Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Auf dieser Seite wird beschrieben, wie Sie die Datenlinie mithilfe des Katalog-Explorers und der Datenliniensystemtabellen visualisieren.
Übersicht über die Datenherkunft
Unity Catalog erfasst laufzeitdatenlinienübergreifend Abfragen, die auf Azure Databricks ausgeführt werden. Die Datenherkunft wird für alle Sprachen unterstützt und bis auf die Spaltenebene herunter erfasst. Datenherkunftsdaten umfassen Notebooks, Aufträge und Dashboards, die zur Abfrage gehören. Lineage kann im Katalog-Explorer in nahezu Echtzeit visualisiert und programmgesteuert mithilfe der Lineage-Systemtabellen abgerufen werden.
Lineage kann auch externe Ressourcen und Workflows enthalten, die außerhalb von Azure Databricks ausgeführt werden. Dieses Feature für externe Linienmetadaten befindet sich in der öffentlichen Vorschau. Siehe "Eigene Datenlinie mitbringen".
Die Datenherkunft wird über alle Arbeitsbereiche hinweg aggregiert, die an einen Unity Catalog-Metastore angefügt sind. Dies bedeutet, dass die in einem Arbeitsbereich erfasste Abstammung in jedem anderen Arbeitsbereich sichtbar ist, der diesen gemeinsamen Metaspeicher nutzt. Insbesondere sind Tabellen und andere datenobjekte, die im Metastore registriert sind, für Benutzer sichtbar, die mindestens BROWSE über Berechtigungen für diese Objekte verfügen, in allen Arbeitsbereichen, die dem Metastore zugeordnet sind. Detaillierte Informationen zu Objekten auf Arbeitsbereichsebene wie Notizbüchern und Dashboards in anderen Arbeitsbereichen sind jedoch maskiert (siehe Einschränkungen für Linien und Linienberechtigungen).
Liniendaten werden unbegrenzt aufbewahrt. Alle nach dem 1. September 2024 erfassten Liniendaten sind verfügbar. Für Metastores, die nach diesem Datum erstellt wurden, enthält der Katalog-Explorer eine Option "Alle Zeiten" in der Dropdownliste "Zeitraum". Bei älteren Metastores enthält das Dropdown eine Option "Alle verfügbar ", die ab dem 1. September 2024 beginnt. Die Standardauswahl ist 1 Jahr.
Das folgende Bild ist ein Beispiel für einen Herkunfts-Graph.
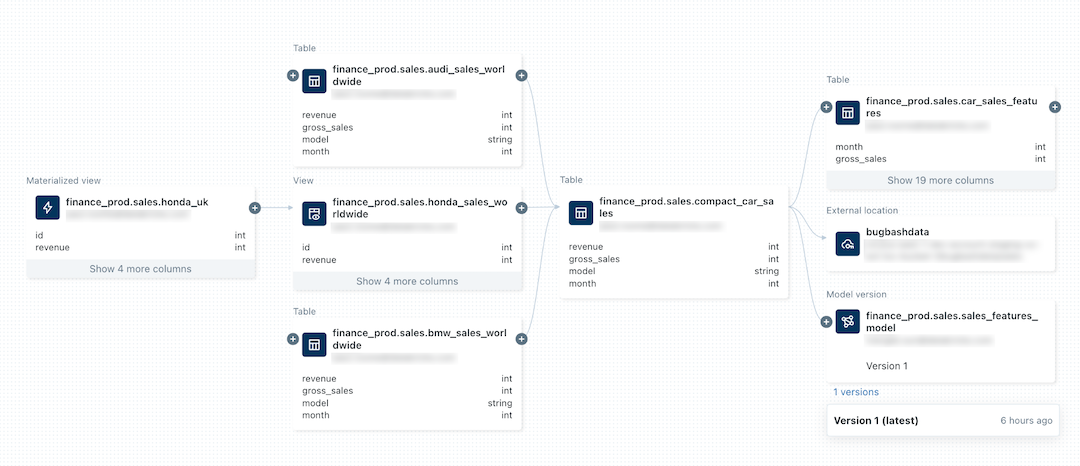
Eine Demo zum Anzeigen der Datenlinie finden Sie unter Unity Catalog – Data Lineage.
Informationen zum Nachverfolgen der Linien eines Machine Learning-Modells finden Sie unter Nachverfolgen der Datenlinie eines Modells im Unity-Katalog.
Anforderungen
So erfassen Sie die Datenlinie mithilfe des Unity-Katalogs:
- Tabellen müssen in einem Unity Catalog-Metastore registriert sein.
- Externe Ressourcen (die nicht im Unity-Katalog-Metastore registriert sind) müssen als externe Metadatenobjekte im Unity-Katalog hinzugefügt werden, die so konfiguriert sind, dass Beziehungen zu anderen sicherungsfähigen Objekten im Unity-Katalog-Metastore registriert sind. Siehe "Eigene Datenlinie mitbringen".
- Abfragen müssen die Spark DataFrame (z. B. Spark SQL-Funktionen, die einen DataFrame zurückgeben) oder Databricks SQL-Schnittstellen wie Notizbücher oder den SQL-Abfrageeditor verwenden.
Anzeigen der Datenherkunft:
- Sie müssen mindestens über die Berechtigungen
BROWSEfür den übergeordneten Katalog der Tabelle oder Ansicht verfügen. Der übergeordnete Katalog muss auch über den Arbeitsbereich zugänglich sein. Siehe Arbeitsbereich-Katalogbindung. - Für Notizbücher, Aufträge oder Dashboards müssen Sie über Berechtigungen für diese Objekte verfügen, wie sie durch die Zugriffssteuerungseinstellungen im Arbeitsbereich definiert sind. Ausführliche Informationen finden Sie unter "Lineage"-Berechtigungen.
- Für eine Unity Catalog-fähige Pipeline müssen Sie über die BERECHTIGUNG CAN VIEW für die Pipeline verfügen.
Computeanforderungen:
- Die Nachverfolgung der Datenherkunft des Streamings zwischen Delta-Tabellen erfordert Databricks Runtime 11.3 LTS oder höher.
- Die Spaltenleitungsnachverfolgung für Lakeflow Spark Declarative Pipelines-Workloads erfordert Databricks Runtime 13.3 LTS oder höher.
Netzwerkanforderungen:
- Möglicherweise müssen Sie Ihre ausgehenden Firewallregeln aktualisieren, um die Konnektivität mit dem Event Hubs-Endpunkt in der Azure Databricks Steuerebene zu ermöglichen. Dies gilt in der Regel, wenn Ihr Azure Databricks Arbeitsbereich in Ihrem eigenen VNet bereitgestellt wird (auch als VNet-Injektion bezeichnet). Weitere Informationen zum Abrufen des Event Hubs-Endpunkts für Ihre Arbeitsbereichsregion finden Sie unter Die IP-Adressen von Metastore, Artefaktblobspeicher, Systemtabellenspeicher, Protokollblobspeicher und Event Hubs-Endpunkt. Informationen zum Einrichten benutzerdefinierter Routen (USER-Defined Routes, UDR) für Azure Databricks finden Sie unter Benutzerdefinierte Routeneinstellungen für Azure Databricks.
Anzeigen der Datenlinie mithilfe des Katalog-Explorers
So verwenden Sie den Katalog-Explorer, um die Tabellendatenherkunft anzuzeigen:
Klicken Sie in Ihrem Azure Databricks Arbeitsbereich auf
 Catalog.
Catalog.Suchen oder durchsuchen Sie Ihre Tabelle.
Wählen Sie die Registerkarte "Linie" aus . Der Bereich "Linie" wird angezeigt und zeigt verwandte Tabellen an.
Um ein interaktives Diagramm der Datenlinie anzuzeigen, klicken Sie auf "Liniendiagramm anzeigen".
Standardmäßig wird eine Ebene im Diagramm angezeigt. Klicken Sie auf das
 auf einem Knoten, um weitere Verbindungen anzuzeigen, wenn sie verfügbar sind.
auf einem Knoten, um weitere Verbindungen anzuzeigen, wenn sie verfügbar sind.Klicken Sie auf einen Pfeil, der Knoten im Liniendiagramm verbindet, um den Verbindungsbereich "Linie " zu öffnen.
Das Panel Datenherkunftsverbindung zeigt Details zur Verbindung, darunter Quell- und Zieltabellen, Notebooks und Aufträge.
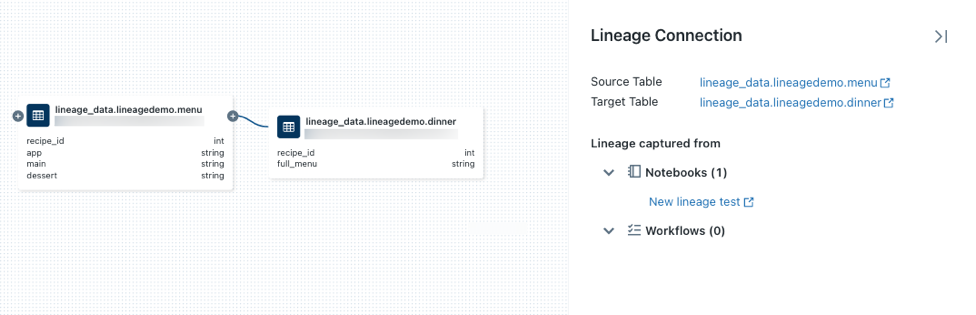
Um ein Notizbuch anzuzeigen, das einer Tabelle zugeordnet ist, wählen Sie das Notizbuch im Verbindungsbereich "Linie " aus, oder schließen Sie das Liniendiagramm, und klicken Sie auf " Notizbücher".
Um das Notizbuch in einer neuen Registerkarte zu öffnen, klicken Sie auf den Notizbuchnamen.
Klicken Sie zum Anzeigen der Linien auf Spaltenebene auf eine Spalte im Diagramm, um Verknüpfungen zu verwandten Spalten anzuzeigen. Wenn Sie beispielsweise auf die
full_menuSpalte in diesem Beispieldiagramm klicken, werden die vorgelagerten Spalten angezeigt, von der die Spalte abgeleitet wurde: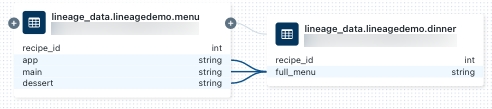
Job-Herkunft anzeigen
Um die Auftragslinie anzuzeigen, wechseln Sie zur Registerkarte " Lineage " einer Tabelle, wählen Sie "Aufträge" und dann "Downstream" aus. Der Job Name erscheint unter Job Name als Consumer der Tabelle.
Dashboarddatenherkunft anzeigen
Um die Dashboardlinie anzuzeigen, wechseln Sie zur Registerkarte " Linien " einer Tabelle, und klicken Sie auf "Dashboards". Das Dashboard wird unter Dashboardname als Nutzer der Tabelle angezeigt.
Tabellenherkunft mit Genie Code abrufen
Genie Code liefert detaillierte Informationen zu Tabellenabstammungen und Erkenntnissen.
So rufen Sie Zeileninformationen mithilfe von Genie Code ab:
- Klicken Sie in der Arbeitsbereichs-Randleiste auf das Katalog.
- Durchsuchen oder suchen Sie im Katalog, klicken Sie auf den Katalognamen und dann auf das
 Genie Code-Symbol in der oberen rechten Ecke.
Genie Code-Symbol in der oberen rechten Ecke. - Geben Sie an der Eingabeaufforderung von Genie Code Folgendes ein:
- /getTableLineages zum Anzeigen von upstream- und downstream-Abhängigkeiten.
- /getTableInsights , um auf metadatengesteuerte Einblicke zuzugreifen, z. B. Benutzeraktivität und Abfragemuster.
Mit diesen Abfragen kann Genie Code Fragen wie "Nachgelagerte Linien anzeigen" oder "wer diese Tabelle am häufigsten abfragt" beantworten.

Herkunftsdaten mit Systemtabellen abfragen
Sie können die Herkunftssystemtabellen verwenden, um Herkunftsdaten programmgesteuert abzufragen. Ausführliche Anweisungen finden Sie unter Referenz zu Systemtabellen und Systemtabellen für Linien.
Herkunft Berechtigungen
Liniendiagramme verwenden das gleiche Berechtigungsmodell wie Unity-Katalog. Tabellen und andere im Unity-Katalog-Metaspeicher registrierte Datenobjekte sind nur für Benutzer sichtbar, die mindestens BROWSE über Berechtigungen für diese Objekte verfügen. Wenn ein Benutzer nicht über das BROWSE- oder SELECT-Privileg für eine Tabelle verfügt, kann er deren Herkunft nicht erkunden. Liniendiagramme zeigen Unity Catalog-Objekte in allen Arbeitsbereichen an, die dem Metastore zugeordnet sind, sofern der Benutzer über ausreichende Objektberechtigungen verfügt.
Führen Sie beispielsweise die folgenden Befehle für userA:
GRANT USE SCHEMA on lineage_data.lineagedemo to `userA@company.com`;
GRANT SELECT on lineage_data.lineagedemo.menu to `userA@company.com`;
Wenn userA das Liniendiagramm für die Tabelle lineage_data.lineagedemo.menu anzeigt, wird die Tabelle menu angezeigt. Sie können keine Informationen zu zugehörigen Tabellen anzeigen, z. B. die nachgeschaltete lineage_data.lineagedemo.dinner-Tabelle. Die dinner-Tabelle wird als masked-Knoten in der Anzeige für userA angezeigt und userA kann das Diagramm nicht ausklappen, um nachgelagerte Tabellen aus Tabellen anzuzeigen, für er keine Zugriffsberechtigung hat.
Wenn Sie den folgenden Befehl ausführen, um die BROWSE Berechtigung zu userBerteilen, kann dieser Benutzer das Liniendiagramm für eine beliebige Tabelle im lineage_data Schema anzeigen:
GRANT BROWSE on lineage_data to `userB@company.com`;
Ebenso müssen Benutzer von Lineagen über bestimmte Berechtigungen zum Anzeigen von Arbeitsbereichsobjekten wie Notizbüchern, Aufträgen und Dashboards verfügen. Darüber hinaus können sie nur detaillierte Informationen zu Arbeitsbereichsobjekten sehen, wenn sie beim Arbeitsbereich angemeldet sind, in dem diese Objekte erstellt wurden. Detaillierte Informationen zu Objekten auf Arbeitsbereichsebene in anderen Arbeitsbereichen sind im Liniendiagramm maskiert.
Weitere Informationen zum Verwalten des Zugriffs auf sicherungsfähige Objekte im Unity-Katalog finden Sie unter Verwalten von Berechtigungen im Unity-Katalog. Weitere Informationen zum Verwalten des Zugriffs auf Arbeitsbereichsobjekte wie Notizbücher, Aufträge und Dashboards finden Sie unter Access-Steuerelementlisten.
Einschränkungen der Datenherkunft
Die Datenlinie weist die folgenden Einschränkungen auf. Diese Einschränkungen gelten auch für Zeilensystemtabellen:
- Obwohl die Herkunft für alle Arbeitsbereiche, die mit demselben Unity Catalog-Metaspeicher verbunden sind, aggregiert wird, sind Details zu Arbeitsbereichsobjekten wie Notebooks und Dashboards nur in dem Arbeitsbereich sichtbar, in dem sie erstellt wurden.
- Die vor dem 1. September 2024 erfassten Liniendaten sind nicht verfügbar.
- Aufträge, die die Auftrags-API-Anforderung
runs submitoder denspark submitAufgabentyp verwenden, sind in Zeilenansichten nicht verfügbar. Tabellen- und Spaltenebenenherkunft wird für diese Workflows weiterhin gesammelt, aber die Verknüpfung zum Auftrag wird nicht erfasst. - Die Zeile wird für umbenannte Objekte nicht beibehalten. Dies gilt für Kataloge, Schemas, Tabellen, Ansichten und Spalten.
- Wenn Sie Spark SQL-Dataset-Prüfpunkte verwenden, wird die Herkunft nicht erfasst.
- Unity Catalog erfasst die Linien von Lakeflow Spark Declarative Pipelines in den meisten Fällen. In einigen Fällen kann jedoch keine vollständige Lineageabdeckung garantiert werden, z. B. wenn Pipelines PRIVATE Tabellen verwenden.
- Ausfallsichere verteilte Datasets (RDDs) werden nicht in Linien erfasst.
- Globale temporäre Sichten werden nicht nach Datenherkunft erfasst.
- Transaktionen emittieren eine Linie, während jeder Lese- und Schreibvorgang auftritt. Lineage-Ereignisse bleiben auch dann erhalten, wenn die Transaktion zurückgesetzt wird.
- Tabellen unter
system.information_schemawerden nicht nach Datenherkunft erfasst. - Unity Catalog erfasst so weit wie möglich die Datenherkunft auf Spaltenebene. Es gibt jedoch einige Fälle, in denen die Datenherkunft auf Spaltenebene nicht erfasst werden kann. Dazu gehören:
Spaltenlinien können nicht erfasst werden, wenn die Quelle oder das Ziel als Pfad referenziert wird (Beispiel:
select * from delta."s3://<bucket>/<path>"). Spaltenlinien werden nur unterstützt, wenn sowohl die Quelle als auch das Ziel nach Tabellenname referenziert werden (Beispiel:select * from <catalog>.<schema>.<table>).Verwendung von benutzerdefinierten Funktionen (USER-Defined Functions, UDFs), wodurch die Zuordnung zwischen Quell- und Zielspalten verdeckt werden kann.