Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Auf dieser Seite werden die Standardconnectors in Databricks Lakeflow Connect beschrieben, die im Vergleich zu den verwalteten Connectors höhere Anpassungsebenen für die Aufnahmepipeline bieten.
Ebenen des ETL-Stapels
Einige Verbinder arbeiten auf einer Ebene des ETL-Stapels. Beispielsweise bietet Databricks vollständig verwaltete Connectors für Unternehmensanwendungen wie Salesforce und Datenbanken wie SQL Server. Andere Verbinder funktionieren auf mehreren Ebenen des ETL-Stapels. Sie können z. B. Standardconnectors entweder in Structured Streaming für eine umfassende Anpassung oder Lakeflow Spark Declarative Pipelines für ein besser verwaltetes Erlebnis verwenden.
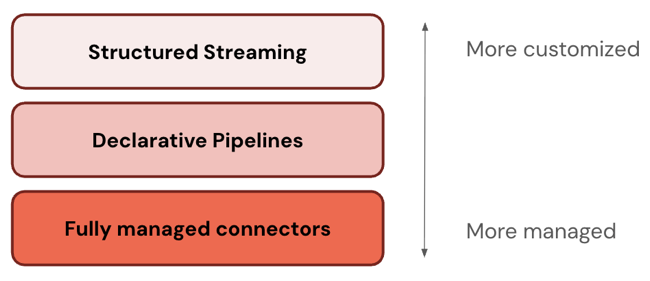
Databricks empfiehlt, mit der am häufigsten verwalteten Ebene zu beginnen. Wenn dies Ihre Anforderungen nicht erfüllt (z. B. wenn Ihre Datenquelle nicht unterstützt wird), gehen Sie zur nächsten Ebene.
In der folgenden Tabelle werden die drei Ebenen der Aufnahmeprodukte beschrieben, sortiert von den meisten anpassbaren bis zu den meisten verwalteten Produkten:
| Ebene | BESCHREIBUNG |
|---|---|
| Strukturiertes Streaming | Apache Spark Structured Streaming ist eine Streaming-Engine, die End-to-End-Fehlertoleranz mit Garantien für genau eine Verarbeitung unter Verwendung von Spark-APIs bietet. |
| Lakeflow Spark Deklarative Datenpipelines | Lakeflow Spark Declarative Pipelines baut auf Structured Streaming auf und bietet ein deklaratives Framework zum Erstellen von Datenpipelines. Sie können die Transformationen definieren, die für Ihre Daten ausgeführt werden sollen, und Lakeflow Spark Declarative Pipelines verwaltet Orchestrierung, Überwachung, Datenqualität, Fehler und vieles mehr. Daher bietet es mehr Automatisierung und weniger Mehraufwand als strukturiertes Streaming. |
| Verwaltete Connectors | Vollständig verwaltete Connectors basieren auf Lakeflow Spark Declarative Pipelines und bieten noch mehr Automatisierung für die beliebtesten Datenquellen. Sie erweitern die Funktionen von Lakeflow Spark Declarative Pipelines, um auch quellspezifische Authentifizierung, CDC, Edge case Handling, langfristige API-Wartung, automatisierte Wiederholungen, automatisierte Schemaentwicklung usw. einzuschließen. Daher bieten sie noch mehr Automatisierung für alle unterstützten Datenquellen. |
Wählen Sie einen Anschluss
Die folgende Tabelle zeigt Standard-Ingestions-Connectors, geordnet nach Datenquelle und Grad der Anpassung der Pipeline. Verwenden Sie für ein vollständig automatisiertes Erfassungserlebnis stattdessen verwaltete Connectors.
SQL-Beispiele für die inkrementelle Erfassung von Cloudobjektspeichern verwenden CREATE STREAMING TABLE Syntax. Es bietet SQL-Benutzern eine skalierbare und robuste Aufnahmeerfahrung, daher ist es die empfohlene Alternative zu COPY INTO.
| Quelle | Weitere Anpassungen | Einige Anpassungen | Mehr Automatisierung |
|---|---|---|---|
| Cloudobjektspeicher |
Automatisches Laden mit strukturiertem Streaming (Python, Scala) |
Auto Loader mit Lakeflow Spark Declarative Pipelines (Python, SQL) |
Automatisches Laden mit Databricks SQL (SQL) |
| SFTP-Server |
Aufnehmen von Dateien von SFTP-Servern (Python, SQL) |
N/A | N/A |
| Apache Kafka |
Strukturiertes Streaming mit Kafka-Quelle (Python, Scala) |
Lakeflow Spark Declarative Pipelines mit Kafka-Quelle (Python, SQL) |
Databricks SQL mit Kafka-Quelle (SQL) |
| Google Pub/Sub (Nachrichtendienst) |
Strukturiertes Streaming mit Pub/Sub-Quelle (Python, Scala) |
Lakeflow Spark Declarative Pipelines Mit Pub/Sub-Quelle (Python, SQL) |
Databricks SQL mit Pub/Sub-Quelle (SQL) |
| Apache Pulsar |
Strukturiertes Streaming mit Pulsar-Quelle (Python, Scala) |
Lakeflow Spark Deklarative Pipelines mit Pulsar-Quelle (Python, SQL) |
Databricks SQL mit Pulsar-Quelle (SQL) |
Erfassungszeitpläne
Sie können Aufnahmepipelines so konfigurieren, dass sie in einem wiederkehrenden Zeitplan oder kontinuierlich ausgeführt werden.
| Anwendungsfall | Pipelinemodus |
|---|---|
| Batcherfassung | Ausgelöst: Verarbeitet neue Daten gemäß einem Zeitplan oder bei manueller Auslösung. |
| Streamingerfassung | Fortlaufend: Verarbeitet neue Daten, sobald sie in der Quelle eintreffen. |