Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Auf dieser Seite wird beschrieben, wie Sie die Datenklassifizierung von Databricks im Unity-Katalog verwenden, um vertrauliche Daten in Ihrem Katalog automatisch zu klassifizieren und zu kategorisieren.
Datenkataloge können eine große Datenmenge aufweisen, die häufig bekannte und unbekannte vertrauliche Daten enthält. Es ist wichtig, dass Datenteams verstehen, welche Art vertraulicher Daten in jeder Tabelle vorhanden ist, damit sie den Zugriff auf diese Daten steuern und demokratisieren können.
Um dieses Problem zu beheben, verwendet databricks Data Classification einen KI-Agent, um Tabellen in Ihrem Katalog automatisch zu klassifizieren und zu kategorisieren. Auf diese Weise können Sie vertrauliche Daten ermitteln und Governancesteuerelemente auf die Ergebnisse anwenden, indem Sie Tools wie die attributbasierte Zugriffssteuerung im Unity-Katalog verwenden. Eine Liste der unterstützten Tags finden Sie unter "Unterstützte Klassifizierungstags".
Mit dieser Funktion können Sie die folgenden Schritte ausführen:
- Klassifizieren von Daten: Das Modul verwendet ein agentisches KI-System, um alle Tabellen im Unity-Katalog automatisch zu klassifizieren und zu kategorisieren.
- Optimieren Sie die Kosten durch intelligentes Scannen: Das System bestimmt intelligent, wann Ihre Daten durch Nutzung des Unity-Katalogs und des Data Intelligence-Moduls gescannt werden sollen. Dies bedeutet, dass das Scannen inkrementell und optimiert ist, um sicherzustellen, dass alle neuen Daten ohne manuelle Konfiguration klassifiziert werden.
- Überprüfen und Schützen vertraulicher Daten: Die Anzeige der Ergebnisse unterstützt Sie beim Anzeigen von Klassifizierungsergebnissen und beim Schützen vertraulicher Daten durch Kategorisieren und Erstellen von Zugriffssteuerungsrichtlinien für jede Klasse.
Von Bedeutung
Die Datenklassifizierung von Databricks verwendet den Standardspeicher zum Speichern von Klassifizierungsergebnissen. Sie werden für den Speicher nicht in Rechnung gestellt.
Databricks Data Classification verwendet ein großes Sprachmodell (LLM), um die Klassifizierung zu unterstützen.
Anforderungen
- Ihr Arbeitsbereich muss über verfügbare serverlose Rechenleistung verfügen (standardmäßig in Arbeitsbereichen mit dem Unity Catalog aktiviert).
- Um die Datenklassifizierung zu aktivieren, müssen Sie Eigentümer des Katalogs sein oder über die Berechtigungen
USE CATALOGundMANAGEverfügen. - Um das automatische Tagging für einen Katalog zu aktivieren, müssen Sie über
USE CATALOGfür den Katalog,APPLY TAGfür den Katalog undASSIGNfür das angewendete Tag verfügen. - Um die Klassifizierungsergebnisse in der Benutzeroberfläche anzuzeigen, müssen Sie über
USE CATALOGund entwederMANAGEoder (SELECT+USE SCHEMA) im Katalog verfügen. Um Beispielwerte anzuzeigen, die mit Erkennungen verknüpft sind, müssen SieSELECTin der Ergebnissystemtabelle haben.
Hinweis
Standardmäßig haben nur Kontoadministratoren die Berechtigungen MANAGE und ASSIGN für durch das Datenklassifizierungssystem geregelte Tags. Kontoadministratoren können MANAGE und ASSIGN für einzelne geregelte Tags anderen Benutzern, Dienstprinzipalen oder Gruppen gewähren. Siehe "Verwalten von Berechtigungen für geregelte Tags".
Verwenden der Datenklassifizierung
Sie können die Datenklassifizierung für mehrere Kataloge gleichzeitig auf der Ergebnisseite aktivieren oder einzelne Kataloge mit genauerer Steuerung auf Schemaebene konfigurieren.
Aktivieren mehrerer Kataloge
- Klicken Sie auf der Ergebnisseite "Datenklassifizierung " auf "Konfigurieren".
- Wählen Sie die Kataloge aus, die Sie aktivieren möchten, oder wählen Sie alle verfügbaren Kataloge im Arbeitsbereich aus.
- Klicken Sie auf Aktivieren.
Wenn Sie alle verfügbaren Kataloge aktivieren, werden zukünftige Kataloge nicht automatisch aktiviert. Um einen neuen Katalog zu klassifizieren, kehren Sie zum Dialogfeld "Konfigurieren " zurück, und aktivieren Sie ihn.
Aktivieren eines einzelnen Katalogs mit Schemaauswahl
So wählen Sie bestimmte Schemas in einem Katalog aus:
Navigieren Sie zum Katalog, und klicken Sie auf die Registerkarte "Details ".
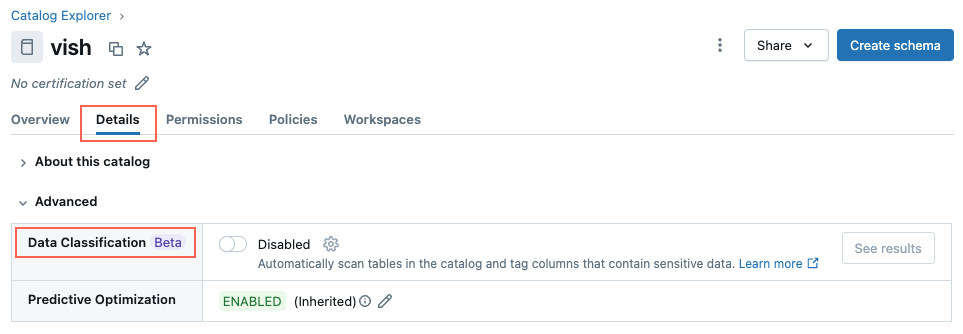
Klicken Sie neben der Datenklassifizierung auf die Schaltfläche " Aktivieren ".
Das Dialogfeld "Datenklassifizierung " wird angezeigt. Standardmäßig sind alle Schemas enthalten. Um nur einige Schemas einzuschließen, wählen Sie diese im Dropdown-Menü Schemas zum Einschließen aus. Sie können auch eine Nutzungsrichtlinie auswählen.
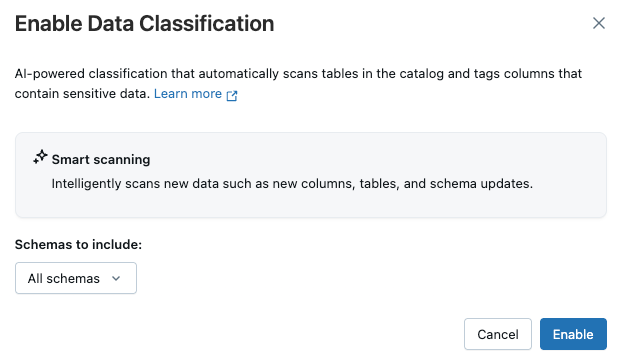
Klicke auf Speichern.
Dadurch wird ein Hintergrundauftrag erstellt, der alle Tabellen im Katalog oder ausgewählte Schemas inkrementell überprüft.
Das Klassifizierungsmodul basiert auf intelligentem Scannen, um zu bestimmen, wann eine Tabelle gescannt werden soll. Neue Tabellen und Spalten in einem Katalog werden in der Regel innerhalb von 24 Stunden nach der Erstellung gescannt.
Anzeigen der Klassifizierungsergebnisse
Klicken Sie zum Anzeigen von Klassifizierungsergebnissen neben der Einstellung "Datenklassifizierung" auf "Ergebnisse anzeigen".
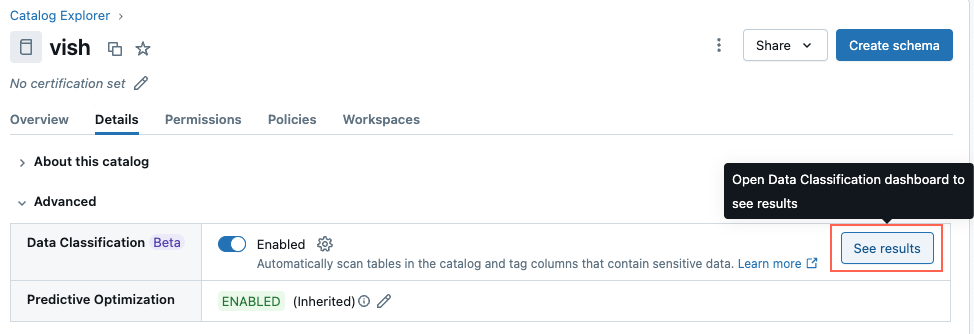
Dadurch wird die Datenklassifizierungs-Benutzeroberfläche für den Katalog geöffnet. Zum Anzeigen von Klassifizierungsergebnissen ist ein serverloses SQL-Warehouse erforderlich.
Sie können aggregierte Ergebnisse auch über alle klassifizierten Kataloge im Metastore anzeigen, indem Sie die Katalogauswahl oben links verwenden. Wählen Sie im Dropdownmenü "Alle Kataloge " aus.
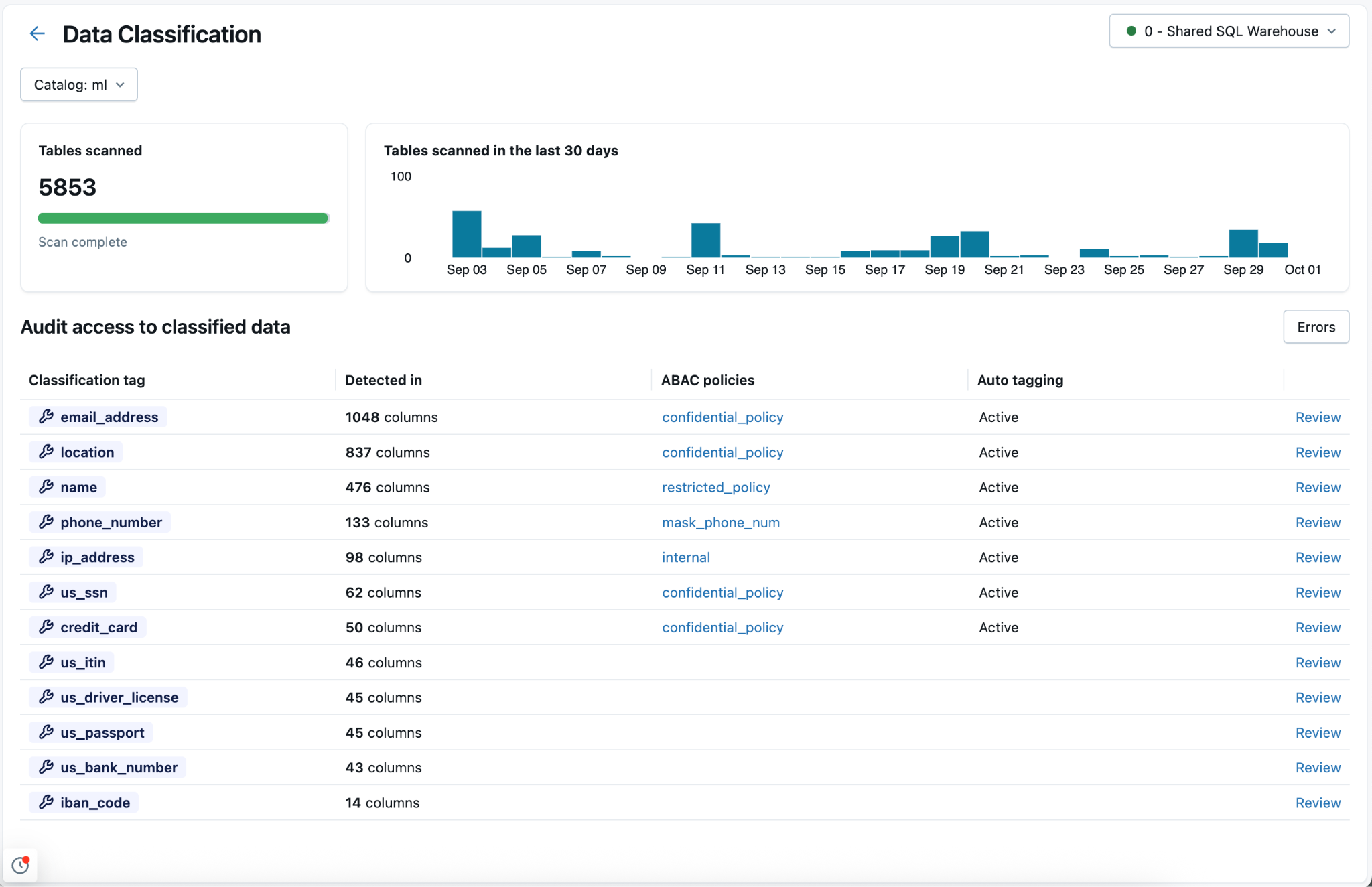
Für jeden Klassifizierungstyp zeigt die Tabelle Folgendes an:
- Erkannte Spalten: Die Anzahl der Spalten, in denen die Klassifizierung erkannt wurde.
- Automatisches Kategorisieren: Der Taggingstatus für diese Klassifizierung – aktiv oder inaktiv. In der Metastore-Ansicht gibt ein Status von "Teilweise aktiv " an, dass tagging in einigen, aber nicht allen Katalogen aktiviert ist.
- Benutzerzugriff (letzte 7d):Die Anzahl der eindeutigen Benutzer, die in den letzten 7 Tagen auf unmaskete und maskierte Daten dieser Klassifizierung zugegriffen haben. Verwenden Sie diese Informationen, um die Exposition vertraulicher Daten in Ihrer Organisation zu bewerten.
Überprüfen von Erkennungen
Um die Ergebnisse für einen bestimmten Klassifizierungstyp zu überprüfen, klicken Sie in der spalte ganz rechts auf "Überprüfen ". Ein Bereich mit zwei Registerkarten wird angezeigt:
- Erkannte Spalten: Zeigt die Spalten an, in denen das Klassifizierungstag mit hoher Zuversicht erkannt wurde, sortiert nach der neuesten Erkennung zuerst. Enthält außerdem ein Diagramm zu Erkennungen über die Zeit und eine Liste der erkannten Spalten mit Beispielwerten. Klicken Sie auf einen beliebigen Balken im Diagramm, um die spezifischen Erkennungen für dieses Datum anzuzeigen. Beispielwerte werden nur angezeigt, wenn Sie über die erforderlichen Berechtigungen zum Anzeigen von Klassifizierungsergebnissen verfügen.
- Benutzerzugriff: Listet alle Benutzer auf, die mit diesem Klassifizierungstag auf Spalten zugegriffen haben, und zeigt ihre E-Mail und ihren Benutzernamen sowie an, ob sie maskierten oder nicht maskierten Zugriff haben. Zeigt auch alle attributbasierten Zugriffssteuerungsrichtlinien (ABAC) an, die diesem Klassifizierungs-Tag zugewiesen sind. Wenn Sie Ergebnisse für einen einzelnen Katalog anzeigen, können Sie eine neue ABAC-Richtlinie direkt aus dem Bedienfeld erstellen.
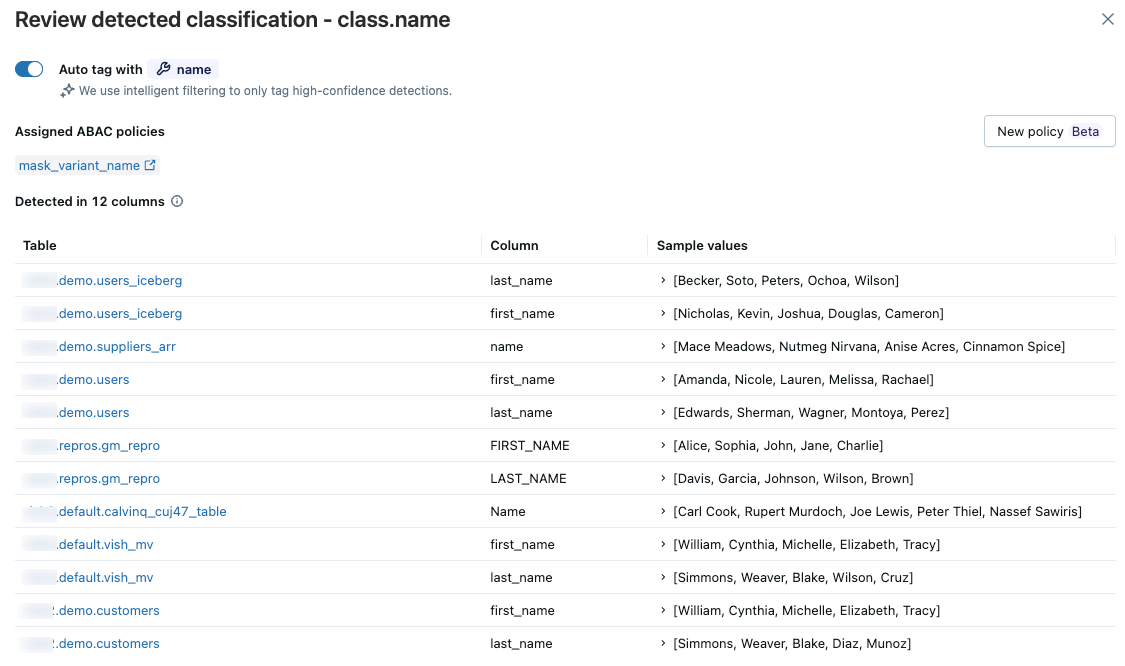
Wenn erkannte Spalten falsch sind, können Sie rechts neben dem Eintrag auf das Symbol "Ausschließen " klicken. Siehe "Erkennung ausschließen".
Aktivieren der automatischen Markierung
Wenn die identifizierten Spalten Ihren Erwartungen entsprechen, können Sie das automatische Tagging für das Klassifizierungsetikett aktivieren. Wenn die automatische Markierung aktiviert ist, werden alle vorhandenen und zukünftigen Erkennungen dieser Klassifizierung markiert.
Sie können die automatische Kategorisierung auf zwei Ebenen konfigurieren:
-
Metastoreebene: Aktivieren oder deaktivieren Sie die Funktion über alle Kataloge hinweg gleichzeitig. Sie müssen ein Metastore-Administrator sein und über
ASSIGNfür das angewendete Tag verfügen. -
Katalogebene: Nur für den aktuellen Katalog aktivieren oder deaktivieren. Einstellungen auf Katalogebene haben Vorrang vor der Einstellung auf Metastoreebene. Sie müssen über
USE CATALOGundAPPLY TAGfür den Katalog sowie überASSIGNfür das angewendete Tag verfügen.
Auf Katalogebene weist das automatische Tagging drei Zustände auf:
- Standard (geerbt):Der Katalog erbt die Taggingeinstellung von der Metastore-Ebene.
- Aktiv: Tagging ist für diesen Katalog unabhängig von der Einstellung auf Metastoreebene explizit aktiviert.
- Inaktiv: Tagging ist für diesen Katalog unabhängig von der Einstellung auf Metastoreebene explizit deaktiviert.
Wenn Sie die Markierung deaktivieren, werden keine zukünftigen Tags angewendet, vorhandene Tags werden jedoch nicht entfernt.
Hinweis
Wenn Sie das automatische Tagging aktivieren, werden Tags nicht sofort nachträglich vervollständigt. Sie werden beim nächsten Scan eingetragen, der innerhalb von 24 Stunden wirksam sein sollte. Nachfolgende Klassifizierungen werden sofort markiert.
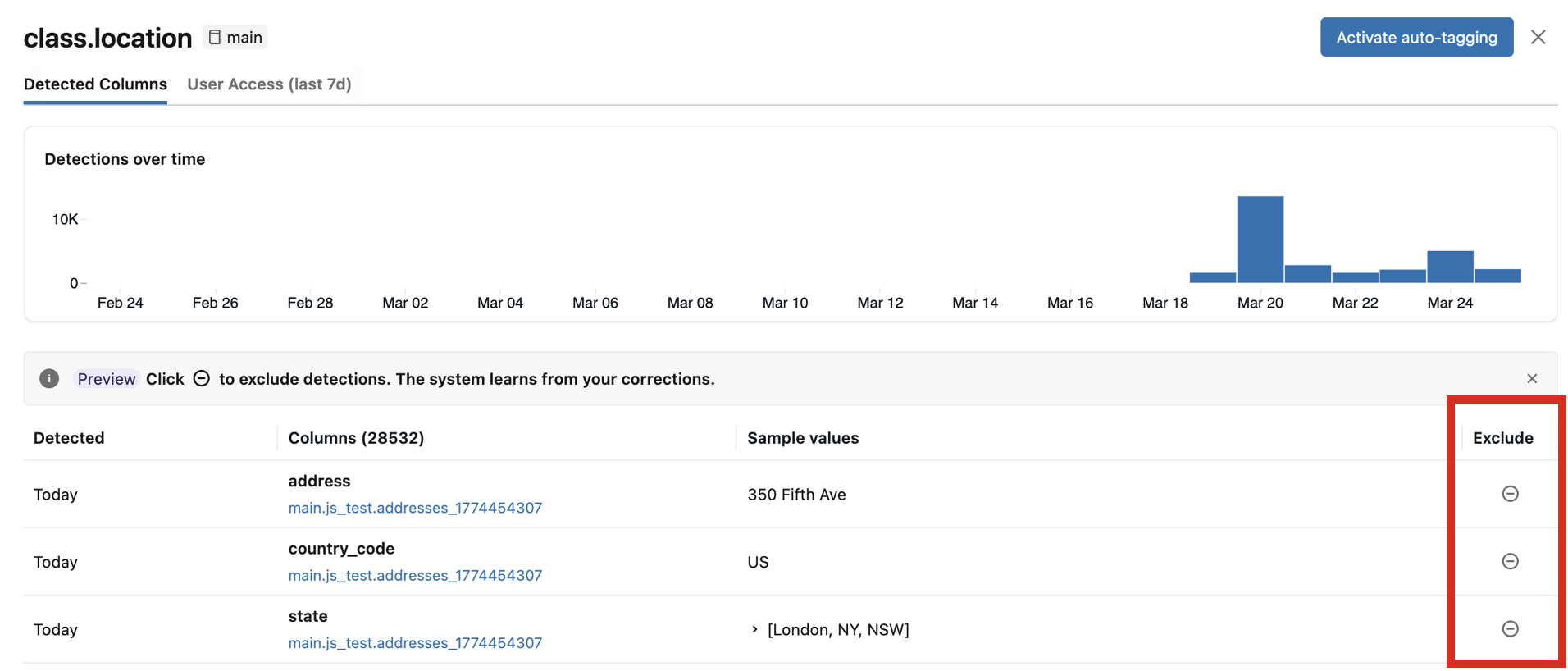
Erkennungen ausschließen
Von Bedeutung
Erkennungsausschlüsse und ihre Verwendung zur Verbesserung der zukünftigen Klassifizierungsgenauigkeit befinden sich in der Betaversion.
Im Überprüfungsbereich können Sie einzelne Spaltenerkennungen ausschließen. Ausschließen einer Detektion:
- Entfernt alle vorhandenen Klassifizierungstags aus dieser Spalte.
- Verhindert, dass zukünftige Scans das Tag erneut auf diese Spalte anwenden.
- Liefert Feedback, das die Genauigkeit zukünftiger Klassifizierungsergebnisse verbessert.
Um eine Erkennung auszuschließen, klicken Sie auf das Symbol "Ausschließen " für die entsprechende Spalte im Überprüfungsbereich. Um die Erkennung erneut einzuschließen, klicken Sie erneut auf das Symbol.
Die Ergebnissystemtabelle
Die Datenklassifizierung erstellt eine Systemtabelle, die zum Speichern von Ergebnissen benannt system.data_classification.results ist, auf die standardmäßig nur der Kontoadministrator zugreifen kann. Der Kontoadministrator kann diese Tabelle freigeben. Auf die Tabelle kann nur zugegriffen werden, wenn Sie serverlose Berechnung verwenden. Ausführliche Informationen zu dieser Tabelle finden Sie in der Datenklassifizierungssystemtabellenreferenz.
Von Bedeutung
Die Ergebnistabelle system.data_classification.results enthält alle Klassifizierungsergebnisse im gesamten Metastore und enthält Beispielwerte aus Tabellen in jedem Katalog. Sie sollten diese Tabelle nur für Benutzer freigeben, die berechtigt sind, metastoreweite Klassifizierungsergebnisse anzuzeigen, einschließlich Beispielwerten.
Benutzer mit SELECT Zugriff auf diese Tabelle können auch Beispielwerte sehen, die mit Erkennungen auf der Ergebnisseite "Datenklassifizierung" verknüpft sind.
Richten Sie Governance-Kontrollen basierend auf den Ergebnissen der Datenklassifizierung ein
Maskieren vertraulicher Daten mithilfe einer ABAC-Richtlinie
Databricks empfiehlt die Verwendung der attributbasierten Zugriffssteuerung im Unity-Katalog zum Erstellen von Governance-Steuerelementen basierend auf Datenklassifizierungsergebnissen.
Um eine Richtlinie auf der Ergebnisseite der Datenklassifizierung zu erstellen, klicken Sie für ein Klassifizierungstag auf Überprüfen, öffnen Sie die Registerkarte Benutzerzugriff, und klicken Sie auf Neue Richtlinie. Das Richtlinienformular ist vorab ausgefüllt, um Spalten mit dem überprüften Klassifizierungstag zu maskieren. Um die Daten zu maskieren, geben Sie eine maskierende Funktion an, die im Unity-Katalog registriert ist, und klicken Sie auf " Speichern".
Sie können auch eine Richtlinie erstellen, die mehrere Klassifizierungstags abdeckt, indem Sie die Spalte "Wann" ändern, um die Bedingung zu erfüllen und mehrere Tags bereitzustellen.
Wenn Sie beispielsweise eine Richtlinie namens "Vertraulich" erstellen möchten, die einen beliebigen Namen, eine E-Mail oder Telefonnummer maskiert, legen Sie die erfüllte Bedingung auf has_tag("class.name") OR has_tag("class.email_address") OR has_tag("class.phone_number").
Erkennung und Löschung von Daten gemäß DSGVO
Dieses Beispielnotizbuch zeigt, wie Sie die Datenklassifizierung verwenden können, um die Datenermittlung und -löschung für die DSGVO-Compliance zu unterstützen.
GDPR-Ermittlung und -Löschung mithilfe des Datenklassifizierungsnotizbuchs
Wie man mit falschen Tags umgeht
Wenn eine Klassifizierung falsch ist, schließen Sie die Erfassung aus dem Überprüfungspanel aus. Durch das Ausschließen einer Erkennung wird das Tag entfernt, eine erneute Anwendung verhindert und die Genauigkeit zukünftiger Scans verbessert. Siehe "Erkennung ausschließen".
Scanfehler
Wenn während der Überprüfung Fehler auftreten, wird oben rechts in der Ergebnistabelle eine Schaltfläche " Fehler " angezeigt.
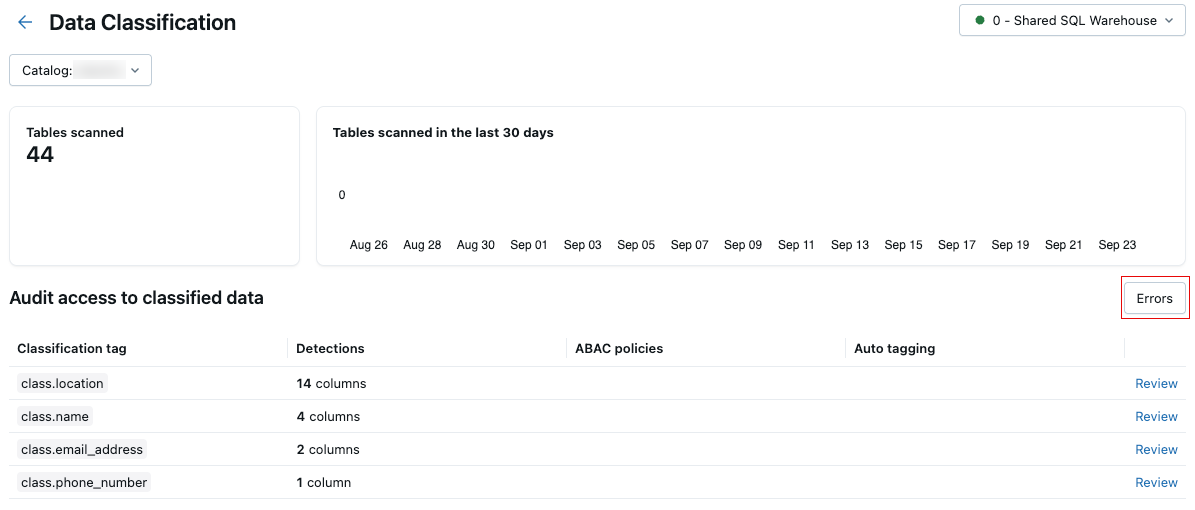
Klicken Sie auf die Schaltfläche, um die Tabellen anzuzeigen, bei denen die Überprüfung fehlgeschlagen ist, und zugehörige Fehlermeldungen.

Standardmäßig werden Fehler, die für einzelne Tabellen aufgetreten sind, übersprungen und am folgenden Tag wiederholt.
Datenklassifizierungsausgaben anzeigen
Informationen dazu, wie die Datenklassifizierung abgerechnet wird, finden Sie auf der Preisseite. Sie können Ausgaben im Zusammenhang mit der Datenklassifizierung anzeigen, indem Sie entweder eine Abfrage ausführen oder das Nutzungsdashboard anzeigen.
Hinweis
Die anfängliche Überprüfung ist teurer als nachfolgende Scans im selben Katalog, da diese Scans inkrementell sind und in der Regel niedrigere Kosten verursachen.
Anzeigen des Verbrauchs über die Systemtabelle system.billing.usage
Sie können Datenklassifizierungskosten von system.billing.usage abfragen. Die Felder created_by und catalog_id können optional zum Aufschlüsseln der Kosten verwendet werden:
-
created_by: Einschließen, um die Kosten pro Benutzer anzuzeigen, der die Nutzung ausgelöst hat. -
catalog_id: Einschließen, um Kosten nach Katalog anzuzeigen. Die Katalog-ID wird in dersystem.data_classification.resultsTabelle angezeigt.
Beispielabfrage für die letzten 30 Tage:
SELECT
usage_date,
identity_metadata.created_by,
usage_metadata.catalog_id,
SUM(usage_quantity) AS dbus
FROM
system.billing.usage
WHERE
usage_date >= DATE_SUB(CURRENT_DATE(), 30)
AND billing_origin_product = 'DATA_CLASSIFICATION'
GROUP BY
usage_date,
created_by,
catalog_id
ORDER BY
usage_date DESC,
created_by;
Um die Gesamtkosten in Dollar zu berechnen, verbinden Sie mit system.billing.list_prices. Die folgende Beispielabfrage verwendet einen benannten Parameter :add_on_rate als Multiplikator für den Listenpreis. Legen Sie es auf 1 fest, um den Listenpreis direkt zu verwenden, oder auf einen Wert kleiner als 1, um einen ausgehandelten Rabatt widerzuspiegeln (z. B. 0.9 für einen Rabatt von 10%).
Beispielabfrage für die Gesamtkosten in Dollar innerhalb der letzten 30 Tage.
SELECT
u.usage_date,
SUM(u.usage_quantity * lp.pricing.effective_list.default) * :add_on_rate
AS `Data Classification Dollar Cost`
FROM system.billing.usage AS u
JOIN system.billing.list_prices AS lp
ON lp.sku_name = u.sku_name
WHERE
u.billing_origin_product = 'DATA_CLASSIFICATION'
AND u.usage_end_time >= lp.price_start_time
AND (lp.price_end_time IS NULL OR u.usage_end_time < lp.price_end_time)
AND u.usage_date >= DATE_ADD(CURRENT_DATE(), -30)
GROUP BY
u.usage_date
ORDER BY
u.usage_date DESC;
Nutzung in der Nutzungsübersicht anzeigen
Wenn Sie bereits ein Nutzungsdashboard in Ihrem Arbeitsbereich konfiguriert haben, können Sie es verwenden, um die Verwendung zu filtern, indem Sie den Abrechnungsursprung Project mit der Bezeichnung "Datenklassifizierung" auswählen. Wenn Sie kein Verwendungsdashboard konfiguriert haben, können Sie ein Dashboard importieren und dieselbe Filterung anwenden. Ausführliche Informationen finden Sie unter Verwendungsdashboards.
Unterstützte Klassifizierungstags
Eine vollständige Liste der unterstützten Tags, die nach globalen Tags, regionalen Tags und Compliance-Frameworks (PII, PCI DSS, DSGVO, HIPAA, GLBA, DPDPA und PIPEDA) organisiert sind, finden Sie unter Unterstützte Klassifizierungstags.
Einschränkungen
- Ansichten und Metrikansichten werden nicht unterstützt. Wenn die Ansicht auf vorhandenen Tabellen basiert, empfiehlt Databricks, die zugrunde liegenden Tabellen zu klassifizieren, um festzustellen, ob sie vertrauliche Daten enthalten.