schlägt fehl, und Sie müssen den Datenstrom neu starten, um die Schemakonfliktigkeit zu beheben.
- Andere Typänderungen: Unterstützt. Die Abfrage schlägt fehl, und Sie müssen den Datenstrom neu starten, um die Schemakonfliktigkeit zu beheben.
Schemaentwicklung nach Dataset
Streamingtabellen
Streamingtabellen unterstützen standardmäßig das Zusammenführen von Schemaentwicklungsverhalten . Das Aktualisieren des Schemas erfordert keinen manuellen Neustart, aber beliebige Schemaänderungen erfordern eine vollständige Aktualisierung.
- Neue Spalten: Unterstützt. Die Abfrage wird automatisch neu gestartet, um das Schema-Missverhältnis zu beheben.
- Spaltenumbenennung: Unterstützt. Die Abfrage wird neu gestartet, um das Schemakonflikt zu beheben. Die umbenannte Spalte wird als neue Hinzugefügte Spalte behandelt.
- Entfernte Spalten: Unterstützt. Gelöschte Spalten werden als Soft-Löschungen behandelt, wobei neue Zeilen für die gelöschte Spalte auf NULL festgelegt sind.
- Typweiterung: Unterstützt. Die Typerweiterung muss entweder auf Pipelineebene oder direkt in der Tabelle aktiviert sein. Siehe Typerweiterung in Lakeflow Spark Declarative Pipelines.
- Andere Typänderungen: Nicht unterstützt. Zum Aktualisieren des Schemas ist eine vollständige Aktualisierung erforderlich.
Materialisierte Ansichten
Jede Aktualisierung des Schemas oder die definierende Abfrage löst eine vollständige Neukompilierung der materialisierten Ansicht aus.
- Neue Spalten: Vollständige Neuberechnung ausgelöst.
- Spaltenumbenennung: Vollständige Neukompilierung ausgelöst.
- Verworfene Spalten: Vollständige Neuberechnung eingeleitet.
- Typenerweiterung: Vollständige Neuberechnung ausgelöst.
- Andere Typänderungen: Vollständige Neuberechnung ausgelöst.
Delta-Tabellen
Delta-Tabellen unterstützen eine Vielzahl von Konfigurationen zum Aktualisieren des Tabellenschemas, einschließlich Umbenennen, Ablegen und Verbreitern des Spaltentyps ohne Umschreiben von Tabellendaten. Unterstützte Konfigurationen umfassen die Zusammenführungsschemaentwicklung, Spaltenzuordnung, Typweiterung und overwriteSchema.
- Neue Spalten: Unterstützt. Wird automatisch weiterentwickelt, wenn die Zusammenführungsschemaentwicklung aktiviert ist, ohne dass eine Delta-Tabelle neu geschrieben werden muss. Wenn die Zusammenführungsschemaentwicklung nicht aktiviert ist, schlagen Updates fehl.
- Spaltenumbenennung: Unterstützt. Kann über manuelle
ALTER TABLE DDLBefehle umbenannt werden, wobei die Spaltenzuordnung aktiviert ist. Erfordert keine Neuschreibung einer Delta-Tabelle. -
Entfernte Spalten: Unterstützt. Spalten können durch manuelle
ALTER TABLE DDL-Befehle entfernt werden, wenn die Spaltenzuordnung aktiviert ist. Erfordert keine Neuschreibung einer Delta-Tabelle. -
Typweiterung: Unterstützt. Wendet die Typänderung automatisch an, wenn die Typweiterung und die Zusammenführungsschemaentwicklung aktiviert sind. Sie können Spalten über manuelle
ALTER TABLE DDLBefehle erweitern, wenn die Typweiterung aktiviert ist. Ohne eine der konfigurierten Vorgänge schlagen Vorgänge fehl. Weitere Informationen finden Sie unter "Verbreitern von Typen mit automatischer Schemaentwicklung". -
Andere Typänderungen: Unterstützt, erfordert jedoch eine vollständige Neuschreibung der Delta-Tabelle. Sie müssen
overwriteSchemaaktivieren. Dies ermöglicht eine vollständige Neuschreibung der Delta-Tabelle. Andernfalls schlagen Vorgänge fehl.
Ansichten
Wenn die Ansicht ein column_list enthält, das nicht mit dem neuen Schema übereinstimmt, oder eine Abfrage enthält, die nicht analysiert werden kann, wird die Ansicht ungültig. Andernfalls können Sie die Schemaentwicklung für Typänderungen mit SCHEMA TYPE EVOLUTION aktivieren und für Typänderungen, neue, umbenannte oder entfernte Spalten mit SCHEMA EVOLUTION (welches eine Obermenge der Typentwicklung darstellt).
-
Neue Spalten: Unterstützt. Im
SCHEMA EVOLUTION-Modus verändert sich die Darstellung automatisch ohne manuelle Intervention, wenn keine explizitecolumn_listvorhanden ist. Andernfalls kann die Ansicht ungültig werden, und der Benutzer kann sie nicht abfragen. - Spaltenumbenennung: Wird unterstützt. Im
SCHEMA EVOLUTION-Modus verändert sich die Darstellung automatisch ohne manuelle Intervention, wenn keine explizitecolumn_listvorhanden ist. Andernfalls kann die Ansicht ungültig werden. -
Entfernte Spalten: Unterstützt. Im
SCHEMA EVOLUTION-Modus verändert sich die Darstellung automatisch ohne manuelle Intervention, wenn keine explizitecolumn_listvorhanden ist. Andernfalls kann die Ansicht ungültig werden. -
Typweiterung: Unterstützt. Mit
SCHEMA TYPE EVOLUTIONdem Modus wird die Ansicht automatisch für alle Typänderungen weiterentwickelt. ImSCHEMA EVOLUTION-Modus verändert sich die Darstellung automatisch ohne manuelle Intervention, wenn keine explizitecolumn_listvorhanden ist. Andernfalls kann die Ansicht ungültig werden. -
Andere Typänderungen: Unterstützt. Mit
SCHEMA TYPE EVOLUTIONdem Modus wird die Ansicht automatisch für alle Typänderungen weiterentwickelt. ImSCHEMA EVOLUTION-Modus verändert sich die Darstellung automatisch ohne manuelle Intervention, wenn keine explizitecolumn_listvorhanden ist. Andernfalls kann die Ansicht ungültig werden.
Example
Das folgende Beispiel zeigt, wie Sie ein Kafka-Topic mit Avro-codierten Nutzlasten aufnehmen, die im Confluent Schema Registry registriert sind, und diese in eine verwaltete Delta-Tabelle mit aktivierter Schemaentwicklung schreiben.
Die wichtigsten Punkte sind dargestellt:
- Integrieren Sie sich in den Kafka-Connector.
- Decodieren Sie Avro-Datensätze mithilfe von from_avro mit einer Kafka-Schemaregistrierung.
- Behandeln Sie die Schemaentwicklung durch das Festlegen von
avroSchemaEvolutionMode. - Schreiben in eine Delta-Tabelle mit
mergeSchemaaktivierter Option zum Zulassen von additiven Änderungen.
Der Code geht davon aus, dass Sie über ein Kafka-Thema mit der Confluent-Schemaregistrierung verfügen und Avro-codierte Daten ausgeben.
# ----- CONFIG: fill these in -----
# Catalog and schema:
CATALOG = "<catalog_name>"
SCHEMA = "<schema_name>"
# Schema Registry:
# (This is where the producer evolves the schema)
SCHEMA_REG = "<schema registry endpoint>"
SR_USER = "<api key>"
SR_PASS = "<api secret>"
# Confluent Cloud: SASL_SSL broker:
BOOTSTRAP = "<server:ip>"
# Kafka topic:
TOPIC = "<topic>"
# ----- end: config -----
BRONZE_TABLE = f"{CATALOG}.{SCHEMA}.bronze_users"
CHECKPOINT = f"/Volumes/{CATALOG}/{SCHEMA}/checkpoints/bronze_users"
# Kafka auth (example for Confluent Cloud SASL/PLAIN over SSL)
KAFKA_OPTS = {
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "PLAIN",
"kafka.sasl.jaas.config": f"kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username='{SR_USER}' password='{SR_PASS}';"
}
# ----- Evolution knobs -----
# spark.conf.set("spark.databricks.delta.schema.autoMerge.enabled", value = True)
from pyspark.sql.functions import col
from pyspark.sql.avro.functions import from_avro
# Build reader
reader = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", BOOTSTRAP)
.option("subscribe", TOPIC)
.option("startingOffsets", "earliest")
)
# Attach Kafka auth options
for k, v in KAFKA_OPTS.items():
reader = reader.option(k, v)
# --- No native schema evolution supported. Returns a binary blob. ---
raw_df = reader.load()
# Decode Avro with Schema Registry
# --- The format parser handles updating the schema using the schema registry ---
decoded = from_avro(
data=col("value"),
jsonFormatSchema=None, # using SR
subject=f"{TOPIC}-value",
schemaRegistryAddress=SCHEMA_REG,
options={
"confluent.schema.registry.basic.auth.credentials.source": "USER_INFO",
"confluent.schema.registry.basic.auth.user.info": f"{SR_USER}:{SR_PASS}",
# Behavior on schema changes:
"avroSchemaEvolutionMode": "restart", # fail-fast so you can restart and adopt new fields
"mode": "FAILFAST"
}
).alias("payload")
bronze_df = raw_df.select(decoded, "timestamp").select("payload.*", "timestamp")
# Write to a managed Delta table as a STREAM
# --- Need to enable schema evolution separately for streaming to a Delta separately with mergeSchema --
(bronze_df.writeStream
.format("delta")
.option("checkpointLocation", CHECKPOINT)
.option("ignoreChanges", "true")
.outputMode("append")
.option("mergeSchema", "true") # only supports adding new columns. Renaming, dropping, and type changes need to be handled separately.
.trigger(availableNow=True) # Use availableNow trigger for Databricks SQL/Unity Catalog
.toTable(BRONZE_TABLE)
)