Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Leitprinzipien sind Regeln der Ebene null, die Ihre Architektur definieren und beeinflussen. Um ein Datenseehaus zu erstellen, das Ihrem Unternehmen jetzt und in Zukunft hilft, ist ein Konsens zwischen den Projektbeteiligten in Ihrer Organisation wichtig.
Zusammenstellen von Daten und Anbieten vertrauenswürdiger Daten als Produkte
Das Zusammenstellen von Daten ist für die Erstellung eines hochwertigen Datensees für BI und ML/AI unerlässlich. Behandeln Sie Daten wie ein Produkt mit einer klaren Definition, einem Schema und einem Lebenszyklus. Stellen Sie die semantische Konsistenz sicher, und dass sich die Datenqualität von Ebene zu Schicht verbessert, damit Geschäftsbenutzer den Daten vollständig vertrauen können.
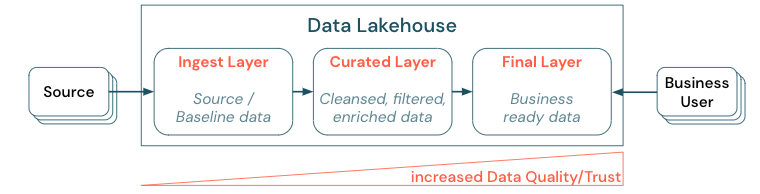
Das Zusammenstellen von Daten durch die Schaffung einer mehrschichtigen Multi-Hop-Architektur ist eine zentrale bewährte Methode für das Lakehouse, da Datenteams die Daten nach Qualitätsstufen ordnen und Rollen sowie Verantwortlichkeiten pro Ebene definieren können. Ein gängiger Ansatz für Ebenen ist:
- Aufnahmeschicht: Quelldaten werden in das Seehaus in die erste Schicht aufgenommen und sollten dort beibehalten werden. Wenn alle nachgelagerten Daten aus der Ingest-Ebene erstellt werden, ist bei Bedarf der Neuaufbau der folgenden Ebenen aus dieser Ebene möglich.
- Kuratierte Ebene: Der Zweck der zweiten Ebene besteht darin, bereinigte, verfeinerte, gefilterte und aggregierte Daten zu halten. Ziel dieser Ebene ist es, eine solide, zuverlässige Grundlage für Analysen und Berichte in allen Rollen und Funktionen bereitzustellen.
- Letzte Ebene: Die dritte Ebene wird für geschäfts- oder projektspezifische Anforderungen erstellt; sie bietet eine andere Ansicht als Datenprodukte für andere Geschäftseinheiten oder Projekte, die Vorbereitung von Daten auf Sicherheitsanforderungen (z. B. anonymisierte Daten) oder die Optimierung der Leistung (mit voraggregatierten Ansichten). Die Datenprodukte in dieser Ebene werden als Wahrheit für das Unternehmen angesehen.
Pipelines über alle Ebenen hinweg müssen sicherstellen, dass Datenqualitätseinschränkungen erfüllt sind, was bedeutet, dass Daten immer genau, vollständig, zugänglich und konsistent sind, auch während gleichzeitigen Lese- und Schreibvorgängen. Die Validierung neuer Daten erfolgt zum Zeitpunkt der Dateneingabe in die kuratierte Ebene, und die folgenden ETL-Schritte funktionieren, um die Qualität dieser Daten zu verbessern. Die Datenqualität muss verbessert werden, wenn daten durch die Ebenen vorankommen, und das Vertrauen in die Daten steigt dann aus geschäftlicher Sicht.
Entfernen von Datensilos und Minimieren der Datenverschiebung
Erstellen Sie keine Kopien eines Datasets mit Geschäftsprozessen, die auf diesen verschiedenen Kopien basieren. Kopien können Datensilos werden, die nicht mehr synchronisiert werden, was zu einer geringeren Qualität Ihres Datensees und schließlich zu veralteten oder falschen Erkenntnissen führt. Verwenden Sie zusätzlich zum Freigeben von Daten für externe Partner unternehmensweite Freigabemechanismen, die einen sicheren direkten Zugriff auf die Daten ermöglichen.
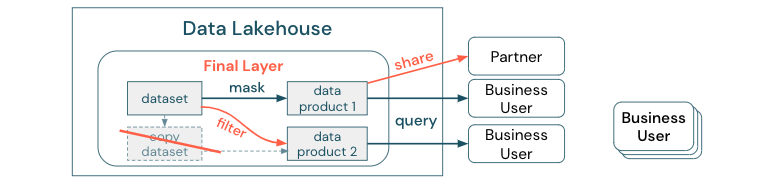
Um den Unterschied zwischen einer Datenkopie und einem Datensilos klar zu machen: Eine eigenständige oder ausgeworfene Kopie von Daten ist allein nicht schädlich. Es ist manchmal notwendig, Flexibilität, Experimentierung und Innovation zu steigern. Wenn diese Kopien jedoch mit nachgelagerten Geschäftsdatenprodukten betriebsbereit werden, werden sie zu Datensilos.
Um Datensilos zu verhindern, versuchen Datenteams in der Regel, einen Mechanismus oder eine Datenpipeline zu erstellen, um alle Kopien mit dem Original synchron zu halten. Da es unwahrscheinlich ist, dass dies konsistent geschieht, verschlechtert sich die Datenqualität letztendlich. Dies kann auch zu höheren Kosten und einem erheblichen Verlust der Benutzervertrauensstellung führen. Andererseits benötigen mehrere geschäftliche Anwendungsfälle den Datenaustausch mit Partnern oder Lieferanten.
Ein wichtiger Aspekt ist die sichere und zuverlässige Freigabe der neuesten Version des Datasets. Kopien des Datasets sind häufig nicht ausreichend, da sie schnell aus der Synchronisierung herauskommen können. Stattdessen sollten Daten über Unternehmensdatenfreigabetools freigegeben werden.
Demokratisierung der Wertschöpfung durch Self-Service
Der beste Data Lake kann keinen ausreichenden Nutzen bieten, wenn Benutzer nicht einfach auf die Plattform oder Daten für ihre BI- und ML/AI-Aufgaben zugreifen können. Verringern Sie die Barrieren für den Zugriff auf Daten und Plattformen für alle Geschäftseinheiten. Berücksichtigen Sie schlanke Datenverwaltungsprozesse und bieten Self-Service-Zugriff für die Plattform und die zugrunde liegenden Daten.
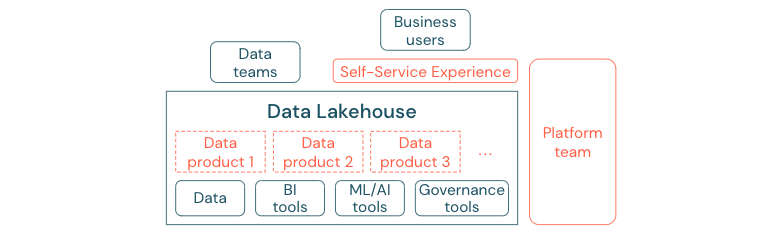
Unternehmen, die erfolgreich in eine datengesteuerte Kultur umgezogen sind, werden gedeihen. Dies bedeutet, dass jede Geschäftseinheit ihre Entscheidungen aus analytischen Modellen oder aus der Analyse eigener oder zentral bereitgestellter Daten ableiten kann. Für Verbraucher müssen Daten leicht auffindbar und sicher zugänglich sein.
Ein gutes Konzept für Datenhersteller ist "Daten als Produkt": Die Daten werden von einer Geschäftseinheit oder einem Geschäftspartner wie einem Produkt angeboten und verwaltet und von anderen Parteien mit ordnungsgemäßer Berechtigungskontrolle genutzt. Anstatt sich auf ein zentrales Team und potenziell langsame Anforderungsprozesse zu verlassen, müssen diese Datenprodukte erstellt, angeboten, entdeckt und in einer Self-Service-Erfahrung genutzt werden.
Es sind jedoch nicht nur die Daten, die wichtig sind. Die Demokratisierung von Daten erfordert die richtigen Tools, mit denen jeder die Daten produzieren oder nutzen und verstehen kann. Dazu benötigen Sie das Data Lakehouse als moderne Daten- und KI-Plattform, die die Infrastruktur und Tools zum Erstellen von Datenprodukten bereitstellt, ohne den Aufwand für die Einrichtung eines anderen Toolstapels zu duplizieren.
Einführung einer organisationsweiten Daten- und KI-Governancestrategie
Daten sind eine wichtige Ressource jeder Organisation, aber Sie können nicht jedem Zugriff auf alle Daten gewähren. Der Datenzugriff muss aktiv verwaltet werden. Zugriffskontrolle, Überwachung und Herkunftsverfolgung sind entscheidend für die korrekte und sichere Verwendung von Daten.
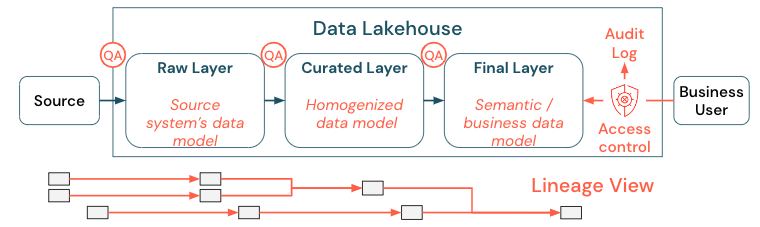
Die Datenverwaltung ist ein breites Thema. Das Seehaus deckt die folgenden Dimensionen ab:
Datenqualität
Die wichtigste Voraussetzung für korrekte und aussagekräftige Berichte, Analyseergebnisse und Modelle sind qualitativ hochwertige Daten. Qualitätssicherung (Quality Assurance, QA) muss um alle Pipelineschritte herum bestehen. Beispiele für die Implementierung sind Datenverträge, das Einhalten von SLAs, das Sicherstellen stabiler Schemata und deren kontrollierte Weiterentwicklung.
Datenkatalog
Ein weiterer wichtiger Aspekt ist die Datenermittlung: Benutzer aller Geschäftsbereiche, insbesondere in einem Self-Service-Modell, müssen in der Lage sein, relevante Daten einfach zu ermitteln. Daher benötigt ein Lakehouse einen Datenkatalog, der alle geschäftsrelevanten Daten abdeckt. Die primären Ziele eines Datenkatalogs sind wie folgt:
- Stellen Sie sicher, dass dasselbe Geschäftskonzept einheitlich aufgerufen und im gesamten Unternehmen deklariert wird. Sie können sich dies als semantisches Modell in der kuratierten und der endgültigen Ebene vorstellen.
- Verfolgen Sie die Datenherkunft genau, damit Benutzer erklären können, wie diese Daten ihre aktuelle Gestalt und Form angenommen haben.
- Bewahren Sie qualitativ hochwertige Metadaten auf, was ebenso wichtig ist wie die Daten selbst für die ordnungsgemäße Verwendung der Daten.
Zugriffskontrolle
Da die Wertschöpfung aus den Daten im Lakehouse über alle Geschäftsbereiche hinweg erfolgt, muss das Lakehouse mit Sicherheit als vorrangige Priorität aufgebaut werden. Unternehmen haben möglicherweise eine offenere Datenzugriffsrichtlinie oder folgen streng dem Prinzip der geringsten Rechte. Unabhängig davon müssen Datenzugriffssteuerelemente in jeder Ebene vorhanden sein. Es ist wichtig, feingranulare Berechtigungsschemata von Anfang an zu implementieren (Zugriffssteuerung auf Spalten- und Zeilenebene, rollenbasierte oder attributbasierte Zugriffssteuerung). Unternehmen können mit weniger strengen Regeln beginnen. Aber da die Seehausplattform wächst, sollten alle Mechanismen und Prozesse für ein komplexeres Sicherheitssystem bereits vorhanden sein. Darüber hinaus müssen alle Zugriffe auf die Daten im Lakehouse von Anfang an durch Audit-Logs gesteuert werden.
Fördern von offenen Schnittstellen und offenen Formaten
Offene Schnittstellen und Datenformate sind entscheidend für die Interoperabilität zwischen dem Lakehouse und anderen Tools. Es vereinfacht die Integration mit bestehenden Systemen und eröffnet auch ein Ökosystem von Partnern, die ihre Tools in die Plattform integriert haben.
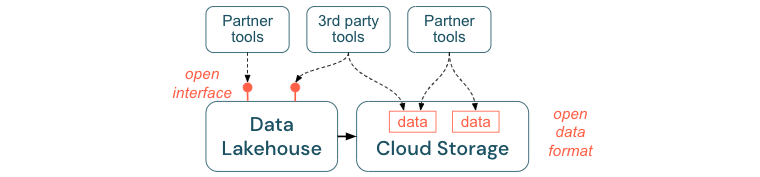
Offene Schnittstellen sind wichtig, um die Interoperabilität zu ermöglichen und abhängigkeiten von jedem einzelnen Anbieter zu verhindern. Traditionell haben Anbieter proprietäre Technologien und geschlossene Schnittstellen entwickelt, die Unternehmen in der Art und Weise einschränkten, wie sie Daten speichern, verarbeiten und teilen konnten.
Durch den Aufbau auf offenen Schnittstellen bauen Sie für die Zukunft.
- Es erhöht die Langlebigkeit und Portabilität der Daten, damit Sie sie mit mehr Anwendungen und für mehr Anwendungsfälle verwenden können.
- Es eröffnet ein Ökosystem von Partnern, die die offenen Schnittstellen schnell nutzen können, um ihre Werkzeuge in die Seehausplattform zu integrieren.
Schließlich werden die Gesamtkosten durch die Standardisierung offener Formate für Daten deutlich niedriger sein; man kann direkt auf die Daten im Cloudspeicher zugreifen, ohne dass sie über eine proprietäre Plattform weitergeleitet werden müssen, die hohe Ausgangs- und Berechnungskosten verursachen kann.
Bauen zum Skalieren und Optimieren von Leistung und Kosten
Daten wachsen zwangsläufig weiter und werden komplexer. Um Ihre Organisation für zukünftige Anforderungen auszustatten, sollte Ihr Seehaus in der Lage sein, skalieren zu können. Beispielsweise sollten Sie in der Lage sein, neue Ressourcen bei Bedarf einfach hinzuzufügen. Die Kosten sollten auf den tatsächlichen Verbrauch beschränkt werden.
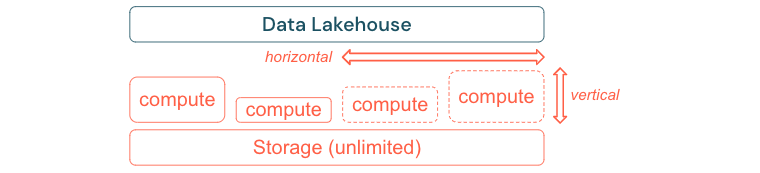
Standardmäßige ETL-Prozesse, Geschäftsberichte und Dashboards verfügen häufig über einen vorhersehbaren Ressourcenbedarf aus Speicher- und Berechnungsperspektive. Neue Projekte, saisonbedingte Vorgänge oder moderne Ansätze wie Modellschulungen (Churn, Prognose, Wartung) erzeugen jedoch Spitzen des Ressourcenbedarfs. Damit ein Unternehmen all diese Workloads ausführen kann, ist eine skalierbare Plattform für Arbeitsspeicher und Berechnung erforderlich. Neue Ressourcen müssen bei Bedarf problemlos hinzugefügt werden, und nur der tatsächliche Verbrauch sollte Kosten generieren. Sobald der Höchststand vorbei ist, können Ressourcen wieder freigegeben und die Kosten entsprechend reduziert werden. Häufig wird dies als horizontale Skalierung (weniger oder mehr Knoten) und vertikale Skalierung (größere oder kleinere Knoten) bezeichnet.
Durch die Skalierung können Unternehmen auch die Leistung von Abfragen verbessern, indem Knoten mit mehr Ressourcen oder Clustern mit mehr Knoten ausgewählt werden. Statt jedoch dauerhaft große Maschinen und Cluster bereitzustellen, können sie nur für die Zeit bereitgestellt werden, die erforderlich ist, um das Gesamtleistungs-zu-Kosten-Verhältnis zu optimieren. Ein weiterer Aspekt der Optimierung ist Speicher im Vergleich zu Computeressourcen. Da es keine klare Beziehung zwischen dem Volumen der Daten und den Workloads gibt, die diese Daten verwenden (z. B. nur Teile der Daten nutzen oder intensive Berechnungen auf kleinen Datenmengen durchführen), ist es ratsam, sich für eine Infrastrukturplattform zu entscheiden, die Speicher- und Rechenressourcen voneinander entkoppelt.