Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Sie können Databricks-Notizbücher orchestrieren und Code mithilfe von Lakeflow Jobs, dbutils.notebook.run(), Workspace-Dateien und %run modularisieren. Wählen Sie je nach Ihrem Bedarf an Terminplanung, Parameterübergabe und Versionskontrolle eine Methode aus.
Orchestrierungs- und Code-Modularisierungsmethoden
In der folgenden Tabelle werden die methoden verglichen, die zum Orchestrieren von Notizbüchern und zum Modularisieren von Code in Notizbüchern verfügbar sind.
| Methode | Anwendungsfall | Hinweise |
|---|---|---|
| Lakeflow-Aufträge | Notebook-Orchestrierung (empfohlen) | Empfohlene Methode für die Orchestrierung von Notebooks. Unterstützt komplexe Workflows mit Vorgangsabhängigkeiten, Terminplanungen und Triggern. Bietet einen robusten und skalierbaren Ansatz für Produktionsworkloads, erfordert jedoch Setup und Konfiguration. |
| dbutils.notebook.run() | Notebook-Orchestrierung | Verwenden Sie dbutils.notebook.run(), wenn Jobs Ihren Anwendungsfall nicht unterstützen können, z. B. ein Notebook anhand einer Metadatendatei dynamisch auszuführen (metadatengesteuertes ETL).Startet für jeden Aufruf einen neuen kurzlebigen Auftrag, was den Mehraufwand erhöhen kann und keine erweiterten Planungsfeatures bietet. |
| Arbeitsbereichsdateien | Code-Modularisierung (empfohlen) | Empfohlene Methode zum Modularisieren von Code. Modularisieren Sie Code in wiederverwendbare Codedateien, die im Arbeitsbereich gespeichert sind. Unterstützt die Versionssteuerung mit Repos und Integration mit IDEs, um das Debuggen und Komponententests zu verbessern. Erfordert zusätzliche Einrichtung zum Verwalten von Dateipfaden und Abhängigkeiten. |
| %run | Code-Modularisierung | Verwenden Sie %run, wenn Sie nicht auf Arbeitsbereichsdateien zugreifen können.Importieren Sie Funktionen oder Variablen aus anderen Notizbüchern, indem Sie sie inline ausführen. Nützlich für die Prototyperstellung, kann aber zu eng gekoppelten Code führen, der schwieriger zu verwalten ist. Unterstützt keine Parameterübergabe oder Versionssteuerung. |
%run Vs. dbutils.notebook.run()
Mit dem Befehl %run können Sie ein anderes Notebook in ein Notebook einbeziehen. Sie können mit %run Ihren Code modularisieren, indem Sie unterstützende Funktionen in einem separaten Notizbuch ablegen. Sie können damit auch Notebooks verketten, die die Schritte in einer Analyse implementieren. Wenn Sie %run verwenden, wird das aufgerufene Notebook sofort ausgeführt, und die darin definierten Funktionen und Variablen werden im aufrufenden Notebook verfügbar.
Die dbutils.notebook API ergänzt %run , da Sie Parameter an ein Notizbuch übergeben und diese zurückgeben können. Dadurch können Sie komplexe Workflows und Pipelines mit Abhängigkeiten erstellen. Sie können beispielsweise eine Liste von Dateien in einem Verzeichnis abrufen und die Namen an ein anderes Notizbuch übergeben, was mit %run nicht möglich ist. Sie können auch if-then-else-Workflows basierend auf Rückgabewerten erstellen.
Im Gegensatz zu %run startet die dbutils.notebook.run()-Methode einen neuen Auftrag zum Ausführen des Notebooks.
Wie alle dbutils-APIs sind diese Methoden nur in Python und Scala verfügbar. Sie können jedoch mithilfe von dbutils.notebook.run() ein R-Notebook aufrufen.
Verwenden von %run zum Importieren eines Notebooks
In diesem Beispiel wird im ersten Notebook die Funktion reverse definiert, die im zweiten Notebook verfügbar ist, nachdem Sie den Magic-Befehl %run zum Ausführen von shared-code-notebook verwendet haben.

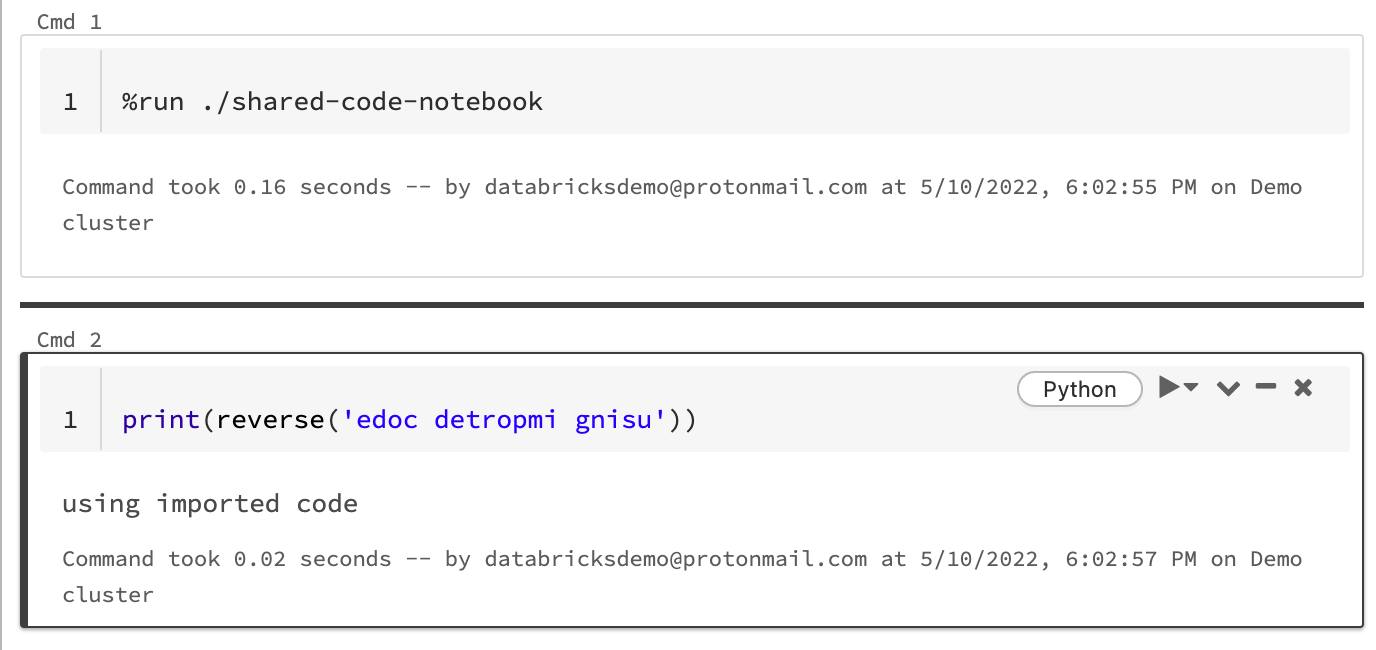
Da sich beide Notebooks im selben Verzeichnis im Arbeitsbereich befinden, verwenden Sie das Präfix ./ in ./shared-code-notebook, um anzugeben, dass der Pfad relativ zum aktuell ausgeführten Notebook aufgelöst werden soll. Sie können Notebooks in Verzeichnissen organisieren (z. B. %run ./dir/notebook) oder einen absoluten Pfad wie %run /Users/username@organization.com/directory/notebook angeben.
Hinweis
-
%runmuss sich in einer eigenen Zelle befinden, da das gesamte Notebook inline ausgeführt wird. - Sie können nicht
%runverwenden, um eine Python-Datei auszuführen undimportdie in dieser Datei definierten Entitäten in ein Notizbuch zu importieren. Informationen zum Importieren aus einer Python Datei finden Sie unter Modularize your code using files. Oder packen Sie die Datei in eine Python-Bibliothek, erstellen Sie eine Azure Databricks library von dieser Python-Bibliothek, und installieren Sie die Bibliothek in den Cluster, in dem Sie das Notebook ausführen. - Wenn Sie
%runverwenden, um ein Notebook auszuführen, das Widgets enthält, wird das angegebene Notebook standardmäßig mit den Standardwerten des Widgets ausgeführt. Sie können auch Werte an Widgets übergeben; siehe Verwenden von Databricks-Widgets mit %run.
Verwenden Sie dbutils.notebook.run, um einen neuen Auftrag zu starten
Führt ein Notebook aus und gibt dessen EXIT-Wert zurück. Die Methode startet einen kurzlebigen Auftrag, der sofort ausgeführt wird.
In der dbutils.notebook-API stehen die Methoden run und exit zur Verfügung. Sowohl Parameter als auch Rückgabewerte müssen Zeichenfolgen sein.
run(path: String, timeout_seconds: int, arguments: Map): String
Der timeout_seconds Parameter steuert das Timeout der Ausführung (0 bedeutet kein Timeout). Der Aufruf an run löst eine Ausnahme aus, wenn er nicht innerhalb des angegebenen Zeitraums abgeschlossen wird. Wenn Azure Databricks für mehr als 10 Minuten ausfällt, schlägt die Ausführung des Notizbuchs unabhängig von timeout_seconds fehl.
Der Parameter arguments legt die Widgetwerte des Zielnotebooks fest. Wenn das von Ihnen ausgeführte Notebook über ein Widget mit dem Namen A verfügt und Sie das Schlüssel-Wert-Paar ("A": "B") als Teil der Argumente an den Aufruf von run() übergeben, wird "B" beim Abrufen des Werts des Widgets A zurückgegeben. Sie finden die Anweisungen zum Erstellen und Arbeiten mit Widgets auf der Seite "Databricks Widgets ".
Hinweis
- Der Parameter
argumentsakzeptiert nur lateinische Zeichen (ASCII-Zeichensatz). Die Verwendung von Nicht-ASCII-Zeichen führt zu einem Fehler. - Aufträge, die unter Verwendung der
dbutils.notebook-API erstellt werden, müssen innerhalb von maximal 30 Tagen abgeschlossen werden.
Verwendung von run
Python
dbutils.notebook.run("notebook-name", 60, {"argument": "data", "argument2": "data2", ...})
Scala
dbutils.notebook.run("notebook-name", 60, Map("argument" -> "data", "argument2" -> "data2", ...))
Übergeben von strukturierten Daten zwischen Notizbüchern
In diesem Abschnitt wird veranschaulicht, wie strukturierte Daten zwischen Notebooks übergeben werden.
Python
# Example 1 - returning data through temporary views.
# You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
# return a name referencing data stored in a temporary view.
## In callee notebook
spark.range(5).toDF("value").createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
# Example 2 - returning data through DBFS.
# For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
## In callee notebook
dbutils.fs.rm("/tmp/results/my_data", recurse=True)
spark.range(5).toDF("value").write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(spark.read.format("parquet").load(returned_table))
# Example 3 - returning JSON data.
# To return multiple values, you can use standard JSON libraries to serialize and deserialize results.
## In callee notebook
import json
dbutils.notebook.exit(json.dumps({
"status": "OK",
"table": "my_data"
}))
## In caller notebook
import json
result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
print(json.loads(result))
Scala
Serverlose Kompatibilität Databricks empfiehlt, sich von RDD-APIs zu entfernen, da sie nicht mit der Serverlosen Computearchitektur von Databricks kompatibel sind. Verwenden Sie stattdessen die DataFrame-API.
// Example 1 - returning data through temporary views.
// You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
// return a name referencing data stored in a temporary view.
/** In callee notebook */
sc.parallelize(1 to 5).toDF().createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
val global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
// Example 2 - returning data through DBFS.
// For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
/** In callee notebook */
dbutils.fs.rm("/tmp/results/my_data", recurse=true)
sc.parallelize(1 to 5).toDF().write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(sqlContext.read.format("parquet").load(returned_table))
// Example 3 - returning JSON data.
// To return multiple values, use standard JSON libraries to serialize and deserialize results.
/** In callee notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
// Exit with json
dbutils.notebook.exit(jsonMapper.writeValueAsString(Map("status" -> "OK", "table" -> "my_data")))
/** In caller notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
val result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
println(jsonMapper.readValue[Map[String, String]](result))
Fehlerbehandlung
In diesem Abschnitt wird die Behandlung von Fehlern veranschaulicht.
Python
# Errors throw a WorkflowException.
def run_with_retry(notebook, timeout, args = {}, max_retries = 3):
num_retries = 0
while True:
try:
return dbutils.notebook.run(notebook, timeout, args)
except Exception as e:
if num_retries > max_retries:
raise e
else:
print("Retrying error", e)
num_retries += 1
run_with_retry("LOCATION_OF_CALLEE_NOTEBOOK", 60, max_retries = 5)
Scala
// Errors throw a WorkflowException.
import com.databricks.WorkflowException
// Since dbutils.notebook.run() is just a function call, you can retry failures using standard Scala try-catch
// control flow. Here, we show an example of retrying a notebook a number of times.
def runRetry(notebook: String, timeout: Int, args: Map[String, String] = Map.empty, maxTries: Int = 3): String = {
var numTries = 0
while (true) {
try {
return dbutils.notebook.run(notebook, timeout, args)
} catch {
case e: WorkflowException if numTries < maxTries =>
println("Error, retrying: " + e)
}
numTries += 1
}
"" // not reached
}
runRetry("LOCATION_OF_CALLEE_NOTEBOOK", timeout = 60, maxTries = 5)
Gleichzeitiges Ausführen mehrerer Notebooks
Sie können mehrere Notizbücher gleichzeitig ausführen, indem Sie Standardkonstrukte scala und Python wie Threads (Scala, Python) und Futures (Scala, Python) verwenden. Die Beispielnotebooks veranschaulichen die Nutzung dieser Konstrukte.
- Laden Sie die folgenden vier Notizbücher herunter. Die Notebooks wurden in Scala geschrieben.
- Importieren Sie die Notebooks in einen einzelnen Ordner im Arbeitsbereich.
- Führen Sie das Notebook gleichzeitig aus.