Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Pipelines können viele Datasets mit vielen Flüssen enthalten, um sie auf dem neuesten Stand zu halten. Pipelines verwalten Updates und Cluster automatisch, um effizient zu aktualisieren. Es gibt jedoch einen gewissen Mehraufwand beim Verwalten großer Mengen von Flüssen, und dies kann zu einem größeren als erwarteten Initialisierungs- oder sogar Verwaltungsaufwand während der Verarbeitung führen.
Wenn Sie auf Verzögerungen stoßen, weil Sie darauf warten, bis ausgelöste Pipelines initialisiert sind, z. B. Initialisierungszeiten von über fünf Minuten, sollten Sie erwägen, die Verarbeitung in mehrere Pipelines aufzuteilen, selbst wenn die Datasets dieselben Quelldaten verwenden.
Hinweis
Ausgelöste Pipelines führen die Initialisierungsschritte jedes Mal aus, wenn sie aktiviert werden. Fortlaufende Pipelines führen nur die Initialisierungsschritte aus, wenn sie beendet und neu gestartet werden. Dieser Abschnitt ist besonders nützlich für die Optimierung der ausgelösten Pipeline-Initialisierung.
Wann sollten Sie die Aufteilung einer Pipeline in Betracht ziehen?
Es gibt mehrere Fälle, in denen die Aufteilung einer Pipeline aus Leistungsgründen vorteilhaft sein kann.
- Die Phasen
INITIALIZINGundSETTING_UP_TABLESdauern länger als gewünscht, was sich auf die gesamte Pipeline-Durchlaufzeit auswirkt. Wenn dies länger als 5 Minuten dauert, kann dies oft durch das Aufsplitten der Pipeline verbessert werden. - Der Treiber, der den Cluster verwaltet, kann zu einem Engpass werden, wenn viele (mehr als 30-40) Streamingtabellen in einer einzigen Pipeline ausgeführt werden. Wenn Ihr Treiber nicht reagiert, erhöht sich die Dauer für Streamingabfragen, was sich auf die Gesamtzeit des Updates auswirkt.
- Eine ausgelöste Pipeline mit mehreren Streamingtabellenflüssen kann möglicherweise nicht alle parallelisierbaren Streamupdates parallel ausführen.
Details zu Leistungsproblemen
In diesem Abschnitt werden einige der Leistungsprobleme beschrieben, die sich aus vielen Tabellen und Flüssen in einer einzelnen Pipeline ergeben können.
Engpässe in den Phasen INITIALISIERUNG und TABELLE_EINRICHTEN
Die Anfangsphasen des Durchlaufs können je nach Komplexität der Pipeline ein Leistungsengpass sein.
INITIALISIERUNGsphase
In dieser Phase werden logische Pläne erstellt, einschließlich Pläne zum Erstellen des Abhängigkeitsdiagramms und bestimmen die Reihenfolge der Tabellenaktualisierungen.
SETTING_UP_TABLES-Phase
In dieser Phase werden die folgenden Prozesse basierend auf den in der vorherigen Phase erstellten Plänen durchgeführt:
- Schemaüberprüfung und -auflösung für alle tabellen, die in der Pipeline definiert sind.
- Erstellen Sie den Abhängigkeitsgraphen und bestimmen Sie die Reihenfolge, in der die Tabellen ausgeführt werden.
- Überprüfen Sie, ob jedes Dataset in der Pipeline aktiv ist oder seit jeder vorherigen Aktualisierung neu ist.
- Erstellen Sie Streamingtabellen in der ersten Aktualisierung, und erstellen Sie für materialisierte Ansichten temporäre Ansichten oder Sicherungstabellen, die während jeder Pipelineaktualisierung erforderlich sind.
Warum INITIALISIERUNG und TABELLE_EINSTELLEN länger dauern können
Große Pipelines mit vielen Flüssen für viele Datasets können aus mehreren Gründen länger dauern:
- Für Pipelines mit vielen Flüssen und komplexen Abhängigkeiten können diese Phasen aufgrund der Menge der zu erledigenden Arbeit eine längere Zeit in Anspruch nehmen.
- Komplexe Transformationen, einschließlich
Auto CDCTransformationen, können zu einem Leistungsengpass führen, da die zum Materialisieren der Tabellen auf Basis der definierten Transformationen erforderlichen Vorgänge benötigt werden. - Es gibt auch Szenarien, in denen eine erhebliche Anzahl von Flüssen zu Langsamkeit führen kann, auch wenn diese Flüsse nicht Teil eines Updates sind. Betrachten Sie beispielsweise eine Pipeline mit über 700 Flüssen, von denen weniger als 50 für jeden Trigger basierend auf einer Konfiguration aktualisiert werden. In diesem Beispiel muss jede Ausführung einige der Schritte für alle 700 Tabellen durchlaufen, die Datenframes abrufen und dann die auszuführenden auswählen.
Engpässe im Fahrer
Der Treiber verwaltet die Updates innerhalb der Ausführung. Sie muss eine Logik für jede Tabelle ausführen, um zu entscheiden, welche Instanzen in einem Cluster jeden Fluss behandeln sollen. Wenn mehrere (mehr als 30-40) Streamingtabellen in einer einzigen Pipeline ausgeführt werden, kann der Treiber zu einem Engpass für CPU-Ressourcen werden, da er die Arbeit im gesamten Cluster verarbeitet.
Der Treiber kann auch Speicherprobleme haben. Dies kann häufiger auftreten, wenn die Anzahl der parallelen Flüsse 30 oder mehr beträgt. Es gibt keine bestimmte Anzahl von Flüssen oder Datasets, die zu Treiberspeicherproblemen führen können, aber von der Komplexität der Aufgaben abhängig sind, die parallel ausgeführt werden.
Streamingflüsse können parallel ausgeführt werden. Dies erfordert jedoch, dass der Treiber Arbeitsspeicher und CPU für alle Datenströme gleichzeitig verwendet. In einer ausgelösten Pipeline kann der Treiber jeweils eine Teilmenge von Datenströmen parallel verarbeiten, um Arbeitsspeicher- und CPU-Einschränkungen zu vermeiden.
In all diesen Fällen kann das Aufteilen der Pipelines, sodass es einen optimalen Satz von Datenströmen gibt, die Initialisierung und Verarbeitungszeit beschleunigen.
Abwägungen bei der Aufteilung von Pipelines
Wenn sich alle Ihre Flüsse in derselben Pipeline befinden, verwaltet Lakeflow Spark Declarative Pipelines Abhängigkeiten für Sie. Wenn mehrere Pipelines vorhanden sind, müssen Sie die Abhängigkeiten zwischen Pipelines verwalten.
Abhängigkeiten Möglicherweise verfügen Sie über eine nachgelagerte Pipeline, die von mehreren vorgelagerten Pipelines (anstelle einer) abhängt. Wenn Sie beispielsweise drei Pipelines,
pipeline_A,pipeline_Bundpipeline_Chaben undpipeline_Csowohl vonpipeline_Aals auch vonpipeline_Babhängt, möchten Sie, dasspipeline_Cerst dann aktualisiert wird, wenn sowohlpipeline_Aals auchpipeline_Bihre jeweiligen Updates abgeschlossen haben. Eine Möglichkeit, dies zu lösen, besteht darin, die Abhängigkeiten zu orchestrieren, indem jede Pipeline als Aufgabe in einem Auftrag mit ordnungsgemäß modellierten Abhängigkeiten erstellt wird, sodasspipeline_Cnur dann aktualisiert, wenn sowohlpipeline_Aals auchpipeline_Babgeschlossen sind.Gleichzeitigkeit Möglicherweise haben Sie unterschiedliche Abläufe innerhalb einer Pipeline, die unterschiedlich viel Zeit in Anspruch nehmen, z. B. wenn
flow_Ain 15 Sekunden aktualisiert wird undflow_Bin mehreren Minuten aktualisiert wird. Es kann hilfreich sein, die Abfragezeiten zu betrachten, bevor Sie Ihre Pipelines aufteilen und kürzere Abfragen zusammen gruppieren.
Planen Sie die Aufteilung Ihrer Pipelines
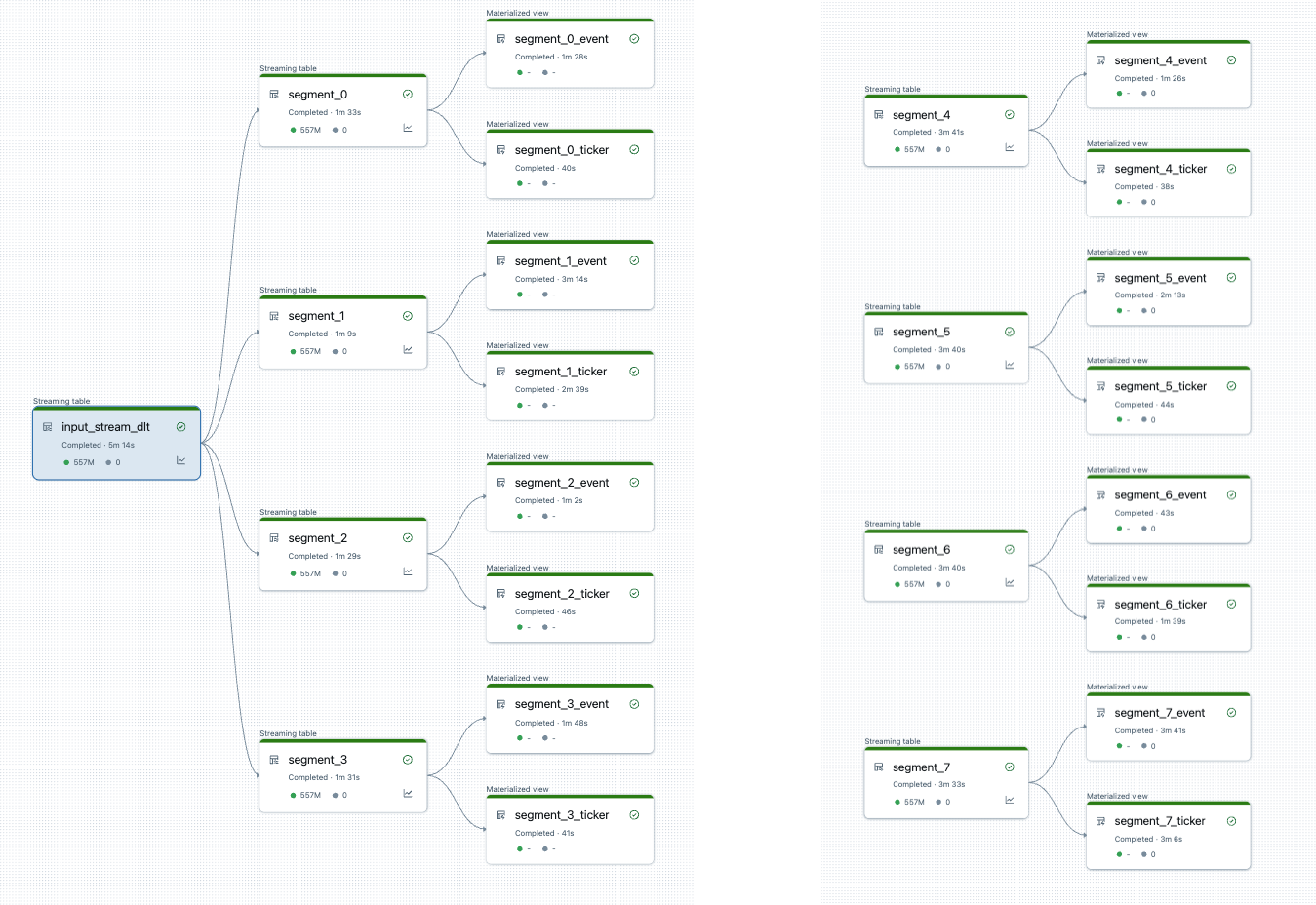
Sie können die Pipelineteilung visualisieren, bevor Sie beginnen. Hier ist ein Diagramm einer Quellpipeline, die 25 Tabellen verarbeitet. Eine einzelne Stammdatenquelle wird in 8 Segmente aufgeteilt, von denen jede zwei Ansichten enthält.
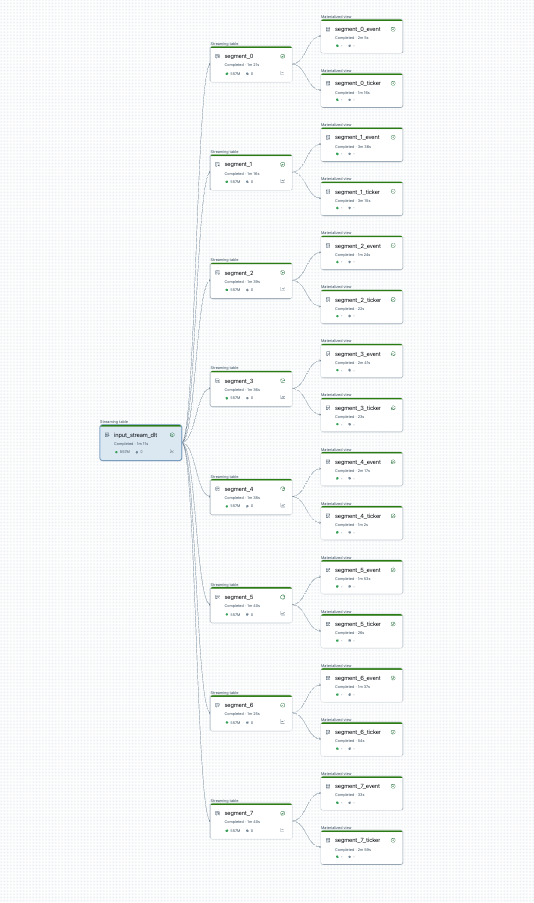
Nach dem Teilen der Pipeline gibt es zwei Pipelines. Eine verarbeitet die einzelne Stammdatenquelle und 4 Segmente und zugehörige Ansichten. Die zweite Pipeline verarbeitet die anderen vier Segmente und die zugehörigen Ansichten. Die zweite Pipeline basiert auf dem ersten, um die Stammdatenquelle zu aktualisieren.
Teilen der Pipeline ohne vollständige Aktualisierung
Nachdem Sie die Pipeline-Aufteilung geplant haben, erstellen Sie alle erforderlichen neuen Pipelines und verschieben Sie Tabellen zwischen Pipelines, um die Lastverteilung der Pipeline auszubalancieren. Sie können Tabellen verschieben, ohne eine vollständige Aktualisierung zu verursachen.
Ausführliche Informationen finden Sie unter "Verschieben von Tabellen zwischen Pipelines".
Bei diesem Ansatz gibt es einige Einschränkungen:
- Die Pipelines müssen sich im Unity-Katalog befinden.
- Quell- und Zielpipelinen müssen sich innerhalb desselben Arbeitsbereichs befinden. Arbeitsbereichübergreifende Verschiebungen werden nicht unterstützt.
- Die Zielpipeline muss vor der Verschiebung einmal erstellt und ausgeführt werden (auch wenn sie fehlschlägt).
- Sie können eine Tabelle nicht aus einer Pipeline verschieben, die den standardmäßigen Veröffentlichungsmodus verwendet, in eine Pipeline, die den Legacy-Veröffentlichungsmodus verwendet. Weitere Details finden Sie im LIVE-Schema (veraltet).