Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GenAI-Agents kombinieren die Intelligenz von GenAI-Modellen mit Tools zum Abrufen von Daten, externen Aktionen und anderen Funktionen. Diese Seite erläutert den Entwurf des Agenten:
- Ein konkretes Beispiel für den Aufbau eines Agentensystems veranschaulicht die Koordination der Abläufe von Modell- und Toolaufrufen.
- Designmuster für Agentsysteme bilden ein Kontinuum der Komplexität und Autonomie, von deterministischen Ketten über Einzel-Agent-Systeme, die dynamische Entscheidungen treffen können, bis hin zu Multi-Agent-Architekturen, die mehrere spezialisierte Agents koordinieren.
- Ein praktischer Ratschlagabschnitt gibt Ratschläge zur Auswahl des richtigen Designs und zur Entwicklung von Agenten, Testen und Übergang in die Produktion.
Agenten verlassen sich stark auf Tools zum Sammeln von Informationen und zum Ergreifen externer Aktionen. Weitere Hintergrundinformationen zu Tools finden Sie unter Tools.
Beispiel-Agent-System
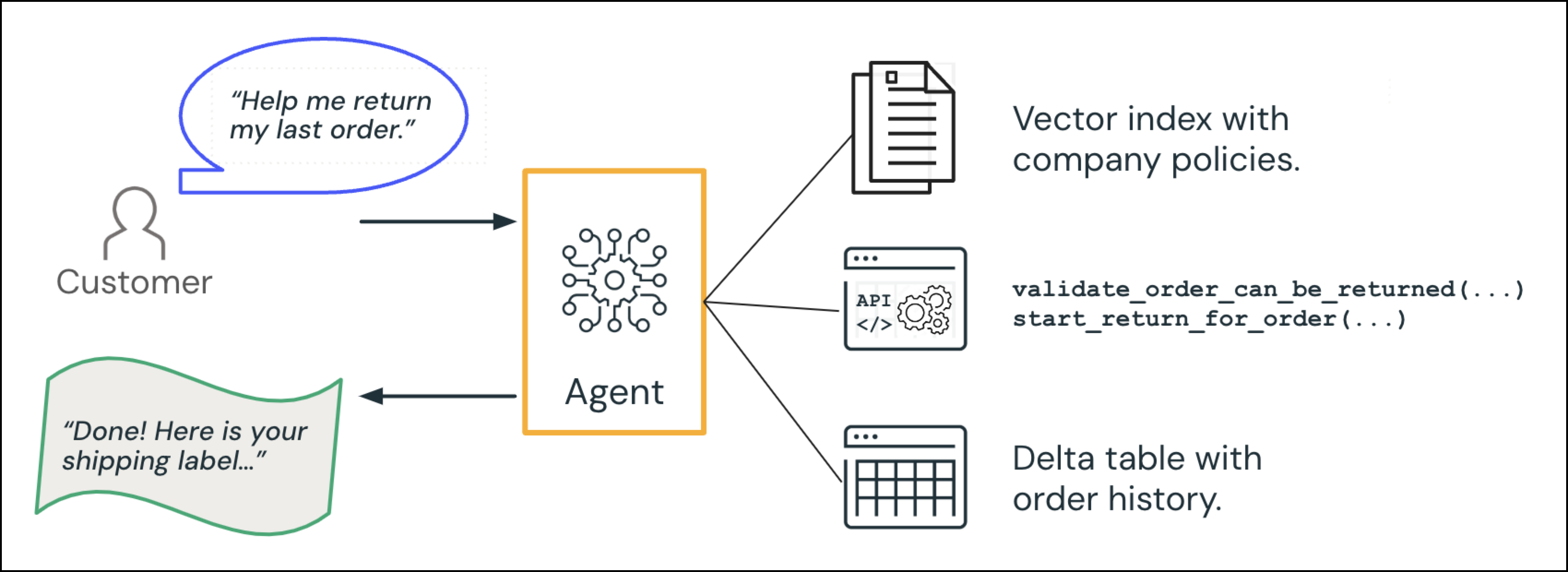
Für ein konkretes Beispiel für ein Agent-System sollten Sie einen GenAI-Callcenter-Agent in Betracht ziehen, der mit einem Kunden interagiert:
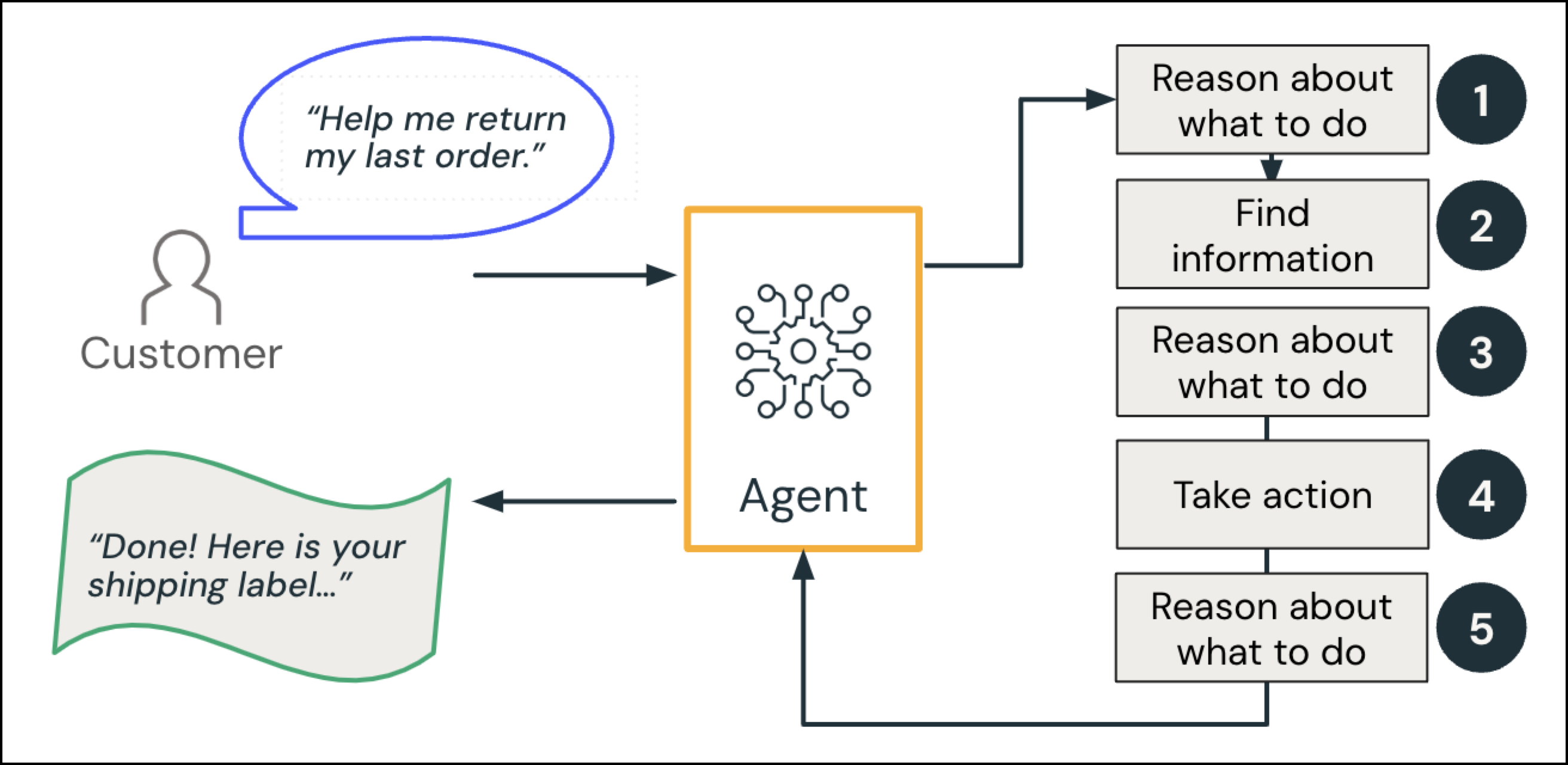
Der Kunde stellt eine Anfrage: "Können Sie mir helfen, meine letzte Bestellung zurückzugeben?"
- Grund und Plan: Angesichts der Absicht der Abfrage plant der Agent: "Die letzte Bestellung des Benutzers nachschlagen und unsere Rückgaberichtlinie überprüfen."
- Informationen finden (Datenintelligenz): Der Agent fragt die Bestelldatenbank ab, um die relevante Bestellung abzurufen und konsultiert ein Richtliniendokument.
-
Grund: Der Agent überprüft, ob diese Reihenfolge in das Rückgabefenster passt.
- Optionaler Mensch in der Schleife: Der Agent überprüft eine zusätzliche Regel: Wenn das Element in eine bestimmte Kategorie fällt oder sich außerhalb des normalen Rückgabefensters befindet, eskalieren Sie an einen Menschen.
- Aktion: Der Agent löst den Rückgabevorgang aus und generiert ein Versandetikett.
- Grund: Der Agent generiert eine Antwort auf den Kunden.
Der KI-Agent antwortet auf den Kunden: "Fertig! Hier ist Ihr Versandetikett..."
Diese Schritte sind zweite Natur in einem menschlichen Callcenterkontext. In einem Agentensystem-Kontext zieht das LLM Schlussfolgerungen, während das System spezielle Tools oder Datenquellen aufruft, um die Details zu ergänzen.
Komplexitätsstufen: Von LLMs zu Agentsystemen
GenAI-Apps können von einer Reihe von Systemen unterstützt werden, von einfachen LLM-Aufrufen bis hin zu komplexen Multi-Agent-Systemen. Starten Sie beim Erstellen einer KI-basierten Anwendung einfach. Führen Sie komplexere agentische Verhaltensweisen ein, wenn Sie sie wirklich für eine bessere Flexibilität oder modellgesteuerte Entscheidungen benötigen. Deterministische Ketten bieten vorhersehbare, regelbasierte Flüsse für gut definierte Vorgänge. Mehr agentische Methoden bieten eine größere Flexibilität und ein größeres Potenzial, aber sie gehen mit den Kosten zusätzlicher Komplexität und verzögertem Antwortverhalten einher.
| Entwurfsmuster | Wann verwendet werden soll | Vorteile | Nachteile |
|---|---|---|---|
| LLM + Prompt |
|
|
|
| Deterministische Kette |
|
|
|
| Einzel-Agent-System |
|
|
|
| Multi-Agent-System |
|
|
|
Agent Framework ist für diese Muster agnostisch, sodass es einfach ist, einfach zu beginnen und sich zu höheren Automatisierungs- und Autonomiestufen zu entwickeln, während Ihre Anwendungsanforderungen wachsen.
Weitere Informationen zur Theorie hinter Agent-Systemen finden Sie in Blogbeiträgen der Databricks-Gründer:
- KI-Agent-Systeme: Modulares Engineering für zuverlässige KI-Anwendungen für Unternehmen
- Der Wechsel von Modellen zu Verbund-KI-Systemen
LLM und Prompt
Das einfachste Design verfügt über ein eigenständiges LLM- oder ein anderes GenAI-Modell, das auf Aufforderungen basierend auf dem Wissen aus einem umfangreichen Schulungsdatensatz reagiert. Dieses Design eignet sich gut für einfache oder generische Abfragen, ist aber häufig von Ihren realen Geschäftsdaten getrennt. Sie können das Verhalten anpassen, indem Sie eine Systemaufforderung mit Ihren benutzerdefinierten Anweisungen oder eingebetteten Daten bereitstellen.

Deterministische Kette (hartcodierte Schritte)
Deterministische Ketten erweitern GenAI-Modelle mit Toolaufrufen, aber der Entwickler definiert, welche Tools oder Modelle aufgerufen werden, in welcher Reihenfolge und mit welchen Parametern. Die LLM trifft keine Entscheidungen darüber , welche Tools aufgerufen werden sollen oder in welcher Reihenfolge. Das System folgt einem vordefinierten Workflow oder einer "Kette" für alle Anforderungen, sodass es sehr vorhersehbar ist.
Beispielsweise könnte eine deterministische Retrieval-augmentierte Generierungskette (RAG) immer:
- Rufen Sie top-k-Ergebnisse aus einem Vektorindex ab, um kontextrelevanten Kontext für eine Benutzeranforderung zu finden.
- Erweitern Sie eine Eingabeaufforderung, indem Sie die Benutzeranforderung mit dem abgerufenen Kontext kombinieren.
- Generieren Sie eine Antwort, indem Sie die erweiterte Eingabeaufforderung an eine LLM senden.

Verwendungsbedingungen:
- Für gut definierte Aufgaben mit vorhersagbaren Workflows.
- Wenn Konsistenz und Überwachung oberste Prioritäten sind.
- Wenn Sie die Latenz minimieren möchten, indem Sie mehrere LLM-Aufrufe für Orchestrierungsentscheidungen vermeiden.
Vorteile:
- Höchste Vorhersagbarkeit und Auditierbarkeit.
- In der Regel geringere Latenz (weniger LLM-Aufrufe für die Orchestrierung).
- Einfacheres Testen und Überprüfen.
Überlegungen:
- Begrenzte Flexibilität für die Behandlung unterschiedlicher oder unerwarteter Anforderungen.
- Kann zunehmend komplex und schwierig zu handhaben sein, wenn logische Verzweigungen wachsen.
- Kann eine erhebliche Umgestaltung erfordern, um neue Funktionen zu berücksichtigen.
Einzel-Agent-System
Ein Einzel-Agent-System verfügt über ein LLM, das einen koordinierten Logikfluss koordiniert. Die LLM entscheidet adaptiv, welche Tools verwendet werden sollen, wann mehr LLM-Aufrufe erfolgen sollen und wann damit aufgehört werden soll. Dieser Ansatz unterstützt dynamische, kontextbezogene Entscheidungen.
Ein Einzel-Agent-System kann:
- Nehmen Sie Anforderungen wie Benutzeranfragen und relevanten Kontext wie z. B. den Unterhaltungsverlauf entgegen.
- Überlegen Sie, wie man am besten reagiert, und entscheiden Sie optional, ob Tools für externe Daten oder Aktionen aufgerufen werden sollen.
- Iterieren Sie bei Bedarf, indem Sie wiederholt ein LLM oder die Werkzeuge aufrufen, um ein Ziel zu erreichen oder eine bestimmte Bedingung zu erfüllen, wie z. B. gültige Daten zu empfangen oder einen Fehler zu beheben.
- Integrieren Sie Werkzeugausgaben in das Gespräch.
- Gibt eine zusammenhängende Antwort als Ausgabe zurück.
Beispielsweise kann sich ein Helpdesk-Assistent wie folgt anpassen:
- Wenn der Benutzer eine einfache Frage stellt ("Was ist unsere Rückgaberichtlinie?"), könnte der Agent direkt aus dem Wissen des LLM antworten.
- Wenn der Benutzer seinen Bestellstatus wünscht, ruft der Agent möglicherweise eine Funktion
lookup_order(customer_id, order_id)auf. Wenn dieses Tool mit "ungültige Bestellnummer" antwortet, kann der Agent den Benutzer erneut zur richtigen ID auffordern, bis er eine endgültige Antwort bereitstellen kann.

Verwendungsbedingungen:
- Sie erwarten unterschiedliche Benutzerabfragen, aber immer noch innerhalb einer zusammenhängenden Domäne oder eines Produktbereichs.
- Bestimmte Abfragen oder Bedingungen können die Verwendung von Tools garantieren, z. B. die Entscheidung, wann Kundendaten abgerufen werden sollen.
- Sie benötigen mehr Flexibilität als eine deterministische Kette, erfordern jedoch keine separaten spezialisierten Agents für verschiedene Aufgaben.
Vorteile:
- Der Agent kann sich an neue oder unerwartete Abfragen anpassen, indem sie auswählen, welche (falls vorhanden) Tools aufgerufen werden sollen.
- Der Agent kann wiederholte LLM-Aufrufe oder Toolaufrufe durchlaufen, um Ergebnisse zu verfeinern , ohne dass eine vollständige Einrichtung mit mehreren Agents erforderlich ist.
- Dieses Entwurfsmuster ist häufig der süße Punkt für Unternehmensanwendungsfälle – einfacher zu debuggen als Multi-Agent-Setups, während gleichzeitig dynamische Logik und eingeschränkte Autonomie ermöglicht werden.
Überlegungen:
- Im Vergleich zu einer fest verdrahteten Kette müssen Sie sich gegen wiederholte oder ungültige Tool-Aufrufe wappnen. Unendliche Schleifen können in jedem Toolaufrufszenario auftreten, sodass Iterationsgrenzwerte oder Timeouts festgelegt werden.
- Wenn Ihre Anwendung radikal unterschiedliche Unterdomänen (Finanzen, DevOps, Marketing usw.) umfasst, kann ein einzelner Agent unübersichtlich oder mit den Funktionsanforderungen überlastet werden.
- Sie benötigen immer noch sorgfältig gestaltete Eingabeaufforderungen und Einschränkungen, um den Agenten fokussiert und relevant zu halten.
- Agentur ist kontinuum; je mehr Freiheit Sie Modelle bereitstellen, um das Verhalten des Systems zu steuern, desto agentischer wird die Anwendung. In der Praxis schränken die meisten Produktionssysteme die Autonomie des Agenten sorgfältig ein, um die Einhaltung und Vorhersagbarkeit zu gewährleisten, z. B. durch die Notwendigkeit einer menschlichen Genehmigung für riskante Maßnahmen.
Multi-Agent-System
Ein Multi-Agent-System umfasst zwei oder mehr spezialisierte Agents, die Nachrichten austauschen oder an Aufgaben zusammenarbeiten. Jeder Agent verfügt über eigene Domänen- oder Aufgabenkompetenzen, Kontext und potenziell unterschiedliche Toolgruppen. Ein separater "Koordinator" oder "KI-Vorgesetzter" leitet Anfragen an den entsprechenden Agenten weiter oder entscheidet, wann die Übergabe von einem Agenten an einen anderen erfolgen soll. Der Vorgesetzte kann ein anderer LLM oder ein regelbasierter Router sein.

Beispielsweise kann ein Kundenassistent einen Vorgesetzten haben, der an spezialisierte Agenten delegiert:
- Shopping-Assistent: Hilft Kunden bei der Suche nach Produkten und bietet Ratschläge zu Vor- und Nachteilen von Bewertungen
- Kundendienstmitarbeiter: Verarbeitet Feedback, Rückgaben und Versand
Verwendungsbedingungen:
- Sie haben unterschiedliche Problembereiche oder Qualifikationssätze, z. B. einen Codierungsagenten oder einen Finanzberater.
- Jeder Agent benötigt Zugriff auf aufgezeichnete Unterhaltungen oder domänenspezifische Eingabeaufforderungen.
- Sie haben so viele Tools, dass es unpraktisch ist, sie alle in das Schema eines einzigen Agenten zu integrieren; jeder Agent kann eine eigene Teilmenge besitzen.
- Sie möchten Reflexion, Kritik oder wechselseitige Zusammenarbeit zwischen spezialisierten Agenten implementieren.
Vorteile:
- Dieser modulare Ansatz bedeutet, dass jeder Agent von separaten Teams entwickelt oder verwaltet werden kann, die sich auf eine enge Domäne spezialisiert haben.
- Kann große, komplexe Unternehmensworkflows verarbeiten, die ein einzelner Mitarbeiter möglicherweise schwer bewältigen könnte.
- Erleichtert die erweiterte mehrstufige oder multispektivische Begründung , z. B. einen Agenten, der eine Antwort generiert, eine andere, die sie überprüft.
Überlegungen:
- Erfordert eine Strategie für das Routing zwischen Agents sowie mehr Aufwand für protokollierung, Ablaufverfolgung und Debugging über mehrere Endpunkte hinweg.
- Wenn Sie über viele Unter-Agents und Tools verfügen, kann es kompliziert werden, zu entscheiden, welcher Agent Zugriff auf welche Daten oder APIs hat.
- Agenten können Aufgaben unbestimmt miteinander hin- und herschieben, ohne eine Lösung, wenn sie nicht sorgfältig eingegrenzt sind. Unendliche Schleifenrisiken bestehen auch bei Toolanrufen mit einem Einzigen Agent, aber Multi-Agent-Setups fügen eine weitere Ebene der Debuggingkomplexität hinzu.
Praktische Beratung
Wenn Ihr Anwendungsfall mithilfe des Wissens-Assistenten oder eines KI-Funktionsangebots behoben werden kann, beginnen Sie mit dieser geführten, einfacheren Option.
Wenn Sie ein benutzerdefiniertes Agent-System erstellen müssen, sind Azure Databricks und das Mosaik AI Agent Framework unabhängig von dem muster, das Sie auswählen, und es ist einfach, Entwurfsmuster zu entwickeln, während Ihre Anwendung wächst. Berücksichtigen Sie die folgenden bewährten Methoden für die Entwicklung stabiler, wartungsfähiger Agent-Systeme:
- Beginnen Sie einfach: Wenn Sie nur eine einfache Kette benötigen, ist eine deterministische Kette schnell zu erstellen.
- Schrittweises Hinzufügen von Komplexität: Wenn Sie dynamischere Abfragen oder flexible Datenquellen benötigen, wechseln Sie mit Toolaufrufen zu einem Einzel-Agent-System. Wenn Sie eindeutig unterschiedliche Domänen oder Aufgaben, mehrere Unterhaltungskontexte oder einen großen Toolsatz haben, sollten Sie ein Multi-Agent-System in Betracht ziehen.
- Kombinieren von Mustern: In der Praxis kombinieren viele reale Agentsysteme Muster. Beispielsweise kann eine meist deterministische Kette einen Schritt aufweisen, in dem die LLM bei Bedarf bestimmte APIs dynamisch aufrufen kann.
Entwicklungsleitfaden
-
Eingabeaufforderungen und Tools
- Halten Sie Aufforderungen klar und minimal, um widersprüchliche Anweisungen, ablenkende Informationen zu vermeiden und Halluzinationen zu reduzieren.
- Stellen Sie nur die Tools und den Kontext bereit, die Ihr Agent benötigt, anstatt einen ungebundenen Satz von APIs oder einen großen irrelevanten Kontext. Wählen Sie ihren Toolansatz während des Entwurfs aus.
-
Protokollierung und Observierbarkeit
- Implementieren Sie detailliertes Logging für jede Benutzeranforderung, jeden Agentenplan und jeden Toolaufruf mithilfe der MLflow-Ablaufverfolgung.
- Speichern Sie Protokolle sicher und achten Sie auf personenbezogene Informationen (PII) in Unterhaltungsdaten. Betrachten Sie die Datenklassifizierung für die Automatisierung.
Leitfaden zu Tests und Iterationen
-
Auswertung
- Verwenden Sie die MLflow-Auswertung und Produktionsüberwachung , um Auswertungsmetriken für Entwicklung und Produktion zu definieren.
- Sammeln Sie menschliches Feedback von Experten und Benutzern, um sicherzustellen, dass Ihre automatisierten Auswertungsmetriken gut kalibriert sind.
-
Fehlerbehandlung und Fallbacklogik
- Planen Sie Werkzeug- oder LLM-Fehler ein. Timeouts, falsch formatierte Antworten oder leere Ergebnisse können einen Workflow unterbrechen. Fügen Sie Wiederholungsstrategien, Fallbacklogik oder eine einfachere Fallbackkette ein, wenn erweiterte Features fehlschlagen.
-
Iterative Verbesserungen
- Erwarten Sie, die Aufforderungen und die Agentlogik im Laufe der Zeit zu verfeinern. Änderungen der Versionen mit der MLflow Prompt-Registry für Ihre Eingabeaufforderungen und MLflow-App-Versionenverfolgung für Ihre Apps. Die Versionsverwaltung vereinfacht Vorgänge und ermöglicht Rollbacks und Vergleiche.
- Wenn Sie Auswertungsdaten sammeln und Metriken definieren, sollten Sie automatisierte Optimierungsmethoden wie die Optimierung von MLflow-Eingabeaufforderungen in Betracht ziehen.
Produktionsleitfaden
-
Modell-Updates und Versionsfestlegung
- LLM-Verhaltensweisen können sich verschieben, wenn Anbieter Modelle hinter den Kulissen aktualisieren. Verwenden Sie Versionsfixierung und häufige Regressionstests, um sicherzustellen, dass die Agentlogik robust und stabil bleibt.
-
Latenz und Kostenoptimierung
- Jeder zusätzliche LLM- oder Toolaufruf erhöht den Tokenverbrauch und die Reaktionszeit. Kombinieren Sie nach Möglichkeit Schritte oder zwischenspeichern Sie wiederholte Abfragen, um die Leistung und Kosten überschaubar zu halten.
-
Sicherheit und Sandboxing
- Wenn Ihr Agent Datensätze aktualisieren oder Code ausführen kann, isolieren Sie diese Aktionen oder erzwingen Sie, falls erforderlich, eine menschliche Genehmigung. Dies ist in Unternehmens- oder regulierten Umgebungen wichtig, um unbeabsichtigte Schäden zu vermeiden. Unity Catalog-Funktionen bieten Sandkastenausführung für die Produktion.
- Weitere Anleitungen zu Tooloptionen finden Sie unter KI-Agent-Tools .
Anhand dieser Richtlinien können Sie viele der am häufigsten auftretenden Fehlermodi wie z. B. Fehlaufrufe von Tools, Verschlechterung der LLM-Leistung oder unerwartete Kostenspitzen mindern und zuverlässigere, skalierbare Agent-Systeme erstellen.