Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Wichtig
Dieses Feature ist in den folgenden Regionen als Public Preview verfügbar: centralus, eastus, eastus2, northcentralus und westus.
In diesem Artikel wird beschrieben, wie Sie einen Schulungslauf mithilfe der Foundation Model Fine-Tuning-API (jetzt Teil der Mosaik AI Model Training)-API erstellen und konfigurieren und alle parameter beschreiben, die im API-Aufruf verwendet werden. Sie können eine Ausführung auch mithilfe der Benutzeroberfläche erstellen. Anweisungen finden Sie unter Erstellen einer Schulungsausführung mithilfe der Foundation Model Fine-Tuning UI.
Anforderungen
Siehe Anforderungen.
Erstellen einer Trainingsausführung
Zum programmgesteuerten Erstellen von Trainingsausführungen verwenden Sie die create()-Funktion. Diese Funktion trainiert ein Modell für das bereitgestellte Dataset und speichert das trainierte Modell zur Ableitung.
Die erforderlichen Eingaben sind das Modell, das Sie trainieren möchten, der Speicherort Ihres Trainingsdatasets und wo Sie Ihr Modell registrieren möchten. Es gibt auch optionale Parameter, mit denen Sie die Auswertung durchführen und die Hyperparameter Ihrer Ausführung ändern können.
Nach Abschluss der Ausführung werden die abgeschlossenen Ausführungen und die abschließenden Prüfpunkte gespeichert, das Modell wird geklont, und der Klon wird in Unity Catalog als Modellversion für den Rückschluss registriert.
Das Modell aus der abgeschlossenen Ausführung, nicht die geklonte Modellversion im Unity-Katalog, wird in MLflow gespeichert. Die Prüfpunkte können für fortgesetzte Feinabstimmungsaufgaben verwendet werden.
Weitere Informationen zu Argumenten für die -Funktion finden Sie unter create().
from databricks.model_training import foundation_model as fm
run = fm.create(
model='meta-llama/Llama-3.2-3B-Instruct',
train_data_path='dbfs:/Volumes/main/mydirectory/ift/train.jsonl', # UC Volume with JSONL formatted data
# Public HF dataset is also supported
# train_data_path='mosaicml/dolly_hhrlhf/train'
register_to='main.mydirectory', # UC catalog and schema to register the model to
)
Konfigurieren einer Trainingsausführung
In der folgenden Tabelle sind die Parameter für die foundation_model.create() Funktion zusammengefasst.
| Parameter | Erforderlich | Typ | Beschreibung des Dataflows |
|---|---|---|---|
model |
x | Str | Der Name des zu verwendenden Modells. Weitere Informationen finden Sie unter Unterstützte Modelle. |
train_data_path |
x | Str | Der Speicherort Ihrer Trainingsdaten. Dies kann ein Speicherort in Unity Catalog (<catalog>.<schema>.<table> oder dbfs:/Volumes/<catalog>/<schema>/<volume>/<dataset>.jsonl) oder ein Hugging Face-Dataset sein.Für INSTRUCTION_FINETUNE sollten die Daten mit jeder Zeile formatiert sein, die ein prompt-Feld und ein response-Feld enthält.Für CONTINUED_PRETRAIN ist dies ein Ordner mit .txt-Dateien. Weitere Informationen finden Sie unter Vorbereiten von Daten für foundation Model Fine-Tuning für akzeptierte Datenformate und empfohlene Datengröße für Modellschulungen für Empfehlungen zur Datengröße. |
register_to |
x | Str | Der Katalog und das Schema von Unity Catalog (<catalog>.<schema> oder <catalog>.<schema>.<custom-name>), in dem das Modell nach dem Training registriert wird, um eine einfache Bereitstellung zu ermöglichen. Wenn custom-name nicht angegeben wird, ist der Standardwert der Ausführungsname. |
data_prep_cluster_id |
Str | Die Cluster-ID des Clusters, der für die Spark-Datenverarbeitung verwendet werden soll. Dies ist für Schulungsaufgaben erforderlich, bei denen sich die Schulungsdaten in einer Delta-Tabelle befinden. Informationen zum Ermitteln der Cluster-ID finden Sie unter Abrufen der Cluster-ID. | |
experiment_path |
Str | Der Pfad zu dem MLflow-Experiment, in dem die Ausgabe der Trainingsausführung (Metriken und Prüfpunkte) gespeichert wird. Standardmäßig wird der Ausführungsname innerhalb des persönlichen Arbeitsbereichs des Benutzers verwendet, also /Users/<username>/<run_name>. |
|
task_type |
Str | Der Typ der auszuführenden Aufgabe. Kann CHAT_COMPLETION (Standard) CONTINUED_PRETRAIN oder INSTRUCTION_FINETUNE lauten. |
|
eval_data_path |
Str | Der Remotestandort Ihrer Auswertungsdaten (sofern vorhanden). Das Format muss train_data_path entsprechen. |
|
eval_prompts |
List[str] | Eine Liste der Promptzeichenfolgen zum Generieren von Antworten während der Auswertung. Der Standardwert ist None (keine Prompts generieren). Die Ergebnisse werden bei jeder Prüfpunkterstellung für das Modell im Experiment protokolliert. Die Generierung erfolgt bei jedem Modellprüfpunkt mit den folgenden Generationparametern: max_new_tokens: 100, temperature: 1, top_k: 50, top_p: 0.95, do_sample: true. |
|
custom_weights_path |
Str | Der Remotestandort eines benutzerdefinierten Modellprüfpunkts für das Training. Der Standardwert ist None, d. h., die Ausführung beginnt mit den ursprünglichen vortrainierten Gewichtung des ausgewählten Modells. Wenn Sie benutzerdefinierte Gewichtungen bereitstellen, werden diese anstelle der ursprünglichen vortrainierten Gewichtungen des Modells verwendet. Diese Gewichte müssen von der Feinabstimmungs-API erstellt worden sein und der Architektur des angegebenen model entsprechen. Weitere Informationen finden Sie unter "Erstellen von benutzerdefinierten Modellgewichtungen".HINWEIS: Wenn Sie ein Modell vor dem 26.03.2025 trainiert haben, können Sie von diesen Modell-Checkpoints nicht mehr weiter trainieren. Alle zuvor abgeschlossenen Schulungsläufe können weiterhin ohne Probleme mit bereitgestelltem Durchsatz genutzt werden. |
|
training_duration |
Str | Die Gesamtdauer der Ausführung. Der Standardwert ist eine Epoche oder 1ep. Kann in Epochen (10ep) oder Token (1000000tok) angegeben werden. |
|
learning_rate |
Str | Die Lernrate für das Modelltraining. Alle Modelle werden mit dem AdamW-Optimierer trainiert, wobei die Lernrate zunächst hochgefahren wird. Die Standardlernrate kann je nach Modell variieren. Wir empfehlen, eine Hyperparameter-Optimierung durchzuführen, um verschiedene Lernraten und Trainingsdauern zu testen, um Modelle von höchster Qualität zu erhalten. | |
context_length |
Str | Die maximale Sequenzlänge einer Datenstichprobe. Dieser Wert wird verwendet, um alle Daten zu kürzen, die zu lang sind, und um kürzere Sequenzen aus Effizienzgründen zusammenzupacken. Der Standardwert ist 8192 Token oder die maximale Kontextlänge für das bereitgestellte Modell, je nachdem, welcher Wert niedriger ist. Sie können diesen Parameter verwenden, um die Kontextlänge zu konfigurieren, aber die Konfiguration über die maximale Kontextlänge jedes Modells hinaus wird nicht unterstützt. Unter Unterstützte Modelle finden Sie die maximale unterstützte Kontextlänge jedes Modells. |
|
validate_inputs |
Boolescher Typ (Boolean) | Gibt an, ob der Zugriff auf Eingabepfade vor der Übermittlung des Trainingsauftrags überprüft werden soll. Der Standardwert ist True. |
Erstellen nach benutzerdefinierten Modellgewichtungen
HINWEIS: Wenn Sie ein Modell vor dem 26.03.2025 trainiert haben, können Sie von diesen Modell-Checkpoints nicht mehr weiter trainieren. Alle zuvor abgeschlossenen Schulungsläufe können weiterhin ohne Probleme mit bereitgestelltem Durchsatz genutzt werden.
Foundation Model Fine-Tuning unterstützt das Hinzufügen von benutzerdefinierten Gewichtungen mithilfe des optionalen Parameters custom_weights_path zum Trainieren und Anpassen eines Modells.
Legen Sie custom_weights_path zunächst den Prüfpunktpfad aus einer vorherigen Feinabstimmungs-API-Schulungsausführung fest. Prüfpunktpfade finden Sie auf der Registerkarte "Artefakte" einer vorherigen MLflow-Ausführung. Der Name des Prüfpunktordners entspricht dem Batch und der Epoche einer bestimmten Momentaufnahme, z ep29-ba30/. B. .

- Um den neuesten Prüfpunkt aus einer vorherigen Ausführung bereitzustellen, legen Sie
custom_weights_pathdiesen auf den Prüfpunkt fest, der von der Feinabstimmungs-API erstellt wurde. Beispiel:custom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/latest-sharded-rank0.symlink. - Um einen früheren Prüfpunkt bereitzustellen, legen Sie
custom_weights_patheinen Pfad zu einem Ordner fest, der Dateien enthält.distcp, die dem gewünschten Prüfpunkt entsprechen, zcustom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/ep#-ba#. B. .
Aktualisieren Sie als Nächstes den model Parameter so, dass er dem Basismodell des Prüfpunkts entspricht, an custom_weights_pathden Sie übergeben haben.
Im folgenden Beispiel ift-meta-llama-3-1-70b-instruct-ohugkq handelt es sich um eine vorherige Ausführung, die Feinmusik enthält meta-llama/Meta-Llama-3.1-70B. Um den neuesten Prüfpunkt ift-meta-llama-3-1-70b-instruct-ohugkqzu optimieren, legen Sie die model und custom_weights_path die Variablen wie folgt fest:
from databricks.model_training import foundation_model as fm
run = fm.create(
model = 'meta-llama/Meta-Llama-3.1-70B'
custom_weights_path = 'dbfs:/databricks/mlflow-tracking/2948323364469837/d4cd1fcac71b4fb4ae42878cb81d8def/artifacts/ift-meta-llama-3-1-70b-instruct-ohugkq/checkpoints/latest-sharded-rank0.symlink'
... ## other parameters for your fine-tuning run
)
Weitere Informationen finden Sie unter "Konfigurieren einer Schulungsausführung ", um andere Parameter in Ihrer Feinabstimmungsausführung zu konfigurieren.
Abrufen der Cluster-ID
So rufen Sie die Cluster-ID ab:
Wählen Sie auf der linken Navigationsleiste des Databricks-Arbeitsbereichs Compute aus.
Wählen Sie in der Tabelle den Namen Ihres Clusters aus.
Wählen Sie in der rechten oberen Ecke
 und dann im Dropdownmenü die Option JSON anzeigen aus.
und dann im Dropdownmenü die Option JSON anzeigen aus.Die JSON-Clusterdatei wird angezeigt. Kopieren Sie die Cluster-ID in der ersten Zeile in der Datei.
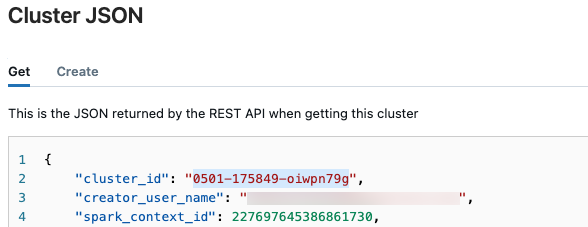
Abrufen des Status einer Ausführung
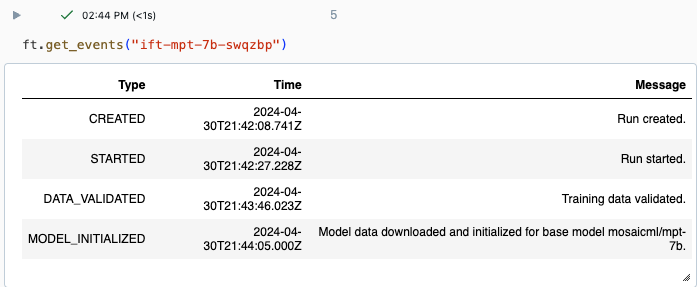
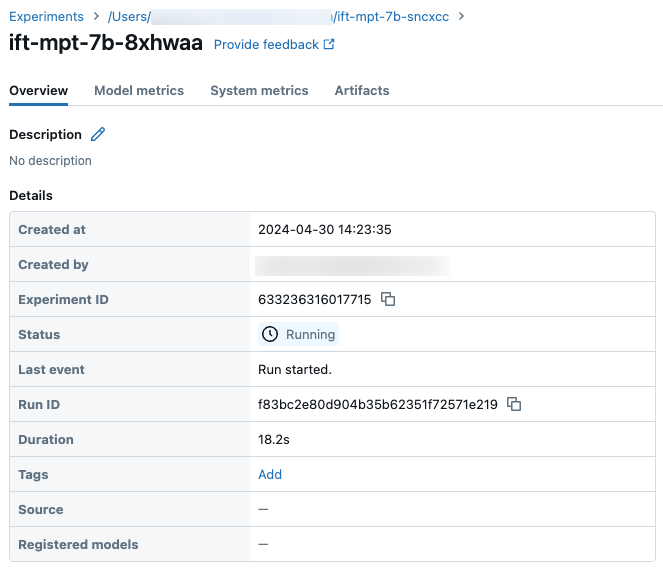
Sie können den Fortschritt einer Ausführung auf der Seite „Experiment“ der Databricks-Benutzeroberfläche oder mit dem API-Befehl get_events() nachverfolgen. Ausführliche Informationen finden Sie unter Anzeigen, Verwalten und Analysieren von Foundation Model Fine-Tuning-Ausführungen.
Beispielausgabe von get_events():
Beispielausführungsdetails auf der Seite „Experiment“:
Nächste Schritte
Nach Abschluss der Trainingsausführung können Sie Metriken in MLflow überprüfen und Ihr Modell für Rückschlüsse bereitstellen. Weitere Informationen finden Sie in den Schritten 5 bis 7 des Lernprogramms: Erstellen und Bereitstellen einer Feinabstimmung des Foundation-Modells.
Ein Beispiel finden Sie im Demo-Notebook für die Feinabstimmung von Instruktionen mit dem Titel Feinabstimmung von Instruktionen: Erkennung benannter Entitäten, das Sie durch die Datenvorbereitung, die Konfiguration des Feinabstimmungs-Trainingslaufs und die Bereitstellung führt.
Notebookbeispiel
Das folgende Notebook zeigt ein Beispiel für das Generieren synthetischer Daten mithilfe des Meta Llama 3.1 405B Instruct-Modells und das Verwenden dieser Daten zum Optimieren eines Modells:
Generieren von synthetischen Daten mit einem Llama 3.1 405B Instruct-Notebook
Zusätzliche Ressourcen
- Feinabstimmung von Grundlagenmodellen
- Lernprogramm: Erstellen und Bereitstellen einer Foundation Model Fine-Tuning-Ausführung
- Erstellen eines Schulungslaufs mithilfe der Foundation Model Fine-Tuning UI
- Anzeigen, Verwalten und Analysieren von Foundation Model Fine-Tuning-Ausführungen
- Vorbereiten von Daten für die Feinabstimmung des Foundation-Modells