Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Databricks Runtime für Machine Learning (Databricks Runtime ML) bietet eine vorgefertigte Machine Learning-Infrastruktur, die in alle Funktionen des Azure Databricks-Arbeitsbereichs integriert ist. Jede Version von Databricks Runtime ML basiert auf der entsprechenden Version von Databricks Runtime. Databricks Runtime 12.2 LTS für Machine Learning basiert beispielsweise auf Databricks Runtime 12.2 LTS.
Ausführliche Informationen zu den Funktionen jeder Version von Databricks Runtime ML, einschließlich der vollständigen Liste der enthaltenen Bibliotheken, finden Sie in den Versionshinweisen.
Warum Databricks Runtime für Machine Learning verwenden?
Databricks Runtime ML automatisiert die Erstellung eines Clusters, der für maschinelles Lernen optimiert ist. Zu den Vorteilen der Verwendung von Databricks Runtime ML-Clustern gehören:
- Integrierte beliebte Machine Learning-Bibliotheken wie TensorFlow, PyTorch, Keras und XGBoost.
- Integrierte verteilte Trainingsbibliotheken, z. B. Horovod.
- Kompatible Versionen installierter Bibliotheken.
- Vorkonfigurierte GPU-Unterstützung, einschließlich Treibern und unterstützenden Bibliotheken.
- Schnellere Clustererstellung.
Mit Azure Databricks können Sie eine beliebige Bibliothek verwenden, um die Logik zum Trainieren Ihres Modells zu erstellen. Die vorkonfigurierte Databricks Runtime ML ermöglicht ein problemloses Skalieren gängiger Machine Learning- und Deep Learning-Schritte.
Databricks Runtime ML umfasst auch alle Funktionen des Azure Databricks-Arbeitsbereichs, z. B.:
- Datenuntersuchung, -verwaltung und -governance.
- Erstellung und Verwaltung von Clustern.
- Bibliotheks- und Umgebungsverwaltung.
- Codeverwaltung mit Databricks-Repositorys.
- Automatisierungsunterstützung, einschließlich Delta Live Tables, Databricks-Aufträgen und APIs.
- Integrierter MLflow für die Modellentwicklungsnachverfolgung, -implementierung und -bereitstellung sowie Echtzeitrückschlüsse.
Vollständige Informationen zur Verwendung von Azure Databricks für maschinelles Lernen und Deep Learning finden Sie in der Einführung in Databricks Machine Learning.
In Databricks Runtime ML enthaltene Bibliotheken
Databricks Runtime ML enthält eine Vielzahl von gängigen ML-Bibliotheken. Bei jedem Release werden die Bibliotheken mit neuen Features und Fixes aktualisiert.
Eine Teilmenge der unterstützten Bibliotheken wurde von Azure Databricks als Bibliotheken der obersten Ebene festgelegt. Für diese Bibliotheken bietet Azure Databricks einen schnelleren Aktualisierungsrhythmus, bei dem mit jeder Runtime-Version auf die aktuellen Paketversionen aktualisiert wird (sofern es keine Abhängigkeitskonflikte gibt). Azure Databricks bietet außerdem erweiterte Unterstützung, Tests und eingebettete Optimierungen für Bibliotheken der obersten Ebene.
Eine vollständige Liste der Bibliotheken der obersten Ebene und anderer bereitgestellter Bibliotheken finden Sie in den Versionshinweisen für Databricks Runtime ML.
Erstellen eines Clusters mit Databricks Runtime ML
Wenn Sie einen Cluster erstellen, wählen Sie im Dropdownmenü für die Databricks Runtime-Version eine Version von Databricks Runtime ML aus. Es sind CPU- und GPU-fähige ML-Runtimes verfügbar.
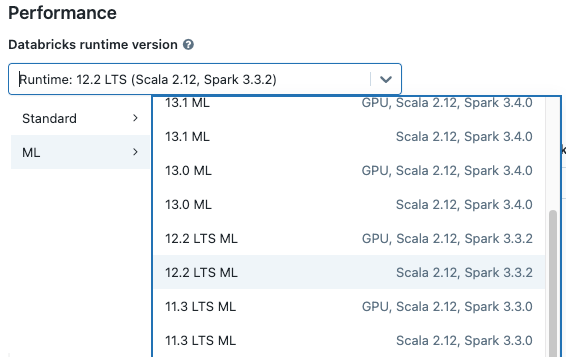
Wenn Sie im Notebook im Dropdownmenü einen Cluster auswählen, wird die Databricks Runtime-Version rechts neben dem Clusternamen angezeigt:
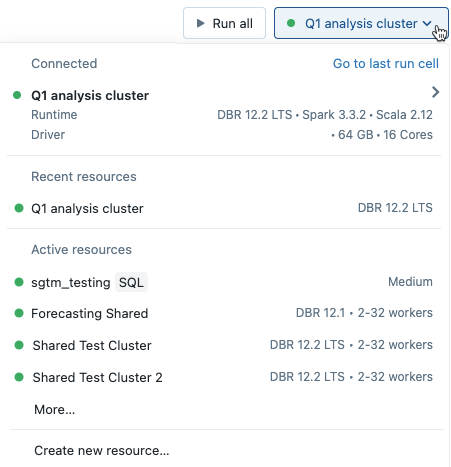
Wenn Sie eine GPU-fähige ML-Runtime auswählen, werden Sie aufgefordert, einen kompatiblen Treibertyp und Workertyp auszuwählen. Inkompatible Instanztypen sind in den Dropdownlisten ausgegraut. GPU-fähige Instanztypen werden unter der Bezeichnung GPU-beschleunigt aufgeführt.
Hinweis
Um in Unity Catalog auf Daten für Workflows zum maschinellen Lernen zuzugreifen, muss der Zugriffsmodus für den Cluster auf Einzelbenutzer (zugewiesen) eingestellt sein. Geteite Cluster sind nicht mit Databricks Runtime für Machine Learning kompatibel.
Verwalten von Python-Paketen
Databricks Runtime ML unterscheidet sich von Databricks Runtime darin, wie Sie Python-Pakete verwalten. In Databricks Runtime ML wird zum Installieren der Python-Pakete der virtualenv-Paket-Manager verwendet. Alle Python-Pakete werden in einer einzigen Umgebung installiert: /databricks/python3.
Informationen zum Verwalten von Python-Bibliotheken finden Sie unter Bibliotheken.
Support für automatisiertes maschinelles Lernen
Databricks Runtime ML enthält Tools, mit deren Hilfe Sie den Modellentwicklungsprozess automatisieren und das Modell mit der besten Leistung effizient finden können.
- AutoML erstellt automatisch eine Reihe von Modellen und erstellt ein Python-Notebook mit dem Quellcode für jede Ausführung, damit Sie den Code überprüfen, reproduzieren und ändern können.
- Managed MLFlow verwaltet den End-to-End-Modelllebenszyklus, einschließlich der Nachverfolgung experimenteller Läufe, der Bereitstellung und Freigabe von Modellen und der Verwaltung einer zentralisierten Modellregistrierung.
- Hyperopt, erweitert um die
SparkTrials-Klasse, automatisiert und verteilt die ML-Modellparameteroptimierung
Einschränkungen
Databricks Runtime ML wird nicht unterstützt unter:
- TableACLs-Cluster
- „Shared“ UC-Cluster
- Cluster mit auf
truefestgelegterspark.databricks.pyspark.enableProcessIsolation config.