Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Von Bedeutung
Lakebase Autoscaling ist in den folgenden Regionen verfügbar: eastus, eastus2, centralus, southcentralus, westus, westus2, canadacentral, brazilsouth, northeurope, uksouth, westeurope, australiaeast, centralindia, southeastasia.
Lakebase Autoscaling ist die neueste Version von Lakebase mit automatischer Berechnung, Skalierung bis Null, Verzweigung und sofortiger Wiederherstellung. Wenn Sie ein Lakebase Provisioned-Benutzer sind, lesen Sie Lakebase Provisioned.
In diesem Leitfaden wird gezeigt, wie externe Anwendungen mit Lakebase Autoscaling mithilfe von Standard-Postgres-Treibern (psycopg, pgx, JDBC) mit OAuth-Tokenrotation verbunden werden. Sie verwenden das Azure Databricks SDK mit einem Dienstprinzipal und einem Verbindungspool, der beim Öffnen jeder neuen Verbindung aufruft generate_database_credential() , sodass Sie bei jeder Verbindung ein neues Token (60-Minuten-Lebensdauer) erhalten. Beispiele für Python, Java und Go. Für eine einfachere Einrichtung mit der automatischen Verwaltung von Anmeldeinformationen sollten Sie stattdessen Azure Databricks-Apps in Betracht ziehen.
Was Sie erstellen werden: Ein Verbindungsmuster, das die OAuth-Tokenrotation verwendet, um eine Verbindung mit Lakebase-Autocaling von einer externen Anwendung herzustellen, und überprüfen Sie dann, ob die Verbindung funktioniert.
Sie benötigen das Databricks SDK (Python v0.89.0+, Java v0.73.0+ oder Go v0.109.0+). Führen Sie die folgenden Schritte wie folgt aus:
:::tipp Andere Sprachen für Sprachen ohne Databricks SDK-Unterstützung (Node.js, Ruby, PHP, Elixir, Rust usw.), siehe Verbinden externer App mit Lakebase mithilfe der API. :::
Funktionsweise
Das Databricks SDK vereinfacht die OAuth-Authentifizierung, indem die Verwaltung von Arbeitsbereichstoken automatisch verarbeitet wird:
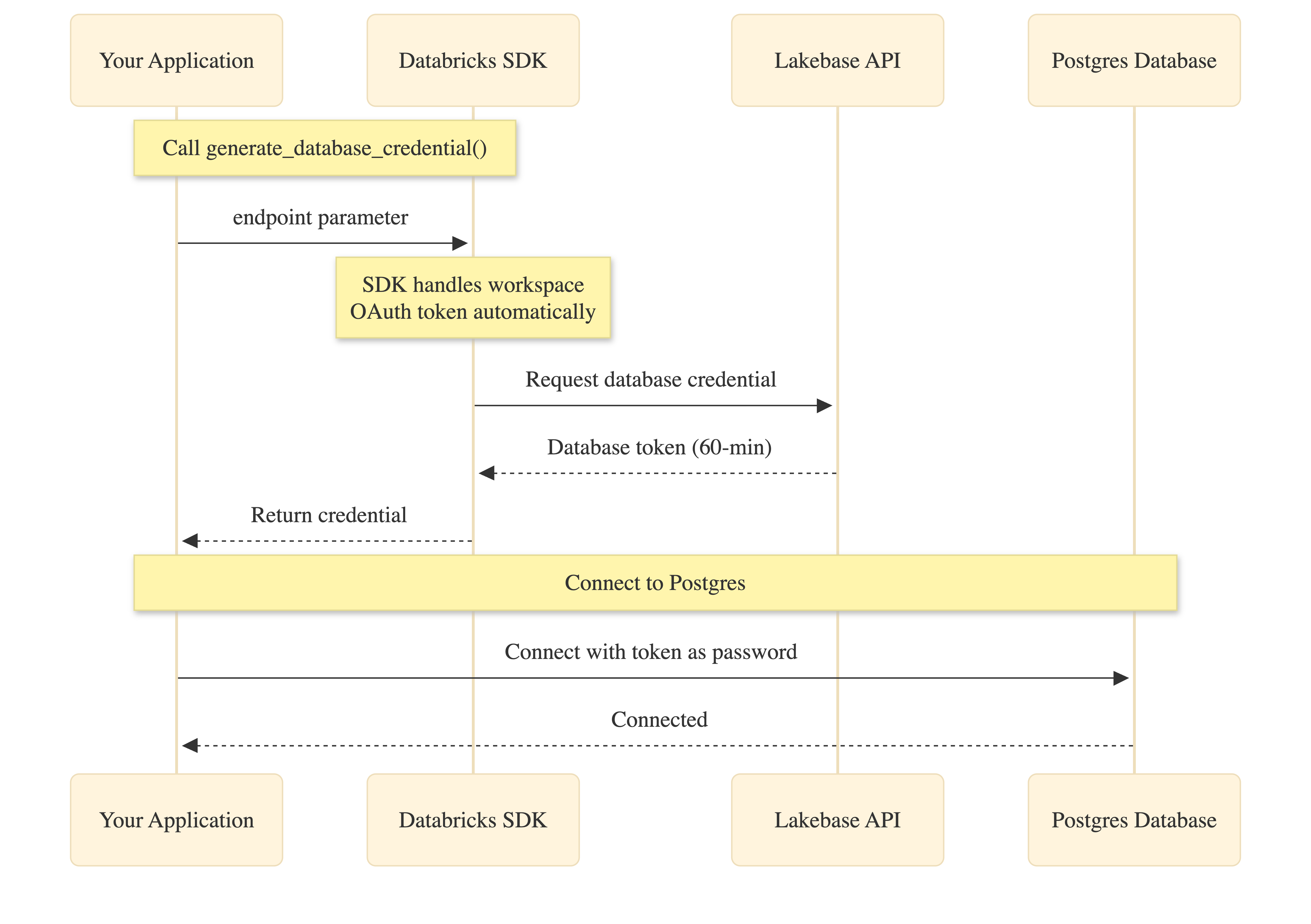
Ihre Anwendung ruft generate_database_credential() mit dem Endpunktparameter auf. Das SDK ruft das OAuth-Arbeitsbereichstoken intern ab (kein Code erforderlich), fordert die Datenbankanmeldeinformationen von der Lakebase-API an und gibt es an Ihre Anwendung zurück. Sie verwenden diese Anmeldeinformationen dann als Kennwort, wenn Sie eine Verbindung mit Postgres herstellen.
Sowohl das Arbeitsbereich-OAuth-Token als auch die Datenbankanmeldeinformationen laufen nach 60 Minuten ab. Verbindungspools behandeln die automatische Aktualisierung, indem beim Erstellen neuer Verbindungen generate_database_credential() aufgerufen wird.
1. Erstellen eines Service Principals mit dem OAuth-Geheimnis
Erstellen Sie einen Azure Databricks-Dienstprinzipal mit einem OAuth-Geheimnis. Vollständige Details finden Sie im Autorisieren des Dienstprinzipalzugriffs. Beachten Sie beim Erstellen einer externen App Folgendes:
- Legen Sie Ihren geheimen Schlüssel auf Ihre bevorzugte Lebensdauer fest, bis zu 730 Tage. Dadurch wird definiert, wie oft Sie das Geheimnis aktualisieren müssen, das zum Generieren von Datenbankanmeldeinformationen durch Rotation verwendet wird.
-
Aktivieren Sie "Arbeitsbereichszugriff" für den Dienstprinzipal (Einstellungen → Identität und Zugriff → Dienstprinzipale →
{name}Registerkarte "Konfigurationen" → →). Es ist erforderlich, um neue Datenbankanmeldeinformationen zu generieren. -
Notieren Sie sich die Client-ID (eine UUID). Sie verwenden sie beim Erstellen der passenden Postgres-Rolle in Ihrem App-Setup und für
PGUSER.
2. Erstellen einer Postgres-Rolle für den Dienstprinzipal
Die Lakebase-Benutzeroberfläche unterstützt nur kennwortbasierte Rollen. Erstellen Sie eine OAuth-Rolle im Lakebase SQL-Editor mithilfe der Client-ID aus Schritt 1 (nicht mit dem Anzeigenamen; Bei Rollennamen wird die Groß-/Kleinschreibung beachtet):
-- Enable the auth extension (if not already enabled)
CREATE EXTENSION IF NOT EXISTS databricks_auth;
-- Create OAuth role using the service principal client ID
SELECT databricks_create_role('{client-id}', 'SERVICE_PRINCIPAL');
-- Grant database permissions
GRANT CONNECT ON DATABASE databricks_postgres TO "{client-id}";
GRANT USAGE ON SCHEMA public TO "{client-id}";
GRANT SELECT, INSERT, UPDATE, DELETE ON ALL TABLES IN SCHEMA public TO "{client-id}";
ALTER DEFAULT PRIVILEGES IN SCHEMA public
GRANT SELECT, INSERT, UPDATE, DELETE ON TABLES TO "{client-id}";
Ersetzen Sie {client-id} durch die Dienstprinzipal-Client-ID. Siehe Erstellen von OAuth-Rollen.
3. Abrufen von Verbindungsdetails
Klicken Sie in Ihrem Projekt in der Lakebase-Konsole auf "Verbinden", wählen Sie "Verzweigung" und "Endpunkt" aus, und notieren Sie sich den Host, die Datenbank (in der Regel databricks_postgres) und den Endpunktnamen (Format: projects/<project-id>/branches/<branch-id>/endpoints/<endpoint-id>).
Oder verwenden Sie die CLI:
databricks postgres list-endpoints projects/<project-id>/branches/<branch-id>
Details finden Sie unter Verbindungszeichenfolgen .
4. Festlegen von Umgebungsvariablen
Legen Sie diese Umgebungsvariablen fest, bevor Sie Ihre Anwendung ausführen:
# Databricks workspace authentication
export DATABRICKS_HOST="https://your-workspace.databricks.com"
export DATABRICKS_CLIENT_ID="<service-principal-client-id>"
export DATABRICKS_CLIENT_SECRET="<your-oauth-secret>"
# Lakebase connection details (from step 3)
export ENDPOINT_NAME="projects/<project-id>/branches/<branch-id>/endpoints/<endpoint-id>"
export PGHOST="<endpoint-id>.database.<region>.cloud.databricks.com"
export PGDATABASE="databricks_postgres"
export PGUSER="<service-principal-client-id>" # Same UUID as step 1
export PGPORT="5432"
export PGSSLMODE="require" # Python only
5. Hinzufügen von Verbindungscode
Python
In diesem Beispiel wird psycopg3 mit einer benutzerdefinierten Verbindungsklasse verwendet, die ein neues Token generiert, wenn der Pool jede neue Verbindung erstellt.
import os
from databricks.sdk import WorkspaceClient
import psycopg
from psycopg_pool import ConnectionPool
# Initialize Databricks SDK
workspace_client = None
def _get_workspace_client():
"""Get or create the workspace client for OAuth."""
global workspace_client
if workspace_client is None:
workspace_client = WorkspaceClient(
host=os.environ["DATABRICKS_HOST"],
client_id=os.environ["DATABRICKS_CLIENT_ID"],
client_secret=os.environ["DATABRICKS_CLIENT_SECRET"],
)
return workspace_client
def _get_endpoint_name():
"""Get endpoint name from environment."""
name = os.environ.get("ENDPOINT_NAME")
if not name:
raise ValueError(
"ENDPOINT_NAME must be set (format: projects/<id>/branches/<id>/endpoints/<id>)"
)
return name
class OAuthConnection(psycopg.Connection):
"""Custom connection class that generates a fresh OAuth token per connection."""
@classmethod
def connect(cls, conninfo="", **kwargs):
endpoint_name = _get_endpoint_name()
client = _get_workspace_client()
# Generate database credential (tokens are workspace-scoped)
credential = client.postgres.generate_database_credential(
endpoint=endpoint_name
)
kwargs["password"] = credential.token
return super().connect(conninfo, **kwargs)
# Create connection pool with OAuth token rotation
def get_connection_pool():
"""Get or create the connection pool."""
database = os.environ["PGDATABASE"]
user = os.environ["PGUSER"]
host = os.environ["PGHOST"]
port = os.environ.get("PGPORT", "5432")
sslmode = os.environ.get("PGSSLMODE", "require")
conninfo = f"dbname={database} user={user} host={host} port={port} sslmode={sslmode}"
return ConnectionPool(
conninfo=conninfo,
connection_class=OAuthConnection,
min_size=1,
max_size=10,
open=True,
)
# Use the pool in your application
pool = get_connection_pool()
with pool.connection() as conn:
with conn.cursor() as cur:
cur.execute("SELECT current_user, current_database()")
print(cur.fetchone())
Abhängigkeiten:databricks-sdk>=0.89.0, psycopg[binary,pool]>=3.1.0
Go
In diesem Beispiel wird pgxpool mit einem BeforeConnect-Rückruf verwendet, der für jede neue Verbindung ein neues Token generiert.
package main
import (
"context"
"fmt"
"log"
"os"
"time"
"github.com/databricks/databricks-sdk-go"
"github.com/databricks/databricks-sdk-go/service/postgres"
"github.com/jackc/pgx/v5"
"github.com/jackc/pgx/v5/pgxpool"
)
func createConnectionPool(ctx context.Context) (*pgxpool.Pool, error) {
// Initialize Databricks workspace client
w, err := databricks.NewWorkspaceClient(&databricks.Config{
Host: os.Getenv("DATABRICKS_HOST"),
ClientID: os.Getenv("DATABRICKS_CLIENT_ID"),
ClientSecret: os.Getenv("DATABRICKS_CLIENT_SECRET"),
})
if err != nil {
return nil, err
}
// Build connection string
connStr := fmt.Sprintf("host=%s port=%s dbname=%s user=%s sslmode=require",
os.Getenv("PGHOST"),
os.Getenv("PGPORT"),
os.Getenv("PGDATABASE"),
os.Getenv("PGUSER"))
config, err := pgxpool.ParseConfig(connStr)
if err != nil {
return nil, err
}
// Configure pool
config.MaxConns = 10
config.MinConns = 1
config.MaxConnLifetime = 45 * time.Minute
config.MaxConnIdleTime = 15 * time.Minute
// Generate fresh token for each new connection
config.BeforeConnect = func(ctx context.Context, connConfig *pgx.ConnConfig) error {
credential, err := w.Postgres.GenerateDatabaseCredential(ctx,
postgres.GenerateDatabaseCredentialRequest{
Endpoint: os.Getenv("ENDPOINT_NAME"),
})
if err != nil {
return err
}
connConfig.Password = credential.Token
return nil
}
return pgxpool.NewWithConfig(ctx, config)
}
func main() {
ctx := context.Background()
pool, err := createConnectionPool(ctx)
if err != nil {
log.Fatal(err)
}
defer pool.Close()
var user, database string
err = pool.QueryRow(ctx, "SELECT current_user, current_database()").Scan(&user, &database)
if err != nil {
log.Fatal(err)
}
fmt.Printf("Connected as: %s to database: %s\n", user, database)
}
Abhängigkeiten: Databricks SDK für Go v0.109.0+ (github.com/databricks/databricks-sdk-go), pgx-Treiber (github.com/jackc/pgx/v5)
Hinweis: Der BeforeConnect Rückruf stellt neue OAuth-Token für jede neue Verbindung sicher, wobei die automatische Tokenrotation für lange ausgeführte Anwendungen verarbeitet wird.
Java
In diesem Beispiel wird JDBC mit HikariCP und einer benutzerdefinierten Datenquelle verwendet, die ein neues Token generiert, wenn der Pool jede neue Verbindung erstellt.
import java.sql.*;
import javax.sql.DataSource;
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.core.DatabricksConfig;
import com.databricks.sdk.service.postgres.*;
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
public class LakebaseConnection {
private static WorkspaceClient workspaceClient() {
String host = System.getenv("DATABRICKS_HOST");
String clientId = System.getenv("DATABRICKS_CLIENT_ID");
String clientSecret = System.getenv("DATABRICKS_CLIENT_SECRET");
return new WorkspaceClient(new DatabricksConfig()
.setHost(host)
.setClientId(clientId)
.setClientSecret(clientSecret));
}
private static DataSource createDataSource() {
WorkspaceClient w = workspaceClient();
String endpointName = System.getenv("ENDPOINT_NAME");
String host = System.getenv("PGHOST");
String database = System.getenv("PGDATABASE");
String user = System.getenv("PGUSER");
String port = System.getenv().getOrDefault("PGPORT", "5432");
String jdbcUrl = "jdbc:postgresql://" + host + ":" + port +
"/" + database + "?sslmode=require";
// DataSource that returns a new connection with a fresh token (tokens are workspace-scoped)
DataSource tokenDataSource = new DataSource() {
@Override
public Connection getConnection() throws SQLException {
DatabaseCredential cred = w.postgres().generateDatabaseCredential(
new GenerateDatabaseCredentialRequest().setEndpoint(endpointName)
);
return DriverManager.getConnection(jdbcUrl, user, cred.getToken());
}
@Override
public Connection getConnection(String u, String p) {
throw new UnsupportedOperationException();
}
// ... other DataSource methods (getLogWriter, etc.)
};
// Wrap in HikariCP for connection pooling
HikariConfig config = new HikariConfig();
config.setDataSource(tokenDataSource);
config.setMaximumPoolSize(10);
config.setMinimumIdle(1);
// Recycle connections before 60-min token expiry
config.setMaxLifetime(45 * 60 * 1000L);
return new HikariDataSource(config);
}
public static void main(String[] args) throws SQLException {
DataSource pool = createDataSource();
try (Connection conn = pool.getConnection();
Statement st = conn.createStatement();
ResultSet rs = st.executeQuery("SELECT current_user, current_database()")) {
if (rs.next()) {
System.out.println("User: " + rs.getString(1));
System.out.println("Database: " + rs.getString(2));
}
}
}
}
Abhängigkeiten: Databricks SDK für Java v0.73.0+ (com.databricks:databricks-sdk-java), PostgreSQL JDBC-Treiber (org.postgresql:postgresql), HikariCP (com.zaxxer:HikariCP)
6. Führen Sie die Verbindung aus, und überprüfen Sie sie.
Python
Abhängigkeiten installieren:
pip install databricks-sdk psycopg[binary,pool]
Ausführen:
# Save all the code from step 5 (above) as db.py, then run:
from db import get_connection_pool
pool = get_connection_pool()
with pool.connection() as conn:
with conn.cursor() as cur:
cur.execute("SELECT current_user, current_database()")
print(cur.fetchone())
Erwartete Ausgabe:
('c00f575e-d706-4f6b-b62c-e7a14850571b', 'databricks_postgres')
Wenn current_user mit Ihrer Dienstprinzipal-Client-ID aus Schritt 1 übereinstimmt, funktioniert die OAuth-Tokenrotation.
Java
Hinweis: Dabei wird davon ausgegangen, dass Sie über ein Maven-Projekt mit den Abhängigkeiten aus dem obigen Java-Beispiel in Ihrem pom.xmlBeispiel verfügen.
Abhängigkeiten installieren:
mvn install
Ausführen:
mvn exec:java -Dexec.mainClass="com.example.LakebaseConnection"
Erwartete Ausgabe:
User: c00f575e-d706-4f6b-b62c-e7a14850571b
Database: databricks_postgres
Wenn der Benutzer Ihre Dienstprinzipalclient-ID aus Schritt 1 abgleicht, funktioniert die OAuth-Tokenrotation.
Go
Abhängigkeiten installieren:
go mod init myapp
go get github.com/databricks/databricks-sdk-go
go get github.com/jackc/pgx/v5
Ausführen:
go run main.go
Erwartete Ausgabe:
Connected as: c00f575e-d706-4f6b-b62c-e7a14850571b to database: databricks_postgres
Wenn der Benutzer Ihre Dienstprinzipalclient-ID aus Schritt 1 abgleicht, funktioniert die OAuth-Tokenrotation.
Hinweis: Die erste Verbindung nach dem Leerlauf kann mehr Zeit in Anspruch nehmen, da die Rechenkapazitäten des Lakebase-Autoscaling von Null beginnen.
Problembehandlung
| Fehler | Reparatur |
|---|---|
| "API ist für Benutzer ohne Arbeitsbereichszugriffsberechtigung deaktiviert" | Aktivieren Sie "Arbeitsbereichszugriff" für den Dienstprinzipal (Schritt 1). |
| "Rolle ist nicht vorhanden" oder Authentifizierung schlägt fehl. | Erstellen Sie die OAuth-Rolle über SQL (Schritt 2) und nicht über die Benutzeroberfläche. |
| "Verbindung verweigert" oder "Endpunkt nicht gefunden" |
ENDPOINT_NAMEFormat verwendenprojects/<id>/branches/<id>/endpoints/<id>; Endpunkt-ID befindet sich im Host. |
| "Ungültiger Benutzer" oder "Benutzer nicht gefunden" | Stellen Sie PGUSER auf die Dienstprinzipal-Client-ID (UUID) und nicht auf den Anzeigenamen ein. |