Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird beschrieben, wie und warum Databricks Token pro Sekunde für bereitgestellte Durchsatzworkloads für Foundation Model-APIs misst.
Die Leistung für große Sprachmodelle (LLMs) wird häufig in Bezug auf Token pro Sekunde gemessen. Beim Konfigurieren des Produktionsmodells, das Endpunkte bedient, ist es wichtig, die Anzahl der Anforderungen zu berücksichtigen, die Ihre Anwendung an den Endpunkt sendet. Dies hilft Ihnen zu verstehen, ob Ihr Endpunkt so konfiguriert werden muss, dass er skaliert werden kann, ohne die Latenz zu beeinträchtigen.
Beim Konfigurieren der Skalierungsbereiche für Endpunkte, die mit bereitgestelltem Durchsatz ausgestattet sind, stellte Databricks fest, dass es einfacher ist, über die Eingaben in Ihr System mithilfe von Token nachzudenken.
Was sind Token?
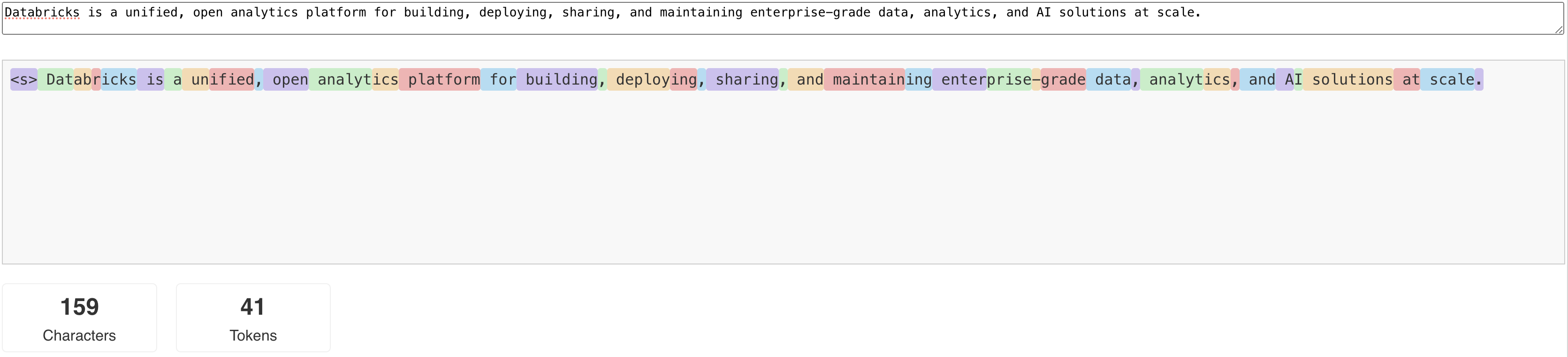
LLMs lesen und generieren Text in Form von sogenannten Tokens. Token können Wörter oder Unterwörter sein, und die genauen Regeln zum Aufteilen von Text in Token variieren von Modell zu Modell. Sie können z. B. Onlinetools verwenden, um zu sehen, wie llamas Tokenizer Wörter in Token konvertiert.
Das folgende Diagramm zeigt ein Beispiel, wie der Llama-Tokenizer Text aufbricht:
Warum die LLM-Leistung im Hinblick auf Token pro Sekunde messen?
Die Bereitstellung von Endpunkten wird traditionell basierend auf der Anzahl der gleichzeitigen Anforderungen pro Sekunde (RPS) konfiguriert. Eine LLM-Inference-Anfrage benötigt jedoch unterschiedlich viel Zeit, basierend auf der Anzahl der Token, die übergeben werden, und wie viele Token generiert werden, was zu Ungleichgewichten zwischen Anfragen führen kann. Daher müssen Sie entscheiden, wie viel Skalierung Ihr Endpunkt benötigt, um die Endpunktskala im Hinblick auf den Inhalt Ihrer Anforderung – die Tokens – zu messen.
Verschiedene Anwendungsfälle bieten unterschiedliche Eingabe- und Ausgabetokenverhältnisse:
- Unterschiedliche Eingabekontexte: Während einige Anforderungen nur wenige Eingabetoken umfassen können, z. B. eine kurze Frage, können andere Hunderte oder sogar Tausende von Token umfassen, z. B. ein langes Dokument zur Zusammenfassung. Diese Variabilität macht die Konfiguration eines Servier-Endpunkts basierend ausschließlich auf RPS herausfordernd, da sie die unterschiedlichen Verarbeitungsanforderungen der verschiedenen Anfragen nicht berücksichtigt.
- Unterschiedliche Ausgabelängen je nach Anwendungsfall: Unterschiedliche Anwendungsfälle für LLMs können zu erheblich unterschiedlichen Ausgabetokenlängen führen. Das Generieren von Ausgabetoken ist der zeitintensive Teil der LLM-Ableitung, sodass sich dies erheblich auf den Durchsatz auswirken kann. Beispielsweise umfasst die Zusammenfassung kürzere, prägnantere Antworten, während die Textgenerierung, wie das Schreiben von Artikeln oder Produktbeschreibungen, viel längere Antworten erzeugen kann.
Wie bestimme ich den Bereich der Tokens pro Sekunde für meinen Endpunkt?
Bereitgestellte Durchsatz-Endpunkte sind so konfiguriert, dass sie eine bestimmte Anzahl von Token pro Sekunde verarbeiten können, die an den Endpunkt gesendet werden. Der Endpunkt skaliert nach oben und unten, um die Last Ihrer Produktionsanwendung zu verarbeiten. Sie werden pro Stunde berechnet, basierend auf dem Tokenbereich pro Sekunde, auf den Ihr Endpunkt skaliert wird.
Die beste Möglichkeit, herauszufinden, welche Token-pro-Sekunde-Reichweite für den bereitgestellten Durchsatz des für Ihren Anwendungsfall geeigneten Endpunkts funktioniert, besteht darin, einen Lasttest mit einem repräsentativen Datensatz durchzuführen. Siehe Führen Sie Ihr eigenes LLM-Endpunkt-Benchmarking durch.
Es gibt zwei wichtige Faktoren zu berücksichtigen:
- Wie Databricks Token pro Sekunde der LLM-Leistung misst.
- Funktionsweise der automatischen Skalierung.
Wie Databricks die Leistung des LLM anhand der Verarbeitung von Token pro Sekunde misst.
Databricks vergleicht Endpunkte mit einer Workload, die Zusammenfassungsaufgaben darstellen, die für Anwendungsfälle zur Generierung von Abruferweiterungen üblich sind. Insbesondere besteht die Arbeitsauslastung aus:
- 2048 Eingabetoken
- 256 Ausgabetoken
Die angezeigten Tokenbereiche kombinieren den Eingabe- und Ausgabetokendurchsatz und optimieren standardmäßig den Ausgleich des Durchsatzes und der Latenz.
Benutzer können mit Databricks-Benchmarks so viele Token pro Sekunde gleichzeitig an den Endpunkt senden, wobei jede Anforderung eine Batchgröße von 1 aufweist. Dadurch werden mehrere Anforderungen simuliert, die gleichzeitig auf den Endpunkt treffen, was genauer darstellt, wie Sie den Endpunkt tatsächlich in der Produktion verwenden würden.
- Wenn beispielsweise ein bereitgestellter Durchsatz, der den Endpunkt bedient, eine festgelegte Rate von 2304 Token pro Sekunde (2048 + 256) aufweist, wird eine einzelne Anforderung mit einer Eingabe von 2048 Token und eine erwartete Ausgabe von 256 Token voraussichtlich etwa eine Sekunde dauern.
- Ebenso, wenn die Rate auf 5600 festgelegt ist, können Sie erwarten, dass eine einzelne Anforderung, wie oben bei den Eingabe- und Ausgabetoken angegeben, etwa 0,5 Sekunden zur Ausführung benötigt – das heißt, der Endpunkt kann zwei ähnliche Anforderungen in etwa einer Sekunde verarbeiten.
Wenn Sich Ihre Workload von der oben angegebenen Durchsatzrate unterscheidet, können Sie davon ausgehen, dass die Latenz in Bezug auf die angegebene bereitgestellte Durchsatzrate variiert. Wie bereits erwähnt, ist das Generieren von mehr Ausgabetoken zeitintensiver als das Einschließen von mehr Eingabetoken. Wenn Sie eine Batchableitung durchführen und den Zeitraum schätzen möchten, der bis zum Abschluss benötigt wird, können Sie die durchschnittliche Anzahl von Eingabe- und Ausgabetoken berechnen und mit der obigen Datenbricks-Benchmark-Workload vergleichen.
- Wenn Sie beispielsweise über 1000 Zeilen verfügen, mit einer durchschnittlichen Anzahl von Eingabetoken von 3000 und einer durchschnittlichen Ausgabetokenanzahl von 500 und einem bereitgestellten Durchsatz von 3500 Token pro Sekunde kann es länger als 1000 Sekunden insgesamt (eine Sekunde pro Zeile) dauern, da Ihre durchschnittliche Tokenanzahl größer als der Databricks-Benchmark ist.
- Ebenso kann es bei 1000 Zeilen, einer durchschnittlichen Eingabe von 1500 Token, einer durchschnittlichen Ausgabe von 100 Token und einem bereitgestellten Durchsatz von 1600 Token pro Sekunde weniger als 1000 Sekunden dauern (eine Sekunde pro Zeile), da Ihr durchschnittliches Token weniger als der Databricks-Benchmark ist.
Um den idealen bereitgestellten Durchsatz für die Ausführung Ihrer Batch-Inferenz-Workload zu schätzen, können Sie das Notizbuch unter Ausführen eines Batch-LLM-Rückschlusses mithilfe von „ai_query“ verwenden.
Funktionsweise der automatischen Skalierung
Model Serving verfügt über ein schnelles automatisches Skalierungssystem, das die zugrunde liegende Berechnung skaliert, um die Anforderung Ihrer Anwendung an Tokens pro Sekunde zu erfüllen. Databricks skaliert den bereitgestellten Durchsatz in Tokenblöcken pro Sekunde, sodass Zusätzliche Einheiten des bereitgestellten Durchsatzes nur berechnet werden, wenn Sie sie verwenden.
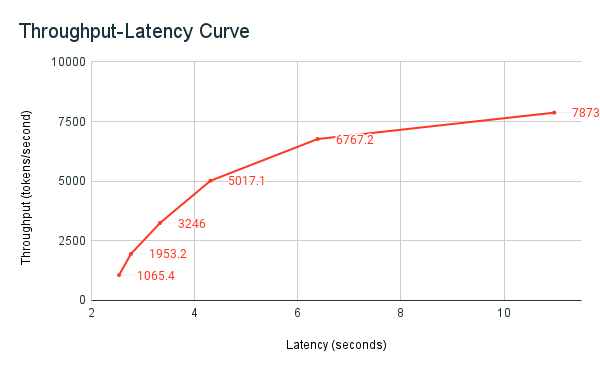
Das folgende Durchsatzlatenzdiagramm zeigt einen getesteten bereitgestellten Durchsatzendpunkt mit einer steigenden Anzahl paralleler Anforderungen. Der erste Punkt stellt 1 Anforderung, die zweite, 2 parallele Anforderungen, die dritte, 4 parallele Anforderungen usw. dar. Wenn die Anzahl der Anforderungen steigt und damit auch die Nachfrage nach Tokens pro Sekunde zunimmt, sehen Sie, dass der bereitgestellte Durchsatz ebenfalls ansteigt. Diese Erhöhung zeigt an, dass die automatische Skalierung die verfügbare Berechnung erhöht. Sie werden jedoch möglicherweise feststellen, dass der Durchsatz allmählich abflacht und einen Grenzwert von etwa 8 000 Tokens pro Sekunde erreicht, wenn mehr parallele Anforderungen gestellt werden. Die Gesamtlatenz steigt, da mehr Anforderungen in der Warteschlange warten müssen, bevor sie verarbeitet werden, da die zugewiesene Berechnung gleichzeitig verwendet wird.
Hinweis
Sie können den Durchsatz konsistent halten, indem Sie die Skalierung auf Null deaktivieren und einen minimalen Durchsatz für den Serving-Endpoint konfigurieren. Dadurch entfällt die Notwendigkeit, darauf zu warten, dass der Endpunkt hochskaliert wird.
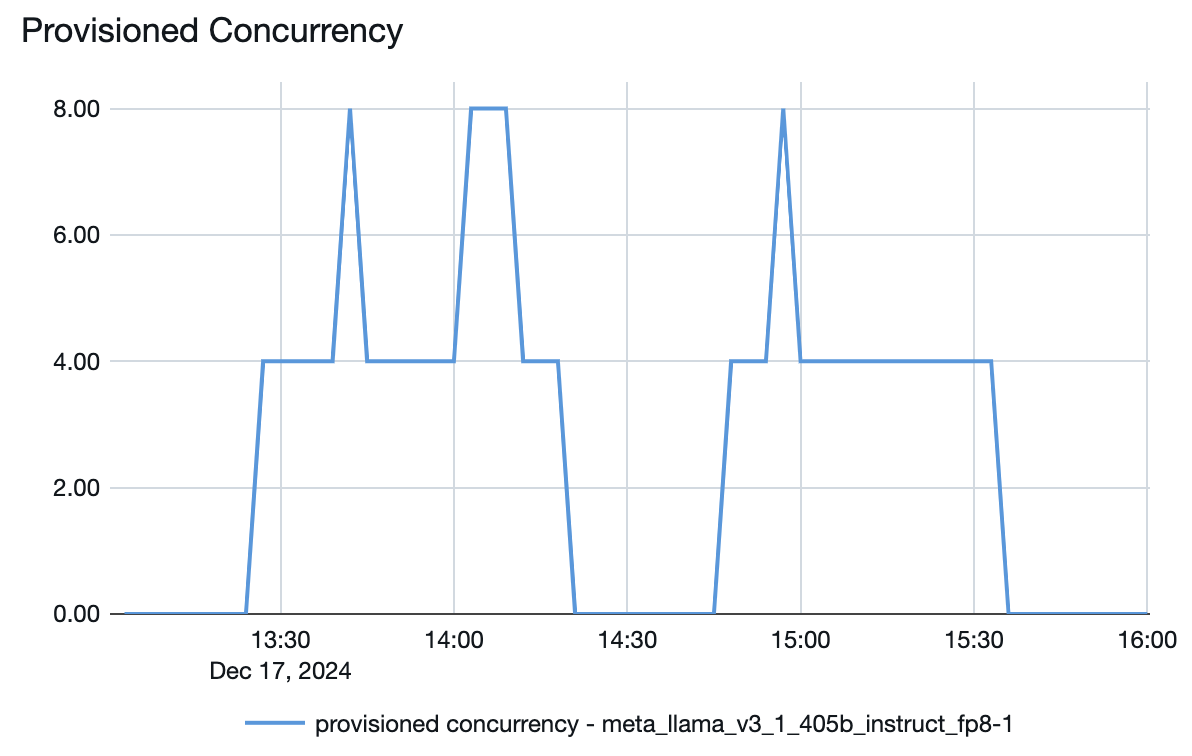
Sie können auch am Modellbereitstellungsendpunkt sehen, wie Ressourcen je nach Bedarf hoch- oder heruntergefahren werden:
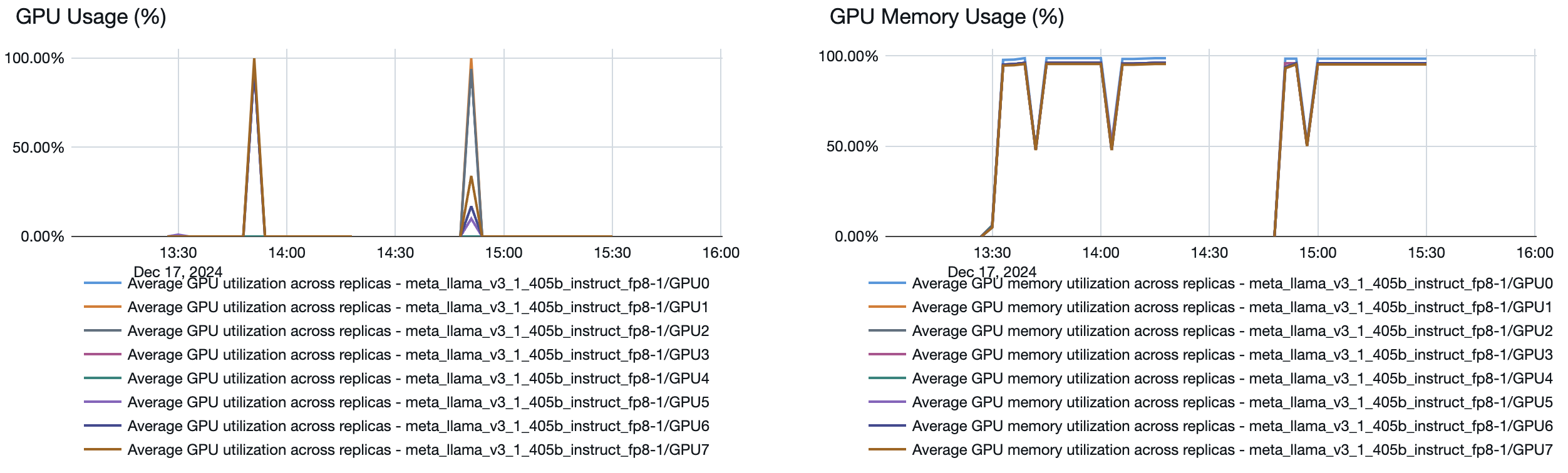
Problembehandlung
Wenn Ihr bereitgestellter Endpunkt für den Durchsatz weniger Tokens pro Sekunde verarbeitet als vorgesehen, überprüfen Sie anhand der folgenden Angaben, wie stark der Endpunkt tatsächlich skaliert wurde:
- Die bereitgestellten Nebenläufigkeitskurven in den Endpunktmetriken
- Die bereitgestellte Durchsatzendpunkt-Mindestbandgröße.
- Öffnen Sie die Details der bereitgestellten Entität für den Endpunkt und überprüfen Sie den Wert für die Mindestanzahl an Tokens pro Sekunde im Dropdown-Menü Bis zu.
Anschließend können Sie berechnen, wie viel der Endpunkt tatsächlich skaliert hat, indem Sie die folgende Formel verwenden:
- Bereitgestellte Parallelität * Mindestbandgröße / 4
Der bereitgestellte Parallelitätsplot für das oben beschriebene Llama 3.1 405B-Modell weist beispielsweise eine maximal bereitgestellte Parallelität von 8 auf. Beim Einrichten eines Endpunkts dafür betrug die Mindestbandgröße 850 Token pro Sekunde. In diesem Beispiel wurde der Endpunkt auf ein Maximum von hochskaliert:
- 8 (bereitgestellte Parallelität) * 850 (minimale Bandgröße) / 4 = 1700 Token pro Sekunde