Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Important
Dieses Feature befindet sich in der Betaversion. Arbeitsbereichsadministratoren können den Zugriff auf dieses Feature über die Vorschauseite steuern. Siehe Manage Azure Databricks Previews.
Hinweis
Diese Seite behandelt die alte Version der Informationsextraktion. Databricks empfiehlt die Verwendung der neuesten Version. Siehe Informationsextraktion.
Auf dieser Seite wird beschrieben, wie Sie einen generativen KI-Agent für die Informationsextraktion mithilfe der Informationsextraktion erstellen.
Was ist die Informationsextraktion?
Die Informationsextraktion unterstützt die Informationsextraktion und vereinfacht das Transformieren eines großen Volumens nicht bezeichneter Textdokumente in eine strukturierte Tabelle mit extrahierten Informationen für jedes Dokument.
Beispiele für die Informationsextraktion sind:
- Extrahieren von Preisen und Mietinformationen aus Verträgen.
- Organisieren von Daten aus Kundennotizen.
- Wichtige Details aus Newsartikeln abrufen.
Die Informationsextraktion nutzt automatisierte Auswertungsfunktionen, einschließlich MLflow- und Agent-Auswertung, um eine schnelle Bewertung des Kostenqualitätskonflikts für Ihren spezifischen Extraktionsvorgang zu ermöglichen. Mit dieser Bewertung können Sie fundierte Entscheidungen über das Gleichgewicht zwischen Genauigkeit und Ressourceninvestitionen treffen.
Die Informationsextraktion verwendet Standardspeicher zum Speichern temporärer Datentransformationen, Modellprüfpunkte und interner Metadaten, die jeder Agent nutzt. Beim Löschen des Agents werden alle dem Agent zugeordneten Daten aus dem Standardspeicher entfernt.
Requirements
- Ein Arbeitsbereich, der Folgendes umfasst:
- Serverlose Compute verfügbar (standardmäßig in Arbeitsbereichen mit Unity-Katalog in einer unterstützten Region aktiviert).
- Unity-Katalog aktiviert. Weitere Informationen finden Sie unter Aktivieren eines Arbeitsbereichs für Unity Catalog.
- Zugriff auf Foundation-Modelle im Unity-Katalog über das
system.aiSchema. - Zugriff auf eine serverlose Nutzungsrichtlinie mit einem Nichtzero-Budget.
- Ein Arbeitsbereich in einer der unterstützten Regionen.
- Möglichkeit zum Verwenden der
ai_querySQL-Funktion. - Dateien, aus denen Sie Daten extrahieren möchten. Die Dateien müssen sich in einem Unity-Katalogvolume oder einer Tabelle befinden.
- Wenn Sie PDF-Dateien verwenden möchten, konvertieren Sie sie zuerst in eine Unity-Katalogtabelle. Siehe Verwenden von PDFs in der Informationsextraktion.
- Um Ihren Agent zu erstellen, benötigen Sie mindestens 1 nicht bezeichnetes Dokument in Ihrem Unity-Katalogvolume oder 1 Zeile in Ihrer Tabelle.
Erstellen eines Informationsextraktions-Agents
Wechseln Sie zum ![]() Agents im linken Navigationsbereich Ihres Arbeitsbereichs. Klicken Sie auf der Kachel "Informationsextraktion " auf "Erstellen".
Agents im linken Navigationsbereich Ihres Arbeitsbereichs. Klicken Sie auf der Kachel "Informationsextraktion " auf "Erstellen".
Schritt 1: Konfigurieren Ihres Agents
Konfigurieren Sie Ihren Agent:
Geben Sie im Feld "Name " einen Namen für Ihren Agent ein.
Wählen Sie den Datentyp aus, den Sie bereitstellen möchten. Sie können entweder " Nicht bezeichnetes Dataset " oder " Beschriftetes Dataset" auswählen.
Wählen Sie das bereitzustellende Dataset aus.
Nicht bezeichnetes Dataset
Wenn Sie "Nicht bezeichnetes Dataset" auswählen:
Wählen Sie im Feld "Datasetspeicherort " den Ordner oder die Tabelle aus, den Sie aus Ihrem Unity-Katalogvolume verwenden möchten. Wenn Sie einen Ordner auswählen, muss der Ordner Dokumente in einem unterstützten Dokumentformat enthalten.
Es folgt ein Beispielvolume:
/Volumes/main/info-extraction/bbc_articles/Wenn Sie eine Tabelle angeben, wählen Sie die Spalte aus, die Ihre Textdaten aus der Dropdownliste enthält. Die Tabellenspalte muss Daten in einem unterstützten Datenformat enthalten.
Wenn Sie PDF-Dateien verwenden möchten, konvertieren Sie sie zuerst in eine Unity-Katalogtabelle. Siehe Verwenden von PDFs in der Informationsextraktion.
Die Informationsextraktion leitet automatisch eine JSON-Beispielausgabe ab, die Daten enthält, die aus Ihrem Dataset extrahiert wurden, im Beispiel-JSON-Ausgabefeld . Sie können die Beispielausgabe akzeptieren, bearbeiten oder durch ein Beispiel für die gewünschte JSON-Ausgabe ersetzen. Der Agent gibt extrahierte Informationen mit diesem Format zurück.
Beschriftetes Dataset
Wenn Sie "Beschriftetes Dataset" auswählen:
- Wählen Sie im Datasetfeld "Ground truths" die Unity-Katalogtabelle aus, die Ihre Daten zur Bodenwahrheit enthält.
- Wählen Sie im Feld "Eingabespalte " die Spalte aus, die den Text enthält, den der Agent verarbeiten soll. Die Daten in dieser Spalte müssen im
strFormat vorliegen. - Wählen Sie im Feld "Boden-Wahrheitsantwort " die Spalte aus, die die erwarteten idealen Antworten enthält. Die Daten in dieser Spalte müssen eine JSON-Zeichenfolge sein. Jede Zeile in dieser Spalte muss demselben JSON-Format entsprechen. Zeilen mit zusätzlichen oder fehlenden Schlüsseln sind nicht zulässig.
- Im Beispiel-JSON-Ausgabefeld generiert die Informationsextraktion automatisch eine JSON-Beispielausgabe mithilfe der ersten Datenzeile aus der Spalte für die Boden-Wahrheitsantwort. Überprüfen Sie, ob diese JSON-Ausgabe dem erwarteten Format entspricht.
Stellen Sie sicher, dass das BEISPIEL-JSON-Ausgabefeld ihrem gewünschten Antwortformat entspricht. Bearbeiten Sie nach Bedarf.
Die folgende JSON-Beispielausgabe kann beispielsweise verwendet werden, um Informationen aus einer Reihe von Newsartikeln zu extrahieren:
{ "title": "Economy Slides to Recession", "category": "Politics", "paragraphs": [ { "summary": "GDP fell by 0.1% in the last three months of 2004.", "word_count": 38 }, { "summary": "Consumer spending had been depressed by one-off factors such as the unseasonably mild winter.", "word_count": 42 } ], "tags": ["Recession", "Economy", "Consumer Spending"], "estimate_time_to_read_min": 1, "published_date": "2005-01-15", "needs_review": false }Wählen Sie unter "Modellauswahl" das beste Modell für Ihren Informationsextraktions-Agent aus:
- Optimieren für Skalierung (Standard): Wählen Sie diese Option aus, wenn Sie große Datenmengen verarbeiten oder einen kostengünstigen Agent bevorzugen. Dieses Modell ist für hohen Durchsatz und schnellere Bearbeitungszeit ausgelegt und eignet sich für die meisten Informationsextraktionsvorgänge.
- Optimierung für Komplexität: Wählen Sie diese Option aus, wenn Sie komplexe Gründe benötigen und die Genauigkeit gegenüber Geschwindigkeit und Kosten priorisieren. Dieses Modell bietet höhere Denkkapazitäten für längere Dokumente (z. B. Finanzunterlagen) und kann komplexere Extraktionen verarbeiten, wie das Extrahieren von mehr als 40 Schemafeldern.
Klicken Sie auf "Agent erstellen".
Unterstützte Dokumentformate
In der folgenden Tabelle sind die unterstützten Dokumentdateitypen für Ihre Quelldokumente aufgeführt, wenn Sie ein Unity-Katalogvolume bereitstellen.
| Codedateien | Dokumentdateien | Protokolldateien |
|---|---|---|
|
|
|
Unterstützte Datenformate
Die Informationsextraktion unterstützt die folgenden Datentypen und Schemas für Ihre Quelldokumente, wenn Sie eine Unity-Katalogtabelle bereitstellen. Die Informationsextraktion kann diese Datentypen auch aus jedem Dokument extrahieren.
strintfloatboolean-
enum(wird für Klassifizierungsaufgaben verwendet, bei denen der Agent nur aus vordefinierten Kategorien auswählen sollte) - Object
- Felder
enum (geeignet für Klassifizierungsaufgaben, bei denen der Agent nur aus einer Reihe vordefinierter Kategorien auswählen soll) Objekt (anstelle von "benutzerdefinierten geschachtelten Feldern") Array
Schritt 2: Verbessern Ihres Agents
Überprüfen Sie auf der Registerkarte " Erstellen " Beispielausgaben, um Ihre Schemadefinition zu verfeinern und Anweisungen für bessere Ergebnisse hinzuzufügen.
Überprüfen Sie links die Beispielantworten und geben Sie Feedback, um Ihren Agenten anzupassen. Diese Beispiele basieren auf Ihrer aktuellen Agentkonfiguration.
- Klicken Sie auf eine Zeile, um die vollständige Eingabe und Antwort zu überprüfen.
- Geben Sie unten neben "Ist diese Antwort korrekt?" Feedback ab, indem Sie entweder
 Ja oder
Ja oder  Beheben Sie dies auswählen. Um das Feedback zu beheben , geben Sie zusätzliche Details dazu an, wie der Agent seine Antwort ändern soll, und klicken Sie dann auf das
Beheben Sie dies auswählen. Um das Feedback zu beheben , geben Sie zusätzliche Details dazu an, wie der Agent seine Antwort ändern soll, und klicken Sie dann auf das  Speichern.
Speichern. - Nachdem Sie alle Antworten überprüft haben, klicken Sie auf das Ja, Update-Agent. Sie können auch auf " Feedback speichern" und "Aktualisieren " klicken, nachdem Sie mindestens drei Antworten überprüft haben.
Verfeinern Sie auf der rechten Seite unter "Ausgabefelder" die Beschreibungen Ihrer Extraktionsschemafelder. Diese Beschreibungen sind das, was der Agent benötigt, um zu verstehen, was Sie extrahieren möchten. Verwenden Sie die Beispielantworten auf der linken Seite, um die Schemadefinition zu verfeinern.
- Überprüfen und bearbeiten Sie für jedes Feld die Schemadefinition nach Bedarf. Verwenden Sie die Beispielantworten auf der linken Seite, um diese Beschreibungen zu verfeinern.
- Zum Bearbeiten des Feldnamens und des Typs klicken Sie auf
 Feld bearbeiten.
Feld bearbeiten. - Um ein neues Feld hinzuzufügen, klicken Sie auf das
 Neues Feld hinzufügen. Geben Sie den Namen, den Typ und die Beschreibung ein, und klicken Sie auf "Bestätigen".
Neues Feld hinzufügen. Geben Sie den Namen, den Typ und die Beschreibung ein, und klicken Sie auf "Bestätigen". - Um ein Feld zu entfernen, klicken Sie auf
 Feld entfernen.
Feld entfernen. - Klicken Sie auf "Speichern und aktualisieren ", um die Agentkonfiguration zu aktualisieren.
(Optional) Geben Sie auf der rechten Seite unter "Anweisungen" alle globalen Anweisungen für Ihren Agenten ein. Diese Anweisungen gelten für alle extrahierten Elemente. Klicken Sie auf "Speichern" und "Aktualisieren ", um die Anweisungen anzuwenden.
Neue Beispielantworten werden auf der linken Seite generiert. Überprüfen Sie diese aktualisierten Antworten, und verfeinern Sie ihre Agentkonfiguration weiter, bis die Antworten zufriedenstellend sind.
Schritt 3: Verwenden Ihres Agents
Sie können Ihren Agenten in Workflows über Databricks hinweg verwenden.
Um mit der Verwendung Ihres Agents zu beginnen, klicken Sie auf "Verwenden". Sie können ihren Agenten auf verschiedene Arten verwenden:
-
Extrahieren Sie Daten für alle Dokumente: Klicken Sie auf "Extraktion starten ", um den SQL-Editor zu öffnen und
ai_queryAnforderungen an Ihren neuen Informationsextraktions-Agent zu senden. - ETL-Pipeline erstellen: Klicken Sie auf " Pipeline erstellen", um eine Pipeline bereitzustellen, die in geplanten Intervallen ausgeführt wird, um Ihren Agent für neue Daten zu verwenden. Weitere Informationen zu Pipelines finden Sie unter Lakeflow Spark Declarative Pipelines .
- Testen Sie Ihren Agent: Klicken Sie auf "In Playground öffnen ", um Ihren Agent in einer Testumgebung auszuprobieren, um zu sehen, wie es funktioniert. Weitere Informationen zu AI Playground finden Sie im "Chat mit LLMs und zur Erstellung von Prototypen generativer KI-Apps im AI Playground".
(Optional) Schritt 4: Auswerten Ihres Agents
Um sicherzustellen, dass Sie einen qualitativ hochwertigen Agent erstellt haben, führen Sie eine Auswertung aus, und überprüfen Sie den resultierenden Qualitätsbericht.
Wechseln Sie zur Registerkarte "Qualität ".
Klicken Sie auf
Führen Sie die Auswertung aus.Konfigurieren Sie im Bereich "Neue Auswertung, der sich herausbewegt, die Auswertung:
- Wählen Sie den Namen der Auswertungsausführung aus. Sie können einen generierten Namen verwenden oder einen benutzerdefinierten Namen angeben.
- Wählen Sie das Auswertungsdatenset aus. Sie können dasselbe Quelldatenset verwenden, das zum Erstellen Ihres Agents verwendet wird, oder ein benutzerdefiniertes Auswertungsdatenset mit beschrifteten oder nicht bezeichneten Daten bereitstellen.
Klicken Sie auf "Auswertung starten".
Überprüfen Sie nach Abschluss der Auswertung den Qualitätsbericht:
Standardmäßig wird eine Zusammenfassungsansicht angezeigt. Überprüfen Sie die Gesamtqualität, die Kosten, den Durchsatz und den Zusammenfassenden Bericht über die Auswertungsmetriken. Klicken Sie auf das
 Neben dem Schemafeld erfahren Sie, wie dieses Feld ausgewertet wird.
Neben dem Schemafeld erfahren Sie, wie dieses Feld ausgewertet wird.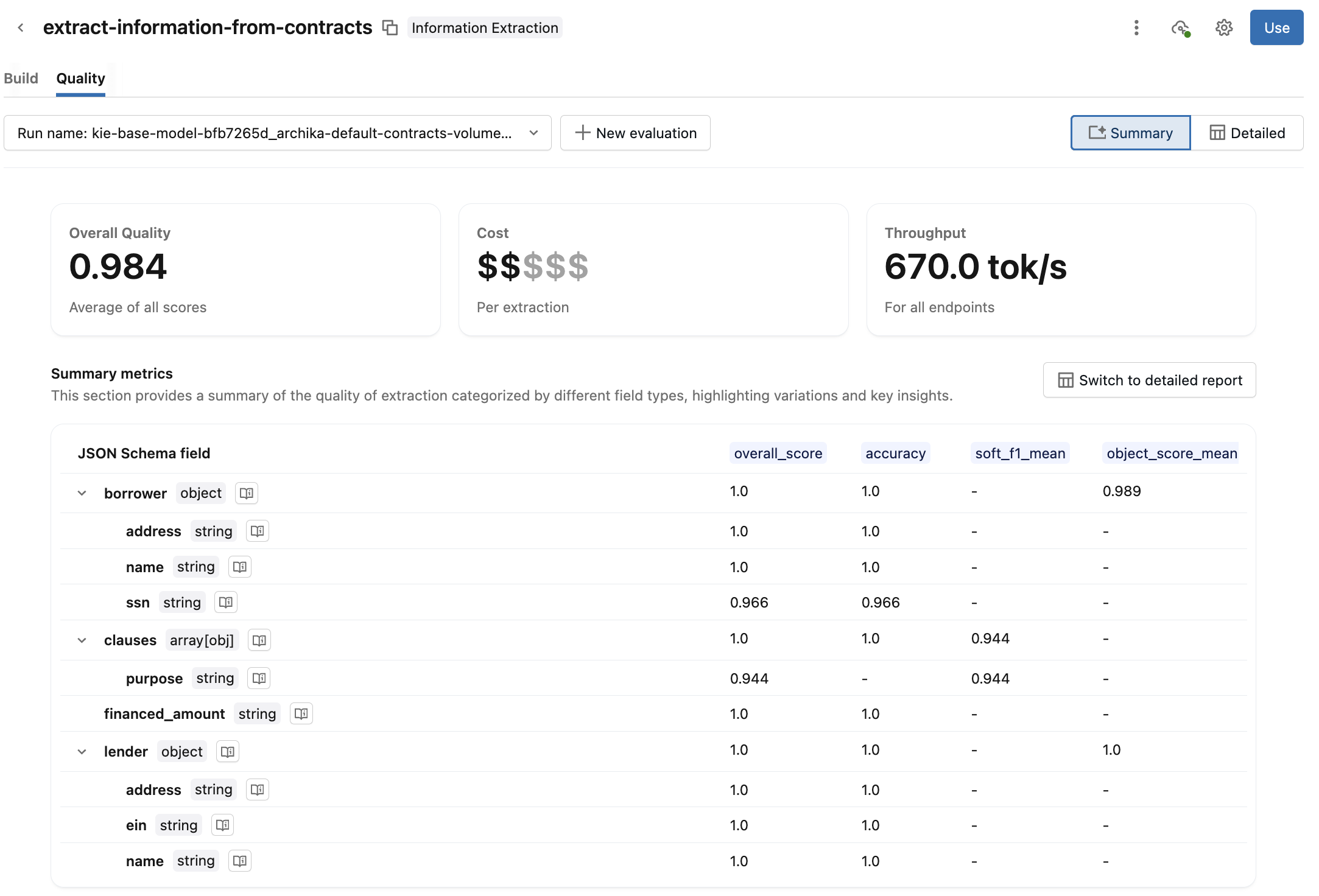
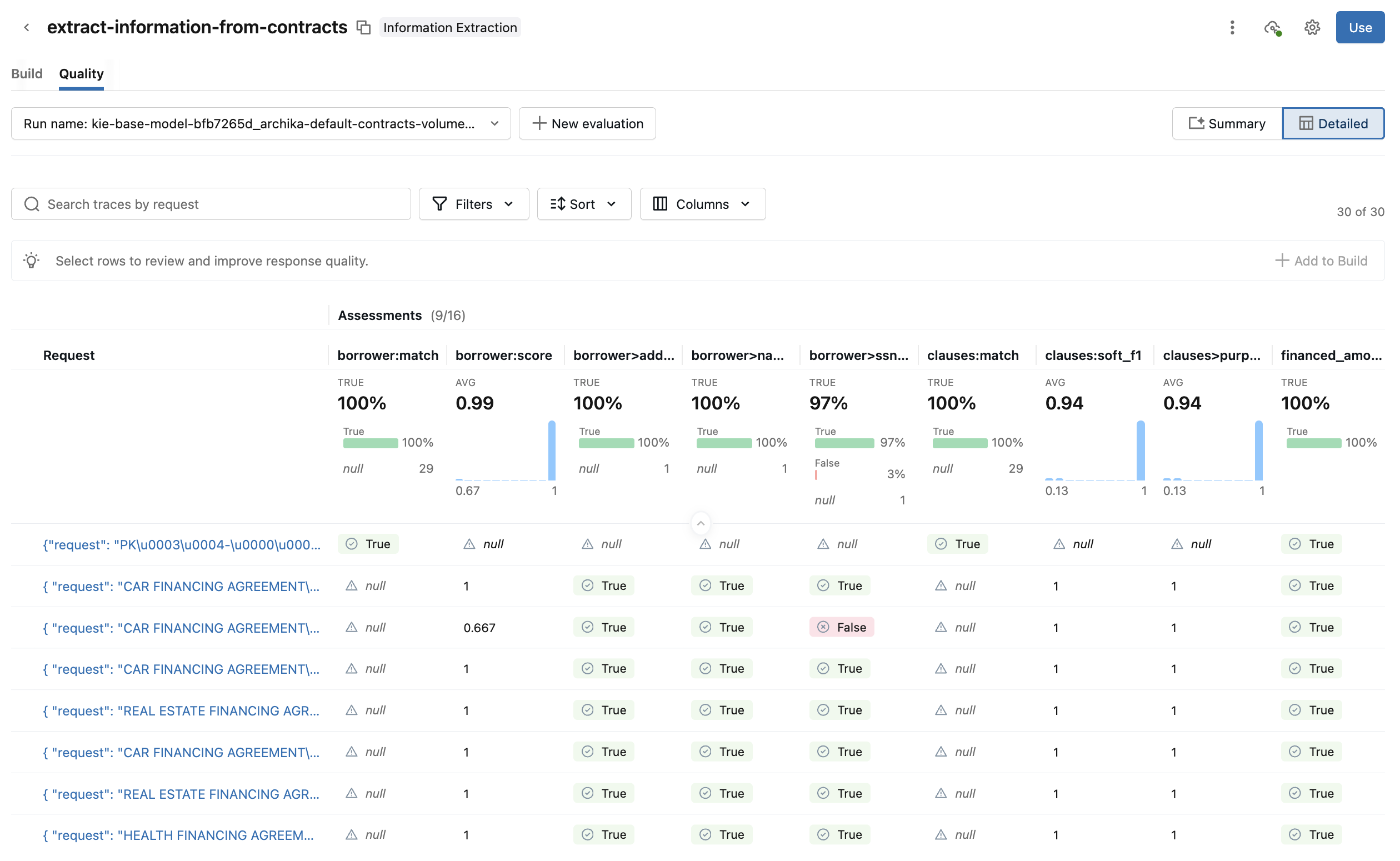
Wechseln Sie zur Detaillierten Ansicht, um weitere Details anzuzeigen. In dieser Ansicht werden jede Anforderung und die Auswertungsbewertung für jede Metrik angezeigt. Klicken Sie in eine Anforderung, um weitere Details anzuzeigen, z. B. Eingabe, Ausgabe, Bewertungen, Ablaufverfolgungen und verknüpfte Eingabebefehle. Sie können die Bewertungen der Anforderung auch bearbeiten und zusätzliches Feedback geben.
Agentenendpunkt abfragen
Klicken Sie auf der Agentseite auf das ![]() Siehe Agentstatus oben rechts, um Ihren bereitgestellten Agent-Endpunkt abzurufen und Endpunktdetails anzuzeigen.
Siehe Agentstatus oben rechts, um Ihren bereitgestellten Agent-Endpunkt abzurufen und Endpunktdetails anzuzeigen.
Es gibt mehrere Möglichkeiten, den erstellten Agentendpunkt abzufragen. Verwenden Sie die codebeispiele in AI Playground als Ausgangspunkt:
- Klicken Sie auf der Agentseite auf "Verwenden".
- Klicken Sie auf "Im Playground öffnen".
- Klicken Sie im Playground auf "Code abrufen".
- Wählen Sie aus, wie Sie den Endpunkt verwenden möchten:
- Wählen Sie "Auf Daten anwenden" aus, um eine SQL-Abfrage zu erstellen, die den Agent auf eine bestimmte Tabellenspalte anwendet.
- Wählen Sie die Curl-API für ein Codebeispiel aus, um den Endpunkt mithilfe von curl abzufragen.
- Wählen Sie Python-API aus, um mithilfe von Python mit dem Endpunkt zu interagieren.
Berechtigungen verwalten
Standardmäßig verfügen nur Agentautoren und Arbeitsbereichsadministratoren über Berechtigungen für den Agent. Damit andere Benutzer Ihren Agent bearbeiten oder abfragen können, müssen Sie ihnen explizit die Berechtigung erteilen.
So verwalten Sie Berechtigungen für Ihren Agent:
- Öffnen Sie Ihren Agent auf der Seite "Agents ".
- Klicken Sie oben auf das
 Kebab-Menü.
Kebab-Menü. - Klicken Sie auf "Berechtigungen verwalten".
- Wählen Sie im Fenster "Berechtigungseinstellungen " den Benutzer, die Gruppe oder den Dienstprinzipal aus.
- Wählen Sie die zu gewährende Berechtigung aus.
- Kann verwaltet werden: Ermöglicht die Verwaltung des Agents, einschließlich des Festlegens von Berechtigungen, des Bearbeitens der Agentenkonfiguration und der Verbesserung der Qualität.
- Can Query: Ermöglicht das Abfragen des Agenten-Endpunkts in AI Playground und über die API. Benutzer mit nur dieser Berechtigung können den Agent nicht auf der Seite "Agents" anzeigen oder bearbeiten.
- Klicken Sie auf Hinzufügen.
- Klicken Sie auf "Speichern".
Hinweis
Für Agent-Endpunkte, die vor dem 16. September 2025 erstellt wurden, können Sie Abfrageberechtigungen dem Endpunkt auf der Seite Servieren Endpunkte erteilen.
Verwenden von PDFs in der Informationsextraktion
PDFs werden noch nicht nativ in der Informationsextraktion und dem benutzerdefinierten LLM unterstützt. Sie können jedoch den UI-Workflow verwenden, um einen Ordner mit PDF-Dateien in Markdown zu konvertieren, und verwenden Sie dann die resultierende Unity-Katalogtabelle als Eingabe beim Erstellen Ihres Agents. Dieser Workflow verwendet ai_parse_document für die Konvertierung. Folgen Sie diesen Schritten:
Klicken Sie im linken Navigationsbereich auf "Agents ".
Klicken Sie in den Anwendungsfällen "Information Extraction" oder "Custom LLM" auf "PDFs verwenden".
Geben Sie im daraufhin geöffneten Seitenbereich die folgenden Felder ein, um einen neuen Workflow zu erstellen, um Ihre PDFs zu konvertieren:
- Wählen Sie einen Ordner mit PDFs oder Bildern aus: Wählen Sie den Unity-Katalogordner mit den PDF-Dateien aus, die Sie verwenden möchten.
- Zieltabelle auswählen: Wählen Sie das Zielschema für die konvertierte Markdowntabelle aus, und passen Sie optional den Tabellennamen im folgenden Feld an.
- Wählen Sie active SQL Warehouse aus: Wählen Sie das SQL Warehouse aus, um den Workflow auszuführen.
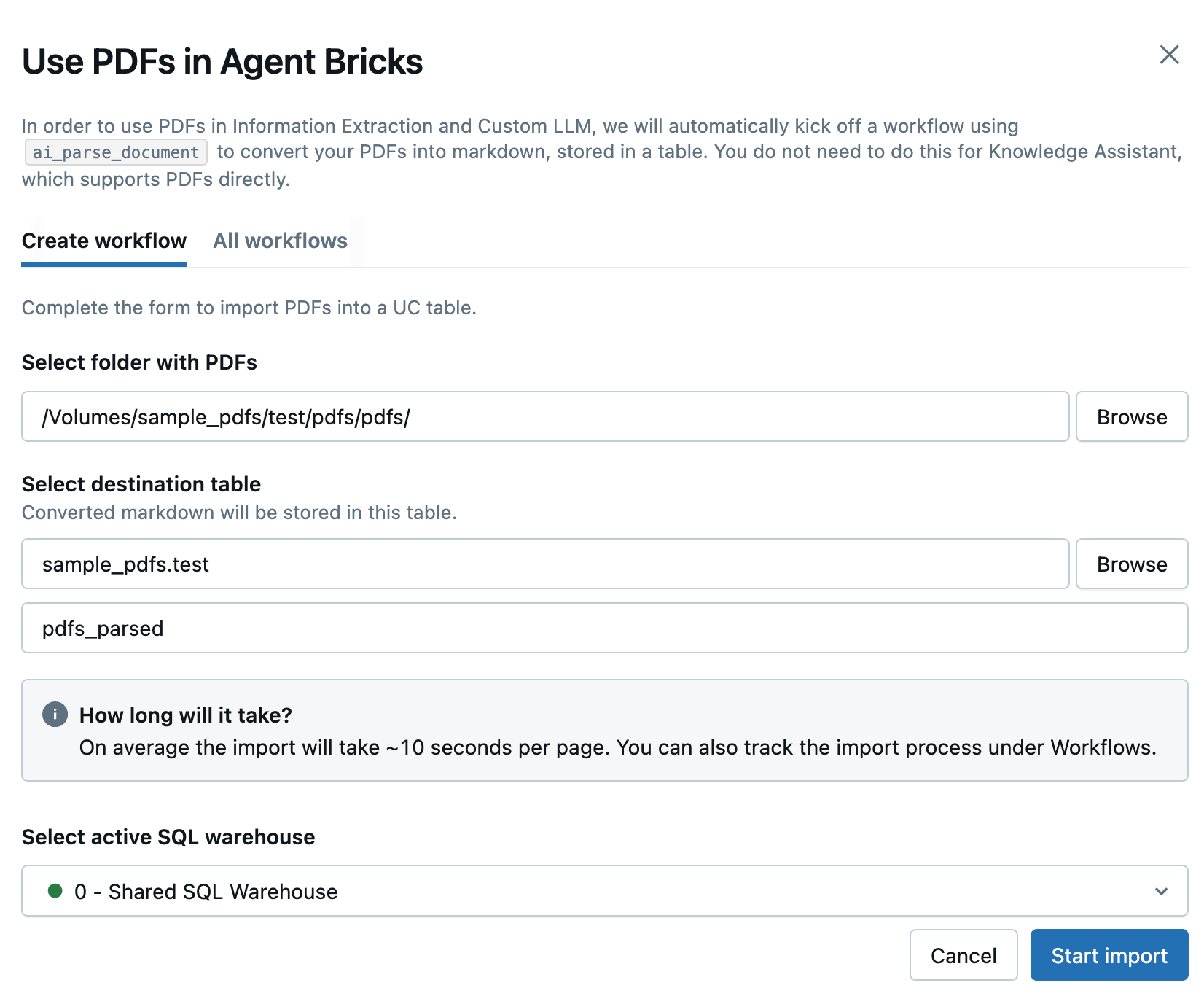
Klicken Sie auf "Import starten".
Sie werden zur Registerkarte "Alle Workflows " umgeleitet, auf der alle PDF-Workflows aufgelistet sind. Mithilfe dieser Registerkarte können Sie den Status Ihrer Aufträge überwachen.
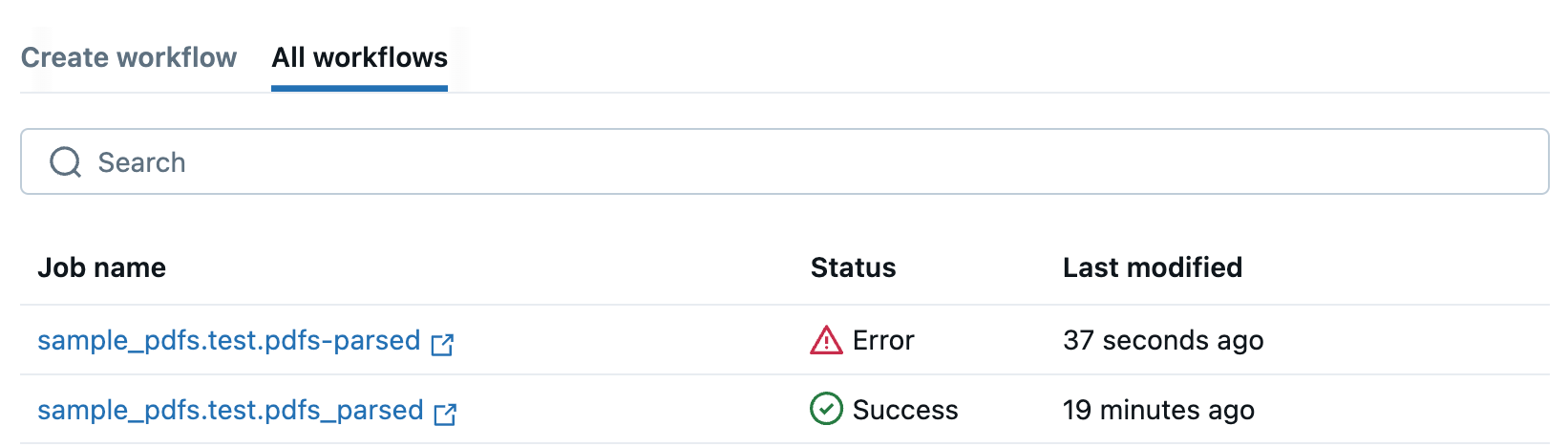
Wenn der Workflow fehlschlägt, klicken Sie auf den Auftragsnamen, um ihn zu öffnen, und zeigen Sie Fehlermeldungen an, die Sie beim Debuggen unterstützen.
Wenn Der Workflow erfolgreich abgeschlossen wurde, klicken Sie auf den Auftragsnamen, um die Tabelle im Katalog-Explorer zu öffnen, um die Spalten zu erkunden und zu verstehen.
Verwenden Sie die Unity-Katalogtabelle als Eingabedaten, wenn Sie Ihren Agent konfigurieren.
Limitations
- Informationsextraktions-Agents weisen eine maximale Kontextlänge von 128k-Token auf.
- Arbeitsbereiche mit aktivierter erweiterter Sicherheit und Compliance werden nicht unterstützt.
- Union-Schematypen werden nicht unterstützt.