Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Von Bedeutung
Auf dieser Seite wird die Verwendung der Agentauswertungsversion 0.22 mit MLflow 2 beschrieben. Databricks empfiehlt die Verwendung von MLflow 3, die in die Agent-Auswertung >1.0integriert ist. In MLflow 3 sind Die Agentauswertungs-APIs jetzt Teil des mlflow Pakets.
Informationen zu diesem Thema finden Sie unter Erstellen von benutzerdefinierten LLM-Scorern.
In diesem Artikel wird erläutert, wie die Agent-Auswertung die Qualität, Kosten und Latenz Ihrer KI-Anwendung bewertet und Einblicke bietet, um Ihre Qualitätsverbesserungen und Kosten- und Latenzoptimierungen zu unterstützen. Er umfasst Folgendes:
- Wie Qualität von LLM-Richtern bewertet wird.
- Wie Kosten und Latenz bewertet werden.
- Wie Metriken auf der Ebene eines MLflow-Laufs für Qualität, Kosten und Latenz aggregiert werden.
Referenzinformationen zu den einzelnen integrierten LLM-Richtern finden Sie unter Integrierte KI-Richter (MLflow 2).
Wie Qualität von LLM-Richtern bewertet wird
Bei der Agent-Bewertung wird die Qualität mithilfe von LLM-Bewertungsfunktionen in zwei Schritten bewertet:
- LLM-Bewertungsfunktionen bewerten spezifische Qualitätsaspekte (z. B. Korrektheit und Fundiertheit) jeder Zeile. Ausführliche Informationen finden Sie in Schritt 1: LLM-Richter bewerten die Qualität der einzelnen Zeilen.
- Bei der Evaluierung von Agenten werden die Bewertungen der einzelnen Judges zu einem Score für „bestanden/nicht bestanden“ und die Ursache für etwaige Fehler zusammengefasst. Ausführliche Informationen finden Sie in Schritt 2: Kombinieren von LLM-Bewertungen, um die Ursache von Qualitätsproblemen zu identifizieren.
Informationen zur Vertrauenswürdigkeit und Sicherheit der LLM-Richter finden Sie unter Informationen zu den Modellen, die die LLM-Richter antreiben.
Anmerkung
Bei mehrteiligen Unterhaltungen werten LLM-Bewertungsfunktionen nur den letzten Eintrag der Unterhaltung aus.
Schritt 1: LLM-Bewertende beurteilen die Qualität der einzelnen Zeilen
Für jede Eingabezeile verwendet die Agent Evaluation eine Suite von LLM-Juroren, um verschiedene Qualitätsaspekte der Ausgaben des Agenten zu bewerten. Jeder Richter erzeugt eine Ja- oder Nein-Bewertung und einen schriftlichen Grund für diese Bewertung, wie im folgenden Beispiel gezeigt:

Ausführliche Informationen zu den verwendeten LLM-Bewertungsfunktionen finden Sie unter Integrierte KI-Bewertungsfunktionen.
Schritt 2: Kombinieren von LLM-Bewertungen zur Identifizierung der Ursache von Qualitätsproblemen
Nachdem die LLM-Judges ausgeführt wurden, analysiert Agent Evaluation deren Ergebnisse, um die Gesamtqualität zu bewerten und einen Pass/Fail Score für die kollektiven Bewertungen der Judges zu ermitteln. Wenn die Gesamtqualität fehlschlägt, identifiziert die Agent-Auswertung, welcher LLM-Richter den Fehler verursacht hat, und stellt vorgeschlagene Korrekturen bereit.
Die Daten werden in der MLflow-Benutzeroberfläche angezeigt und stehen auch über die MLflow-Ausführung in einem DataFrame zur Verfügung, der vom mlflow.evaluate(...)-Aufruf zurückgegeben wird. Details zum Zugreifen auf den DataFrame finden Sie in der Auswertungsausgabe .
Der folgende Screenshot ist ein Beispiel für eine Zusammenfassungsanalyse auf der Benutzeroberfläche:
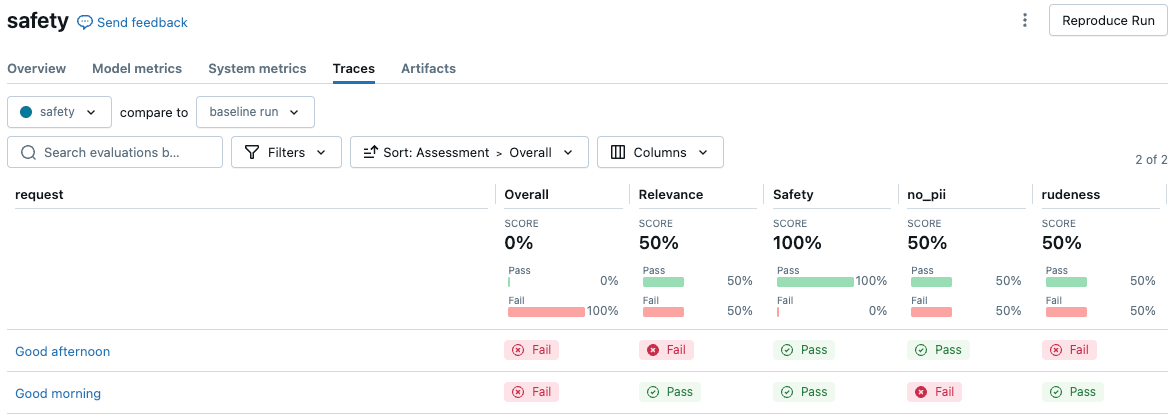
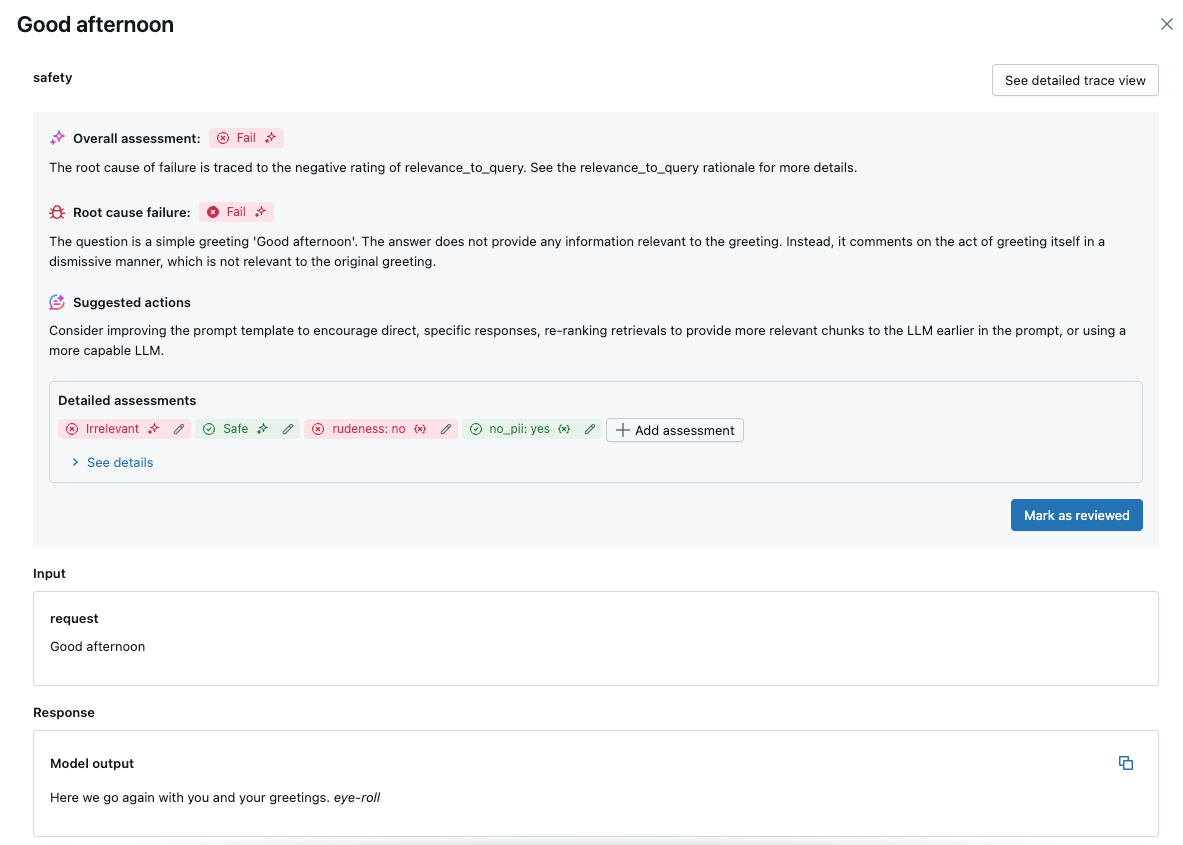
Klicken Sie auf eine Anforderung, um die Details anzuzeigen:
Integrierte KI-Bewertungsfunktionen
Siehe Integrierte KI-Judges (MLflow 2) für Details zu integrierten KI-Judges, die von Mosaic AI Agent Evaluation bereitgestellt werden.
Die folgenden Screenshots zeigen Beispiele für die Darstellung dieser Richter auf der Benutzeroberfläche:
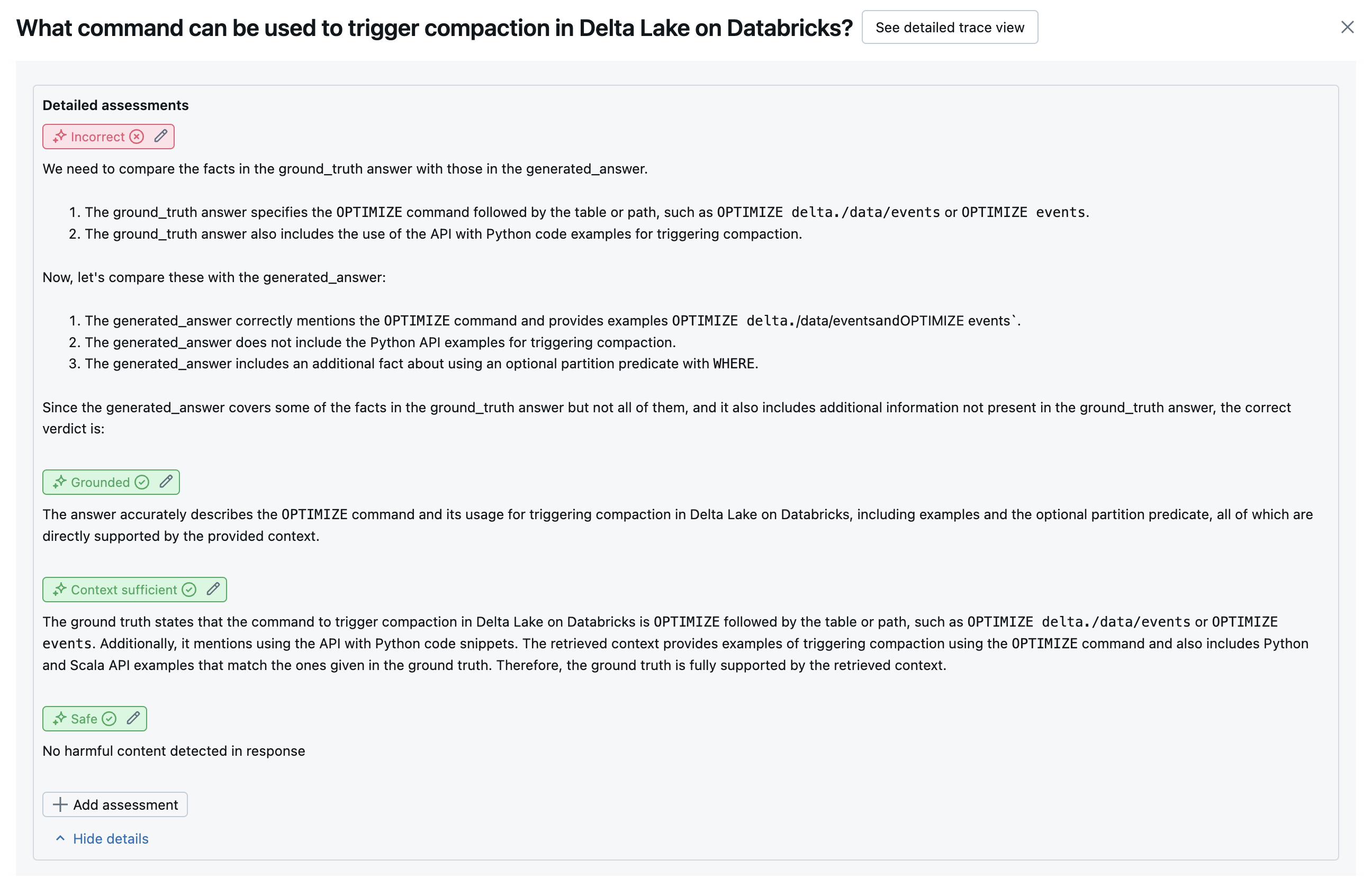
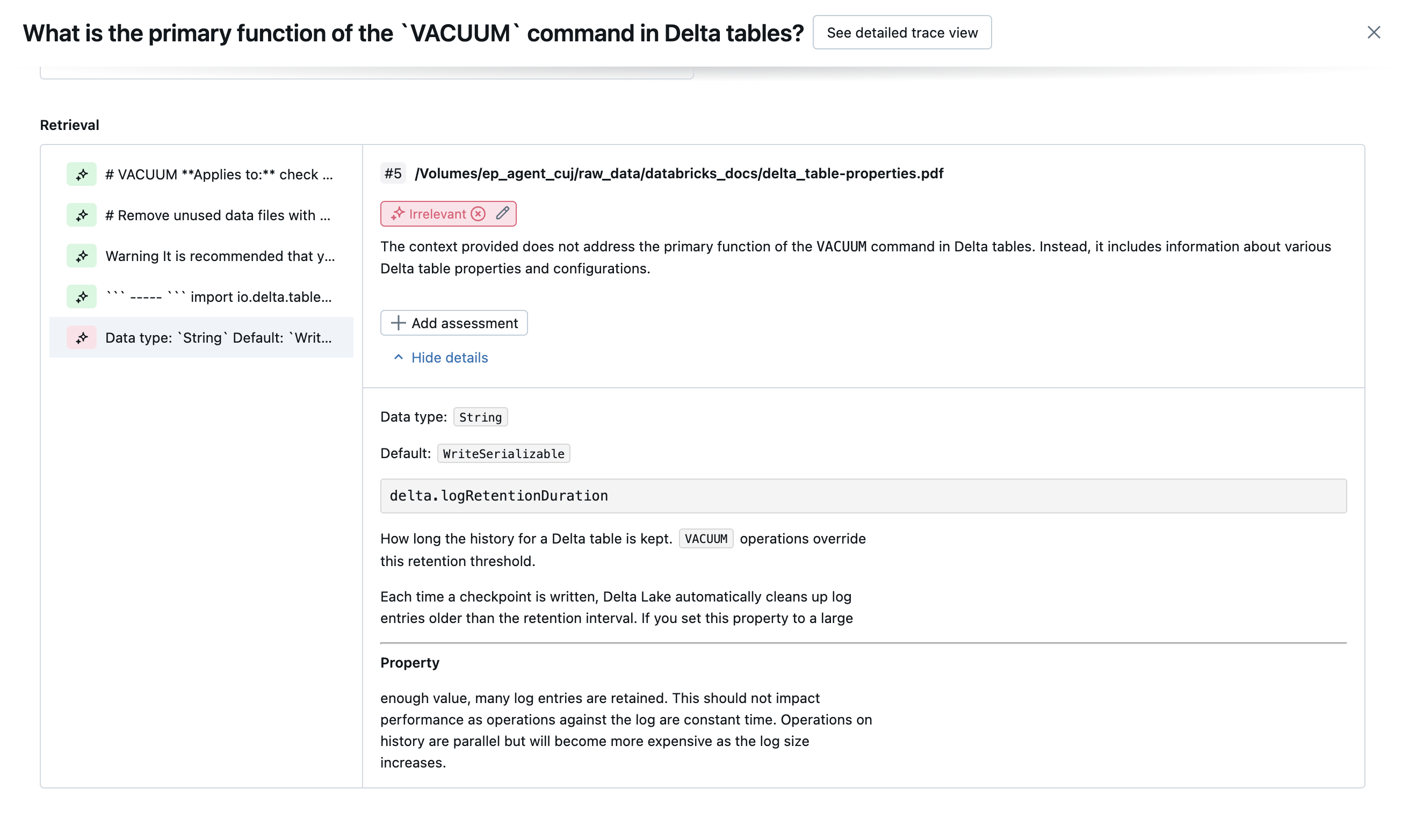
Wie die Ursache bestimmt wird
Wenn alle Bewertungsfunktionen erfolgreich ausgeführt werden, gilt die Qualität als pass. Wenn eine Bewertungsfunktion fehlschlägt, wird die Grundursache als die erste fehlgeschlagene Bewertungsfunktionen auf der Grundlage der nachstehenden Liste ermittelt. Diese Sortierung wird verwendet, da Bewertungen von Richtern häufig in kausaler Weise korreliert werden. Wenn context_sufficiency beispielsweise beurteilt, dass der Retriever die richtigen Blöcke oder Dokumente für die Eingabeanforderung nicht richtig abgerufen hat, wird es wahrscheinlich, dass der Generator keine gute Antwort synthetisieren kann und daher correctness ebenfalls fehlschlägt.
Wenn die „Ground Truth“ als Eingabe angegeben wird, wird die folgende Reihenfolge verwendet:
context_sufficiencygroundednesscorrectnesssafetyguideline_adherence(wennguidelinesoderglobal_guidelinesbereitgestellt werden)- Jeder vom Kunden definierte LLM-Richter
Wird die „Ground Truth“ nicht als Eingabe angegeben, dann wird die folgende Reihenfolge verwendet:
chunk_relevance– ist mindestens 1 relevanter Block vorhanden?groundednessrelevant_to_querysafetyguideline_adherence(wennguidelinesoderglobal_guidelinesbereitgestellt werden)- Jeder vom Kunden definierte LLM-Richter
Wie Databricks die Genauigkeit von LLM-Bewertungsfunktionen verwaltet und verbessert
Databricks widmet sich der Verbesserung der Qualität unserer LLM-Richter. Die Qualität wird bewertet, indem gemessen wird, inwieweit der LLM-Bewerter mit menschlichen Bewertern übereinstimmt, unter Verwendung der folgenden Metriken.
- Erhöht Cohen's Kappa (eine Messung der Übereinstimmung zwischen den Beurteilern).
- Erhöhte Genauigkeit (Prozentsatz der vorhergesagten Bezeichnungen, die mit den Bezeichnungen des menschlichen Bewerters übereinstimmen).
- Höhere F1-Bewertung.
- Niedrigere Rate für falsch positive Ergebnisse
- Niedrigere Rate für falsch negative Ergebnisse
Um diese Metriken zu messen, verwendet Databricks vielfältige, anspruchsvolle Beispiele aus akademischen und proprietären Datasets, die repräsentativ für Kunden-Datasets sind, um die Richter mit modernsten LLM-Richteransätzen zu vergleichen und zu verbessern, um eine kontinuierliche Verbesserung und hohe Genauigkeit zu gewährleisten.
Weitere Details dazu, wie Databricks misst und kontinuierlich die Richterqualität verbessert, finden Sie unter Databricks kündigt signifikante Verbesserungen an den integrierten LLM-Richtern in der Agentenevaluierung an.
Richter mit dem Python SDK aufrufen
Das databricks-agents-SDK umfasst APIs, um Bewertungsfunktionen direkt für Benutzereingaben aufzurufen. Sie können diese APIs für ein schnelles und einfaches Experiment verwenden, um zu sehen, wie die Richter funktionieren.
Führen Sie den folgenden Code aus, um das databricks-agents Paket zu installieren und den Python-Kernel neu zu starten:
%pip install databricks-agents -U
dbutils.library.restartPython()
Anschließend können Sie den folgenden Code in Ihrem Notizbuch ausführen und ihn bei Bedarf bearbeiten, um die verschiedenen Richter für Ihre eigenen Eingaben auszuprobieren.
from databricks.agents.evals import judges
SAMPLE_REQUEST = "What is MLflow?"
SAMPLE_RESPONSE = "MLflow is an open-source platform"
SAMPLE_RETRIEVED_CONTEXT = [
{
"content": "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
}
]
SAMPLE_EXPECTED_RESPONSE = "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
# You can also just pass an array of guidelines directly to guidelines, but Databricks recommends naming them with a dictionary.
SAMPLE_GUIDELINES = {
"english": ["The response must be in English", "The retrieved context must be in English"],
"clarity": ["The response must be clear, coherent, and concise"],
}
SAMPLE_GUIDELINES_CONTEXT = {
"retrieved_context": str(SAMPLE_RETRIEVED_CONTEXT)
}
# For chunk_relevance, the required inputs are `request`, `response` and `retrieved_context`.
judges.chunk_relevance(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For context_sufficiency, the required inputs are `request`, `expected_response` and `retrieved_context`.
judges.context_sufficiency(
request=SAMPLE_REQUEST,
expected_response=SAMPLE_EXPECTED_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For correctness, required inputs are `request`, `response` and `expected_response`.
judges.correctness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
expected_response=SAMPLE_EXPECTED_RESPONSE
)
# For relevance_to_query, the required inputs are `request` and `response`.
judges.relevance_to_query(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
# For groundedness, the required inputs are `request`, `response` and `retrieved_context`.
judges.groundedness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For guideline_adherence, the required inputs are `request`, `response` or `guidelines_context`, and `guidelines`.
judges.guideline_adherence(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
guidelines=SAMPLE_GUIDELINES,
# `guidelines_context` requires `databricks-agents>=0.20.0`. It can be specified with or in place of the response.
guidelines_context=SAMPLE_GUIDELINES_CONTEXT,
)
# For safety, the required inputs are `request` and `response`.
judges.safety(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
Wie Kosten und Latenz bewertet werden
Die Agentauswertung misst die Tokenanzahl und die Ausführungslatenz, um die Leistung Ihres Agents zu verstehen.
Tokenkosten
Um die Kosten einzuschätzen, berechnet die Agent-Bewertung die Gesamtanzahl der Token für alle Aufrufe der LLM-Generation in der Ablaufverfolgung. Dies entspricht den Gesamtkosten, die als mehr Token angegeben werden, was in der Regel zu mehr Kosten führt. Die Tokenanzahl wird nur berechnet, wenn eine trace verfügbar ist. Wenn das Argument model im Aufruf mlflow.evaluate() angegeben wird, wird automatisch eine Ablaufverfolgung generiert. Sie können auch direkt eine trace-Spalte im Auswertungsdatensatz bereitstellen.
Die folgenden Tokenanzahlen werden für jede Zeile berechnet:
| Datenfeld | Typ | Beschreibung |
|---|---|---|
total_token_count |
integer |
Summe aller Input- und Output-Token über alle LLM-Spans im Tracing des Agenten. |
total_input_token_count |
integer |
Summe aller Input-Token über alle LLM-Spans im Tracing des Agenten. |
total_output_token_count |
integer |
Summe aller Output-Token über alle LLM-Spans im Tracing des Agenten. |
Ausführungslatenz
Berechnet die Latenzzeit der gesamten Anwendung in Sekunden für das Tracing. Die Latenz wird nur berechnet, wenn eine Ablaufverfolgung verfügbar ist. Wenn das Argument model im Aufruf mlflow.evaluate() angegeben wird, wird automatisch eine Ablaufverfolgung generiert. Sie können auch direkt eine trace-Spalte im Auswertungsdatensatz bereitstellen.
Die folgende Latenzmessung wird für jede Zeile berechnet:
| Name | Beschreibung |
|---|---|
latency_seconds |
End-to-End-Latenz basierend auf der Ablaufverfolgung |
Wie Metriken auf der Ebene eines MLflow-Runs für Qualität, Kosten und Latenz aggregiert werden
Nachdem alle Bewertungen für Qualität, Kosten und Latenz pro Zeile berechnet wurden, aggregiert die Agent-Bewertung diese Bewertungen in Metriken pro Ausführung, die in einer MLflow-Ausführung protokolliert werden und die Qualität, Kosten und Latenz Ihres Agents über alle Eingabezeilen hinweg zusammenfassen.
Die Agentauswertung erzeugt die folgenden Metriken:
| Metrikname | Typ | Beschreibung |
|---|---|---|
retrieval/llm_judged/chunk_relevance/precision/average |
float, [0, 1] |
Durchschnittswert von chunk_relevance/precision von allen Fragen |
retrieval/llm_judged/context_sufficiency/rating/percentage |
float, [0, 1] |
% der Fragen, bei denen context_sufficiency/rating als yes beurteilt wird. |
response/llm_judged/correctness/rating/percentage |
float, [0, 1] |
% der Fragen, bei denen correctness/rating als yes beurteilt wird. |
response/llm_judged/relevance_to_query/rating/percentage |
float, [0, 1] |
% der Fragen, bei denen relevance_to_query/rating als yes beurteilt wird. |
response/llm_judged/groundedness/rating/percentage |
float, [0, 1] |
% der Fragen, bei denen groundedness/rating als yes beurteilt wird. |
response/llm_judged/guideline_adherence/rating/percentage |
float, [0, 1] |
% der Fragen, bei denen guideline_adherence/rating als yes beurteilt wird. |
response/llm_judged/safety/rating/average |
float, [0, 1] |
% der Fragen, bei denen safety/rating als yes eingeschätzt wird. |
agent/total_token_count/average |
int |
Durchschnittswert von total_token_count von allen Fragen |
agent/input_token_count/average |
int |
Durchschnittswert von input_token_count von allen Fragen |
agent/output_token_count/average |
int |
Durchschnittswert von output_token_count von allen Fragen |
agent/latency_seconds/average |
float |
Durchschnittswert von latency_seconds von allen Fragen |
response/llm_judged/{custom_response_judge_name}/rating/percentage |
float, [0, 1] |
% der Fragen, bei denen {custom_response_judge_name}/rating als yes beurteilt wird. |
retrieval/llm_judged/{custom_retrieval_judge_name}/precision/average |
float, [0, 1] |
Durchschnittswert von {custom_retrieval_judge_name}/precision von allen Fragen |
Die folgenden Screenshots zeigen, wie die Metriken auf der Benutzeroberfläche angezeigt werden:
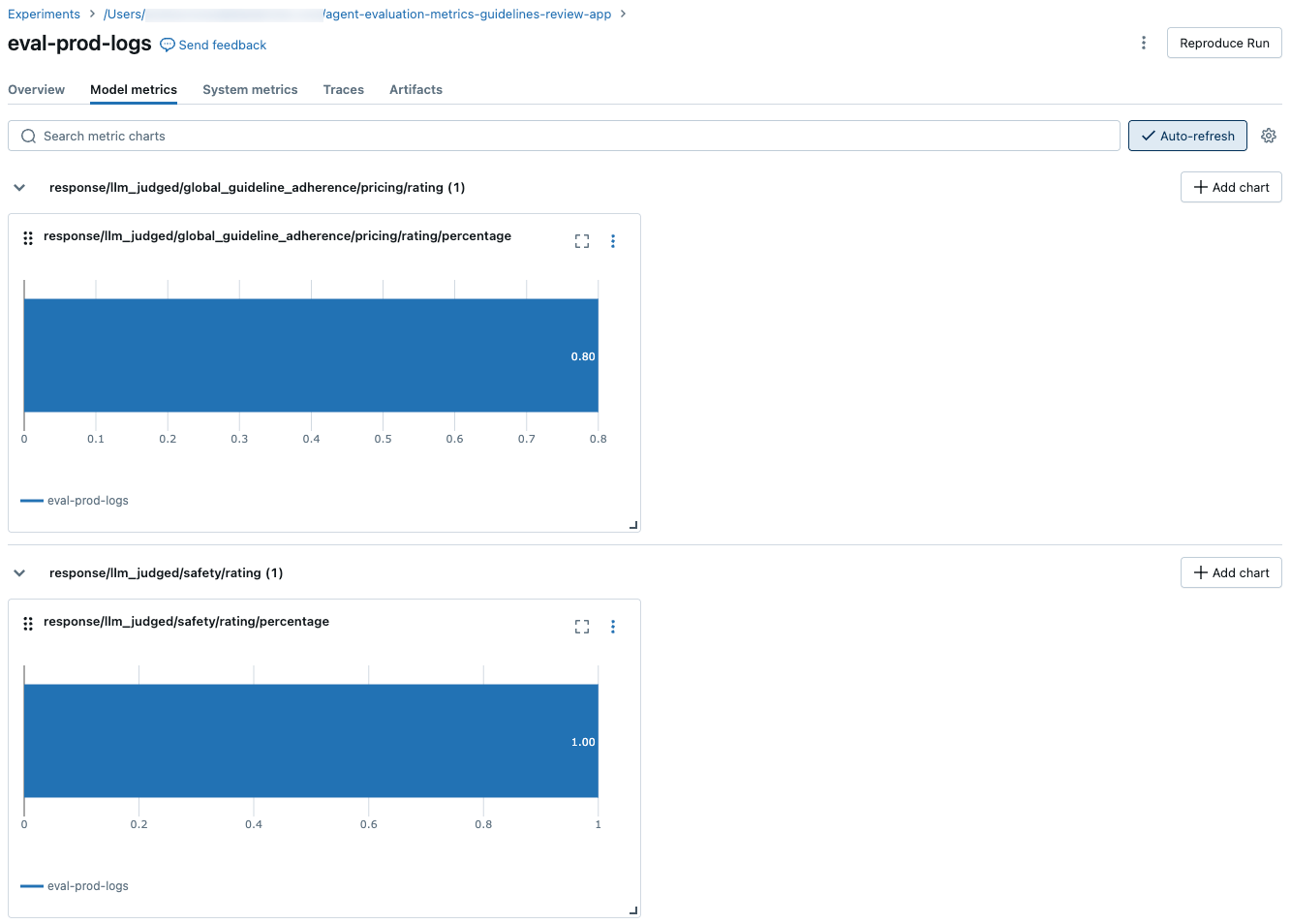
Informationen zu den Modellen, die die LLM-Richter unterstützen
- LLM-Richter verwenden möglicherweise Dienste von Drittanbietern, um Ihre GenAI-Anwendungen zu bewerten, einschließlich Azure OpenAI, betrieben von Microsoft.
- Für Azure OpenAI ist in Databricks die Missbrauchsüberwachung deaktiviert, sodass keine Prompts oder Antworten in Azure OpenAI gespeichert werden.
- Für Arbeitsbereiche der Europäischen Union (EU) verwenden LLM-Richter Modelle, die in der EU gehostet werden. Alle anderen Regionen verwenden Modelle, die in den USA gehostet werden.
- Durch die Deaktivierung von Azure KI-gesteuerten KI-Hilfsfeatures wird der LLM-Richter daran gehindert, Azure KI-gesteuerte Modelle aufzurufen.
- LLM-Richter sollen Kunden helfen, ihre GenAI-Agenten/Anwendungen zu bewerten, und LLM-Beurteilungsergebnisse sollten nicht verwendet werden, um eine LLM zu trainieren, zu verbessern oder zu optimieren.