Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Erstellen und bereitstellen Sie Ihren ersten KI-Agent mithilfe von Databricks-Apps-Vorlagen. In diesem Tutorial führen Sie Folgendes durch:
- Erstellen und Bereitstellen eines Agents aus der Benutzeroberfläche von Databricks-Apps.
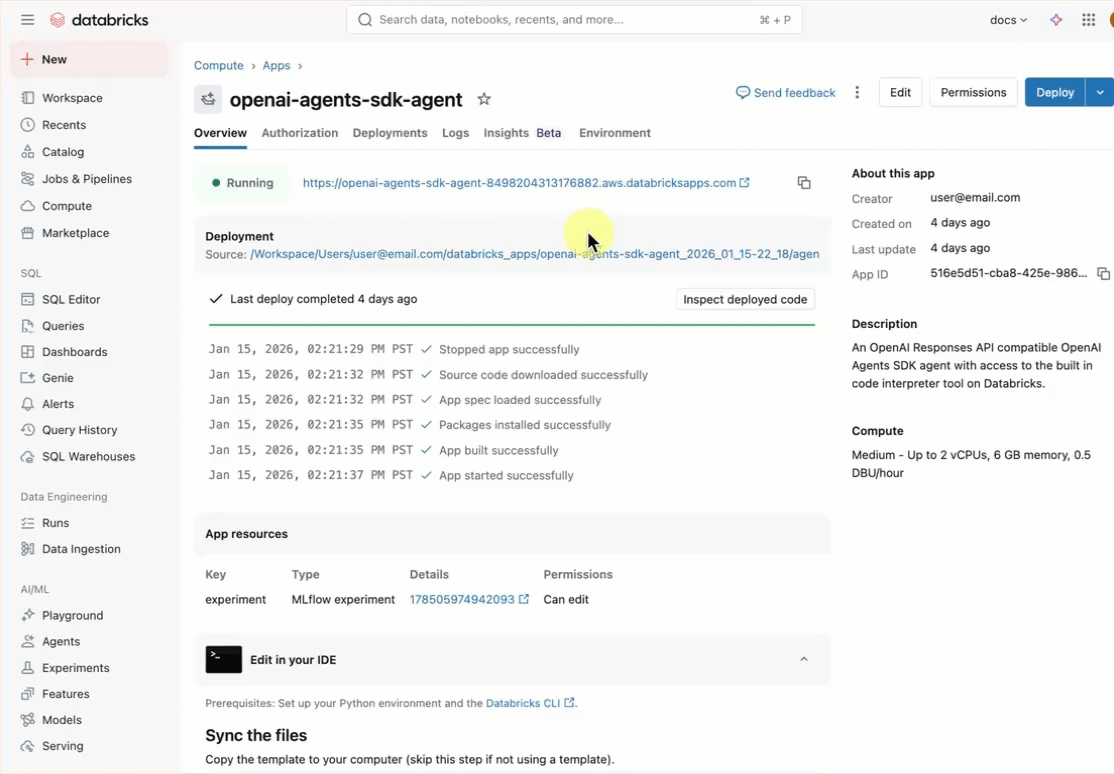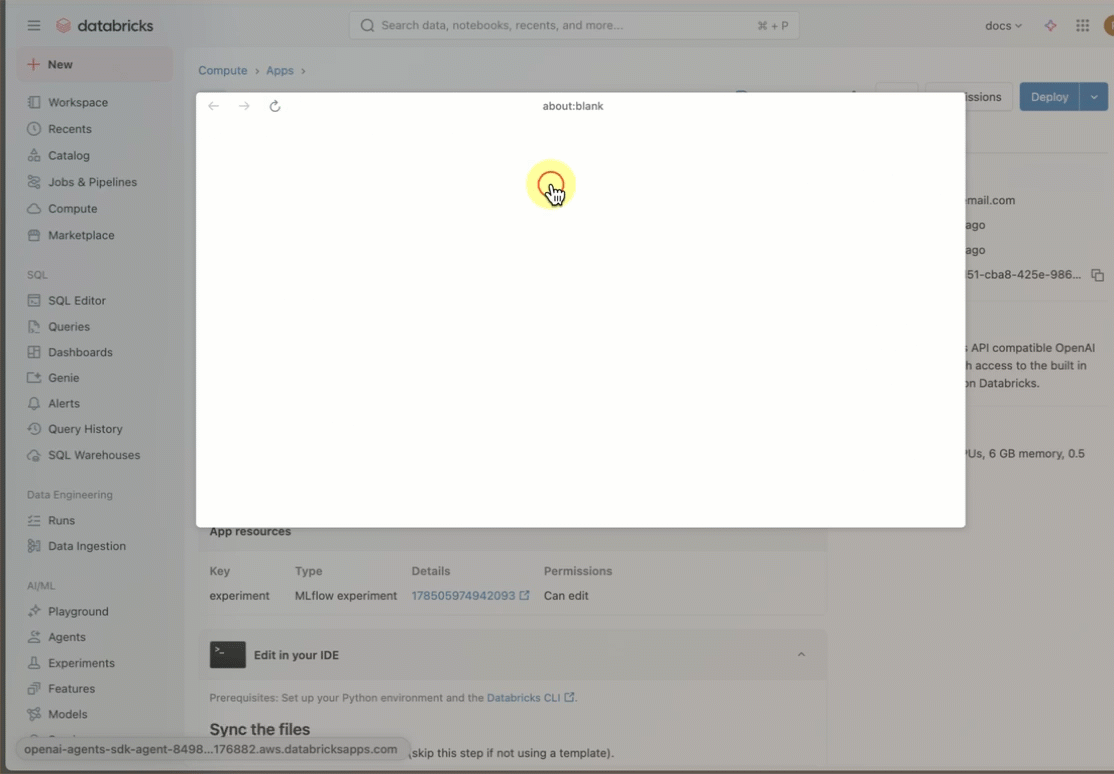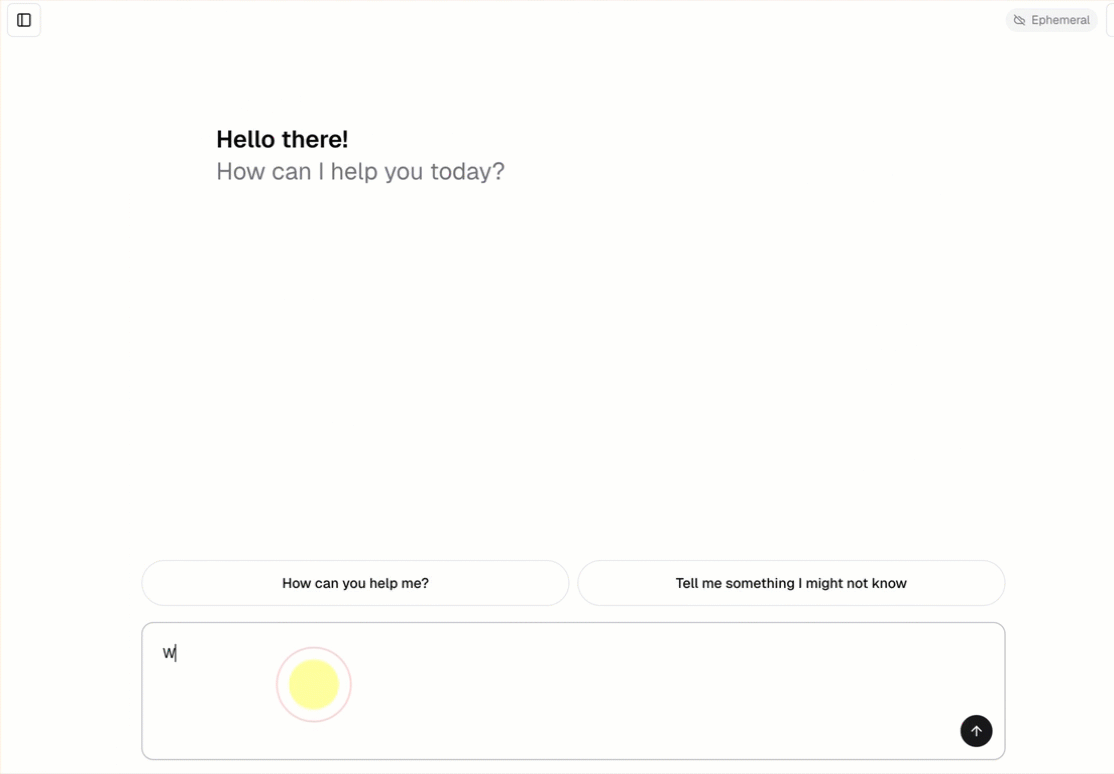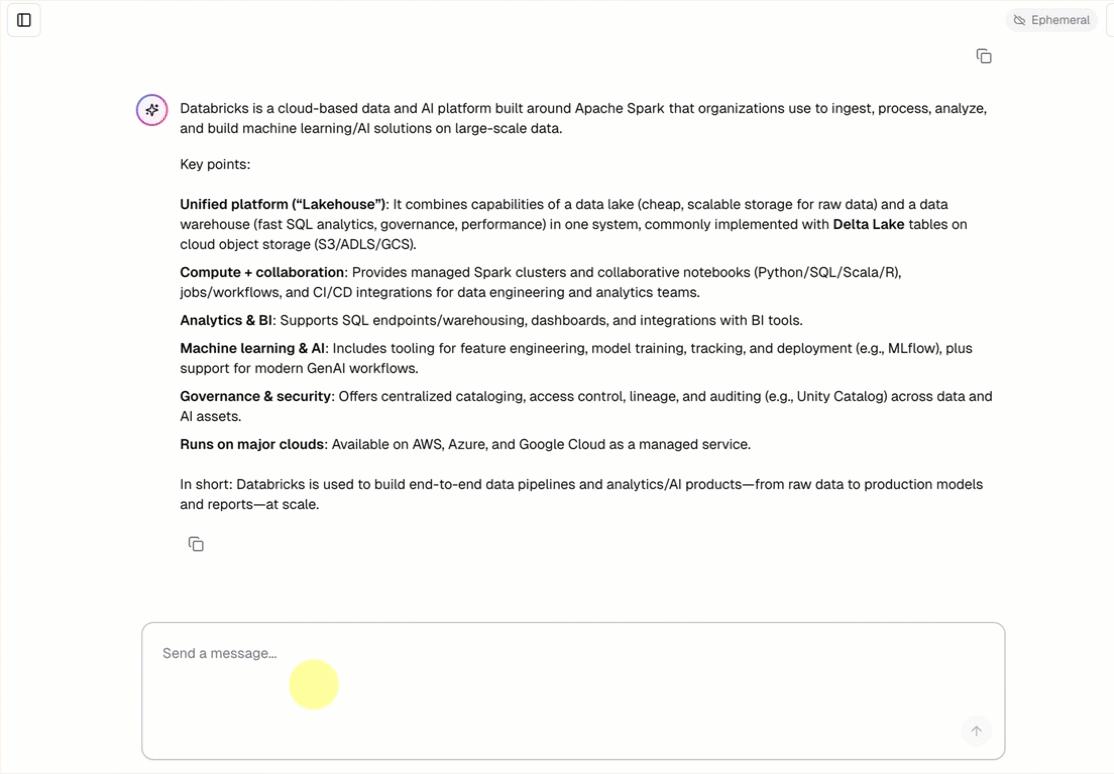
- Chatten Sie mit dem Agent über eine vordefinierte Chatschnittstelle.
Voraussetzungen
Aktivieren Sie Databricks-Apps in Ihrem Arbeitsbereich. Weitere Informationen finden Sie unter Einrichten ihres Databricks-Apps-Arbeitsbereichs und ihrer Entwicklungsumgebung.
Bereitstellen der Agentvorlage
Beginnen Sie, indem Sie eine vorgefertigte Agent-Vorlage aus dem Databricks-App-Vorlagen-Repository verwenden.
In diesem Lernprogramm wird die agent-openai-agents-sdk Vorlage verwendet, die Folgendes umfasst:
- Ein Agent, der mit dem OpenAI Agent SDK erstellt wurde
- Startcode für eine Agenten-Anwendung mit einer Konversations-REST-API und einer interaktiven Chat-Benutzeroberfläche
- Code zum Auswerten des Agents mithilfe von MLflow
Installieren Sie die App-Vorlage mithilfe der Arbeitsbereichs-Benutzeroberfläche. Dadurch wird die App installiert und auf einer Rechenressource in Ihrem Arbeitsbereich bereitgestellt.
Klicken Sie in Ihrem Databricks-Arbeitsbereich auf +Neue>App.
Klicken Sie auf Agents Agent>– OpenAI Agents SDK.
Erstellen Sie ein neues MLflow-Experiment mit dem Namen
openai-agents-template, und schließen Sie den Rest der Einrichtung ab, um die Vorlage zu installieren.Nachdem Sie die App erstellt haben, klicken Sie auf die App-URL, um die Chat-UI zu öffnen.
Grundlegendes zur Agentanwendung
Die Agentvorlage veranschaulicht eine produktionsbereite Architektur mit den folgenden Schlüsselkomponenten:
MLflow-AgentServer: Ein asynchroner FastAPI-Server, der Agentanforderungen mit integrierter Ablaufverfolgung und Observierbarkeit verarbeitet. Der AgentServer stellt den /invocations Endpunkt zum Abfragen Ihres Agents bereit und verwaltet automatisch das Anforderungsrouting, die Protokollierung und die Fehlerbehandlung.
OpenAI Agents SDK: Die Vorlage verwendet das OpenAI Agents SDK als Agent-Framework für Gesprächsmanagement und Tool-Orchestrierung. Sie können Agents mithilfe eines beliebigen Frameworks erstellen. Der Schlüssel liegt darin, Ihren Agenten mit der MLflow-Schnittstelle ResponsesAgent zu umwickeln.
ResponsesAgent Schnittstelle: Diese Schnittstelle stellt sicher, dass Ihr Agent über verschiedene Frameworks hinweg funktioniert und mit Databricks-Tools integriert wird. Erstellen Sie Ihren Agenten mithilfe von OpenAI SDK, LangGraph, LangChain oder reinem Python, und binden Sie es dann mit ResponsesAgent ein, um die automatische Kompatibilität mit AI Playground, Agentenevaluierung und Databricks-Apps-Deployment zu erhalten.
MCP-Server (Model Context Protocol): Die Vorlage stellt eine Verbindung mit Databricks MCP-Servern her, um auf Agents für Tools und Datenquellen zuzugreifen. Siehe Model Context Protocol (MCP) für Databricks.

Nächste Schritte
Erfahren Sie, wie Sie einen benutzerdefinierten Agent erstellen:Erstellen eines KI-Agents und Bereitstellen auf Databricks-Apps