Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Die Ausführung adaptiver Abfragen (Adaptive Query Execution, AQE) ist die Erneute Optimierung der Abfrage, die während der Abfrageausführung auftritt.
Die Motivation für die Erneute Optimierung der Laufzeit besteht darin, dass Azure Databricks am Ende eines Shuffle- und Broadcast-Austauschs (als Abfragestufe in AQE bezeichnet) die am meisten up-todatumsgenaue Statistiken aufweist. Daher können sich Azure Databricks für eine bessere physische Strategie entscheiden, eine optimale Partitionsgröße und -zahl nach dem Shuffle auswählen oder Optimierungen durchführen, die früher Hinweise erforderten, z. B. Umgang mit schiefen Verknüpfungen.
Dies kann sehr nützlich sein, wenn die Statistiksammlung nicht aktiviert ist oder wenn Statistiken veraltet sind. Es ist auch nützlich in Situationen, in denen statisch abgeleitete Statistiken ungenau sind, z. B. in der Mitte einer komplizierten Abfrage oder nach dem Auftreten einer Datenschiefverteilung.
Fähigkeiten
AQE ist standardmäßig aktiviert. AQE umfasst vier Hauptfunktionen:
- Dynamische Änderung von Sort-Merge-Join in Broadcast-Hash-Join.
- Dynamisches Zusammenführen von Partitionen (Zusammenführung kleiner Partitionen in vernünftig große Partitionen) nach dem Shuffle-Austausch. Sehr kleine Vorgänge haben einen schlechteren E/A-Durchsatz und neigen dazu, mehr unter dem Planungsoverhead und dem Einrichtungsaufwand zu leiden. Das Kombinieren kleiner Vorgänge spart Ressourcen und verbessert den Clusterdurchsatz.
- Dynamisch behandelt es die Schieflage in Sort-Merge-Join und Shuffle-Hash-Join, indem schiefe Aufgaben in etwa gleich große Aufgaben aufgeteilt und bei Bedarf repliziert werden.
- Dynamische Erkennung und Weitergabe von leeren Beziehungen.
Anwendung
AQE gilt für alle Abfragen, die wie folgt sind:
- Nicht-Streaming
- Sie enthalten mindestens einen Austausch (in der Regel, wenn eine Verknüpfung, ein Aggregat oder ein Fenster vorhanden ist), eine Unterabfrage oder beides.
Nicht alle AQE-angewendeten Abfragen werden unbedingt erneut optimiert. Die erneute Optimierung kann möglicherweise zu einem anderen Abfrageplan führen als der statisch kompilierte. Informationen dazu, ob der Plan einer Abfrage von AQE geändert wurde, finden Sie im folgenden Abschnitt, Abfragepläne.
Abfragepläne
In diesem Abschnitt wird erläutert, wie Sie Abfragepläne auf unterschiedliche Weise untersuchen können.
Inhalt dieses Abschnitts:
Spark-Benutzeroberfläche
AdaptiveSparkPlan Knoten
AQE-angewendete Abfragen enthalten einen oder mehrere AdaptiveSparkPlan Knoten, in der Regel als Stammknoten der Haupt- oder Unterabfragen.
Bevor die Abfrage ausgeführt wird oder wenn sie ausgeführt wird, wird das isFinalPlan Flag des entsprechenden AdaptiveSparkPlan Knotens angezeigt als false; nach Abschluss der Abfrageausführung ändert sich das isFinalPlan Flag in true.
Weiterentwickelter Plan
Das Abfrageplandiagramm wird während des Fortschritts der Ausführung weiterentwickelt und spiegelt den aktuellen Plan wider, der ausgeführt wird. Knoten, die bereits ausgeführt wurden (bei denen Metriken verfügbar sind), ändern sich nicht, aber diejenigen, die noch nicht ausgeführt wurden, können sich im Laufe der Zeit als Ergebnis erneuter Optimierungen ändern.
Nachfolgend sehen Sie ein Beispiel für ein Abfrageplandiagramm:
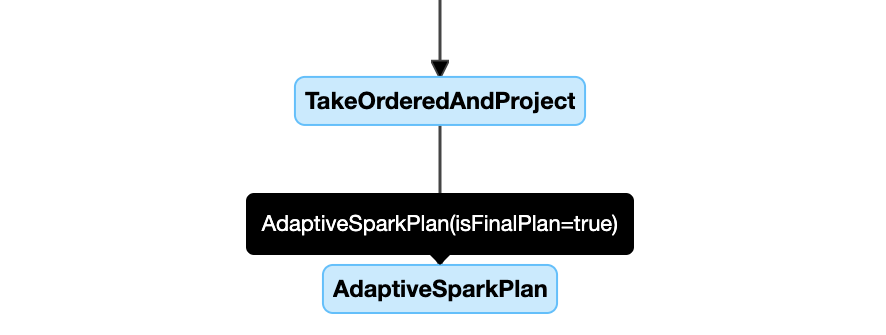
DataFrame.explain()
AdaptiveSparkPlan Knoten
AQE-angewendete Abfragen enthalten einen oder mehrere AdaptiveSparkPlan Knoten, in der Regel als Stammknoten der Haupt- oder Unterabfragen. Bevor die Abfrage ausgeführt wird oder wenn sie ausgeführt wird, wird das isFinalPlan Flag des entsprechenden AdaptiveSparkPlan Knotens angezeigt als false; nach Abschluss der Abfrageausführung ändert sich das isFinalPlan Flag in true.
Aktueller und anfänglicher Plan
Unter jedem AdaptiveSparkPlan Knoten gibt es sowohl den anfänglichen Plan (den Plan vor der Anwendung von AQE-Optimierungen) als auch den aktuellen oder den endgültigen Plan, je nachdem, ob die Ausführung abgeschlossen wurde. Der aktuelle Plan wird sich entwickeln, wenn die Ausführung fortschreitet.
Laufzeitstatistiken
Jede Shuffle- und Broadcast-Phasen enthalten Datenstatistiken.
Bevor die Phase ausgeführt wird oder wenn die Phase ausgeführt wird, werden die Statistiken zu Kompilierungszeitschätzungen erstellt, und die Kennzeichnung isRuntime lautet falsebeispielsweise: Statistics(sizeInBytes=1024.0 KiB, rowCount=4, isRuntime=false);
Nach Abschluss der Phasenausführung werden die Statistiken zur Laufzeit erfasst, und das Flag isRuntime wird true, z. B.: Statistics(sizeInBytes=658.1 KiB, rowCount=2.81E+4, isRuntime=true)
Im Folgenden sehen Sie ein DataFrame.explain Beispiel:
Vor der Ausführung
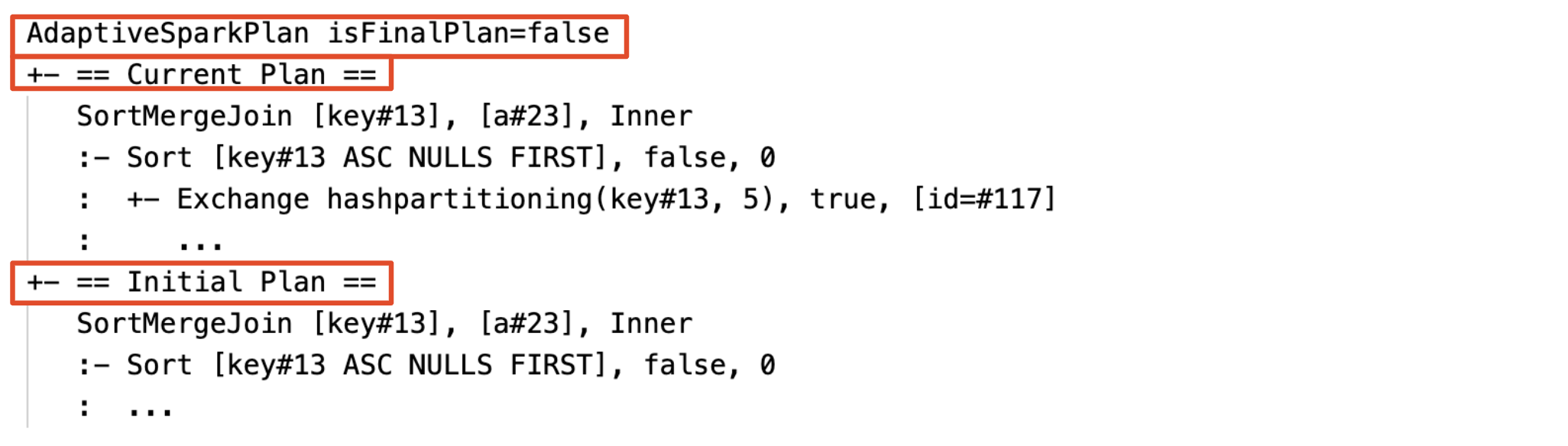
Während der Ausführung des Vorgangs
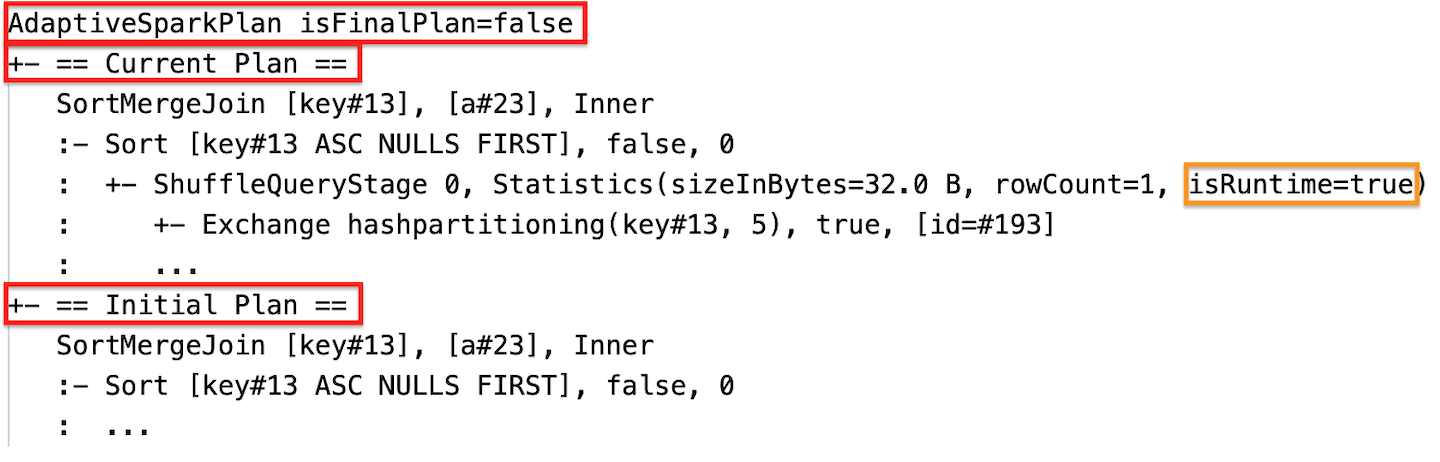
Nach der Ausführung
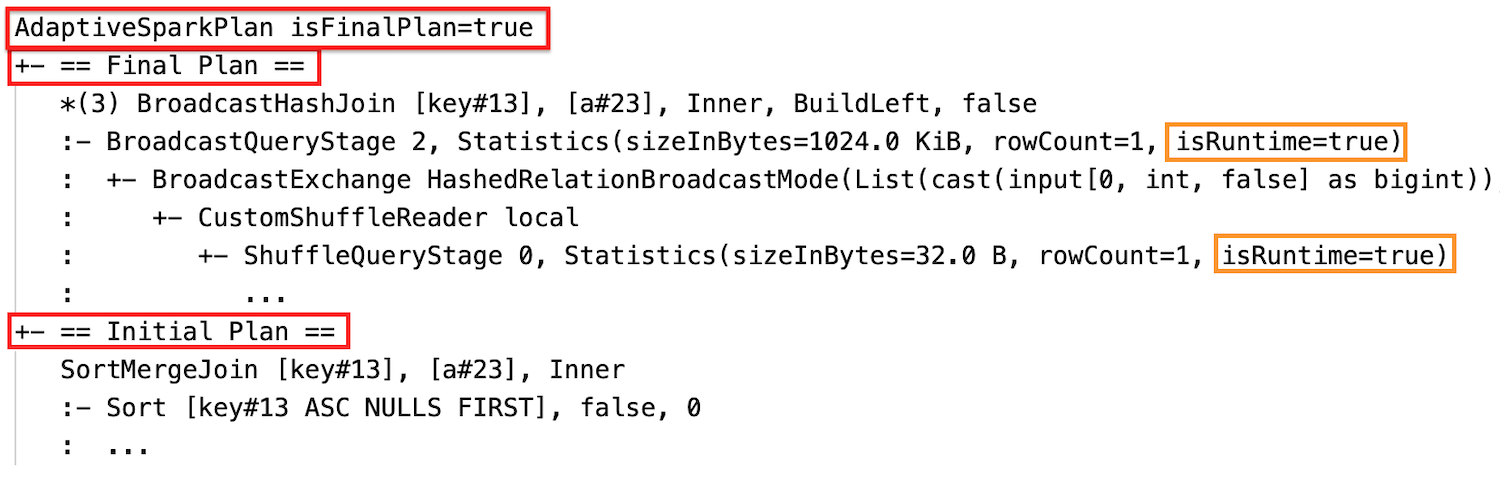
SQL EXPLAIN
AdaptiveSparkPlan Knoten
AQE-angewendete Abfragen enthalten mindestens einen AdaptiveSparkPlan-Knoten, in der Regel als Stammknoten jeder Hauptabfrage oder Unterabfrage.
Kein aktueller Plan
Da SQL EXPLAIN die Abfrage nicht ausgeführt wird, entspricht der aktuelle Plan immer dem ursprünglichen Plan und gibt nicht an, was schließlich von AQE ausgeführt werden würde.
Es folgt ein SQL-Erläuterungsbeispiel:

Wirksamkeit
Der Abfrageplan ändert sich, wenn eine oder mehrere AQE-Optimierungen wirksam werden. Die Auswirkungen dieser AQE-Optimierungen werden durch den Unterschied zwischen den aktuellen und endgültigen Plänen und dem anfänglichen Plan und spezifischen Planknoten in den aktuellen und endgültigen Plänen veranschaulicht.
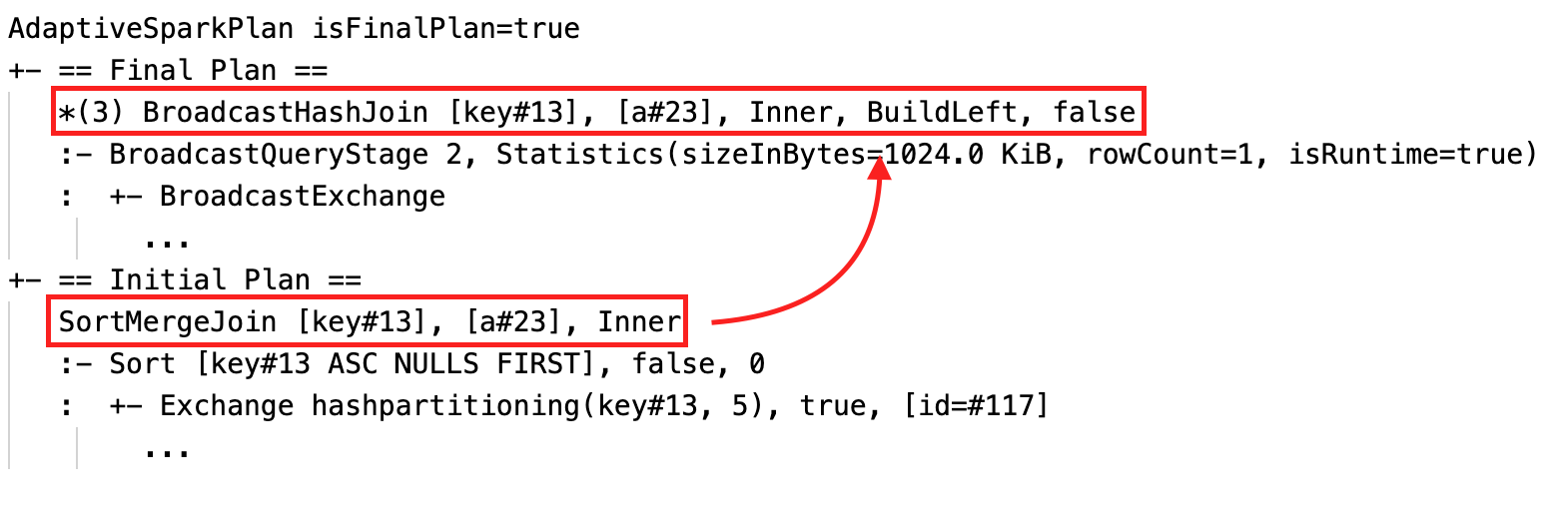
Dynamisches Ändern von Sort-Merge-Join in Broadcast-Hash-Join: verschiedene physische Join-Knoten zwischen dem aktuellen/endgültigen Plan und dem anfänglichen Plan
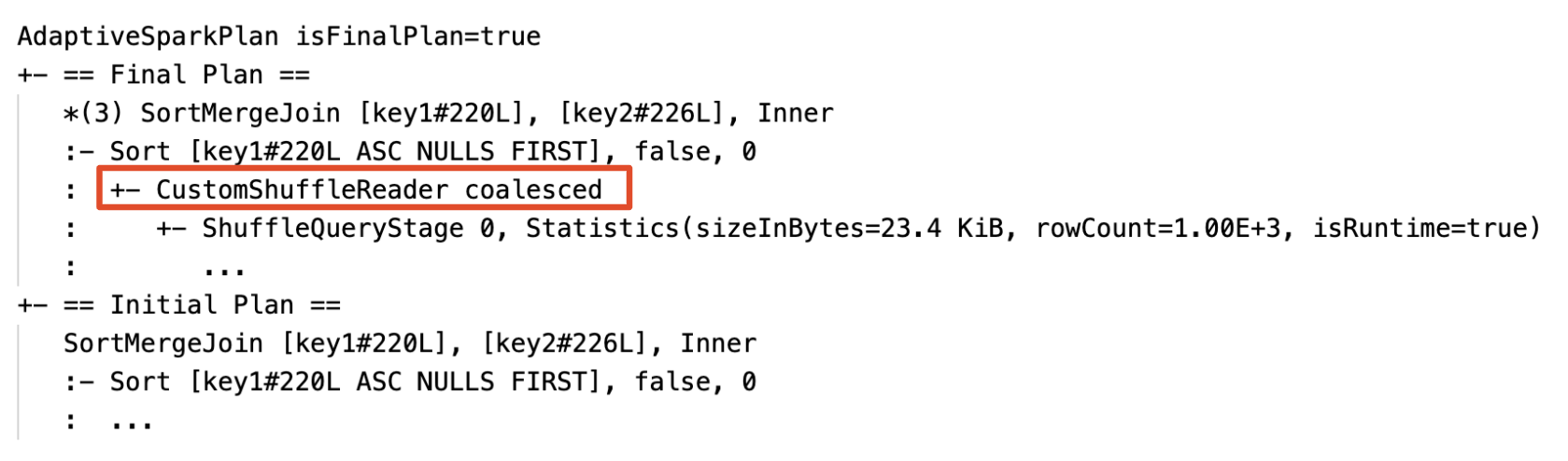
Dynamisches Zusammenwachsen von Partitionen: Knoten
CustomShuffleReadermit EigenschaftCoalesced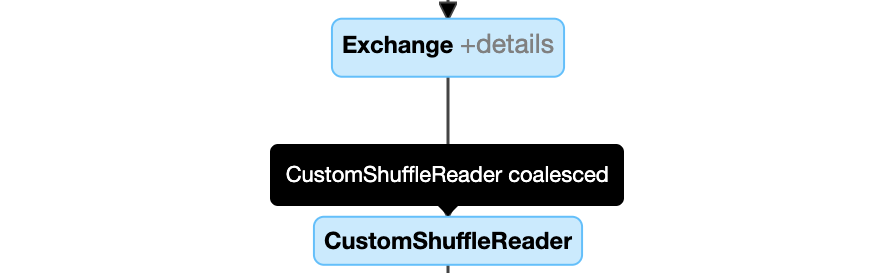
Dynamisches Behandeln der schiefen Verknüpfung: Knoten
SortMergeJoinmit FeldisSkewals "true".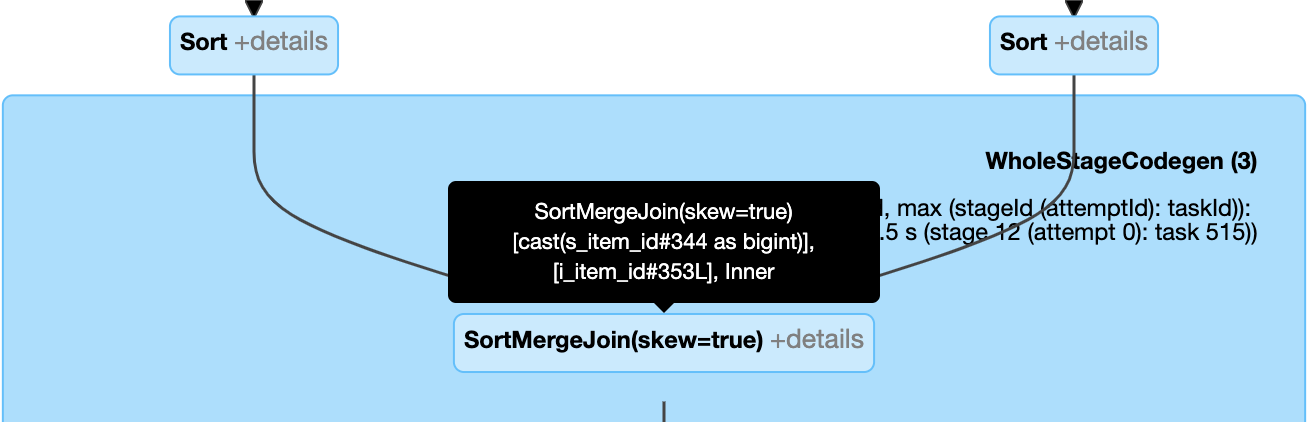
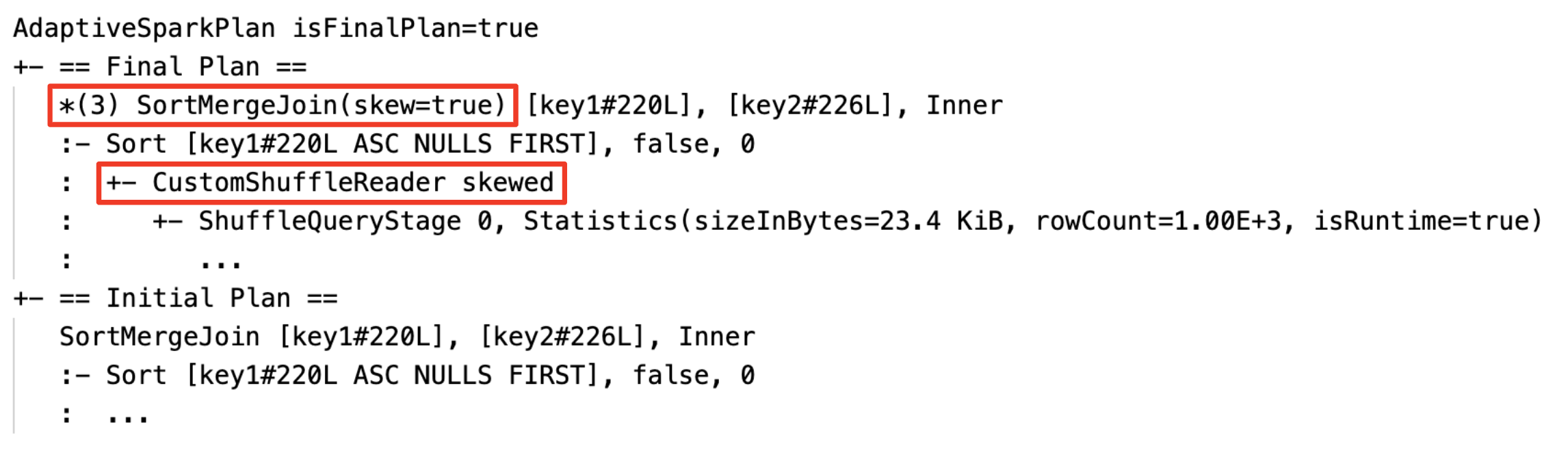
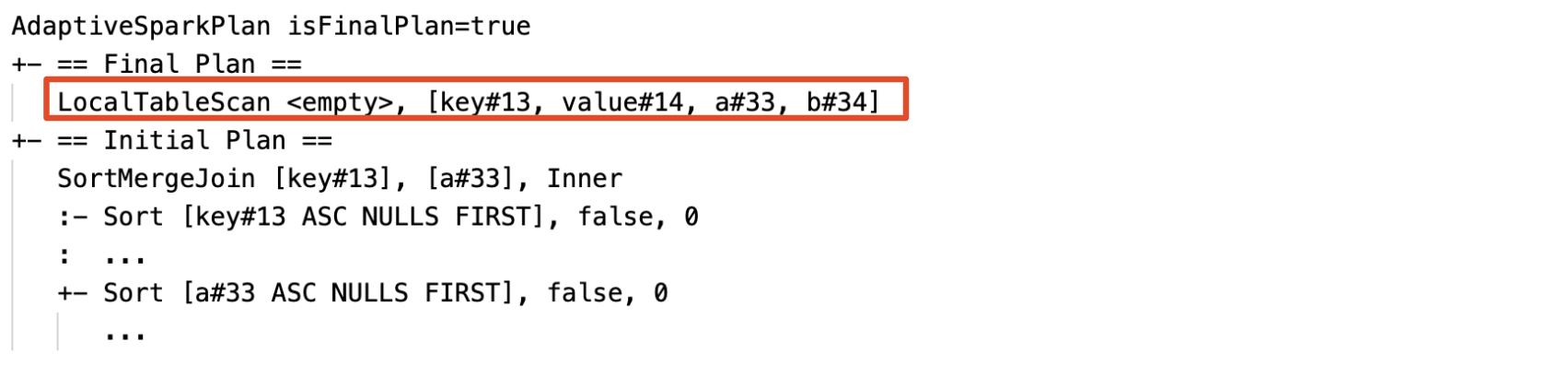
Dynamisches Erkennen und Verteilen leerer Beziehungen: Teil (oder der gesamte) Plan wird durch den Knoten LocalTableScan ersetzt, wobei das Beziehungsfeld leer ist.
Konfiguration
Inhalt dieses Abschnitts:
- Aktivieren und Deaktivieren der Ausführung adaptiver Abfragen
- Aktivieren automatisch optimierter Shuffle-Funktion
- Dynamisches Ändern von Sort-Merge-Join in Broadcast-Hash-Join
- Dynamisches Zusammenführen von Partitionen
- Dynamisch mit schiefen Joins umgehen
- Dynamisches Erkennen und Verteilen leerer Beziehungen
Aktivieren und Deaktivieren der Ausführung adaptiver Abfragen
| Eigentum |
|---|
|
spark.databricks.optimizer.adaptive.enabled Typ: BooleanGibt an, ob die Ausführung adaptiver Abfragen aktiviert oder deaktiviert werden soll. Standardwert: true |
Aktivieren automatisch optimierter Shuffle-Funktion
| Eigentum |
|---|
|
spark.sql.shuffle.partitions Typ: IntegerDie Standardanzahl der Partitionen, die beim Mischen von Daten für Verknüpfungen oder Aggregationen verwendet werden sollen. Durch Festlegen des Werts auto wird ein automatisch optimiertes Shuffle ermöglicht, wobei diese Zahl basierend auf dem Abfrageplan und der Größe der Abfrageeingabedaten automatisch bestimmt wird.Hinweis: Für Structured Streaming kann diese Konfiguration nicht zwischen Neustarts der Abfrage vom gleichen Prüfpunkt-Speicherort geändert werden. Standardwert: 200 |
Sort-Merge-Join dynamisch in Broadcast-Hash-Join umwandeln
| Eigentum |
|---|
|
spark.databricks.adaptive.autoBroadcastJoinThreshold Typ: Byte StringDer Schwellenwert zum Aktivieren der Umschaltung auf Broadcast-Join zur Laufzeit. Standardwert: 30MB |
Dynamische Zusammenführung von Partitionen
| Eigentum |
|---|
|
spark.sql.adaptive.coalescePartitions.enabled Typ: BooleanGibt an, ob die Partitionenverschmelzung aktiviert oder deaktiviert werden soll. Standardwert: true |
|
spark.sql.adaptive.advisoryPartitionSizeInBytes Typ: Byte StringDie Zielgröße nach dem Zusammenwachsen. Die zusammengeführten Partitionsgrößen sind nahe an dieser Zielgröße, aber nicht größer. Standardwert: 64MB |
|
spark.sql.adaptive.coalescePartitions.minPartitionSize Typ: Byte StringDie mindeste Größe der Partitionen nach dem Zusammenwachsen. Die zusammengefassten Partitionsgrößen werden nicht kleiner als diese Größe sein. Standardwert: 1MB |
|
spark.sql.adaptive.coalescePartitions.minPartitionNum Typ: IntegerDie Mindestanzahl der Partitionen nach dem Verschmelzen. Nicht empfohlen, da die Einstellung explizit außer Kraft gesetzt wird spark.sql.adaptive.coalescePartitions.minPartitionSize.Standardwert: 2-mal Anzahl der Clusterkerne |
Dynamische Behandlung der schiefen Verknüpfung
| Eigentum |
|---|
|
spark.sql.adaptive.skewJoin.enabled Typ: BooleanGibt an, ob die Behandlung von schiefen Verknüpfungen aktiviert oder deaktiviert werden soll. Standardwert: true |
|
spark.sql.adaptive.skewJoin.skewedPartitionFactor Typ: IntegerEin Faktor, der bei der Multiplikation mit der Medianpartitionsgröße dazu beiträgt, zu bestimmen, ob eine Partition schief ist. Standardwert: 5 |
|
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes Typ: Byte StringEin Schwellenwert, der dazu beiträgt, zu bestimmen, ob eine Partition schief ist. Standardwert: 256MB |
Eine Partition wird als schief betrachtet, wenn sowohl (partition size > skewedPartitionFactor * median partition size) als auch (partition size > skewedPartitionThresholdInBytes)true sind.
Dynamisches Erkennen und Verteilen leerer Beziehungen
| Eigentum |
|---|
|
spark.databricks.adaptive.emptyRelationPropagation.enabled Typ: BooleanGibt an, ob dynamische leere Beziehungsverteilung aktiviert oder deaktiviert werden soll. Standardwert: true |
Häufig gestellte Fragen (FAQ)
Inhalt dieses Abschnitts:
- Warum hat AQE keine kleine Join-Tabelle übertragen?
- Sollte ich weiterhin einen Hinweis zur Broadcast-Join-Strategie verwenden, wenn AQE aktiviert ist?
- Was ist der Unterschied zwischen der Skew-Join-Empfehlung und der AQE-Skew-Join-Optimierung? Welche sollte ich verwenden?
- Warum hat AQE meine Verknüpfungsbestellung nicht automatisch angepasst?
- Warum hat AQE meine Datenverschiebung nicht erkannt?
Warum hat AQE keine kleine Join-Tabelle übertragen?
Wenn die Größe der zu übertragenden Beziehung unter diesen Schwellenwert fällt, aber immer noch nicht übertragen wird:
- Überprüfen Sie den Verknüpfungstyp. Broadcasting wird für bestimmte Join-Typen nicht unterstützt, z. B. kann die linke Relation eines
LEFT OUTER JOINnicht verteilt werden. - Es kann auch sein, dass die Relation viele leere Partitionen enthält, in diesem Fall kann die Mehrzahl der Aufgaben schnell mit einem Sort-Merge-Join abgeschlossen werden oder durch Skew-Join-Verarbeitung optimiert werden. AQE verhindert, dass solche Sortierzusammenführungsverknnungen geändert werden, um Hash-Verknüpfungen zu übertragen, wenn der Prozentsatz der nicht leeren Partitionen niedriger als
spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoinist.
Sollte ich weiterhin einen Hinweis zur Broadcast-Join-Strategie verwenden, wenn AQE aktiviert ist?
Ja. Eine statisch geplante Broadcast-Join ist in der Regel leistungsfähiger als eine dynamisch geplante durch AQE, da AQE möglicherweise erst nach der Durchführung des "Shuffle" für beide Seiten der Verbindung wechselt, wobei die tatsächlichen Relationsgrößen ermittelt werden. Daher kann die Verwendung eines Broadcasthinweiss immer noch eine gute Wahl sein, wenn Sie Ihre Abfrage gut kennen. AQE berücksichtigt Abfragehinweise auf die gleiche Weise wie die statische Optimierung, kann aber dennoch dynamische Optimierungen anwenden, die von den Hinweisen nicht betroffen sind.
Was ist der Unterschied zwischen der Skew-Join-Empfehlung und der AQE-Skew-Join-Optimierung? Welche sollte ich verwenden?
Es wird empfohlen, auf die AQE skew-Join-Verarbeitung zu setzen, anstatt den Skew Join-Hinweis zu verwenden, da der AQE skew-Join vollständig automatisch ist und im Allgemeinen leistungsfähiger ist als das entsprechende Hinweis.
Warum hat AQE meine Verknüpfungsbestellung nicht automatisch angepasst?
Die Neuanordnung dynamischer Verknüpfungen ist nicht Teil von AQE.
Warum hat AQE meine Daten-Schieflage nicht erkannt?
Es gibt zwei Größenbedingungen, die erfüllt sein müssen, damit AQE eine Partition als schiefe Partition erkennt:
- Die Partitionsgröße ist größer als die
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes(Standardgröße 256 MB) - Die Partitionsgröße ist größer als das Produkt aus der Mediangröße aller Partitionen und dem schiefen Partitionsfaktor
spark.sql.adaptive.skewJoin.skewedPartitionFactor(Standard 5).
Darüber hinaus ist die Unterstützung bei der Behandlung von Schieflagen für bestimmte Verknüpfungstypen eingeschränkt, z. B. in LEFT OUTER JOIN, kann nur die Schieflage auf der linken Seite optimiert werden.
Erbe
Der Begriff "Adaptive Ausführung" ist seit Spark 1.6 vorhanden, aber der neue AQE in Spark 3.0 unterscheidet sich grundlegend. In Bezug auf die Funktionalität übernimmt Spark 1.6 nur den Teil "dynamisches Zusammenwachsen von Partitionen". Im Hinblick auf die technische Architektur ist der neue AQE ein Framework für die dynamische Planung und erneute Planung von Abfragen, die auf Laufzeitstatistiken basieren. Es unterstützt eine Vielzahl von Optimierungen, wie die in diesem Artikel beschriebenen, und kann erweitert werden, um weitere potenzielle Optimierungen zu ermöglichen.