Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird beschrieben, wie Vektorsuchendpunkte und Indizes mithilfe der Mosaik AI-Vektorsuche erstellt werden.
Mithilfe der Benutzeroberfläche, des Python SDK oder der REST API können Sie Vektorsuchkomponenten wie einen Vektorsuchendpunkt und Vektorsuchindizes erstellen und verwalten.
Beispielnotizbücher zum Erstellen und Abfragen von Vektorsuchendpunkten finden Sie unter Notizbücher für die Vektorsuche. Referenzinformationen finden Sie in der Python SDK-Referenz.
Anforderungen
- Arbeitsbereich mit Unity Catalog-Unterstützung.
- Serverloses Rechnen aktiviert Anleitungen finden Sie unter Verbinden mit serverlosem Computing.
- Für Standardendpunkte muss die Quelltabelle "Datenfeed ändern" aktiviert sein. Weitere Informationen finden Sie unter Verwendung des Delta Lake Change Data Feed auf Azure Databricks.
- Zum Erstellen eines Vektorsuchindex müssen Sie über CREATE TABLE Berechtigungen für das Katalogschema verfügen, in dem der Index erstellt wird.
- Um einen Index abzufragen, der einem anderen Benutzer gehört, müssen Sie über zusätzliche Berechtigungen verfügen. Siehe zur Abfrage eines Vektorsuchindexes.
Die Berechtigung zum Erstellen und Verwalten von Vektorsuchendpunkten wird mithilfe von Zugriffssteuerungslisten konfiguriert. Siehe Vektor-Suche-Endpunkt-ACLs.
Installation
Um das Vektorsuch-SDK zu verwenden, müssen Sie es in Ihrem Notizbuch installieren. Verwenden Sie den folgenden Code, um das Paket zu installieren:
%pip install databricks-vectorsearch
dbutils.library.restartPython()
Verwenden Sie dann den folgenden Befehl, um VectorSearchClientzu importieren:
from databricks.vector_search.client import VectorSearchClient
Informationen zur Authentifizierung finden Sie unter Datenschutz und Authentifizierung.
Einen Vektor-Suchendpunkt erstellen
Sie können einen Vektorsuchendpunkt mithilfe der Databricks-Benutzeroberfläche, Python SDK oder der API erstellen.
Erstellen eines Vektorsuchendpunkts mithilfe der Benutzeroberfläche
Führen Sie die folgenden Schritte aus, um einen Vektorsuchendpunkt mithilfe der Benutzeroberfläche zu erstellen.
Klicken Sie in der linken Seitenleiste auf Compute.
Klicken Sie auf die Registerkarte " Vektorsuche ", und klicken Sie auf " Endpunkt erstellen".

Das Formular zum Erstellen von Endpunkten wird geöffnet. Geben Sie einen Namen für diesen Endpunkt ein.
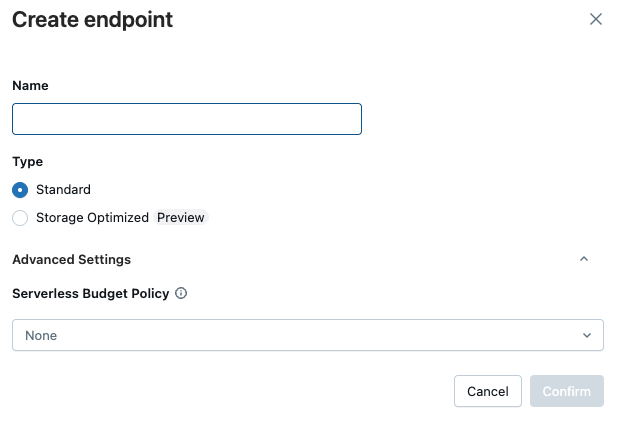
Wählen Sie im Feld "Typ " die Option "Standard " oder " Speicher optimiert" aus. Siehe Endpunktoptionen.
(Optional) Wählen Sie unter "Erweiterte Einstellungen" eine Budgetrichtlinie aus. Siehe Vektorsuchbudgetrichtlinien.
Klicken Sie auf Bestätigen.
Erstellen eines Vektorsuchendpunkts mithilfe des Python SDK
Im folgenden Beispiel wird die create_endpoint() SDK-Funktion verwendet, um einen Vektorsuchendpunkt zu erstellen.
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearchClient(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD" # or "STORAGE_OPTIMIZED"
)
Erstellen eines Vektorsuchendpunkts mithilfe der REST-API
Weitere Informationen finden Sie in der REST-API-Referenzdokumentation: POST /api/2.0/vector-search/endpoints.
Erstellen eines Endpunkts mit einem mindesten QPS-Ziel für Workloads mit hohem Durchsatz
Von Bedeutung
Dieses Feature befindet sich in der Betaversion. Arbeitsbereichsadministratoren können den Zugriff auf dieses Feature über die Vorschauseite steuern. Siehe Manage Azure Databricks Previews.
Für Workloads mit hohem Durchsatz können Sie einen Endpunkt mit einem minimalen QPS-Ziel erstellen. Dieses Feature ist nur für Standardendpunkte verfügbar.
Verwenden Sie den min_qps Parameter, um ein minimales QPS-Ziel festzulegen. Siehe Skalieren des Endpunktdurchsatzes mit hohem QPS (Beta)
Von Bedeutung
Die Bereitstellung min_qps zusätzlicher Kapazität erhöht die Kosten des Endpunkts. Sie werden für diese zusätzliche Kapazität berechnet, unabhängig vom tatsächlichen Abfragedatenverkehr. Um die Belastung zu beenden, setzen Sie den Endpunkt mithilfe von min_qps=-1. Die Durchsatzskalierung erfolgt nach dem Bestmöglichen-Einsatz-Prinzip und ist während der Beta nicht garantiert.
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD",
min_qps=500, # Beta: minimum QPS target for high-throughput workloads
)
Verwenden Sie update_endpoint(), um den Mindest-QPS für einen bestehenden Endpunkt zu ändern.
from databricks.vector_search.client import VectorSearchClient, MIN_QPS_RESET_TO_DEFAULT
client = VectorSearchClient()
# Set or update minimum QPS
response = client.update_endpoint(name="vector_search_endpoint_name", min_qps=500)
# Check scaling status
scaling_info = response.get("endpoint", {}).get("scaling_info", {})
print(f"State: {scaling_info.get('state')}") # SCALING_CHANGE_IN_PROGRESS or SCALING_CHANGE_APPLIED
# Remove high QPS configuration and return to default
client.update_endpoint(name="vector_search_endpoint_name", min_qps=MIN_QPS_RESET_TO_DEFAULT)
Synchronisieren Sie nach dem Aktualisieren der minimalen QPS Ihre Indizes, um die neue Konfiguration anzuwenden.
(Optional) Erstellen und Konfigurieren eines Endpunkts für das Einbettungsmodell
Wenn die Einbettungen von Databricks berechnet werden sollen, können Sie einen vordefinierten Foundation Model-API-Endpunkt verwenden oder ein Modell erstellen, das den Einbettungsmodell Ihrer Wahl bedient. Anweisungen hierzu finden Sie unter Foundation Model-APIs mit tokenbasierter Bezahlung oder Erstellen von Foundation Model-Bereitstellungsendpunkten. Beispielnotizbücher finden Sie unter Vektorsuch-Beispielnotizbücher.
Wenn Sie einen Einbettungsendpunkt konfigurieren, empfiehlt Databricks, die Standardauswahl von Auf Null skalieren zu entfernen. Die Aufwärmphase von Bereitstellungsendpunkten kann einige Minuten dauern, und die anfängliche Abfrage eines Index mit einem herunterskalierten Endpunkt kann zu einem Timeout führen.
Hinweis
Die Initialisierung des Index für die Vektorsuche kann sich verzögern, wenn der einbettende Endpunkt nicht entsprechend für das DataSet konfiguriert ist. Sie sollten nur CPU-Endpunkte für kleine Datasets und Tests verwenden. Verwenden Sie für größere Datasets einen GPU-Endpunkt, um eine optimale Leistung zu erzielen.
Erstellen eines Vektorsuchindex
Sie können einen Vektorsuchindex mithilfe der Benutzeroberfläche, des Python SDK oder der REST-API erstellen. Die Benutzeroberfläche ist der einfachste Ansatz.
Es gibt zwei Arten von Indizes:
- Der Delta-Synchronisierungsindex wird automatisch mit einer Delta-Tabelle synchronisiert und aktualisiert den Index inkrementell, während sich die zugrunde liegenden Daten in der Delta-Tabelle ändern.
- Direct Vector Access Index unterstützt das direkte Lesen und Schreiben von Vektoren und Metadaten. Der Benutzer ist für die Aktualisierung dieser Tabelle mit der REST-API oder dem Python SDK verantwortlich. Dieser Indextyp kann nicht mithilfe der Benutzeroberfläche erstellt werden. Sie müssen die REST-API oder das SDK verwenden.
Delta-Synchronisierungsindizes unterstützen die folgenden Suchmodi:
-
Vektorsuche (ANN oder Hybrid): Erfordert einbetten von Spalten. Unterstützt sowohl standard- als auch speicheroptimierte Endpunkte. Sie können auch für die Stichwortsuche für diese Indizes verwenden
query_type="FULL_TEXT". - Dedizierter Volltext-Suchindex (Beta): Ein Delta-Synchronisierungsindex , der ohne einbettende Spalten erstellt wurde, für die Nur-Schlüsselwort-Suche. Nur für speicheroptimierte Endpunkte verfügbar, die den ausgelösten Synchronisierungsmodus verwenden. Siehe Erstellen eines Volltext-Suchindexes.
Hinweis
Der Spaltenname _id ist reserviert. Wenn die Quelltabelle eine Spalte mit dem Namen _idhat, benennen Sie sie um, bevor Sie einen Vektorsuchindex erstellen.
Erstellen von Index mithilfe der Benutzeroberfläche
Klicken Sie in der linken Randleiste auf Katalog, um die Benutzeroberfläche des Katalog-Explorers zu öffnen.
Navigieren Sie zu der Delta-Tabelle, die Sie verwenden möchten.
Wählen Sie oben rechts die Schaltfläche Erstellen, und wählen Sie im Dropdownmenü den Vektorsuchindex aus.
Verwenden Sie die Selektoren im Dialogfeld, um den Index zu konfigurieren.
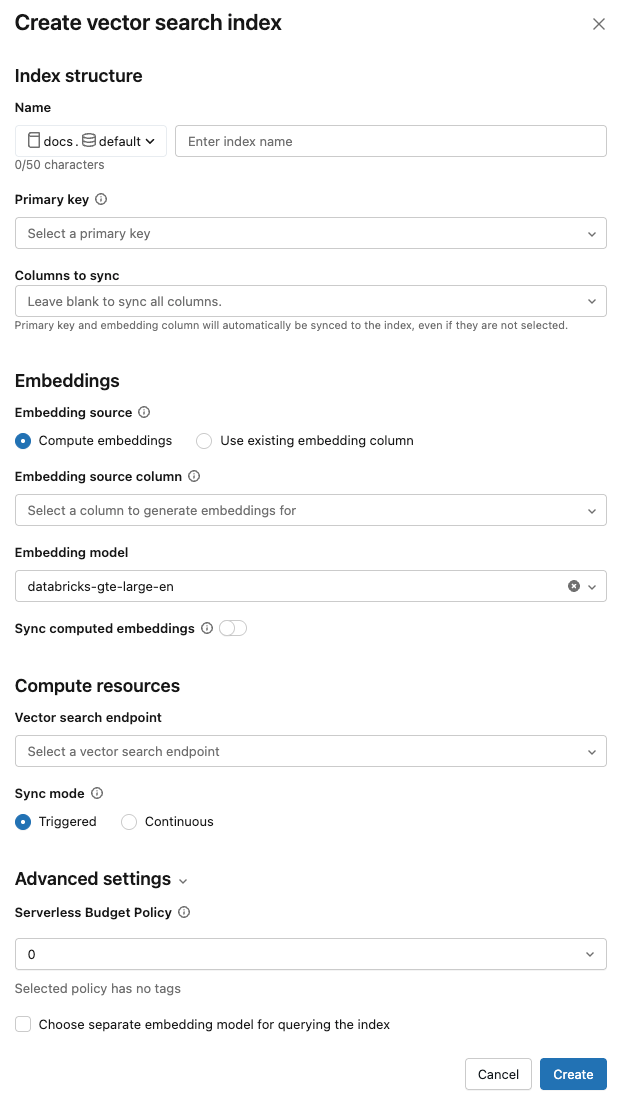
Name: Name, der für die Onlinetabelle in Unity Catalog verwendet werden soll Der Name erfordert einen Namespace mit drei Ebenen,
<catalog>.<schema>.<name>. Es sind nur alphanumerische Zeichen und Unterstriche zulässig.Primärschlüssel: Spalte, die als Primärschlüssel verwendet werden soll.
Zu synchronisierende Spalten: Wählen Sie die Spalten aus, die mit dem Vektorindex synchronisiert werden sollen. Wenn Sie dieses Feld leer lassen, werden alle Spalten aus der Quelltabelle mit dem Index synchronisiert. Die Primärschlüsselspalte und die Einbettungsquellenspalte oder Einbettungsvektorspalte werden immer synchronisiert.
Einbettungsquelle: Geben Sie an, ob Databricks Einbettungen für eine Textspalte in der Delta-Tabelle berechnen sollen (Compute Embeddings), oder wenn Ihre Delta-Tabelle vorkompilierte Einbettungen enthält (Vorhandene Einbettungsspalteverwenden ).
Wenn Sie "Compute embeddings" ausgewählt haben, wählen Sie die Spalte aus, für die Sie Einbettungen berechnen möchten, und das für die Berechnung zu verwendende Einbettungsmodell. Nur Textspalten werden unterstützt.
Für Produktionsanwendungen, die Standardendpunkte verwenden, empfiehlt Databricks die Verwendung des Foundation-Modells
databricks-gte-large-enmit einem bereitgestellten Durchsatz, der den Endpunkt bedient.Verwenden Sie für Produktionsanwendungen, die speicheroptimierte Endpunkte mit von Databricks gehosteten Modellen verwenden, den Modellnamen direkt (z. B
databricks-gte-large-en. ) als Einbettungsmodellendpunkt. Speicheroptimierte Endpunkte verwendenai_querymit Batch-Inferenz zur Eingabezeit und bieten einen hohen Durchsatz für den Einbettungsjob. Wenn Sie einen bereitgestellten Durchsatzendpunkt für die Abfrage verwenden möchten, geben Sie ihn beim Erstellen des Indexes immodel_endpoint_name_for_queryFeld an.
Wenn Sie Vorhandene Einbettungsspalte verwenden ausgewählt haben, wählen Sie die Spalte aus, welche die vorkompilierten Einbettungen und die Dimension für das Einbetten enthält. Das Format der vorkompilierten Einbettungsspalte sollte
array[float]sein. Für speicheroptimierte Endpunkte muss die Einbettungsdimension gleichmäßig durch 16 dividierbar sein.
Synchronisierung berechneter Einbettungen: Aktivieren Sie diese Einstellung, um die generierten Einbettungen in einer Unity-Katalogtabelle zu speichern. Weitere Informationen finden Sie unter Speichern generierter Einbettungstabelle.
Vektorsuchendpunkt: Wählen Sie den Vektorsuchendpunkt aus, um den Index zu speichern.
Synchronisierungsmodus: Fortlaufend hält den Index mit wenigen Sekunden Latenz synchronisiert. Es ist jedoch mit höheren Kosten verbunden, da ein Rechencluster bereitgestellt wird, um die fortlaufende Stream-Synchronisierungspipeline auszuführen.
- Bei Standard-Endpunkten führen sowohl Kontinuierlich als auch Triggered inkrementelle Aktualisierungen durch, so dass nur Daten verarbeitet werden, die sich seit der letzten Sync, Synchronisierung, synchronisiert haben.
- Für speicheroptimierte Endpunkte erstellt jede Synchronisierung den Index teilweise neu. Bei verwalteten Indizes für nachfolgende Synchronisierungen werden alle generierten Einbettungen, bei denen sich die Quellzeile nicht geändert hat, wiederverwendet und müssen nicht erneut kompiliert werden. Siehe Einschränkungen für speicheroptimierte Endpunkte.
Mit Triggered Synchronisierungsmodus verwenden Sie das Python SDK oder die REST-API, um die Synchronisierung zu starten. Siehe Update a Delta Sync Index.
Für speicheroptimierte Endpunkte wird nur der triggerte Synchronisierungsmodus unterstützt.
Erweiterte Einstellungen: (Optional)
Sie können eine Budgetrichtlinie auf den Index anwenden. Siehe Vektorsuchbudgetrichtlinien.
Wenn Sie compute embeddings ausgewählt haben, können Sie ein separates Einbettungsmodell angeben, um den Vektorsuchindex abzufragen. Dies kann nützlich sein, wenn Sie einen Endpunkt mit hohem Durchsatz für die Aufnahme, aber einen niedrigeren Latenzendpunkt für die Abfrage des Indexes benötigen. Das im Feld "Einbettungsmodell " angegebene Modell wird immer für die Aufnahme verwendet und auch für die Abfrage verwendet, es sei denn, Sie geben hier ein anderes Modell an. Wenn Sie ein anderes Modell angeben möchten, klicken Sie auf "Separates Einbettungsmodell auswählen", um den Index abzufragen , und wählen Sie ein Modell aus dem Dropdownmenü aus.
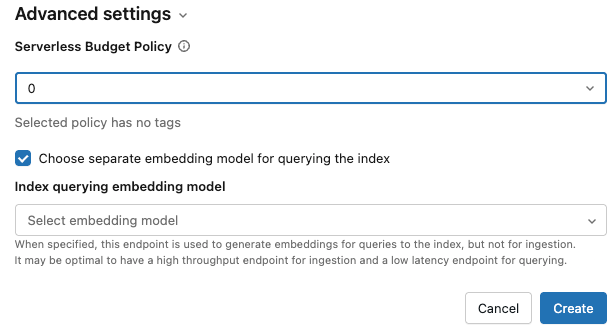
Wenn Sie die Konfiguration des Index abgeschlossen haben, klicken Sie auf Erstellen.
Erstellen von Index mithilfe des Python SDK
Im folgenden Beispiel wird ein Delta-Synchronisierungsindex mit von Databricks berechneten Einbettungen erstellt. Ausführliche Informationen finden Sie in der SDK-Referenz Python.
Dieses Beispiel zeigt auch den optionalen Parameter model_endpoint_name_for_query, der ein separates Einbettungsmodell angibt, das für die Abfrage des Indexes verwendet werden soll.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2", # This model is used for ingestion, and is also used for querying unless model_endpoint_name_for_query is specified.
model_endpoint_name_for_query="e5-mini-v2" # Optional. If specified, used only for querying the index.
)
Im folgenden Beispiel wird ein Delta-Synchronisierungsindex mit selbstverwalteten Einbettungen erstellt.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
Standardmäßig werden alle Spalten aus der Quelltabelle mit dem Index synchronisiert. Verwenden Sie columns_to_sync, um eine Teilmenge der zu synchronisierenden Spalten auszuwählen. Der Primärschlüssel und die Einbettungsspalten sind immer im Index enthalten.
Um nur den Primärschlüssel und die Einbettungsspalte zu synchronisieren, müssen Sie diese in columns_to_sync wie im Beispiel gezeigt angeben.
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
Um zusätzliche Spalten zu synchronisieren, geben Sie sie wie dargestellt an. Sie müssen den Primärschlüssel und die Einbettungsspalte nicht einschließen, da sie immer synchronisiert werden.
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
Erstellen eines Volltext-Suchindexes (Beta)
Von Bedeutung
Die Indexerstellung mit Volltextsuche ist nur für speicheroptimierte Endpunkte als Beta-Feature verfügbar. Um sie zu verwenden, muss die vs_full_text Arbeitsbereichvorschau aktiviert sein. Wenden Sie sich an Ihr Kontoteam, oder siehe Manage Azure Databricks Vorschauen, um Vorschauen zu aktivieren.
Ein Volltext-Suchindex ermöglicht die schlüsselwortbasierte Suche auf Textspalten, ohne dass Vektoreinbettungen erforderlich sind. Dies ist nützlich, wenn Sie nach genauen Begriffen, Bezeichnern oder Schlüsselwörtern suchen möchten, anstatt nach semantischer Ähnlichkeit.
Volltext-Suchindizes haben die folgenden Anforderungen:
- Muss einen speicheroptimierten Endpunkt verwenden. Standardendpunkte werden nicht unterstützt.
- Muss den Trigger-Synchronisierungsmodus verwenden. Kontinuierliche Synchronisierung wird nicht unterstützt.
- Die Parameter
embedding_source_column,embedding_vector_columnundembedding_dimensionwerden nicht unterstützt.
Im folgenden Beispiel wird mithilfe des Python SDK ein Volltextsuchindex erstellt.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="storage_optimized_endpoint",
source_table_name="catalog.schema.source_table",
index_name="catalog.schema.full_text_index",
pipeline_type="TRIGGERED",
primary_key="id",
columns_to_sync=["id", "text", "metadata_column"],
index_subtype="FULL_TEXT"
)
Lösen Sie nach dem Erstellen des Indexes eine Synchronisierung aus, um sie aufzufüllen:
index.sync()
Verwenden Sie query_type="FULL_TEXT"zum Abfragen des Volltextindexes . Details finden Sie unter Abfragen eines Vektorsuchindex .
results = index.similarity_search(
query_text="search terms",
columns=["id", "text"],
num_results=10,
query_type="FULL_TEXT"
)
Im folgenden Beispiel wird ein Direct Vector Access Index erstellt.
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name=f"{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
Erstellen eines Indexes mithilfe der REST-API
Weitere Informationen finden Sie in der REST-API-Referenzdokumentation: POST /api/2.0/vector-search/indexes.
Generierte Einbettungstabelle speichern
Wenn Databricks die Einbettungen generiert, können Sie die generierten Einbettungen in einer Tabelle im Unity-Katalog speichern. Diese Tabelle wird im gleichen Schema wie der Vektorindex erstellt und von der Vektorindexseite verknüpft.
Der Name der Tabelle ist der Name des Vektorsuchindex, angefügt von _writeback_table. Der Name kann nicht bearbeitet werden.
Sie können auf die Tabelle wie jede andere Tabelle im Unity-Katalog zugreifen und diese abfragen. Sie sollten die Tabelle jedoch nicht ablegen oder ändern, da sie nicht manuell aktualisiert werden soll. Die Tabelle wird automatisch gelöscht, wenn der Index gelöscht wird.
Aktualisieren eines Vektorsuchindex
Aktualisieren eines Delta-Synchronisierungsindex
Indizes, die mit fortlaufenden Synchronisierungsmodus erstellt wurden, werden automatisch aktualisiert, wenn sich die Delta-Quelltabelle ändert. Wenn Sie Triggered-Synchronisierungsmodus verwenden, können Sie die Synchronisierung mit der Benutzeroberfläche, dem Python SDK oder der REST-API starten.
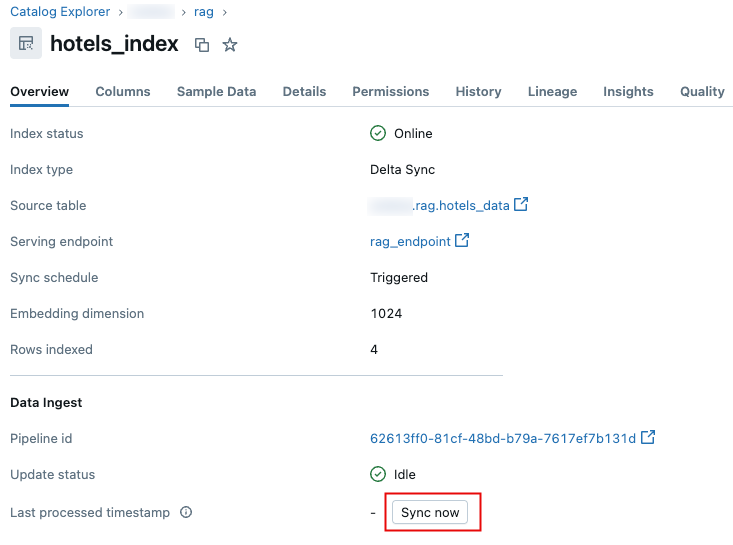
Databricks UI
Navigieren Sie im Katalog-Explorer zum Vektorsuchindex.
Klicken Sie auf der Registerkarte "Übersicht " im Abschnitt "Datenaufnahme " auf "Jetzt synchronisieren".
Python SDK
Ausführliche Informationen finden Sie in der SDK-Referenz Python.
client = VectorSearchClient()
index = client.get_index(index_name="vector_search_demo.vector_search.en_wiki_index")
index.sync()
REST API
Weitere Informationen finden Sie in der REST-API-Referenzdokumentation: POST /api/2.0/vector-search/indexes/{index_name}/sync.
Aktualisieren eines Direct Vector Access Index
Sie können das Python SDK oder die REST-API verwenden, um Daten aus einem Direct Vector Access-Index einzufügen, zu aktualisieren oder zu löschen.
Python SDK
Ausführliche Informationen finden Sie in der SDK-Referenz Python.
index.upsert([
{
"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0] * 1024
},
{
"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1] * 1024
}
])
REST API
Weitere Informationen finden Sie in der REST-API-Referenzdokumentation: POST /api/2.0/vector-search/indexes.
Für Produktionsanwendungen empfiehlt Databricks die Verwendung von Dienstprinzipalen anstelle von persönlichen Zugriffstoken. Die Leistung kann durch bis zu 100 msec pro Abfrage verbessert werden.
Im folgenden Codebeispiel wird veranschaulicht, wie ein Index mithilfe eines Dienstprinzipals aktualisiert wird.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into vector search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from vector search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
Im folgenden Codebeispiel wird veranschaulicht, wie ein Index mithilfe eines persönlichen Zugriffstokens (PERSONAL Access Token, PAT) aktualisiert wird.
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into vector search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from vector search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
So nehmen Sie Schemaänderungen ohne Ausfallzeiten vor
Schemaänderungen an der Quelltabelle werden nur unterstützt, wenn Sie den Index neu erstellen. Dazu gehört das Ändern vorhandener Spalten und das Hinzufügen neuer Spalten. Das Indexschema wird zur Erstellungszeit festgelegt, sodass alle Schemaänderungen das Erstellen eines neuen Indexes erfordern, um wirksam zu werden.
Führen Sie die folgenden Schritte aus, um den Index ohne Ausfallzeiten neu zu erstellen und bereitzustellen:
- Führen Sie die Schemaänderung in der Quelltabelle aus.
- Erstellen Sie einen neuen Index mithilfe des aktualisierten Schemas.
- Nachdem der neue Index bereit ist, wechseln Sie zum neuen Index.
- Löschen Sie den ursprünglichen Index.