Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Von Bedeutung
Lakebase Autoscaling ist die neueste Version von Lakebase mit automatischer Berechnung, Skalierung bis Null, Verzweigung und sofortiger Wiederherstellung. Unterstützte Regionen finden Sie unter "Verfügbarkeit der Region". Wenn Sie ein Lakebase Provisioned-Benutzer sind, lesen Sie Lakebase Provisioned.
Hochverfügbarkeit kombiniert eine primäre Lese-/Schreib-Compute-Instanz mit einer oder mehreren sekundären Berechnungseinheiten, die über Verfügbarkeitszonen verteilt sind. Wenn die primäre Instanz nicht verfügbar ist, wird automatisch eine sekundäre Compute-Instanz befördert, und Ihre Anwendung wird ab der letzten zugesicherten Transaktion fortgesetzt. Ihre Verbindungszeichenfolge bleibt unverändert.
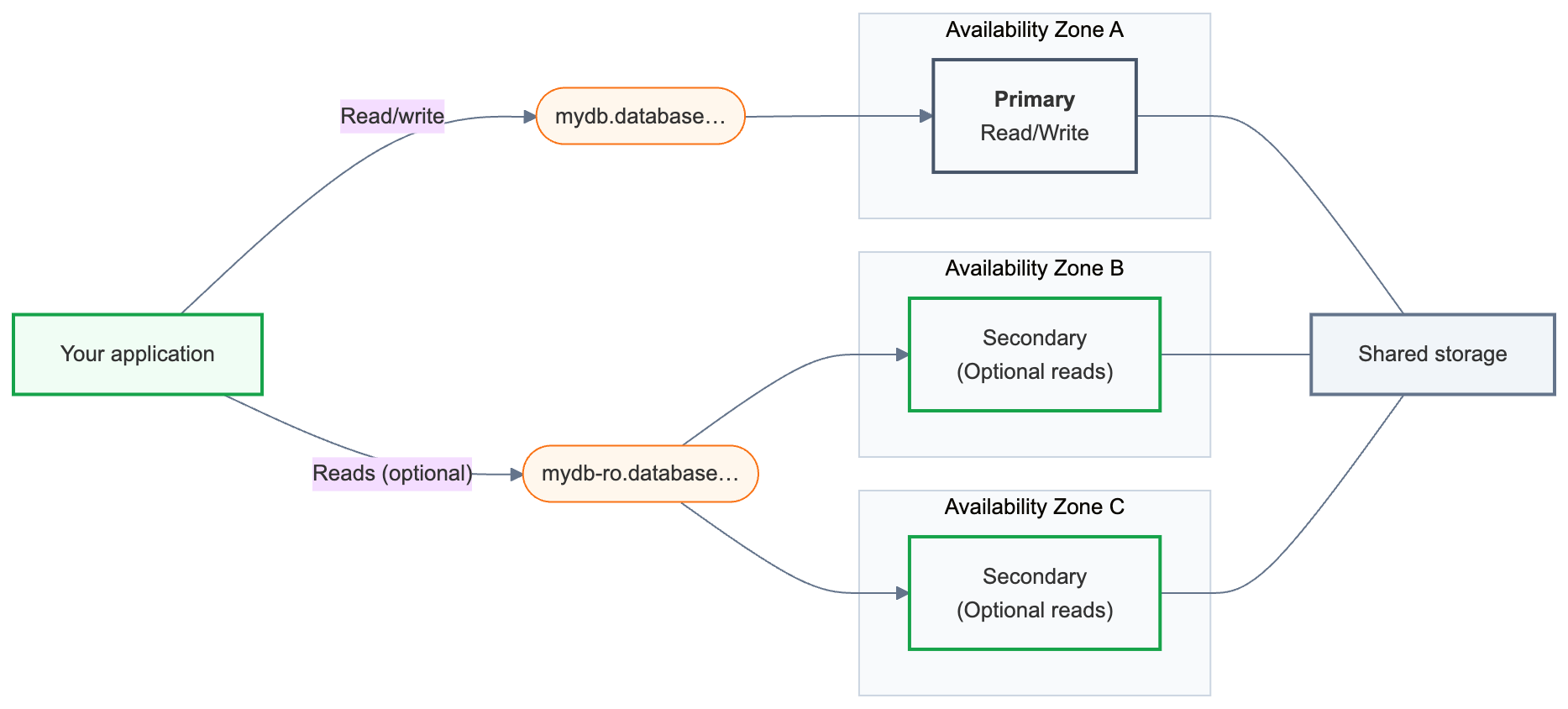
Funktionsweise von Hochverfügbarkeit
Ein Lakebase-Endpunkt ist die Datenbankadresse, mit der Ihre Anwendung eine Verbindung herstellt. Ein Endpunkt für hohe Verfügbarkeit macht zwei Verbindungszeichenfolgen verfügbar:
-
Primär (
{endpoint-id}.database.{region}.databricks.com) – Die Hauptverbindung mit Lese-/Schreibzugriff. Verwenden Sie dies in jeder Anwendung, die eine Verbindung mit Ihrer Datenbank herstellt. Nach einem Failover wird automatisch zur jetzt primären Berechnungsressource weitergeleitet. -
Sekundär (
{endpoint-id}-ro.database.{region}.databricks.com) – nur verfügbar, wenn Zugriff auf schreibgeschützte Computerinstanzen erlaubt ist. Sekundäre Recheninstanzen existieren in erster Linie als Failover-Standbys. Mit aktiviertem Lesezugriff können Leseabfragen darüber hinaus weitergeleitet werden.
Beide Verbindungszeichenfolgen sind über das Dialogfeld "Verbinden " auf Ihrem Endpunkt verfügbar.
Hinter diesen Verbindungszeichenfolgen verfügt ein Endpunkt für hohe Verfügbarkeit immer über genau eine primäre Computeinstanz und eine bis drei sekundäre Computeinstanzen. Die primäre Einheit bearbeitet den gesamten Lese-/Schreibverkehr. Sekundäre Computeinstanzen werden in verschiedenen Verfügbarkeitszonen ausgeführt und werden höhergestuft, um im Falle eines Fehlers zur primären Instanz zu werden.
Jede sekundäre Computeinstanz verfügt über eine Access-Einstellung , die bestimmt, ob sie auch Lesedatenverkehr bietet:
| Sekundärer Zugriff | Was es tut |
|---|---|
| Schreibgeschützt | Sekundäre Recheninstanz liefert Lesevorgänge über die -ro Verbindungszeichenfolge und kann bei Bedarf als primär befördert werden. |
| Deaktiviert | Sekundäre Computeinstanz ist aktiv und bereit für Failover, bietet jedoch keinen Lesedatenverkehr. |
Sie steuern dies mit der Einstellung "Zugriff auf schreibgeschützte Computeinstanzen zulassen" an dem Endpunkt, die Sie im Edit Compute-Bereich aufrufen können. Wenn diese Option aktiviert ist, dienen alle sekundären Computeinstanzen zum Lesen; wenn sie deaktiviert sind, befinden sie sich nur im Standbymodus für Failover. In beiden Fällen wird bereits Computehardware zugewiesen und ausgeführt: Die Heraufstufung erfordert keine neue Bereitstellung, sodass Ihre Failoverkapazität unabhängig von der Nachfrage in der Verfügbarkeitszone reserviert ist.
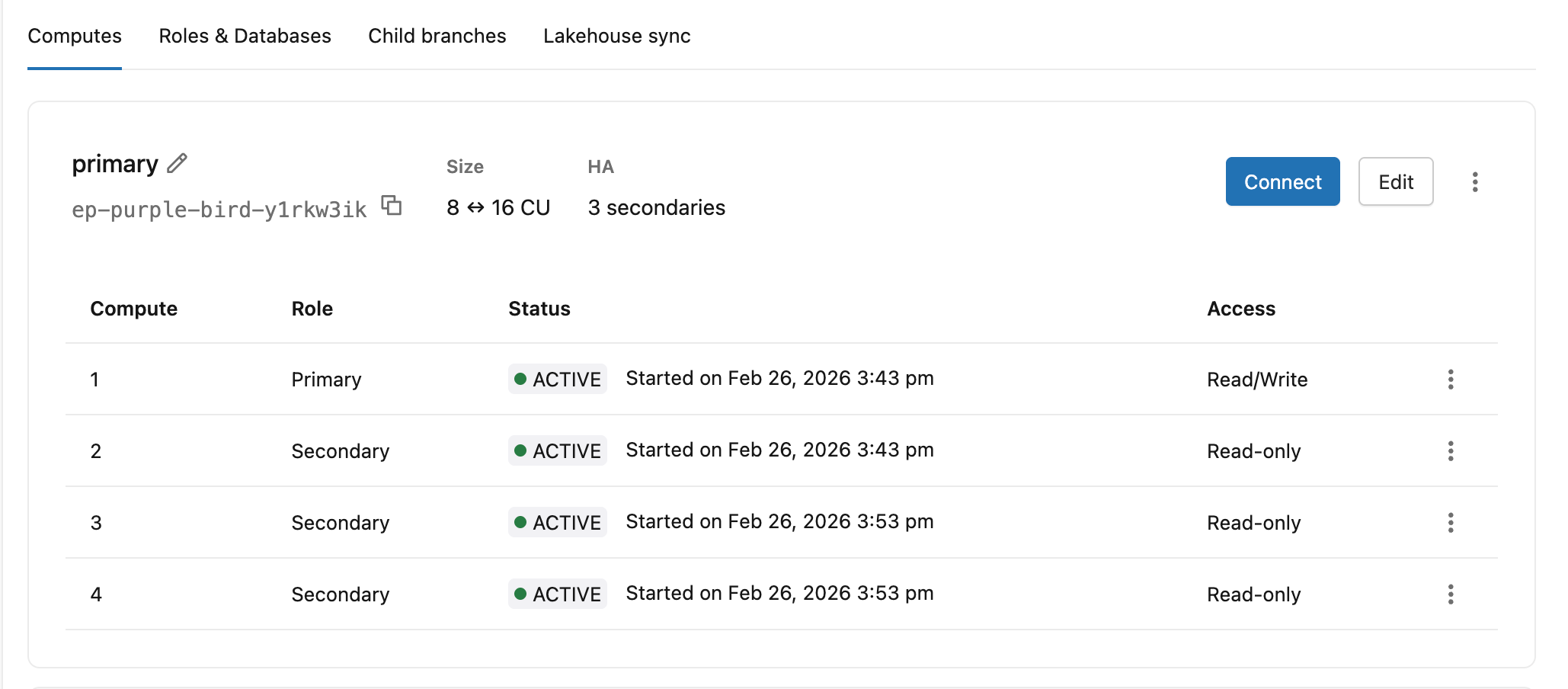
Auf der Registerkarte "Computes" werden die Rolle der einzelnen Computeinstanzen (Primär oder Sekundär), Status und Zugriffsebene auf einen Blick angezeigt.
AZ-Verteilung
Lakebase verteilt die primären und sekundären Computeinstanzen über Verfügbarkeitszonen und reduziert das Risiko, dass ein einzelner AZ-Fehler sowohl die primäre als auch alle sekundären Computeinstanzen betrifft.
Automatische Skalierung in hoher Verfügbarkeit
Alle Computeinstanzen in einer Hochverfügbarkeitskonfiguration teilen denselben automatischen Skalierungsbereich. Die maximale Unterschied zwischen dem Minimum und Maximum CU beträgt 16 CU, das gleiche Limit wie die eigenständigen Compute-Instanzen.
Sekundäre Computeinstanzen werden immer auf mindestens die gleiche CU-Größe wie die primären Instanzen skaliert, um die Konsistenz der Datenbankkapazität nach einem Failover sicherzustellen.
Skalierung auf Null ist für Computeinstanzen in einer Hochverfügbarkeitskonfiguration nicht verfügbar. Sie können alle Computeinstanzen manuell anhalten, ihr Endpunkt ist jedoch während der Pause nicht verfügbar.
Sekundäre Computeinstanzen im Vergleich zu eigenständigen Lesereplikaten
Sekundäre Compute-Instanzen und eigenständige Read-Replikate sind unterschiedliche Features, die in demselben Entwicklungszweig koexistieren können.
| Sekundäre Compute-Instanzen | Eigenständige Lesereplikate | |
|---|---|---|
| Purpose | Failover + optionale Entlastung beim Lesen | Schreibgeschütztes Offload |
| Hinzugefügt über | Hochverfügbarkeitskonfiguration | Lesereplikat hinzufügen |
| Nimmt teil am Failover | Ja | No |
| Verbindungszeichenfolge |
-ro am primären Endpunkt |
Eigener separater Endpunkt |
| Größenbestimmung | Gemeinsam mit der primären (Endpunktebene) genutzt | Unabhängig dimensioniert |
Wenn Sie sowohl hohe Verfügbarkeit als auch zusätzliche Lesekapazität benötigen, die über die bereitgestellten sekundären Computeinstanzen hinausgeht, können Sie beide Features in derselben Verzweigung kombinieren. Siehe Lesen von Replikaten.
Failoververhalten
Automatisches Failover
Lakebase überwacht kontinuierlich die Integrität der primären Rechenleistung. Wenn das Primärsystem nicht verfügbar ist, wird das Failover automatisch ausgelöst.
Failover behält alle zugesicherten Transaktionen bei.
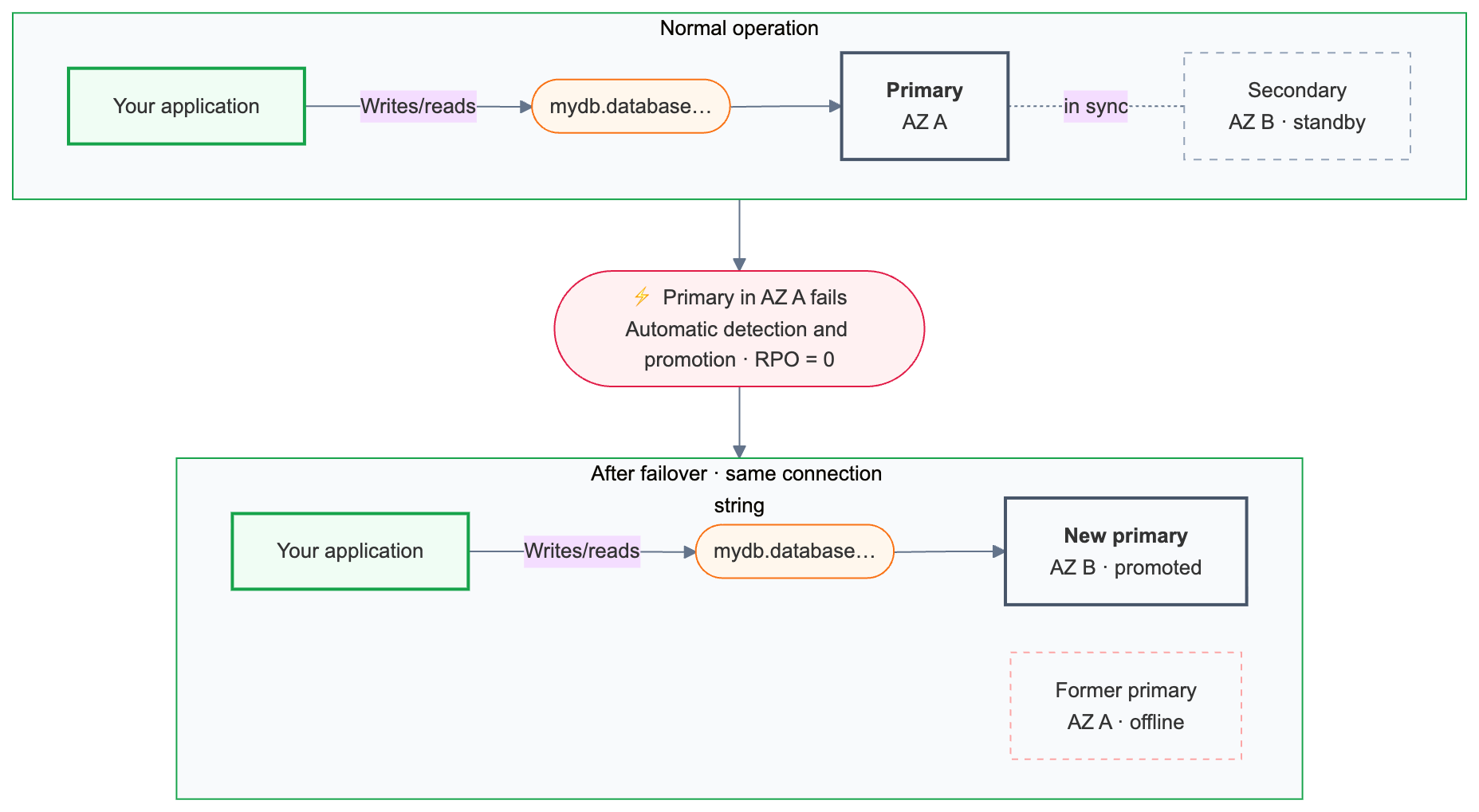
Nach dem Failover leitet die primäre Verbindungszeichenfolge ({endpoint-id}.database.{region}.databricks.com) automatisch an die neu heraufgestufte Computeinstanz weiter. Anwendungen müssen ihre Verbindungskonfiguration nicht ändern, vorhandene Verbindungen werden jedoch während des Failovers beendet und müssen erneut verbunden werden. Anwendungen mit Wiederholungslogik behandeln dies automatisch.
Failover mit aktiviertem schreibgeschütztem Zugriff
Wenn der Zugriff auf schreibgeschützte Computeinstanzen aktiviert ist und ein Failover auftritt, wird die höhergestufte sekundäre Instanz zur neuen primären Instanz und beendet lesevorgänge. Wenn Sie zwei oder mehr lesbare Secondärdateien haben, wird der Lesedatenverkehr in der -ro Verbindungszeichenfolge weiterhin mit reduzierter Kapazität fortgesetzt, bis eine Ersetzung bereitgestellt wird. Wenn Sie nur ein Gerät haben, werden Lesevorgänge vollständig unterbrochen, bis der Ersatz bereit ist.
Verbindungszeichenfolgen
Im Dialogfeld "Verbinden " werden beide Verbindungszeichenfolgen mit ihrem aktuellen Computestatus angezeigt:
| Berechnungsoption im Dialogfeld "Verbinden" | Verbindungszeichenfolge | Verwendung für |
|---|---|---|
Primary (name) ● Active |
{endpoint-id}.database.{region}.databricks.com |
Alle Schreib- und Lesevorgänge, die auf die aktuelle primäre zugreifen müssen |
Secondary (name) ● Active RO |
{endpoint-id}-ro.database.{region}.databricks.com |
Weiterleitung der Lesevorgänge zu sekundären Recheninstanzen (nur verfügbar, wenn der Zugriff auf nur-lesende Recheninstanzen aktiviert ist) |
Die primäre Verbindungszeichenfolge leitet immer an die aktuelle Primäre weiter, einschließlich nach einem Failover.
Jede Computeinstanz verfügt außerdem über eine eigene direkte Verbindungszeichenfolge, auf die über die Registerkarte " Computes " über das Menü "Aktionen" (⋮) in jeder Zeile zugegriffen werden kann. Direkte Verbindungen sind für die Problembehandlung einzelner Computeinstanzen vorgesehen, nicht für die Anwendungsverwendung. Direkte Verbindungszeichenfolgen werden pro Berechnung berechnet und können sich ändern, wenn Secondaries hinzugefügt, entfernt oder höhergestuft werden.
Grenzwerte für hohe Verfügbarkeit
| Begrenzung | Wert |
|---|---|
| Recheninstanzen | 2, 3 oder 4 (1 primäre + 1–3 sekundäre Computeinstanzen) |
| Automatischer Skalierungsbereich (max − min) | ≤ 16 CU zwischen Minimalwert und Maximalwert |
| Skalierung auf null | Für Computeinstanzen in einer Hochverfügbarkeitskonfiguration nicht verfügbar |
Bewährte Methoden
Wenn Sie diese Methoden ausführen, bleibt Ihre Anwendung während Failoverereignissen stabil und verfügbar.
| Praxis | Einzelheiten |
|---|---|
| Implementieren der Verbindungs-Wiederholungslogik | Aktive Verbindungen werden während des Failovers beendet. Verbindungen mit dem fehlgeschlagenen primären Server können bis zum Timeout hängen bleiben. Konfigurieren Sie TCP-Keepalive oder ein Verbindungstimeout in Ihrem Treiber, um das Versagen schnell zu erkennen. Verbindungen mit der höhergestuften Sekundäre werden aktiv beendet, und es wird sofort ein Fehler zurückgegeben. Anwendungen mit Wiederholungslogik werden innerhalb von Sekunden automatisch erneut verbunden. |
| Konfigurieren der sekundären Anzahl für Ihren Anwendungsfall | Jede sekundäre Computeinstanz stellt vorab zugewiesene Hardware dar, die für failover reserviert ist. Die Reduzierung der sekundären Anzahl bedeutet weniger Failoverkapazität und weniger abgedeckte Verfügbarkeitszonen. Eine sekundäre Recheninstanz bietet Failover-Abdeckung. Wenn Sie lesbare Secondärdateien aktivieren, konfigurieren Sie zwei oder mehr. Bei nur einer werden Lesevorgänge während eines Failovers vollständig unterbrochen, bis ein Ersatz bereitgestellt wird. |
| Vermeiden der Überladung von sekundären Computeinstanzen | Der Dienst kann eine sekundäre Computeinstanz neu starten, die überlastet oder zurückfällt. Überwachen Sie die Abfragelast und die Anzahl der Verbindungen und erhöhen Sie die Größe der CUs, wenn Sie eine anhaltend hohe Auslastung feststellen. |
Nächste Schritte
- Verwalten der hohen Verfügbarkeit zum Aktivieren und Konfigurieren hoher Verfügbarkeit
- Autoscaling für Details zu CU-Größen und automatische Skalierung
- Verbindungszeichenfolgen für eine vollständige Referenz