Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure Databricks unterstützt die Binäre Dateidatenquelle, die Binärdateien liest und jede Datei in einen einzelnen Datensatz konvertiert, der den rohen Inhalt und die Metadaten der Datei enthält. Es wird häufig verwendet, um unstrukturierte Daten wie Bilder, Audio- oder PDF-Dateien für nachgeschaltete Verarbeitung oder ML-Ableitung zu laden. Um Binärdateien zu lesen, geben Sie die Datenquelle format als binaryFile an.
Voraussetzungen
Azure Databricks erfordert keine zusätzliche Konfiguration für die Verwendung von Binärdateien.
Optionen
Verwenden Sie die Methoden .option() und .options() von DataFrameReader, um die Datenquelle für Binärdateien zu konfigurieren. Eine vollständige Liste der unterstützten Optionen finden Sie in der Spark-API-Optionsreferenz.
Ausgabeschema
Die Binäre Dateidatenquelle erzeugt einen DataFrame mit den folgenden Spalten sowie alle Partitionsspalten:
-
path (StringType): Der Pfad der Datei. -
modificationTime (TimestampType): Der Zeitpunkt der letzten Änderung der Datei. In einigen HDFS-Implementierungen (Hadoop FileSystem) ist dieser Parameter möglicherweise nicht verfügbar, und der Wert wird auf einen Standardwert festgelegt. -
length (LongType): Die Länge der Datei in Byte. -
content (BinaryType): Der Inhalt der Datei.
Usage
Die folgenden Beispiele veranschaulichen das Laden von Binärdateien mithilfe der Spark DataFrame-API und SQL, filtern nach Dateityp, Anzeigen von Bildvorschauen und Speichern in einer Delta-Tabelle, um die Leseleistung zu verbessern.
Lesen von Binärdateien
Verwenden Sie die Apache Spark DataFrame-API, um Binärdateien in einen DataFrame für Transformation, Anzeige oder Downstreamverarbeitung zu laden.
Python
df = spark.read.format("binaryFile").load("/Volumes/<catalog>/<schema>/<volume>/")
display(df)
Scala
val df = spark.read.format("binaryFile").load("/Volumes/<catalog>/<schema>/<volume>/")
df.show()
SQL
SELECT path, length, modificationTime FROM read_files(
'/Volumes/<catalog>/<schema>/<volume>/images/',
format => 'binaryFile'
)
Konfigurieren von Leseoptionen
Zum Laden von Dateien mit Pfaden, die einem bestimmten Globmuster entsprechen, während das Verhalten der Partitionsermittlung beibehalten wird, können Sie die Option pathGlobFilter verwenden. Der folgende Code liest mittels Partitionsermittlung alle JPG-Dateien aus dem Eingabeverzeichnis:
Python
df = spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load("/Volumes/<catalog>/<schema>/<volume>/images/")
Scala
val df = spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load("/Volumes/<catalog>/<schema>/<volume>/images/")
SQL
SELECT * FROM read_files(
'/Volumes/<catalog>/<schema>/<volume>/images/',
format => 'binaryFile',
pathGlobFilter => '*.jpg'
)
Wenn Sie die Partitionsermittlung ignorieren und Dateien im Eingabeverzeichnis rekursiv durchsuchen möchten, verwenden Sie die Option recursiveFileLookup. Mit dieser Option werden geschachtelte Verzeichnisse auch dann durchsucht, wenn ihre Namen nicht einem Partitionsbenennungsschema wie date=2019-07-01 folgen.
Der folgende Code liest alle JPG-Dateien rekursiv aus dem Eingabeverzeichnis und ignoriert die Partitionsermittlung:
Python
df = (spark.read.format("binaryFile")
.option("pathGlobFilter", "*.jpg")
.option("recursiveFileLookup", "true")
.load("/Volumes/<catalog>/<schema>/<volume>/images/"))
Scala
val df = spark.read.format("binaryFile")
.option("pathGlobFilter", "*.jpg")
.option("recursiveFileLookup", "true")
.load("/Volumes/<catalog>/<schema>/<volume>/images/")
SQL
SELECT * FROM read_files(
'/Volumes/<catalog>/<schema>/<volume>/images/',
format => 'binaryFile',
pathGlobFilter => '*.jpg',
recursiveFileLookup => true
)
Laden und Anzeigen von Bildern
Databricks empfiehlt, die Binärdateidatenquelle zum Laden von Bilddaten zu verwenden. Die Databricks-Funktion display unterstützt die Anzeige von Bilddaten, die mithilfe der binären Datenquelle geladen wurden.
Wenn alle geladenen Dateien einen Dateinamen mit einer Erweiterung für Bilddateien aufweisen, wird automatisch die Bildvorschau aktiviert:
Python
df = spark.read.format("binaryFile").load("/Volumes/<catalog>/<schema>/<volume>/images/")
display(df) # image thumbnails are rendered in the "content" column
Scala
val df = spark.read.format("binaryFile").load("/Volumes/<catalog>/<schema>/<volume>/images/")
df.show()
SQL
SELECT * FROM read_files(
'/Volumes/<catalog>/<schema>/<volume>/images/',
format => 'binaryFile'
)
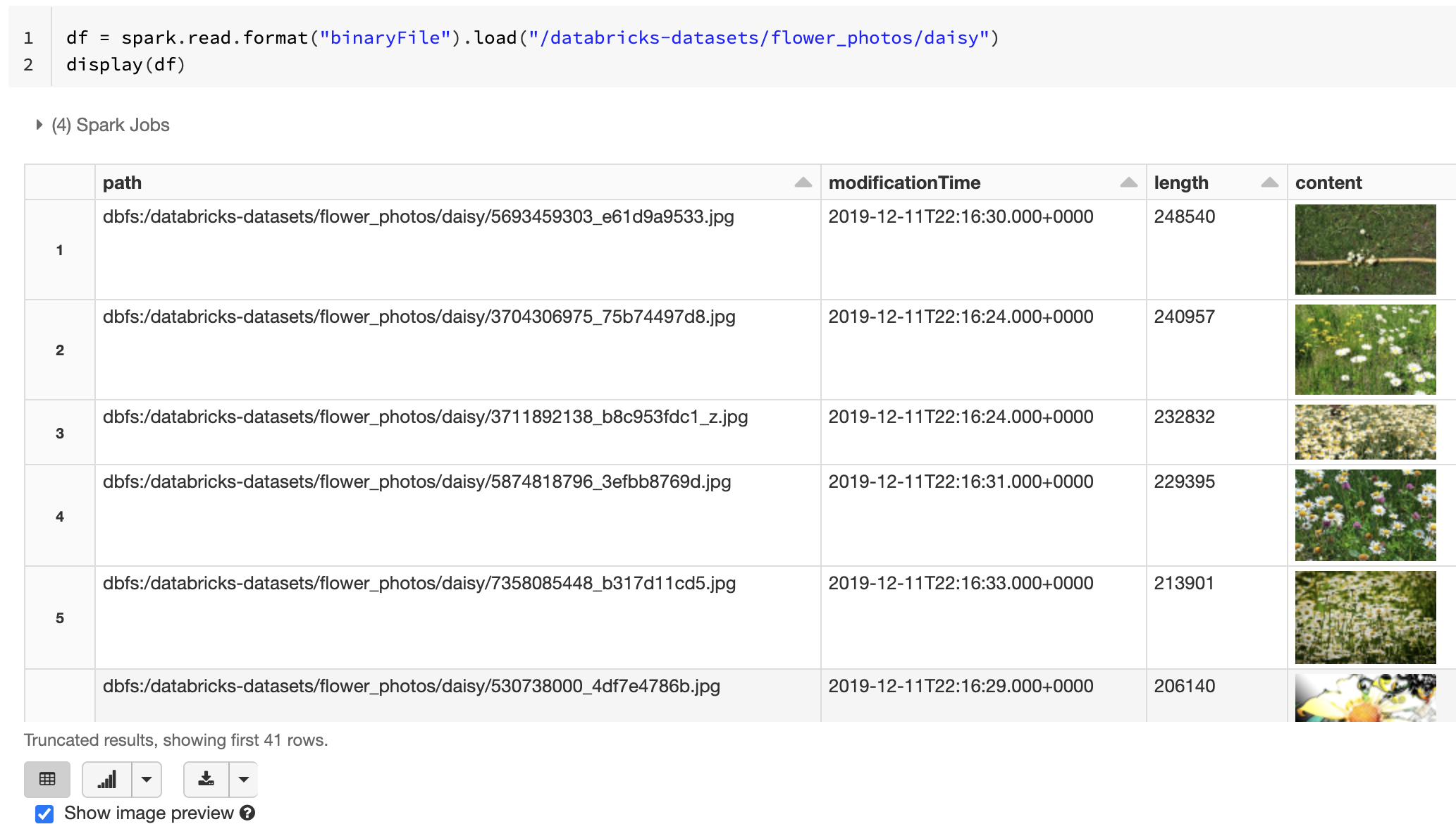
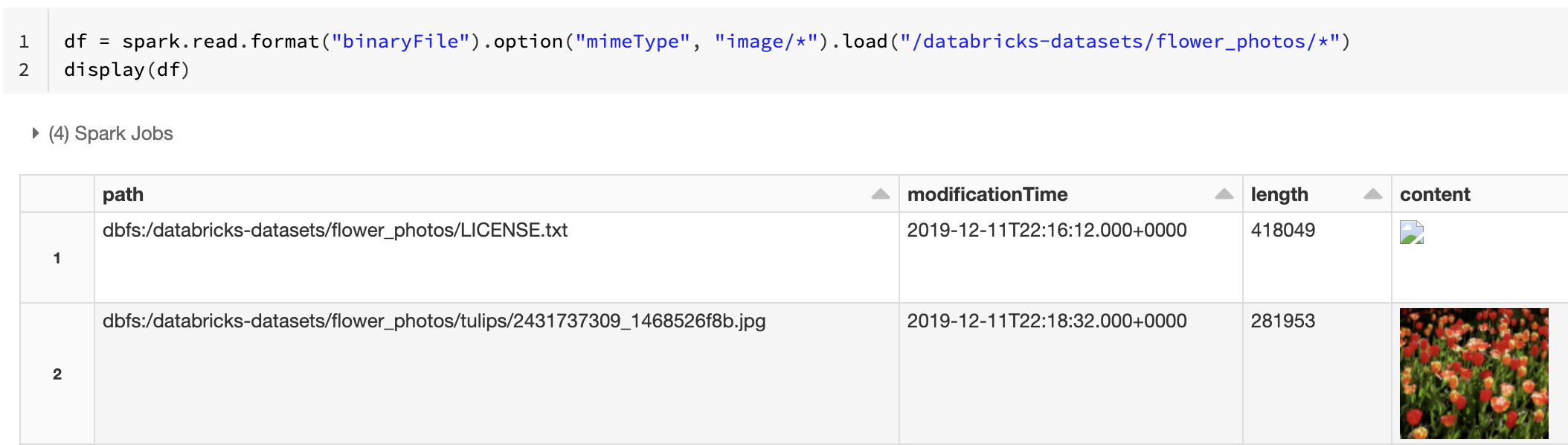
Alternativ können Sie die Bildvorschau erzwingen, indem Sie die Option mimeType mit einem Zeichenfolgenwert "image/*" verwenden, um die Binärspalte zu kommentieren. Bilder werden basierend auf ihren Formatinformationen im binären Inhalt decodiert. Unterstützte Bildtypen sind bmp, gif, jpeg und png. Nicht unterstützte Dateien werden mit einem Symbol für ein defektes Bild angezeigt.
Python
df = spark.read.format("binaryFile").option("mimeType", "image/*").load("/Volumes/<catalog>/<schema>/<volume>/images/")
display(df)
Scala
val df = spark.read.format("binaryFile").option("mimeType", "image/*").load("/Volumes/<catalog>/<schema>/<volume>/images/")
df.show()
SQL
SELECT * FROM read_files(
'/Volumes/<catalog>/<schema>/<volume>/images/',
format => 'binaryFile',
mimeType => 'image/*'
)
Siehe Referenzlösung für Bildanwendungen für den empfohlenen Workflow zum Umgang mit Image-Daten.
In Delta-Tabelle speichern
Um die Leseleistung beim Laden von Daten zu verbessern, empfiehlt Azure Databricks das Speichern von Daten, die aus Binärdateien in eine Delta-Tabelle geladen wurden.
Python
df.write.format("delta").saveAsTable("<catalog>.<schema>.<table>")
Scala
df.write.format("delta").saveAsTable("<catalog>.<schema>.<table>")
Weitere Ressourcen
- Lesen von Bilddateien: Wenn Ihre Workload strukturierte Bildfelder wie Höhe, Breite und Kanaldaten anstelle von unformatierten Bytes erfordert, stellt die Bilddatenquelle ein decodiertes Schema bereit.