Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Von Bedeutung
Lakebase Autoscaling ist die neueste Version von Lakebase mit automatischer Berechnung, Skalierung bis Null, Verzweigung und sofortiger Wiederherstellung. Unterstützte Regionen finden Sie unter "Verfügbarkeit der Region". Wenn Sie ein Lakebase Provisioned-Benutzer sind, lesen Sie Lakebase Provisioned.
Lakebase Postgres Autoscaling ist eine vollständig verwaltete Postgres-Datenbank, die für jede Anwendung erstellt wird, die eine Onlinetransaktionsverarbeitung (OLTP) und eine Datenverarbeitung mit geringer Latenz erfordert. Es ist in die Databricks-Plattform integriert, sodass Sie Transaktionsanwendungen in Echtzeit zusammen mit Ihren Analyseworkloads erstellen können.
Lakebase Postgres Autoscaling kombiniert die Zuverlässigkeit und Vertrautheit von Postgres mit modernen Datenbankfunktionen, einschließlich Autoscaling, Skalierung auf Null, Branching und sofortiger Wiederherstellung. Diese Features ermöglichen flexible Entwicklungsworkflows, kosteneffiziente Vorgänge und schnelle Iterationen.
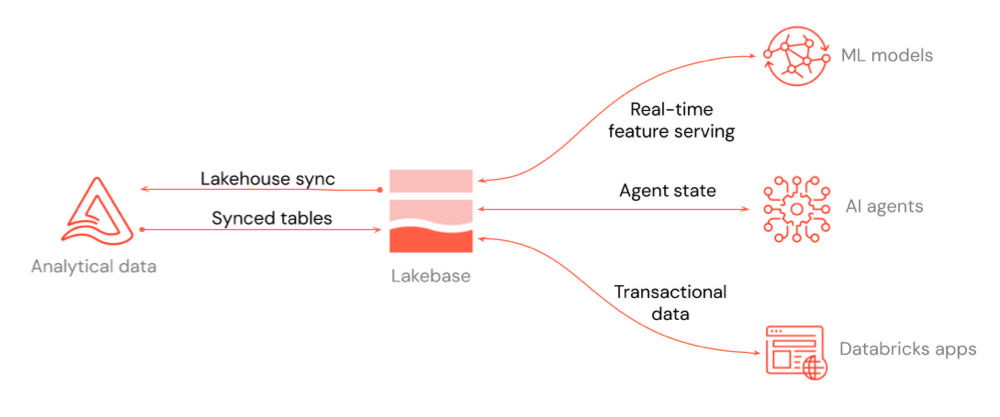
Das Diagramm zeigt, wie Lakebase in die restliche Plattform integriert wird: Bereitstellung von Features in Echtzeit für ML-Modelle und Feature-Speicher, Agentenzustand für KI-Agenten und Transaktionsdaten für Databricks-Apps oder jede beliebige Anwendung, mit der Sie eine Verbindung herstellen.
Sie können Daten in beide Richtungen zwischen Ihrem Lakehouse und Lakebase verschieben. Synchronisierte Tabellen verschieben Daten aus dem Seehaus in Lakebase, damit Ihre Anwendungen sie mit geringer Latenz abfragen können.
Beispielanwendungsfälle und Arbeitsauslastungstypen
Im Folgenden finden Sie nur einige Beispiele für die vielen Möglichkeiten, wie Sie eine OLTP-Postgres-Datenbank wie Lakebase in verschiedenen Branchen verwenden können: personalisierte Empfehlungen und Angebote für E-Commerce und Einzelhandel, klinische Testdaten und Empfehlungssysteme im Gesundheitswesen, automatisierte Handels- und Streaminganalysen in Finanzdienstleistungen sowie Maschinentelemetrie- und Wartungsworkflows in der Fertigung.
Allgemeine Workloadtypen für OLTP-Datenbanken können Folgendes umfassen:
- Datenbereitstellung: Bereitstellen von Erkenntnissen aus goldenen Tabellen zu Anwendungen mit geringer Latenz und hohem QPS.
- Store-Anwendungsstatus: Verwalten des Workflow- und Agentstatus in einem Transaktionsdatenspeicher.
- Feature-Serving: Bereitstellung von featurisierten Daten mit geringer Latenz für ML-Modelle.
Databricks-Integration
Im obigen Diagramm werden drei wichtige Integrationsanwendungsfälle hervorgehoben:
- Echtzeit-Feature-Bereitstellung: Verwenden Sie Lakebase-Projekte als Online-Store für ML-Modelle und den Feature Store, damit Sie featurisierte Daten mit geringer Latenz bereitstellen können. Siehe Online Feature Store (Lakebase) und Feature Serving.
- Agentstatus für KI-Agents: Speichern und verwalten Sie den Zustand für KI-Agents in einer Transaktionsdatenbank, sodass Unterhaltungen und Workflowkontext über Anforderungen hinweg beibehalten werden.
- Transaktionsdaten für Anwendungen: Speichern Sie Daten für Databricks-Apps oder eine beliebige Anwendung, die Sie mit Lakebase verbinden. Fügen Sie für Databricks-Apps ein Lakebase-Projekt als App-Ressource hinzu. Siehe Hinzufügen einer Lakebase-Ressource zu einer Databricks-App.
Lakebase bereitgestellt
Lakebase Provisioned ist die erste Lakebase-Version, die bereitgestellte Computing-Ressourcen verwendet, die Sie manuell skalieren. Vorhandene bereitgestellte Instanzen werden weiterhin unterstützt. Die Entwicklung von Lakebase konzentriert sich auf das Autoscaling. Wenn Sie bereitgestellte Instanzen haben oder beide Optionen evaluieren, lesen Sie "Was ist Lakebase Provisioned? und Autoscaling by default".
Was ist ein Projekt?
Lakebase Autoscaling-Ressourcen sind in einer Projektstruktur organisiert. Ein Projekt ist der Container der obersten Ebene für Ihre Datenbankressourcen. Wenn Sie eine Datenbank für die automatische Skalierung der Lakebase erstellen, erstellen Sie ein Projekt. Das Projekt enthält Ihre Branches (Datenbankumgebungen), Rechner, Rollen und Datenbanken. Stellen Sie sich ein Projekt als Organisationseinheit für eine Anwendung oder Arbeitsauslastung vor. Sie können mehrere Projekte in einem Arbeitsbereich haben, jeweils mit eigenen Verzweigungen und Daten.
Organisieren von Projekten
Wenn Sie die Hierarchie von Objekten in einem Projekt verstehen, können Sie Ihre Ressourcen organisieren und verwalten:
Databricks Workspace
└── Project(s)
└── Branch(es)
├── Compute (primary R/W)
├── Read replica(s) (optional)
├── Role(s)
└── Database(s)
└── Schema(s)
Jede Ebene in der Hierarchie dient einem bestimmten Zweck:
| Object | Description |
|---|---|
| Project | Der Container der obersten Ebene für Ihre Datenbankressourcen. Ein Projekt enthält Verzweigungen, Datenbanken, Rollen und Computeressourcen. Siehe "Projekte verwalten". |
| Filiale | Eine isolierte Datenbankumgebung, die Speicher mit ihrem übergeordneten Zweig teilt. Jedes Projekt kann mehrere Verzweigungen enthalten. Siehe "Verzweigungen verwalten". |
| Berechnen | Der Postgres-Server, der eine Verzweigung unterstützt. Jede Niederlassung verfügt über eigene Rechner, die die Verarbeitungsleistung und den Arbeitsspeicher für Datenbankvorgänge bereitstellen. Siehe "Compute verwalten". |
| Datenbank | Eine standardmäßige Postgres-Datenbank innerhalb eines Zweigs. Jede Verzweigung kann mehrere Datenbanken mit eigenen Tabellen, Schemas und Daten enthalten. Siehe "Datenbanken verwalten". |
Grundlegendes zu Branches
Eines der leistungsstärksten Features von Lakebase Postgres ist die Verzweigung. Wie Git-Branches für Ihren Code ermöglichen es Branches, isolierte Datenbankumgebungen für die Entwicklung und das Testen zu erstellen – ohne die Produktion zu beeinflussen.
Warum dies wichtig ist: Herkömmliche Datenbankworkflows erfordern separate Entwicklungs- und Stagingserver, manuelle Datenaktualisierungen und sorgfältige Koordination. Mit Zweigniederlassungen können Sie:
- Erstellen sie sofort eine Entwicklungsumgebung mit Produktionsdaten
- Testen sie Schemaänderungen sicher, bevor Sie sie auf die Produktion anwenden
- Sich von Fehlern erholen, indem Verzweigungen von einem beliebigen Zeitpunkt aus erstellt werden.
- Zahlen Sie nur für die Daten, die Sie ändern, nicht für vollständige duplizierte Datenbanken
| Thema | Description |
|---|---|
| Filialen | Erfahren Sie, wie Zweigniederlassungen funktionieren, allgemeine Workflows und bewährte Methoden für Ihr Team. |
| Verwalten von Branches | Erstellen, Zurücksetzen und Löschen von Verzweigungen für Entwicklung und Tests. |
| Geschützte Branches | Schützen Sie Produktionszweige vor versehentlichen Änderungen und Löschungen. |
Kernkonzepte
Lakebase basiert auf mehreren wichtigen Innovationen, die sie von herkömmlichen Datenbanksystemen unterscheiden:
- Getrennte Berechnung und Speicher: Skalieren Sie Computeressourcen unabhängig vom Speicher für Kosteneffizienz und Flexibilität.
- Autoskalierung: Die Rechenleistung wird basierend auf der Workload-Nachfrage automatisch angepasst, mit Unterstützung für die Skalierung auf Null während Leerlaufzeiten.
- Copy-on-Write-Speicher: Ermöglicht die sofortige Verzweigungen, bei der Sie nur für Datenänderungen bezahlen, nicht für vollständige Duplikate.
- Sofortige Zeitpunktbezogene Operationen: Erstellen von Verzweigungen oder Wiederherstellen zu einem beliebigen Moment innerhalb des konfigurierten Wiederherstellungsfensters (2-30 Tagen)
Diese Konzepte arbeiten zusammen, um flexible Entwicklungsworkflows, kosteneffiziente Vorgänge und schnelle Wiederherstellung von Fehlern zu ermöglichen.
Eine ausführliche Erläuterung der einzelnen Kernkonzepte finden Sie unter "Kernkonzepte".