HorovodRunner: Verteiltes Deep Learning mit Horovod
Erfahren Sie, wie Sie mithilfe von HorovodRunner verteiltes Training von Machine Learning-Modellen ausführen, um Horovod-Trainingsaufträge als Spark-Aufträge in Azure Databricks zu starten.
Was ist HorovodRunner?
HorovodRunner ist eine allgemeine API zum Ausführen verteilter Deep Learning-Workloads auf Azure Databricks mithilfe des Horovod-Frameworks. Durch die Integration von Horovod in den Barrieremodus von Spark kann Azure Databricks eine höhere Stabilität für zeitintensive Deep Learning-Trainingsaufträge in Spark bereitstellen. HorovodRunner verwendet eine Python-Methode, die Deep Learning-Trainingscode mit Horovod-Hooks enthält. HorovodRunner „picklet“ die Methode für den Treiber und verteilt sie an Spark-Worker. Ein Horovod MPI-Auftrag wird im Barriereausführungsmodus als Spark-Auftrag eingebettet. Der erste Executor erfasst die IP-Adressen aller Aufgaben-Executors mithilfe von BarrierTaskContext und löst mithilfe von mpirun einen Horovod-Auftrag aus. Jeder Python MPI-Prozess lädt das „gepicklete“ Benutzerprogramm, deserialisiert es und führt es aus.
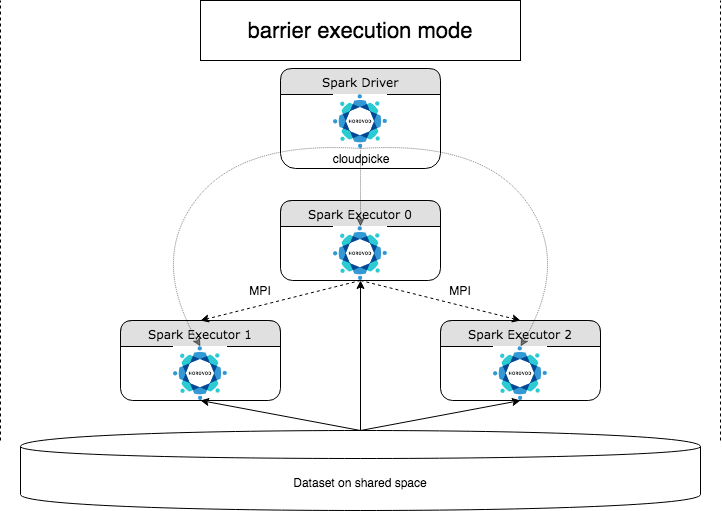
Verteiltes Training mit HorovodRunner
Mit HorovodRunner können Sie Horovod-Trainingsaufträge als Spark-Aufträge starten. Die HorovodRunner-API unterstützt die in der Tabelle gezeigten Methoden. Weitere Informationen finden Sie in der HorovodRunner-API-Dokumentation.
| Methode und Signatur | BESCHREIBUNG |
|---|---|
init(self, np) |
Erstellen Sie eine Instanz von HorovodRunner. |
run(self, main, **kwargs) |
Führen Sie einen Horovod-Trainingsauftrag aus, der main(**kwargs) aufruft. Die Main-Funktion und die Schlüsselwortargumente werden mit cloudpickle serialisiert und an Clusterworker verteilt. |
Der allgemeine Ansatz für die Entwicklung eines verteilten Trainingsprogramms mit HorovodRunner lautet:
- Erstellen Sie eine mit der Anzahl der Knoten initialisierte
HorovodRunner-Instanz. - Definieren Sie eine Horovod-Trainingsmethode gemäß den unter Horovod Usage (Horovod-Verwendung) beschriebenen Methoden, und stellen Sie sicher, dass alle Importanweisungen innerhalb der Methode hinzugefügt werden.
- Übergeben Sie die Trainingsmethode an die
HorovodRunner-Instanz.
Beispiele:
hr = HorovodRunner(np=2)
def train():
import tensorflow as tf
hvd.init()
hr.run(train)
Verwenden Sie hr = HorovodRunner(np=-n), um HorovodRunner nur mit n-Unterprozessen auf dem Treiber auszuführen. Wenn z. B. 4 GPUs auf dem Treiberknoten vorhanden sind, können Sie n bis 4 auswählen. Ausführliche Informationen zum Parameter np finden Sie in der Dokumentation zur HorovodRunner-API. Ausführliche Informationen zum Anheften einer GPU pro Unterprozess finden Sie im Horovod-Nutzungshandbuch.
Ein häufiger Fehler ist, dass TensorFlow-Objekte nicht gefunden oder „gepicklet“ werden können. Dies geschieht, wenn die Bibliothekimportanweisungen nicht an andere Executors verteilt werden. Um dieses Problem zu vermeiden, schließen Sie alle Importanweisungen (z. B. import tensorflow as tf) sowohl am Anfang der Horovod-Trainingsmethode als auch in anderen benutzerdefinierten Funktionen, die in der Horovod-Trainingsmethode aufgerufen werden, ein.
Aufzeichnen des Horovod-Trainings mit Horovod Timeline
Horovod kann die Zeitachse seiner Aktivität aufzeichnen, die als Horovod Timeline bezeichnet wird.
Wichtig
Die Horovod Timeline hat erhebliche Auswirkungen auf die Leistung. Inception3-Durchsatz kann um ~40 % verringert werden, wenn die Horovod Timeline aktiviert ist. Verwenden Sie die Horovod Timeline nicht, um HorovodRunner-Aufträge zu beschleunigen.
Sie können die Horovod Timeline nicht anzeigen, während das Training ausgeführt wird.
Um eine Horovod Timeline aufzuzeichnen, legen Sie die HOROVOD_TIMELINE-Umgebungsvariable auf den Speicherort fest, an dem Sie die Zeitachsendatei speichern möchten. Databricks empfiehlt die Verwendung eines Speicherorts im freigegebenen Speicher, damit die Zeitachsendatei problemlos abgerufen werden kann. Beispielsweise können Sie lokale DBFS-Datei-APIs wie folgt verwenden:
timeline_dir = "/dbfs/ml/horovod-timeline/%s" % uuid.uuid4()
os.makedirs(timeline_dir)
os.environ['HOROVOD_TIMELINE'] = timeline_dir + "/horovod_timeline.json"
hr = HorovodRunner(np=4)
hr.run(run_training_horovod, params=params)
Fügen Sie dann am Anfang und Ende der Trainingsfunktion zeitachsenspezifischen Code hinzu. Das folgende Beispiel-Notebook enthält Beispielcode, den Sie als Problemumgehung zum Anzeigen des Trainingsfortschritts verwenden können.
Horovod Timeline – Beispielnotebook
Um die Zeitachsendatei herunterzuladen, verwenden Sie die Databricks-CLI oder FileStore, und zeigen Sie sie dann mit der Funktion chrome://tracing des Chrome-Browsers an. Beispiel:
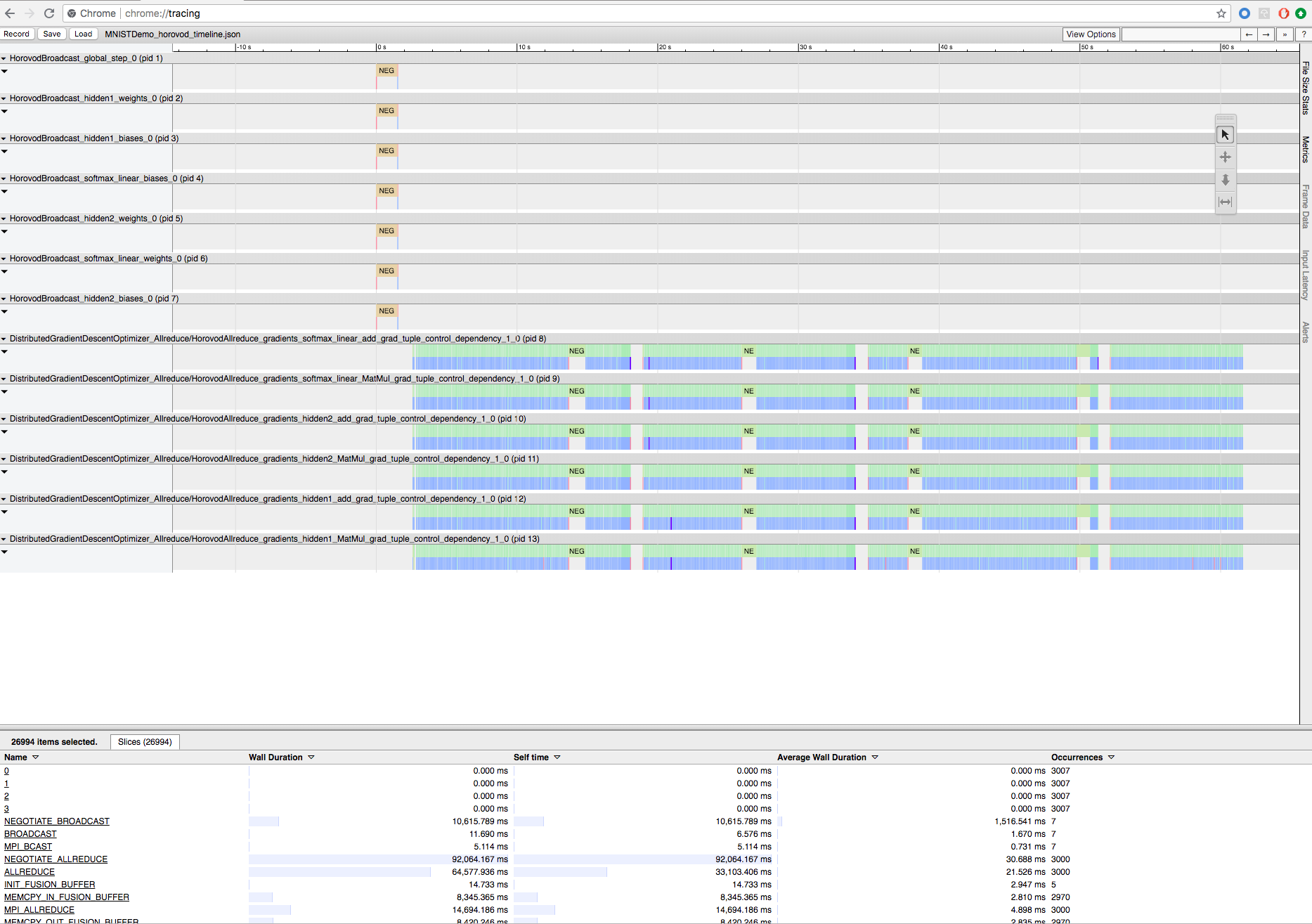
Entwicklungsworkflow
Dies sind die allgemeinen Schritte bei der Migration von Deep Learning-Code mit einem einzelnen Knoten zu verteiltem Training. Die Beispiele: Migrieren zu verteiltem Deep Learning mit HorovodRunner in diesem Abschnitt veranschaulichen diese Schritte.
- Vorbereiten von Einzelknotencode: Bereiten Sie den Einzelknotencode mit TensorFlow, Keras oder PyTorch vor, und testen Sie den Code.
- Migrieren zu Horovod: Befolgen Sie die Anweisungen unter Horovod Usage (Horovod-Verwendung), um den Code mit Horovod zu migrieren und auf dem Treiber zu testen:
- Fügen Sie
hvd.init()hinzu, um Horovod zu initialisieren. - Heften Sie mit
config.gpu_options.visible_device_listeine Server-GPU an, die von diesem Prozess verwendet werden soll. Bei der typischen Einrichtung einer GPU pro Prozess kann dies auf den lokalen Rang festgelegt werden. In diesem Fall wird dem ersten Prozess auf dem Server die erste GPU zugeordnet, dem zweiten Prozess die zweite GPU usw. - Fügen Sie einen Shard des Datasets ein. Dieser Datasetoperator ist sehr nützlich, wenn verteiltes Training ausgeführt wird, da jeder Worker eine eindeutige Teilmenge lesen kann.
- Skalieren Sie die Lernrate nach Anzahl der Worker. Die effektive Batchgröße beim synchronen verteilten Training wird durch die Anzahl der Worker skaliert. Durch Erhöhen der Lernrate wird die erhöhte Batchgröße kompensiert.
- Umschließen Sie den Optimierer mit
hvd.DistributedOptimizer. Der verteilte Optimierer delegiert die Gradientenberechnung an den ursprünglichen Optimierer, mittelt die Gradienten mit allreduce oder allgather und wendet dann die gemittelten Gradienten an. - Fügen Sie
hvd.BroadcastGlobalVariablesHook(0)hinzu, um anfängliche Variablenzustände von Rang 0 an alle anderen Prozesse zu übertragen. Dies ist notwendig, um eine konsistente Initialisierung aller Worker sicherzustellen, wenn das Training mit zufälligen Gewichtungen gestartet oder über einen Prüfpunkt wiederhergestellt wird. Wenn Sie nichtMonitoredTrainingSessionverwenden, können Sie denhvd.broadcast_global_variables-Vorgang alternativ auch ausführen, nachdem globale Variablen initialisiert wurden. - Ändern Sie Ihren Code so, dass Prüfpunkte nur auf Worker 0 gespeichert werden, um zu verhindern, dass andere Worker sie beschädigen.
- Fügen Sie
- Migrieren zu HorovodRunner: HorovodRunner führt den Horovod-Trainingsauftrag durch Aufrufen einer Python-Funktion aus. Sie müssen die Haupttrainingsprozedur mit einer einzelnen Python-Funktion umschließen. Anschließend können Sie HorovodRunner im lokalen und verteilten Modus testen.
Aktualisieren von Deep Learning-Bibliotheken
Hinweis
Dieser Artikel enthält Verweise auf den Begriff Slave, einen Begriff, den Azure Databricks nicht verwendet. Sobald der Begriff aus der Software entfernt wird, wird er auch aus diesem Artikel entfernt.
Wenn Sie TensorFlow, Keras oder PyTorch aktualisieren oder herabstufen, müssen Sie Horovod neu installieren, damit es für die neu installierte Bibliothek kompiliert wird. Wenn Sie beispielsweise TensorFlow aktualisieren möchten, empfiehlt Databricks, das Init-Skript aus den TensorFlow-Installationsanweisungen zu verwenden und den folgenden TensorFlow-spezifischen Horovod-Installationscode an das Ende anzufügen. Informationen zum Arbeiten mit verschiedenen Kombinationen, z. B. ein Upgrade oder Downgrade von PyTorch und anderen Bibliotheken, finden Sie unter Horovod-Installationsanweisungen.
add-apt-repository -y ppa:ubuntu-toolchain-r/test
apt update
# Using the same compiler that TensorFlow was built to compile Horovod
apt install g++-7 -y
update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 60 --slave /usr/bin/g++ g++ /usr/bin/g++-7
HOROVOD_GPU_ALLREDUCE=NCCL HOROVOD_CUDA_HOME=/usr/local/cuda pip install horovod==0.18.1 --force-reinstall --no-deps --no-cache-dir
Beispiele: Migrieren zu verteiltem Deep Learning mit HorovodRunner
Die folgenden Beispiele, die auf dem MNIST-Dataset basieren, veranschaulichen, wie ein Einzelknoten-Deep Learning-Programm zu verteiltem Deep Learning mit HorovodRunner migriert wird.
- Deep Learning mit TensorFlow mit HorovodRunner für MNIST
- PyTorch mit einem einzelnen Knoten für verteiltes Deep Learning anpassen
Einschränkungen
- Beim Arbeiten mit Arbeitsbereichsdateien funktioniert HorovodRunner nicht, wenn
npauf größer als „1“ festgelegt ist und das Notebook aus anderen relativen Dateien importiert wird. Betrachten Sie die Verwendung von horovod.spark anstelle vonHorovodRunner.