Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird beschrieben, wie MLflow-Läufe zum Anzeigen und Analysieren der Ergebnisse eines Modelltrainingsexperiments und zum Verwalten und Organisieren von Läufen verwendet werden. Weitere Informationen zu MLflow-Experimenten finden Sie unter Organisieren von Trainingsläufen mit MLflow-Experimenten.
Eine MLflow-Ausführung entspricht einer einzelnen Ausführung des Modellcodes. Jede Ausführung zeichnet Informationen auf, z. B. das Notizbuch, das die Ausführung gestartet hat, alle Modelle, die von der Ausführung erstellt wurden, Modellparameter und Metriken, die als Schlüsselwertpaare, Tags für Ausführungsmetadaten und alle Artefakte oder Ausgabedateien gespeichert wurden, die von der Ausführung erstellt wurden.
Alle MLflow-Ausführungen werden im aktiven Experiment protokolliert. Wenn Sie ein Experiment nicht explizit als aktives Experiment festgelegt haben, werden Ausführungen im Notebookexperiment protokolliert.
Anzeigen von Ausführungsdetails
Sie können auf eine Ausführung entweder über die Detailseite des Experiments oder direkt über das Notizbuch zugreifen, das die Ausführung erstellt hat.
Klicken Sie auf der Seite für Experimentdetails auf den Ausführungsnamen in der Ausführungstabelle.
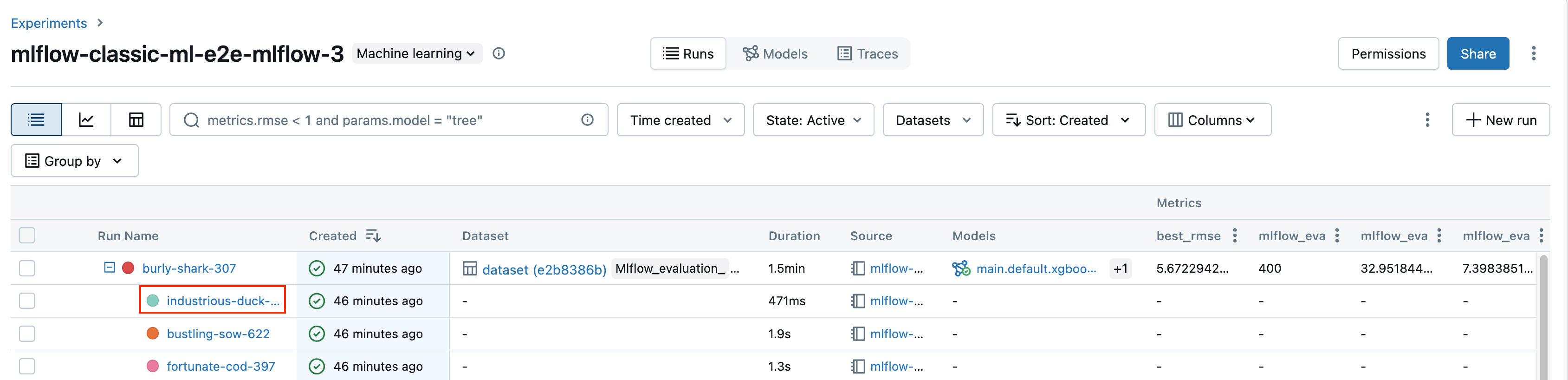
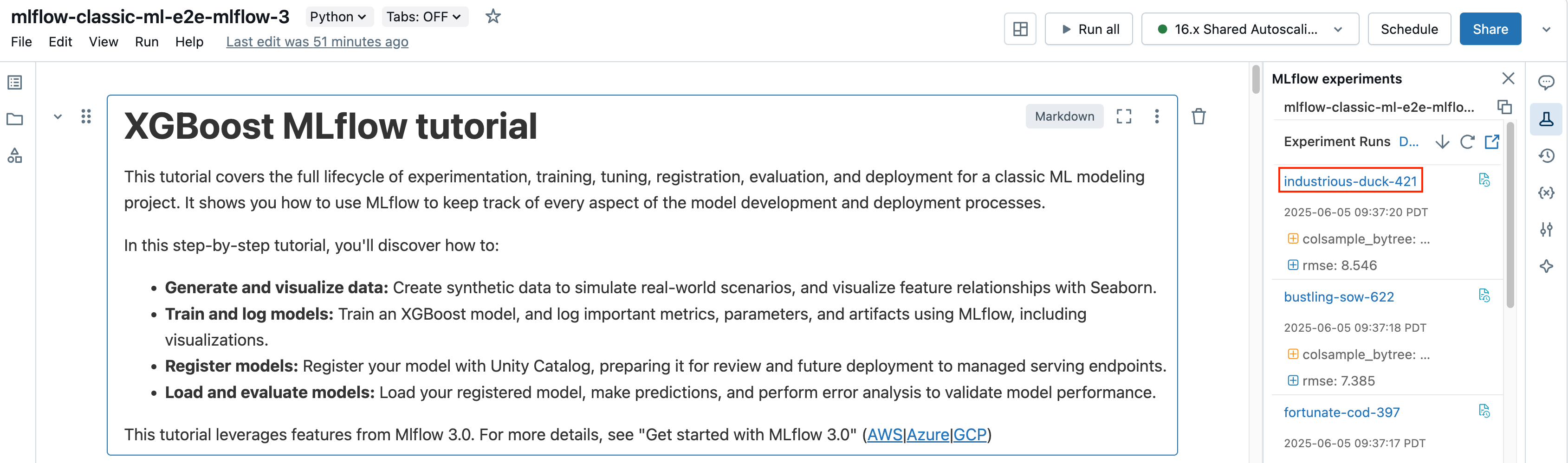
Klicken Sie im Notebook auf den Ausführungsnamen auf der Randleiste „Experimentausführungen“.
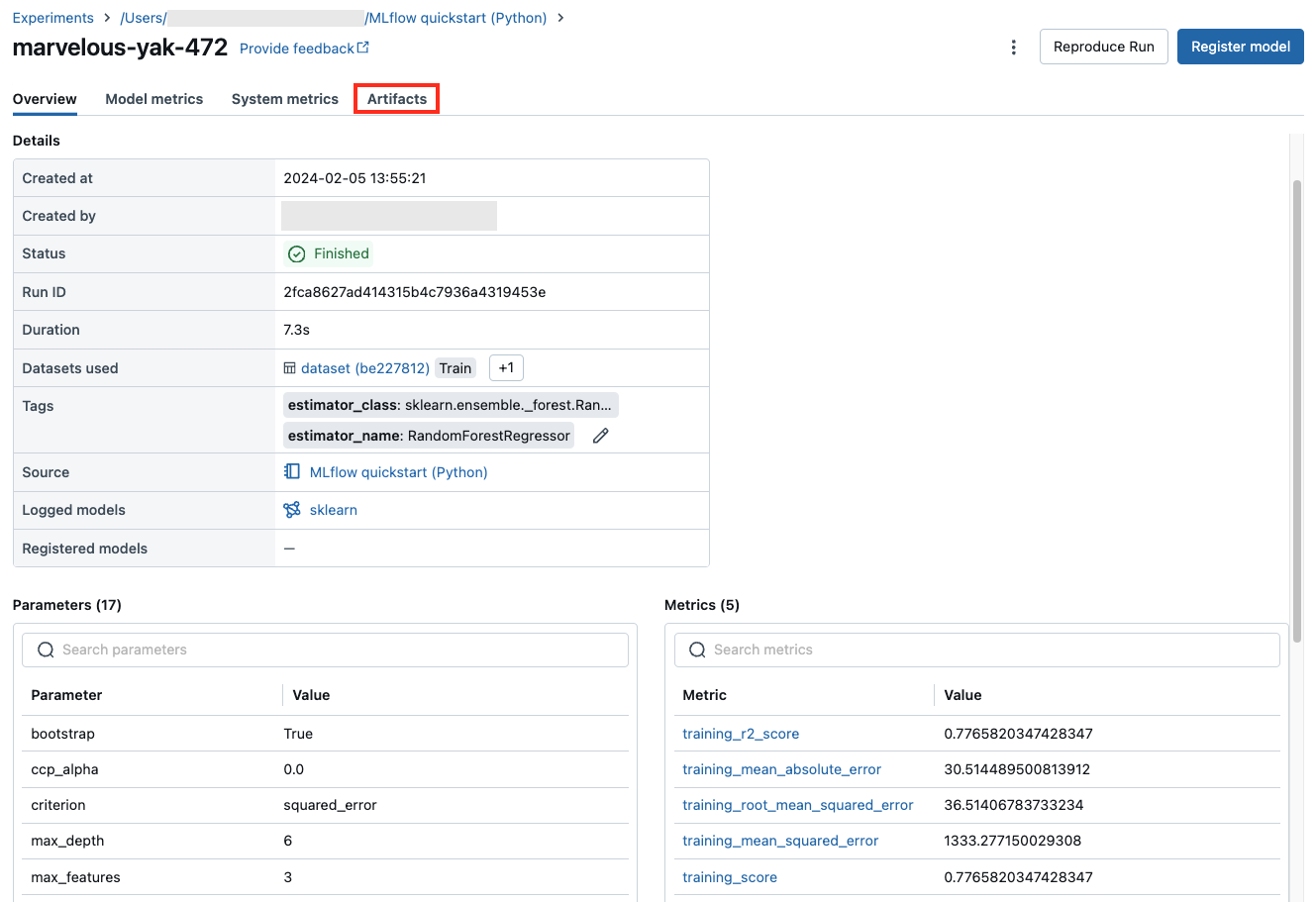
Der Laufbildschirm zeigt die Lauf-ID, die für den Lauf verwendeten Parameter, die daraus resultierenden Metriken und Details über den Lauf einschließlich eines Links zum Quellnotizbuch an. Artefakte, die von der Ausführung gespeichert wurden, sind auf der Registerkarte Artefakte verfügbar.
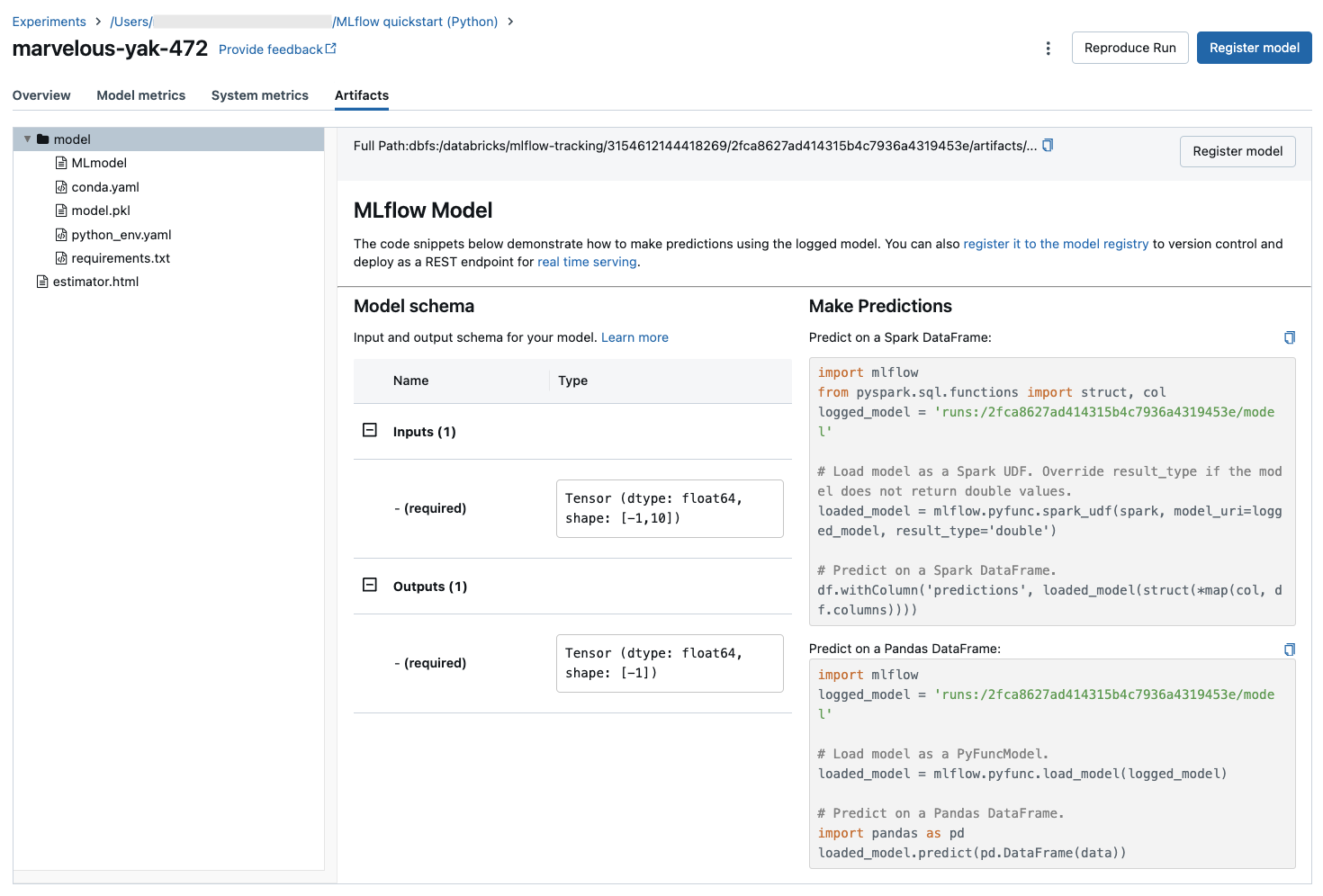
Codeausschnitte für die Vorhersage
Wenn Sie ein Modell aus einer Ausführung protokollieren, wird das Modell auf der Registerkarte Artefakte angezeigt, zusammen mit Codeausschnitten, die veranschaulichen, wie das Modell geladen und verwendet wird, um Vorhersagen für Spark und Pandas DataFrames zu erstellen. In MLflow 3 sind Modelle nun ihr unterschiedliches Objekt der ersten Klasse, anstatt als Ausführungsartefakt protokolliert zu werden. Weitere Informationen finden Sie unter "Erste Schritte mit MLflow 3" für Modelle.
Anzeigen des für eine Ausführung verwendeten Notebooks
Um die Version des Notebooks anzuzeigen, die einen Lauf erstellt hat:
- Klicken Sie auf der Detailseite des Experiments auf den Link in der Spalte Quelle.
- Klicken Sie auf der Ausführungsseite auf den Link neben Quelle.
- Klicken Sie im Notebook in der Seitenleiste „Experimentausführungen“ auf das Symbol Notebook
 im Feld für diese Experimentausführung.
im Feld für diese Experimentausführung.
Die Version des Notebooks, das der Ausführung zugeordnet ist, wird im Hauptfenster mit einer Hervorhebungsleiste angezeigt, die das Datum und die Uhrzeit der Ausführung anzeigt.
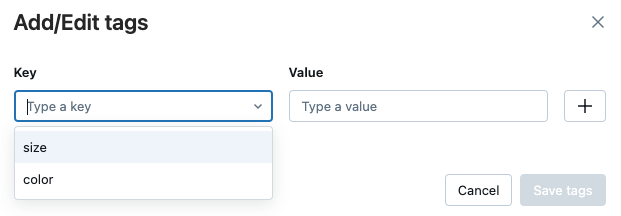
Hinzufügen eines Tags zu einem Lauf
Tags sind Schlüssel-Wert-Paare, die Sie erstellen und später verwenden können, um nach Ausführungen zu suchen.
Klicken Sie in der Tabelle „Details“ auf der Ausführungsseite neben „Tags“ auf „Tags hinzufügen“.
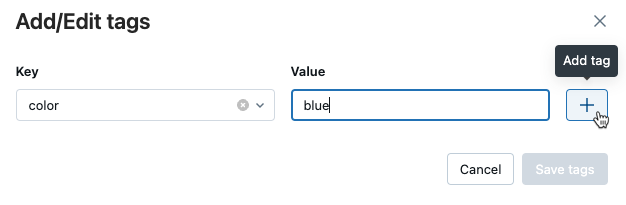
Das Dialogfeld "Tags hinzufügen/bearbeiten" wird geöffnet. Geben Sie im Feld Key einen Namen für den Schlüssel ein, und klicken Sie auf Taghinzufügen.
Geben Sie im Feld Wert den Wert für das Tag ein.
Klicken Sie auf das Pluszeichen, um das soeben eingegebene Schlüsselwertpaar zu speichern.
Wenn Sie zusätzliche Tags hinzufügen möchten, wiederholen Sie die Schritte 2 bis 4.
Wenn Sie fertig sind, klicken Sie auf Tags speichern.
Bearbeiten oder Löschen eines Tags für eine Ausführung
Klicken Sie in der Tabelle "Details" auf der Ausführungsseite auf das
 Neben den vorhandenen Tags.
Neben den vorhandenen Tags.
Das Dialogfeld "Tags hinzufügen/bearbeiten" wird geöffnet.
Um ein Tag zu löschen, klicken Sie auf das X für dieses Tag.
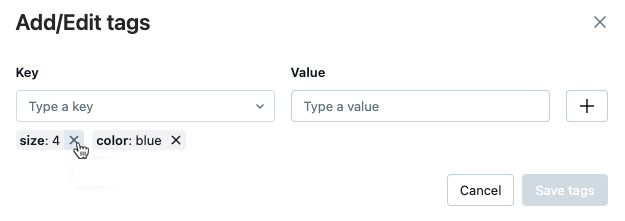
Um ein Tag zu bearbeiten, wählen Sie den Schlüssel im Dropdownmenü aus, und bearbeiten Sie den Wert im Feld Wert. Klicken Sie auf das Pluszeichen, um Ihre Änderung zu speichern.
Wenn Sie fertig sind, klicken Sie auf Tags speichern.
Reproduzieren der Softwareumgebung einer Ausführung
Sie können die genaue Softwareumgebung des Laufs reproduzieren, indem Sie oben rechts auf der Laufseite auf Lauf reproduzieren klicken. Das folgende Dialogfeld wird angezeigt:
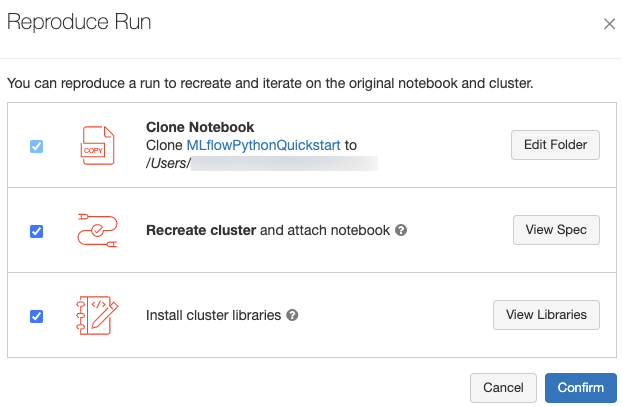
Wenn Sie die Standardeinstellungen verwenden und auf Bestätigen klicken:
- Das Notebook wird an dem im Dialogfeld angegebenen Speicherort geklont.
- Wenn der ursprüngliche Cluster noch vorhanden ist, wird das geklonte Notebook an den ursprünglichen Cluster angefügt, und der Cluster wird gestartet.
- Wenn der ursprüngliche Cluster nicht mehr vorhanden ist, wird ein neuer Cluster mit der gleichen Konfiguration, einschließlich aller installierten Bibliotheken, erstellt und gestartet. Das Notebook wird an den neuen Cluster angefügt.
Sie können einen anderen Speicherort für das geklonte Notebook auswählen und die Clusterkonfiguration und die installierten Bibliotheken überprüfen:
- Klicken Sie auf Ordner bearbeiten, um einen anderen Ordner zum Speichern des geklonten Notebooks auszuwählen.
- Klicken Sie auf Spezifikation anzeigen, um die Clusterspezifikation anzuzeigen. Deaktivieren Sie diese Option, um nur das Notebook und nicht den Cluster zu klonen.
- Wenn der ursprüngliche Cluster nicht mehr vorhanden ist, können Sie die im ursprünglichen Cluster installierten Bibliotheken anzeigen, indem Sie auf Ansichtsbibliothekenklicken. Wenn der ursprüngliche Cluster noch vorhanden ist, ist dieser Abschnitt ausgegraut.
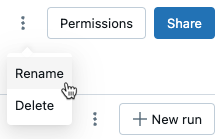
Lauf umbenennen
Um eine Ausführung umzubenennen, klicken Sie auf das ![]() in der oberen rechten Ecke der Ausführungsseite (neben der Schaltfläche Berechtigungen) und wählen Sie Umbenennen aus.
in der oberen rechten Ecke der Ausführungsseite (neben der Schaltfläche Berechtigungen) und wählen Sie Umbenennen aus.
Spalten auswählen, die angezeigt werden sollen
Klicken Sie zum Steuern der Spalten, die in der Ausführungstabelle auf der Experimentdetailseite angezeigt werden, auf Spalten, und wählen Sie im Dropdownmenü die entsprechenden Spalten aus.
Filterausführungen
Sie können in der Tabelle auf der Detailseite des Experiments nach Läufen suchen, basierend auf Parameter- oder Metrikwerten. Sie können auch basierend auf Tags nach Ausführungen suchen.
Um nach Ausführungen zu suchen, die einem Ausdruck entsprechen, der Parameter- und Metrikwerte enthält, geben Sie eine Abfrage in das Suchfeld ein, und drücken Sie die EINGABETASTE. Einige Beispiele für die Abfragesyntax:
metrics.r2 > 0.3params.elasticNetParam = 0.5params.elasticNetParam = 0.5 AND metrics.avg_areaUnderROC > 0.3MIN(metrics.rmse) <= 1MAX(metrics.memUsage) > 0.9LATEST(metrics.memUsage) = 0 AND MIN(metrics.rmse) <= 1Standardmäßig werden Metrikwerte auf Grundlage des zuletzt protokollierten Werts gefiltert. Mit
MINoderMAXkönnen Sie basierend auf den minimalen bzw. maximalen Metrikwerten nach Ausführungen suchen. Minimale und maximale Metrikwerte gibt es nur bei den nach August 2024 protokollierten Ausführungen.Um mittels Tag nach Ausführungen zu suchen, geben Sie Tags im folgenden Format ein:
tags.<key>="<value>". Zeichenfolgenwerte müssen wie gezeigt in Anführungszeichen eingeschlossen werden.tags.estimator_name="RandomForestRegressor"tags.color="blue" AND tags.size=5Schlüssel und Werte können Leerzeichen enthalten. Wenn der Schlüssel Leerzeichen enthält, müssen Sie ihn wie gezeigt in Backticks einschließen.
tags.`my custom tag` = "my value"
Sie können die Ausführung auch basierend auf ihrem Status (Aktiv oder Gelöscht) filtern, wann die Ausführung erstellt wurde und welche Datasets verwendet wurden. Treffen Sie dazu Ihre Auswahl in den Dropdownmenüs Zeitpunkt der Erstellung, Status oder Datasets.
Läufe herunterladen
Sie können Läufe von der Detailseite "Experiment" wie folgt herunterladen:
Klicken Sie auf das
 Um das Kebab-Menü zu öffnen.
Um das Kebab-Menü zu öffnen.
Klicken Sie auf
<n>-Ausführungen herunterladen, um eine Datei im CSV-Format herunterzuladen, die alle angezeigten Ausführungen (maximal 100) enthält. MLflow erstellt und lädt eine Datei mit einer Ausführung pro Zeile mit den folgenden Feldern für jede Ausführung herunter:Start Time, Duration, Run ID, Name, Source Type, Source Name, User, Status, <parameter1>, <parameter2>, ..., <metric1>, <metric2>, ...Wenn Sie mehr als 100 Ausführungen herunterladen oder diese programmgesteuert herunterladen möchten, wählen Sie Alle Ausführungen herunterladen. Ein Dialogfeld wird geöffnet, in dem ein Codeausschnitt angezeigt wird, den Sie in einem Notizbuch kopieren oder öffnen können. Nachdem Sie diesen Code in einer Notebookzelle ausgeführt haben, wählen Sie Alle Zeilen herunterladen in der Zellenausgabe aus.
Löschen von Läufen
Sie können Läufe auf der Detailseite des Experiments mit den folgenden Schritten löschen:
- Wählen Sie im Experiment mindestens eine Ausführung aus, indem Sie auf das Kontrollkästchen links neben der jeweiligen Ausführung klicken.
- Klicken Sie auf Löschen.
- Wenn es sich bei der Ausführung um eine übergeordnete Ausführung handelt, entscheiden Sie, ob Sie auch nachgeordnete Ausführungen löschen möchten. Diese Option ist standardmäßig ausgewählt.
- Klicken Sie auf Löschen, um den Vorgang zu bestätigen. Gelöschte Ausführungsdaten werden 30 Tage lang gespeichert. Wählen Sie zum Anzeigen gelöschter Ausführungen im Feld „Status“ die Option Gelöscht aus.
Massenlöschen von Läufen basierend auf der Erstellungszeit
Sie können Python verwenden, um Ausführungen eines Experiments, die vor oder bei einem UNIX-Zeitstempel erstellt wurden, in Massen zu löschen.
Mit Databricks Runtime 14.1 oder höher können Sie die mlflow.delete_runs-API aufrufen, um Ausführungen zu löschen und die Anzahl der gelöschten Ausführungen zurückzugeben.
Im Folgenden sind die mlflow.delete_runs-Parameter aufgeführt:
-
experiment_id: Dies ist die ID des Experiments, das die zu löschenden Ausführungen enthält. -
max_timestamp_millis: Der maximale Erstellungszeitstempel in Millisekunden seit dem Unix-Epochenbeginn für das Löschen von Läufen. Es werden nur Ausführungen gelöscht, die vor oder zu diesem Zeitstempel erstellt wurden. -
max_runs:Wahlfrei. Eine positive ganze Zahl, die die maximale Anzahl der zu löschenden Durchläufe angibt. Der maximal zulässige Wert für max_runs beträgt 10000. Ohne Angabe wird fürmax_runsstandardmäßig 10000 verwendet.
import mlflow
# Replace <experiment_id>, <max_timestamp_ms>, and <max_runs> with your values.
runs_deleted = mlflow.delete_runs(
experiment_id=<experiment_id>,
max_timestamp_millis=<max_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_deleted = mlflow.delete_runs(
experiment_id="4183847697906956",
max_timestamp_millis=1711990504000,
max_runs=10
)
Mit Databricks Runtime 13.3 LTS oder einer früheren Version können Sie den folgenden Clientcode in einem Azure Databricks-Notebook ausführen.
from typing import Optional
def delete_runs(experiment_id: str,
max_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk delete runs in an experiment that were created prior to or at the specified timestamp.
Deletes at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to delete.
:param max_timestamp_millis: The maximum creation timestamp in milliseconds
since the UNIX epoch for deleting runs. Only runs
created prior to or at this timestamp are deleted.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to delete. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs deleted.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "max_timestamp_millis": max_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/delete-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_deleted"]
In der API-Dokumentation zur Azure Databricks Experimente-API finden Sie Parameter und Rückgabewertspezifikationen zum Löschen von Ausführung basierend auf der Erstellungszeit.
Wiederherstellen von Durchläufen
Sie können zuvor gelöschte Ausführungen auf der Benutzeroberfläche wie folgt wiederherstellen:
- Wählen Sie auf der Seite Experiment im Feld Status die Option Gelöscht aus, um gelöschte Ausführungen anzuzeigen.
- Wählen Sie mindestens eine Ausführung aus, indem Sie auf das Kontrollkästchen links neben der jeweiligen Ausführung klicken.
- Klicken Sie auf Wiederherstellen.
- Klicken Sie zum Bestätigen auf Wiederherstellen. Die wiederhergestellten Ausführungen werden jetzt angezeigt, wenn Sie im Feld „Status“ die Option Aktiv auswählen.
Massenwiederherstellungsvorgänge basieren auf der Löschzeit
Sie können Python auch verwenden, um mehrere Ausführungen eines Experiments, die zu oder nach einem UNIX-Zeitstempel gelöscht wurden, gleichzeitig wiederherzustellen.
Mit Databricks Runtime 14.1 oder höher können Sie die mlflow.restore_runs-API aufrufen, um Ausführungen wiederherzustellen und die Anzahl der wiederhergestellten Ausführungen zurückzugeben.
Im Folgenden sind die mlflow.restore_runs-Parameter aufgeführt:
-
experiment_id: Dies ist die ID des Experiments, das die wiederherzustellenden Ausführungen enthält. -
min_timestamp_millis: Der minimale Löschzeitstempel in Millisekunden seit der UNIX-Epoche für die Wiederherstellung von Durchläufen. Nur Ausführungen, die zu oder nach diesem Zeitstempel gelöscht wurden, werden wiederhergestellt. -
max_runs:Wahlfrei. Eine positive ganze Zahl, die die maximale Anzahl der zu wiederherzustellenden Ausführungen angibt. Der maximal zulässige Wert für max_runs beträgt 10000. Ohne Angabe liegt der Wert für max_runs standardmäßig bei 10000.
import mlflow
# Replace <experiment_id>, <min_timestamp_ms>, and <max_runs> with your values.
runs_restored = mlflow.restore_runs(
experiment_id=<experiment_id>,
min_timestamp_millis=<min_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_restored = mlflow.restore_runs(
experiment_id="4183847697906956",
min_timestamp_millis=1711990504000,
max_runs=10
)
Mit Databricks Runtime 13.3 LTS oder einer früheren Version können Sie den folgenden Clientcode in einem Azure Databricks-Notebook ausführen.
from typing import Optional
def restore_runs(experiment_id: str,
min_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk restore runs in an experiment that were deleted at or after the specified timestamp.
Restores at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to restore.
:param min_timestamp_millis: The minimum deletion timestamp in milliseconds
since the UNIX epoch for restoring runs. Only runs
deleted at or after this timestamp are restored.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to restore. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs restored.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "min_timestamp_millis": min_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/restore-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_restored"]
In der API-Dokumentation zur Azure Databricks Experimente-API finden Sie Parameter und Rückgabewertspezifikationen zum Wiederherstellen von Ausführung basierend auf der Löschzeit.
Vergleichen von Ausführungen
Sie können Läufe aus einem einzelnen Experiment oder aus mehreren Experimenten vergleichen. Auf der Seite Läufe vergleichen werden Informationen zu den ausgewählten Ausführungen im Tabellenformat angezeigt. Sie können auch Visualisierungen von Ausführungsergebnissen und Tabellen mit Ausführungsinformationen, Ausführungsparametern und Metriken erstellen. Siehe Vergleicht MLflow-Ausführungen und -Modelle mithilfe von Grafiken und Diagrammen.
Die Tabellen Parameterund Metrikenzeigen die Ausführungsparameter und Metriken aller ausgewählten Ausführungen an. Die Spalten in diesen Tabellen werden durch die Tabelle Laufdetails direkt darüber identifiziert. Der Einfachheit halber können Sie Parameter und Metriken, die in allen ausgewählten Ausführungen identisch sind, ausblenden, indem Sie die Option  umschalten.
umschalten.
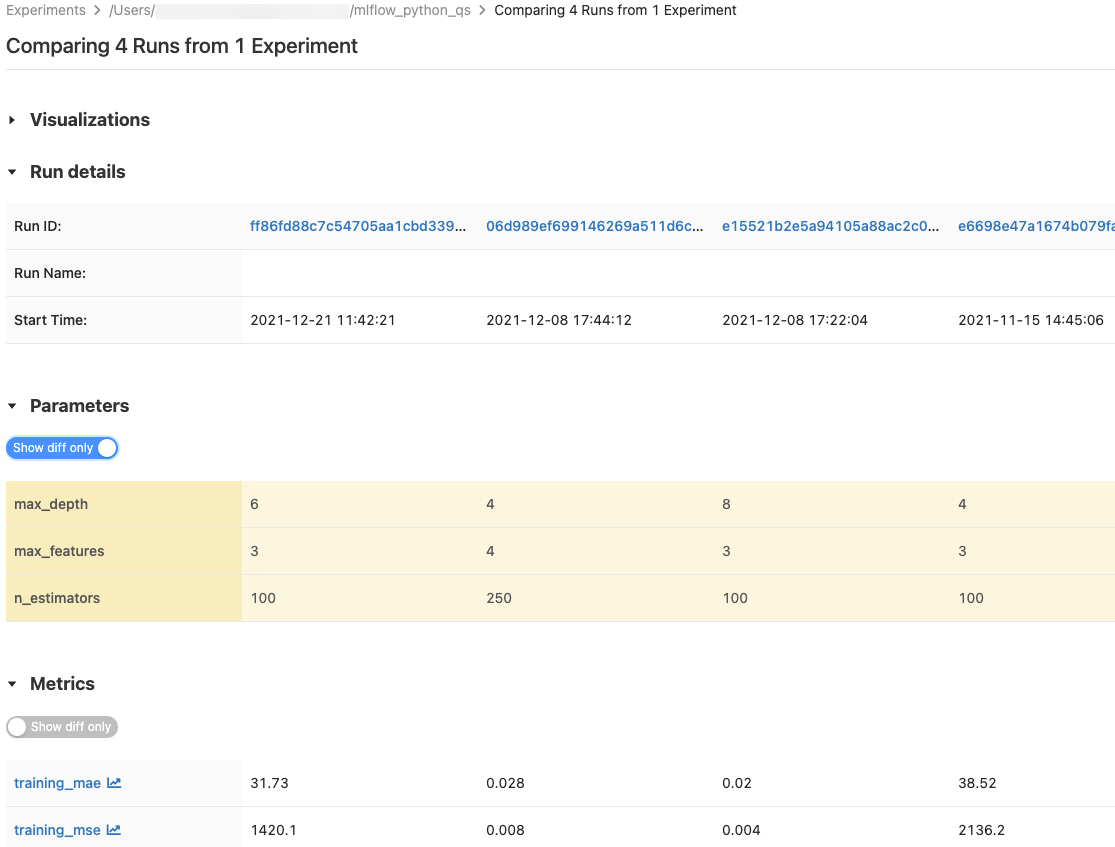
Vergleichen Sie Läufe aus einem einzelnen Experiment
- Wählen Sie auf der Experimentdetails-Seitezwei oder mehr Läufe aus, indem Sie auf das Kontrollkästchen links neben dem Lauf klicken, oder wählen Sie alle Läufe aus, indem Sie das Kontrollkästchen oben in der Spalte anklicken.
- Klicken Sie auf Vergleichen. Der Bildschirm „Vergleich der
<N>Ausführungen“ wird angezeigt.
Vergleichen Sie Läufe aus mehreren Experimenten
- Wählen Sie auf der Seite Experimente die Experimente aus, die Sie vergleichen möchten, indem Sie links neben dem Experimentnamen auf das Feld klicken.
- Klicken Sie auf Vergleichen (n) (n ist die Anzahl der ausgewählten Experimente). Ein Bildschirm wird angezeigt, auf dem alle Läufe aus den ausgewählten Experimenten angezeigt werden.
- Wählen Sie zwei oder mehr Ausführungsläufe aus, indem Sie links neben der Ausführung auf das Kontrollkästchen klicken, oder markieren Sie alle Ausführungen, indem Sie das Kontrollkästchen oben in der Spalte aktivieren.
- Klicken Sie auf Vergleichen. Der Bildschirm „Vergleichen von
<N>Ausführungen“ wird angezeigt.
Vergleich der Ausführung mithilfe von Systemtabellen
MLflow-Metadaten für Experimente und Läufe sind auch in Systemtabellen verfügbar, in denen Sie Databricks SQL und alle Lakehouse-Tools von Databricks nutzen können, um Ihre Experimentdaten zu analysieren. Weitere Informationen finden Sie in der Referenz zu MLflow-Systemtabellen.
Kopieren von Runs zwischen Arbeitsbereichen
Zum Importieren oder Exportieren von MLflow-Ausführungen in oder aus Ihrem Databricks-Arbeitsbereich können Sie das communitygesteuerte Open Source Projekt MLflow Export-Import verwenden.