Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Von Bedeutung
Dieses Feature befindet sich in der Betaversion.
Mit MLflow können Sie automatisch Bewertungen an einer Stichprobe Ihrer Produktionsdatensätze vornehmen, um die Qualität kontinuierlich zu überwachen.
Hauptvorteile:
- Automatisierte Qualitätsbewertung ohne manuelles Eingreifen
- Flexibles Sampling zum Ausgleich der Abdeckung mit Rechenkosten
- Konsistente Auswertung unter Verwendung derselben Bewerter aus der Entwicklung
- Kontinuierliche Überwachung mit regelmäßiger Hintergrundausführung
Voraussetzungen
Installieren von MLflow und erforderlichen Paketen
pip install --upgrade "mlflow[databricks]>=3.1.0" openaiErstellen Sie ein MLflow-Experiment, indem Sie die Schnellstartanleitung zum Einrichten Ihrer Umgebung ausführen.
Instrumentieren Sie Ihre Produktionsanwendung mit der MLflow-Nachverfolgung
Zugriff auf ein Unity-Katalogschema mit
CREATE TABLEBerechtigungen, um die Überwachungsergebnisse zu speichern.
Schritt 1: Testen von Scorern auf Ihre Produktionsablaufverfolgungen
Zunächst testen wir, ob die Scorer, die Sie in der Produktionsumgebung verwenden werden, Ihre Traces auswerten können.
Tipp
Wenn Sie Ihre Produktions-App als predict_fn in mlflow.genai.evaluate() während der Entwicklung verwendet haben, sind Ihre Scorer wahrscheinlich bereits kompatibel.
Warnung
MLflow unterstützt derzeit nur die Verwendung vordefinierter Scorer für die Produktionsüberwachung. Wenden Sie sich an Ihren Databricks-Kontoverantwortlichen, wenn Sie benutzerdefinierte codebasierte oder LLM-basierte Scorer im Produktionsbetrieb ausführen müssen.
Verwenden Sie
mlflow.genai.evaluate(), um die Scorer anhand einer Stichprobe Ihrer Ablaufverfolgungen zu testen.import mlflow from mlflow.genai.scorers import ( Guidelines, RelevanceToQuery, RetrievalGroundedness, RetrievalRelevance, Safety, ) # Get a sample of up to 10 traces from your experiment traces = mlflow.search_traces(max_results=10) # Run evaluation to test the scorers mlflow.genai.evaluate( data=traces, scorers=[ RelevanceToQuery(), RetrievalGroundedness(), RetrievalRelevance(), Safety(), Guidelines( name="mlflow_only", # Guidelines can refer to the request and response. guidelines="If the request is unrelated to MLflow, the response must refuse to answer.", ), # You can have any number of guidelines. Guidelines( name="customer_service_tone", guidelines="""The response must maintain our brand voice which is: - Professional yet warm and conversational (avoid corporate jargon) - Empathetic, acknowledging emotional context before jumping to solutions - Proactive in offering help without being pushy Specifically: - If the customer expresses frustration, anger, or disappointment, the first sentence must acknowledge their emotion - The response must use "I" statements to take ownership (e.g., "I understand" not "We understand") - The response must avoid phrases that minimize concerns like "simply", "just", or "obviously" - The response must end with a specific next step or open-ended offer to help, not generic closings""", ), ], )Verwenden Sie die MLflow-Ablaufverfolgungs-UI, um zu überprüfen, welche Scorer ausgeführt wurden.
In diesem Fall stellen wir fest, dass die
RetrievalGroundedness()undRetrievalRelevance()Scorer in der MLflow-Benutzeroberfläche nicht angezeigt wurden, obwohl wir sie ausgeführt hatten. Dies deutet darauf hin, dass diese Scorer nicht mit unseren Spuren funktionieren, daher sollten wir sie im nächsten Schritt nicht einschalten.
Schritt 2: Aktivieren der Überwachung
Jetzt aktivieren wir den Überwachungsdienst. Nach der Aktivierung synchronisiert der Überwachungsdienst eine Kopie Ihrer ausgewerteten Traces aus Ihrem MLflow Experiment mit einer Delta Table im von Ihnen angegebenen Unity-Katalog-Schema.
Von Bedeutung
Nach der Festlegung kann das Unity-Katalogschema nicht mehr geändert werden.
Verwenden der Benutzeroberfläche
Folgen Sie der nachstehenden Aufzeichnung, um die Benutzeroberfläche zu verwenden, um die Scorer zu aktivieren, die in Schritt 1 erfolgreich ausgeführt wurden. Wenn Sie eine Samplingrate auswählen, werden die Scorer nur auf diesen Prozentsatz der Ablaufverfolgungen ausgeführt (z. B. bewirkt die Eingabe von 1.0 eine Ausführung der Scorer auf 100% Ihrer Ablaufverfolgungen, und .2 wird auf 20%Ihrer Ablaufverfolgungen ausgeführt, usw.).
Wenn Sie die Samplingrate pro Scorer festlegen möchten, müssen Sie das SDK verwenden.
Verwenden des SDK
Verwenden Sie den folgenden Codeausschnitt, um die Scorer zu aktivieren, die in Schritt 1 erfolgreich ausgeführt wurden. Wenn Sie eine Samplingrate auswählen, werden die Scorer nur auf diesen Prozentsatz der Ablaufverfolgungen ausgeführt (z. B. bewirkt die Eingabe von 1.0 eine Ausführung der Scorer auf 100% Ihrer Ablaufverfolgungen, und .2 wird auf 20%Ihrer Ablaufverfolgungen ausgeführt, usw.). Optional können Sie die Samplingrate pro Scorer konfigurieren.
# These packages are automatically installed with mlflow[databricks]
from databricks.agents.monitoring import create_external_monitor, AssessmentsSuiteConfig, BuiltinJudge, GuidelinesJudge
external_monitor = create_external_monitor(
# Change to a Unity Catalog schema where you have CREATE TABLE permissions.
catalog_name="workspace",
schema_name="default",
assessments_config=AssessmentsSuiteConfig(
sample=1.0, # sampling rate
assessments=[
# Predefined scorers "safety", "groundedness", "relevance_to_query", "chunk_relevance"
BuiltinJudge(name="safety"), # or {'name': 'safety'}
BuiltinJudge(
name="groundedness", sample_rate=0.4
), # or {'name': 'groundedness', 'sample_rate': 0.4}
BuiltinJudge(
name="relevance_to_query"
), # or {'name': 'relevance_to_query'}
BuiltinJudge(name="chunk_relevance"), # or {'name': 'chunk_relevance'}
# Guidelines can refer to the request and response.
GuidelinesJudge(
guidelines={
# You can have any number of guidelines, each defined as a key-value pair.
"mlflow_only": [
"If the request is unrelated to MLflow, the response must refuse to answer."
], # Must be an array of strings
"customer_service_tone": [
"""The response must maintain our brand voice which is:
- Professional yet warm and conversational (avoid corporate jargon)
- Empathetic, acknowledging emotional context before jumping to solutions
- Proactive in offering help without being pushy
Specifically:
- If the customer expresses frustration, anger, or disappointment, the first sentence must acknowledge their emotion
- The response must use "I" statements to take ownership (e.g., "I understand" not "We understand")
- The response must avoid phrases that minimize concerns like "simply", "just", or "obviously"
- The response must end with a specific next step or open-ended offer to help, not generic closings"""
],
}
),
],
),
)
print(external_monitor)
Schritt 3. Aktualisieren des Monitors
Um die Scorerkonfiguration zu ändern, verwenden Sie update_external_monitor(). Die Konfiguration ist zustandslos – d. h., sie wird vollständig vom Update überschrieben. Um eine vorhandene Konfiguration zum Ändern abzurufen, verwenden Sie get_external_monitor().
Verwenden der Benutzeroberfläche
Folgen Sie der nachstehenden Aufzeichnung, um die Benutzeroberfläche zum Aktualisieren der Scorer zu verwenden.
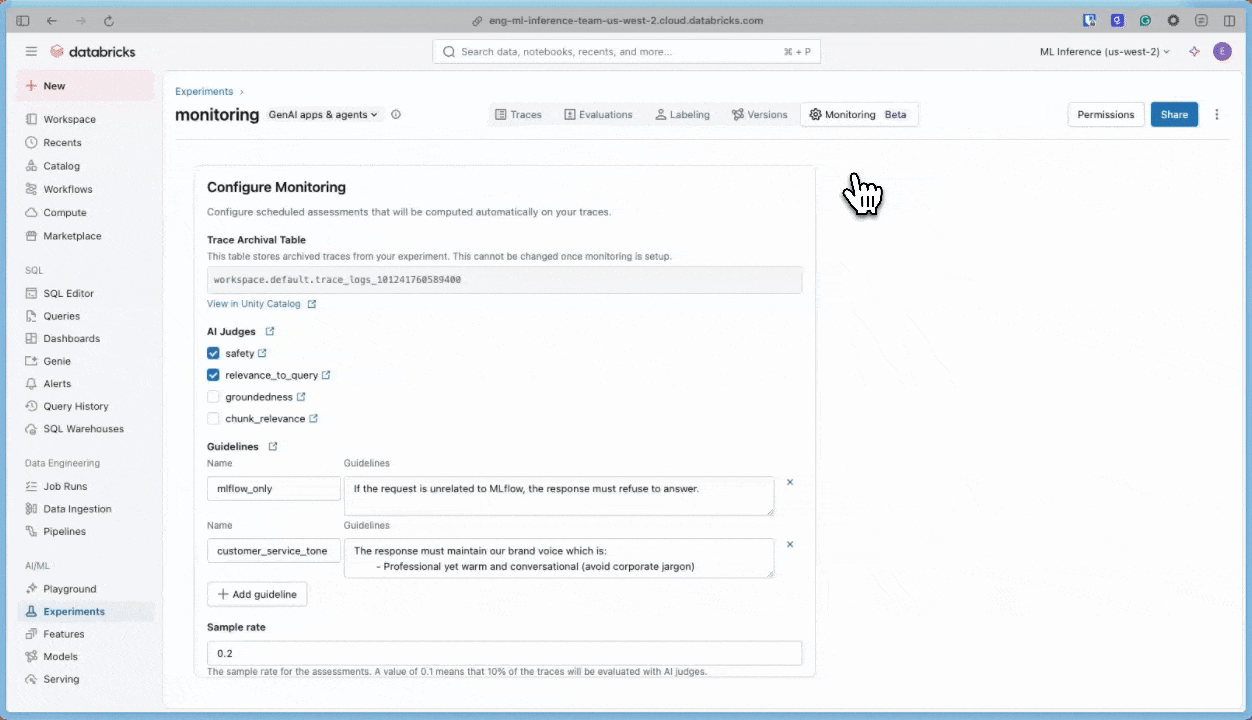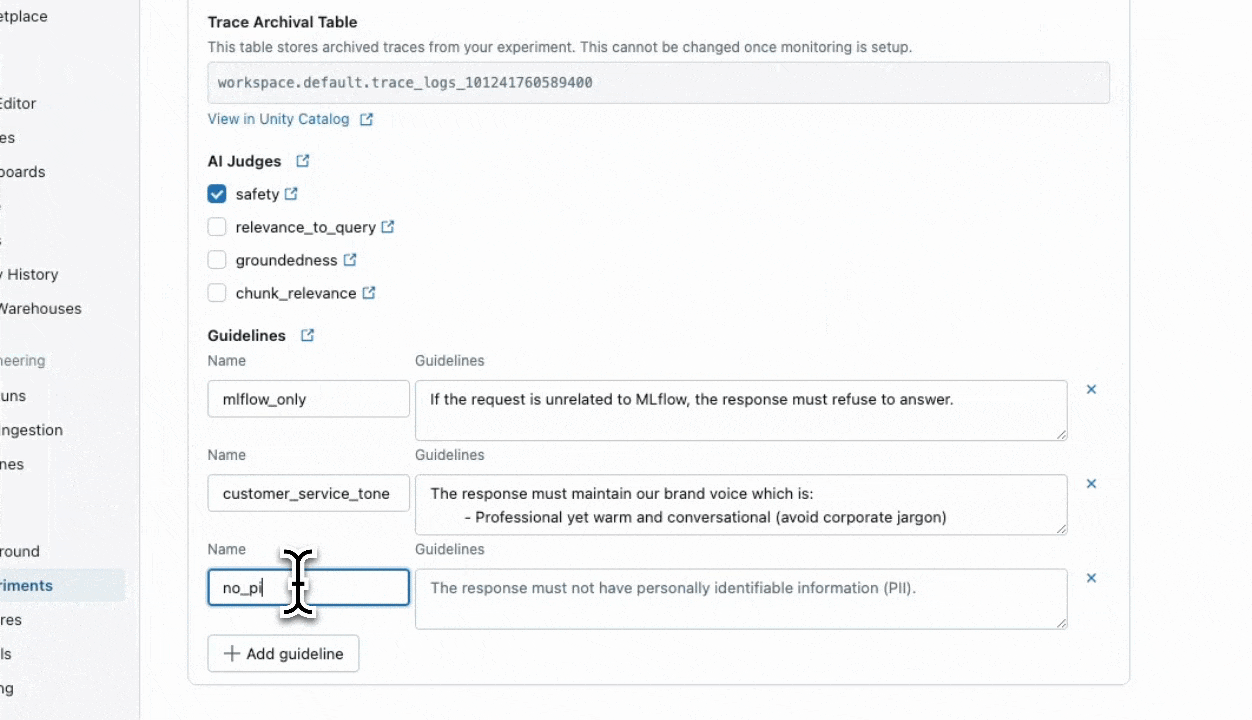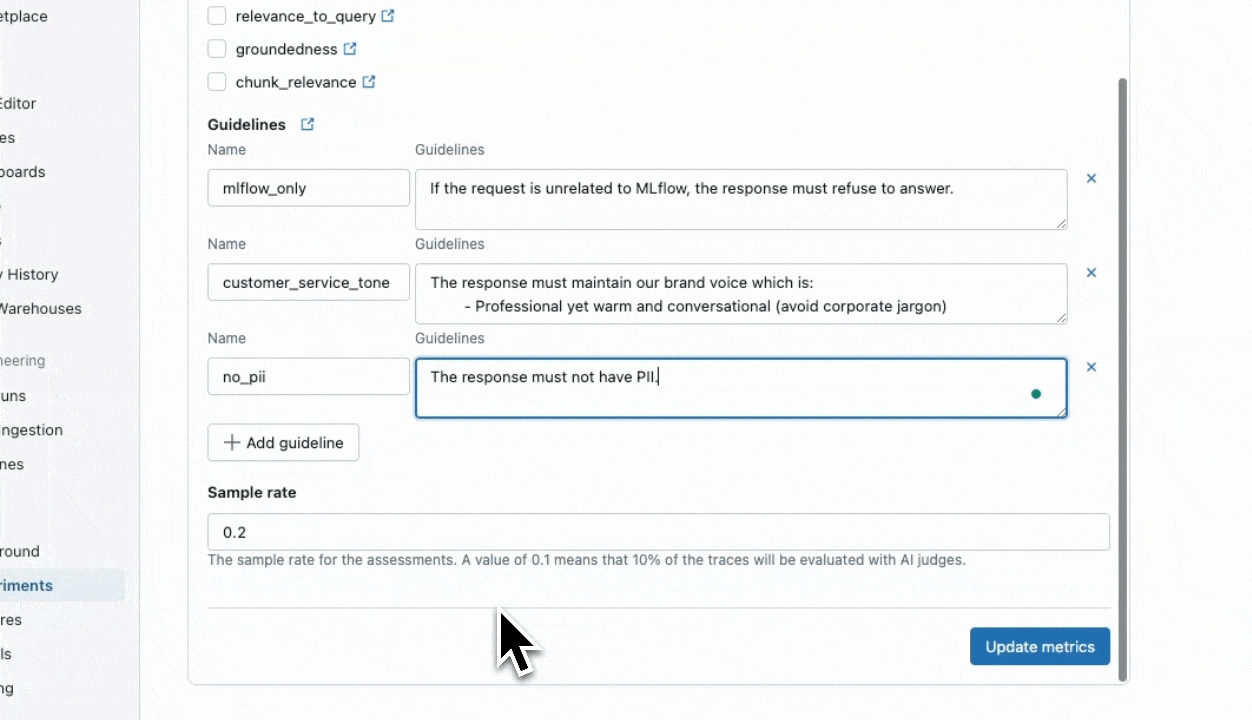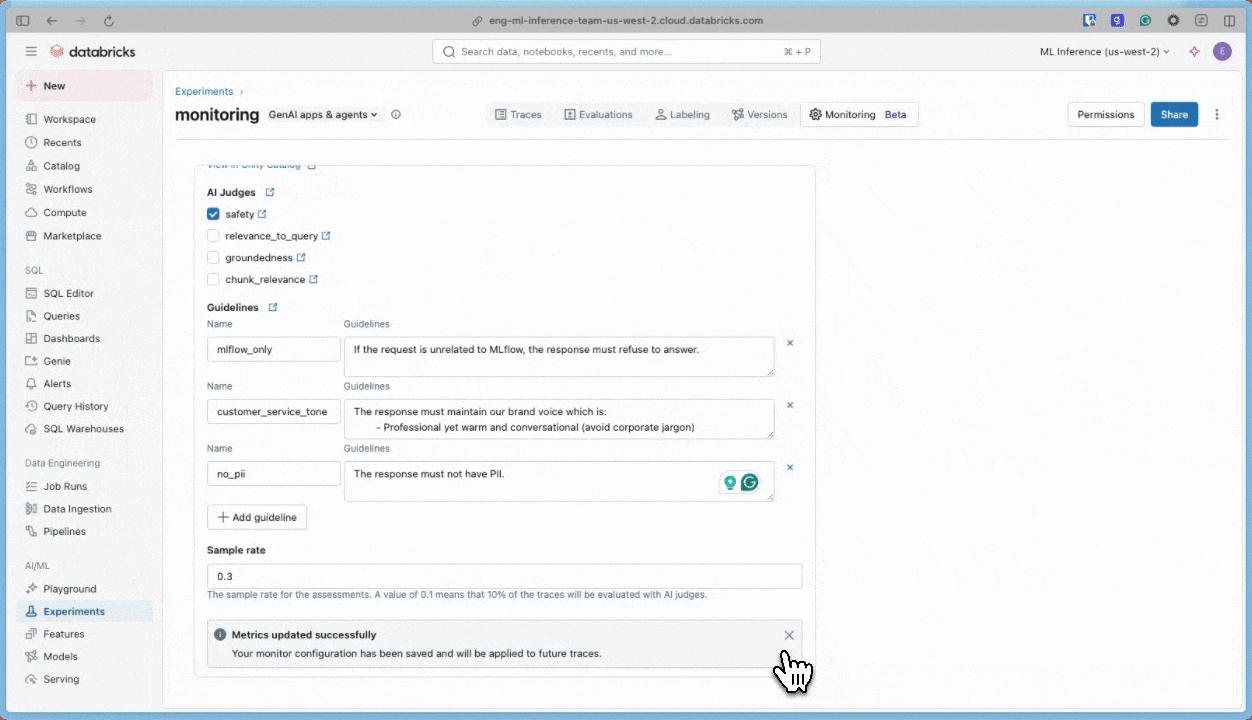
Verwenden des SDK
# These packages are automatically installed with mlflow[databricks]
from databricks.agents.monitoring import update_external_monitor, get_external_monitor
import os
config = get_external_monitor(experiment_id=os.environ["MLFLOW_EXPERIMENT_ID"])
print(config)
external_monitor = update_external_monitor(
# You must pass the experiment_id of the experiment you want to update.
experiment_id=os.environ["MLFLOW_EXPERIMENT_ID"],
# Change to a Unity Catalog schema where you have CREATE TABLE permissions.
assessments_config=AssessmentsSuiteConfig(
sample=1.0, # sampling rate
assessments=[
# Predefined scorers "safety", "groundedness", "relevance_to_query", "chunk_relevance"
BuiltinJudge(name="safety"), # or {'name': 'safety'}
BuiltinJudge(
name="groundedness", sample_rate=0.4
), # or {'name': 'groundedness', 'sample_rate': 0.4}
BuiltinJudge(
name="relevance_to_query"
), # or {'name': 'relevance_to_query'}
BuiltinJudge(name="chunk_relevance"), # or {'name': 'chunk_relevance'}
# Guidelines can refer to the request and response.
GuidelinesJudge(
guidelines={
# You can have any number of guidelines, each defined as a key-value pair.
"mlflow_only": [
"If the request is unrelated to MLflow, the response must refuse to answer."
], # Must be an array of strings
"customer_service_tone": [
"""The response must maintain our brand voice which is:
- Professional yet warm and conversational (avoid corporate jargon)
- Empathetic, acknowledging emotional context before jumping to solutions
- Proactive in offering help without being pushy
Specifically:
- If the customer expresses frustration, anger, or disappointment, the first sentence must acknowledge their emotion
- The response must use "I" statements to take ownership (e.g., "I understand" not "We understand")
- The response must avoid phrases that minimize concerns like "simply", "just", or "obviously"
- The response must end with a specific next step or open-ended offer to help, not generic closings"""
],
}
),
],
),
)
print(external_monitor)
Schritt 4. Verwenden von Überwachungsergebnissen
Der Überwachungsauftrag dauert ca. 15 - 30 Minuten, bis er zum ersten Mal ausgeführt wird. Nach der ersten Ausführung wird sie alle 15 Minuten ausgeführt. Beachten Sie, dass die Aufgabe zusätzliche Zeit in Anspruch nehmen kann, wenn Sie über ein großes Volumen an Produktionstraffic verfügen.
Jedes Mal, wenn der Auftrag ausgeführt wird, passiert Folgendes:
- Führt jeden Scorer für das Beispiel von Ablaufverfolgungen aus.
- Wenn Sie unterschiedliche Samplingraten pro Scorer haben, versucht der Überwachungsauftrag, so viele der gleichen Ablaufverfolgungen wie möglich zu erfassen. Wenn beispielsweise Scorer A eine Samplingrate von 20% hat und Scorer B eine Samplingrate von 40% hat, werden die gleichen 20% Spuren für A und B verwendet.
- Fügt das Feedback des Scorers zu jedem Protokoll im MLflow-Versuch hinzu.
- In die in Schritt 1 konfigurierte Delta-Tabelle wird eine Kopie aller Ablaufverfolgungen (nicht nur der stichprobenartigen) geschrieben.
Sie können die Überwachungsergebnisse mithilfe der Registerkarte "Überwachung" im MLflow-Experiment anzeigen. Alternativ können Sie die Traces in der generierten Delta-Tabelle mit SQL oder Spark abfragen.
Nächste Schritte
Fahren Sie mit diesen empfohlenen Aktionen und Lernprogrammen fort.
- Verwenden von Produktionsablaufverfolgungen zur Verbesserung der Qualität Ihrer App – Erstellen einer semantischen Auswertung mithilfe von LLMs
- Erstellen Sie Auswertungsdatensets – Verwenden Sie die Ergebnisse der Überwachung, um schlecht funktionierende Spuren in Auswertungsdatensets zusammenzustellen und deren Qualität zu verbessern.
Referenzhandbücher
In dieser Anleitung finden Sie ausführliche Dokumentation zu Konzepten und Features.
- Produktionsüberwachung - Tiefer Einblick in die Produktionsüberwachungs-SDKs