Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Auf dieser Seite finden Sie eine Übersicht über die Tools und Ansätze zum Exportieren von Daten und Konfigurationen aus Ihrem Azure Databricks-Arbeitsbereich. Sie können Arbeitsbereichsressourcen für Complianceanforderungen, Datenübertragbarkeit, Sicherungszwecke oder Arbeitsbereichsmigration exportieren.
Überblick
Azure Databricks-Arbeitsbereiche enthalten eine Vielzahl von Ressourcen, darunter Arbeitsbereichskonfiguration, verwaltete Tabellen, AI- und ML-Objekte und daten, die in Cloudspeicher gespeichert sind. Wenn Sie Arbeitsbereichsdaten exportieren müssen, können Sie eine Kombination aus integrierten Tools und APIs verwenden, um diese Ressourcen systematisch zu extrahieren.
Häufige Gründe für den Export von Arbeitsbereichsdaten sind:
- Compliance-Anforderungen: Erfüllung von Datenübertragbarkeitspflichten gemäß Vorschriften wie DSGVO und CCPA.
- Sicherung und Notfallwiederherstellung: Erstellen von Kopien wichtiger Arbeitsbereichsressourcen für geschäftskontinuität.
- Arbeitsbereichmigration: Verschieben von Ressourcen zwischen Arbeitsbereichen oder Cloudanbietern.
- Überwachung und Archivierung: Beibehalten historischer Datensätze von Arbeitsbereichskonfiguration und -daten.
Planen des Exports
Bevor Sie mit dem Exportieren von Arbeitsbereichsdaten beginnen, erstellen Sie einen Bestand der Ressourcen, die Sie exportieren müssen, und verstehen Sie die Abhängigkeiten zwischen ihnen.
Verstehen von Arbeitsbereichsressourcen
Ihr Azure Databricks-Arbeitsbereich enthält mehrere Kategorien von Ressourcen, die Sie exportieren können:
- Arbeitsbereichskonfiguration: Notizbücher, Ordner, Repositorys, Geheime Schlüssel, Benutzer, Gruppen, Zugriffssteuerungslisten (ACCESS Control Lists), Clusterkonfigurationen und Auftragsdefinitionen.
- Datenressourcen: Verwaltete Tabellen, Datenbanken, Databricks File System-Dateien und Daten, die im Cloudspeicher gespeichert sind.
- Berechnen von Ressourcen: Clusterkonfigurationen, Richtlinien und Instanzenpooldefinitionen.
- AI- und ML-Ressourcen: MLflow-Experimente, Ausführungen, Modelle, Feature Store-Tabellen, Vektorsuchindizes und Unity-Katalogmodelle.
- Unity Catalog-Objekte: Metastore-Konfiguration, Kataloge, Schemas, Tabellen, Volumes und Berechtigungen.
Definieren Sie den Umfang Ihres Exports
Erstellen Sie eine Checkliste von Ressourcen, die basierend auf Ihren Anforderungen exportiert werden sollen. Stellen Sie sich die folgenden Fragen:
- Müssen Sie alle Ressourcen oder nur bestimmte Kategorien exportieren?
- Gibt es Compliance- oder Sicherheitsanforderungen, die bestimmen, welche Ressourcen Sie exportieren müssen?
- Müssen Sie Beziehungen zwischen Objekten beibehalten (z. B. Aufträge, die auf Notizbücher verweisen)?
- Müssen Sie die Arbeitsbereichskonfiguration in einer anderen Umgebung neu erstellen?
Wenn Sie Ihren Exportumfang planen, können Sie die richtigen Tools auswählen und fehlende kritische Abhängigkeiten vermeiden.
Exportieren der Arbeitsbereichskonfiguration
Der Terraform-Exporter ist das primäre Tool zum Exportieren der Arbeitsbereichskonfiguration. Es generiert Terraform-Konfigurationsdateien, die Ihre Arbeitsbereichsressourcen als Code darstellen.
Verwenden des Terraform-Exporters
Der Terraform-Exporter ist in den Azure Databricks Terraform-Anbieter integriert und generiert Terraform-Konfigurationsdateien für Arbeitsbereichsressourcen, darunter Notizbücher, Aufträge, Cluster, Benutzer, Gruppen, Geheimnisse und Zugriffssteuerungslisten. Der Exporter muss für jeden Arbeitsbereich separat ausgeführt werden. Siehe Databricks Terraform-Anbieter.
Voraussetzungen:
- Terraform auf Ihrer Maschine installiert
- Azure Databricks-Authentifizierung konfiguriert
- Administratorrechte für den Arbeitsbereich, den Sie exportieren möchten
So exportieren Sie Arbeitsbereichsressourcen:
Sehen Sie sich das Beispielverwendungsvideo für eine exemplarische Vorgehensweise des Exporters an.
Laden Sie den Terraform-Anbieter mit dem Exportertool herunter und installieren Sie es:
wget -q -O terraform-provider-databricks.zip $(curl -s https://api.github.com/repos/databricks/terraform-provider-databricks/releases/latest|grep browser_download_url|grep linux_amd64|sed -e 's|.*: "\([^"]*\)".*$|\1|') unzip -d terraform-provider-databricks terraform-provider-databricks.zipEinrichten von Authentifizierungsumgebungsvariablen für Ihren Arbeitsbereich:
export DATABRICKS_HOST=https://your-workspace-url export DATABRICKS_TOKEN=your-tokenFühren Sie den Exporter aus, um Terraform-Konfigurationsdateien zu generieren:
terraform-provider-databricks exporter \ -directory ./exported-workspace \ -listing notebooks,jobs,clusters,users,groups,secretsAllgemeine Exporteroptionen:
-
-listing: Angeben der zu exportierenden Ressourcentypen (durch Trennzeichen getrennt) -
-services: Alternative zum Auflisten von Ressourcen zum Filtern von Ressourcen -
-directory: Ausgabeverzeichnis für generierte.tfDateien -
-incremental: Im inkrementellen Modus für mehrstufige Migrationen ausführen
-
Überprüfen Sie die generierten
.tfDateien im Ausgabeverzeichnis. Der Exporter erstellt eine Datei für jeden Ressourcentyp.
Hinweis
Der Terraform-Exporter konzentriert sich auf arbeitsbereichskonfiguration und -metadaten. Die tatsächlichen Daten, die in Tabellen oder Databricks File System gespeichert sind, werden nicht exportiert. Sie müssen Daten separat exportieren, indem Sie die in den folgenden Abschnitten beschriebenen Ansätze verwenden.
Exportieren bestimmter Objekttypen
Verwenden Sie für Vermögenswerte, die nicht vollständig vom Terraform-Exporteur abgedeckt werden, die folgenden Ansätze:
- Notizbücher: Laden Sie Notizbücher einzeln über die Arbeitsbereichsbenutzeroberfläche herunter, oder verwenden Sie die Arbeitsbereichs-API, um Notizbücher programmgesteuert zu exportieren. Siehe Verwalten von Arbeitsbereichsobjekten.
- Geheime Schlüssel: Geheime Schlüssel können aus Sicherheitsgründen nicht direkt exportiert werden. Sie müssen Geheimnisse in der Zielumgebung manuell neu erstellen. Geheime Dokumentennamen und Umfänge zum Verweis.
- MLflow-Objekte: Verwenden Sie das mlflow-export-import-Tool zum Exportieren von Experimenten, Läufen und Modellen. Weitere Informationen finden Sie im Abschnitt "ML-Ressourcen " weiter unten.
Exportieren von Daten
Kundendaten befinden sich in der Regel in Ihrem Cloudkontospeicher, nicht in Azure Databricks. Sie müssen keine Daten exportieren, die sich bereits in Ihrem Cloudspeicher befinden. Sie müssen jedoch Daten exportieren, die an von Azure Databricks verwalteten Speicherorten gespeichert sind.
Exportieren verwalteter Tabellen
Obwohl verwaltete Tabellen in Ihrem Cloudspeicher gespeichert sind, werden sie in einer UUID-basierten Hierarchie gespeichert, die schwierig zu analysieren sein kann. Sie können den DEEP CLONE Befehl verwenden, um verwaltete Tabellen an einer bestimmten Stelle als externe Tabellen umzuschreiben, wodurch sie einfacher arbeiten können.
Beispielbefehle DEEP CLONE :
CREATE TABLE delta.`abfss://container@storage.dfs.core.windows.net/path/to/storage/`
DEEP CLONE my_catalog.my_schema.my_table
Ein vollständiges Skript zum Klonen aller Tabellen in einer Liste von Katalogen finden Sie im folgenden Beispielskript.
Exportieren des Databricks-Standardspeichers
Für serverlose Arbeitsbereiche bietet Azure Databricks Standardspeicher, bei dem es sich um eine vollständig verwaltete Speicherlösung innerhalb des Azure Databricks-Kontos handelt. Daten im Standardspeicher müssen vor dem Löschen oder Außerbetriebnahme des Arbeitsbereichs in kundeneigene Speichercontainer exportiert werden. Weitere Informationen zu serverlosen Arbeitsbereichen finden Sie unter Erstellen eines serverlosen Arbeitsbereichs.
Verwenden Sie DEEP CLONE, um Daten aus Tabellen im Standardspeicher in einen kundeneigenen Speichercontainer zu schreiben. Folgen Sie für Volumes und beliebige Dateien den gleichen Mustern, die unten im DbFS-Stammexportabschnitt beschrieben sind.
Databricks-Dateisystemstamm exportieren
Der Stamm des Databricks-Dateisystems ist der ältere Speicherort in Ihrem Arbeitsbereichsspeicherkonto, das möglicherweise Kundenressourcen, Benutzeruploads,Itskripts, Bibliotheken und Tabellen enthalten kann. Obwohl der Stamm des Databricks-Dateisystems ein veraltetes Speichermuster ist, sind in älteren Arbeitsbereichen möglicherweise weiterhin Daten an diesem Speicherort gespeichert, die exportiert werden müssen. Weitere Informationen zur Arbeitsbereichsspeicherarchitektur finden Sie unter Arbeitsbereichsspeicher.
Stammverzeichnis des Databricks-Dateisystems exportieren:
Da Root-Buckets in Azure privat sind, können Sie Azure-eigene Tools wie azcopy nicht verwenden, um Daten zwischen Speicherkonten zu verschieben. Verwenden Sie dbutils fs cp und Delta DEEP CLONE stattdessen innerhalb von Azure Databricks. Dies kann je nach Datenvolumen sehr lange dauern.
# Copy DBFS files to a local path
dbutils.fs.cp("dbfs:/path/to/remote/folder", "/path/to/local/folder", recurse=True)
Verwenden Sie DEEP CLONE für Tabellen im Stammspeicher des Databricks-Dateisystems.
CREATE TABLE delta.`abfss://container@storage.dfs.core.windows.net/path/to/external/storage/`
DEEP CLONE delta.`dbfs:/path/to/dbfs/location`
Von Bedeutung
Durch den Export großer Datenmengen aus dem Cloudspeicher können erhebliche Datenübertragungs- und Speicherkosten entstehen. Überprüfen Sie die Preise Ihres Cloudanbieters, bevor Sie große Exporte initiieren.
Häufige Exportprobleme
Geheimnisse:
Geheime Schlüssel können aus Sicherheitsgründen nicht direkt exportiert werden. Bei Verwendung des Terraform-Exporters mit der -export-secrets Option generiert der Exporteur eine Variable vars.tf mit demselben Namen wie das Geheimnis. Sie müssen diese Datei manuell mit den tatsächlichen geheimen Werten aktualisieren oder den Terraform-Exporter mit der -export-secrets Option ausführen (nur für geheime Azure Databricks-verwaltete Geheimnisse).
Azure Databricks empfiehlt die Verwendung eines Azure Key Vault-unterstützten Geheimspeichers.
Exportieren von KI- und ML-Ressourcen
Einige KI- und ML-Ressourcen erfordern unterschiedliche Tools und Ansätze für den Export. Unity-Katalogmodelle werden als Teil des Terraform-Exporters exportiert.
MLflow-Objekte
MLflow wird nicht vom Terraform-Exporter durch Lücken in der API und Schwierigkeiten bei der Serialisierung abgedeckt. Verwenden Sie zum Exportieren von MLflow-Experimenten, -Ausführungen, -Modellen und -Artefakten das mlflow-export-import-Tool . Dieses Open-Source-Tool bietet eine halb vollständige Abdeckung der MLflow-Migration.
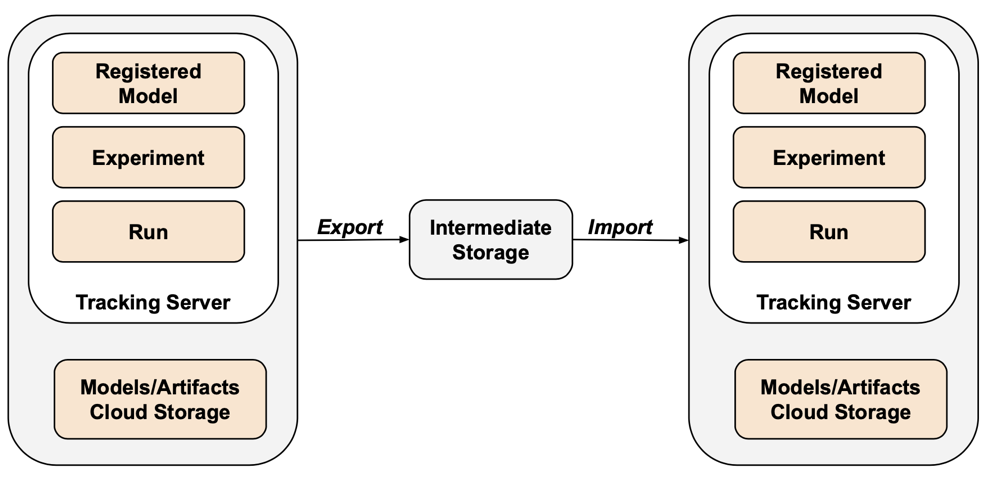
Für exportgeschützte Szenarien können Sie alle MLflow-Ressourcen in einem kundeneigenen Bucket speichern, ohne den Importschritt ausführen zu müssen. Weitere Informationen zur MLflow-Verwaltung finden Sie unter Verwalten des Modelllebenszyklus im Unity-Katalog.
Feature Store und Vektorsuche
Vektorsuchindizes: Vektorsuchindizes gelten nicht im Rahmen der EU-Datenexportverfahren. Wenn Sie sie trotzdem exportieren möchten, müssen sie in eine Standardtabelle geschrieben und dann mit DEEP CLONEexportiert werden.
Feature Store-Tabellen: Der Feature Store sollte ähnlich wie Vektorsuchindizes behandelt werden. Wählen Sie mit SQL relevante Daten aus, und schreiben Sie sie in eine Standardtabelle, und exportieren Sie dann mithilfe DEEP CLONEvon .
Überprüfen exportierter Daten
Überprüfen Sie nach dem Exportieren von Arbeitsbereichsdaten, ob Aufträge, Benutzer, Notizbücher und andere Ressourcen ordnungsgemäß exportiert wurden, bevor die alte Umgebung außer Betrieb genommen wird. Verwenden Sie die Prüfliste, die Sie während der Bereichs- und Planungsphase erstellt haben, um zu überprüfen, ob alles, was Sie exportieren möchten, erfolgreich exportiert wurde.
Prüfliste zur Überprüfung
Verwenden Sie diese Checkliste, um Ihren Export zu überprüfen:
- Konfigurationsdateien generiert: Terraform-Konfigurationsdateien werden für alle erforderlichen Arbeitsbereichsressourcen erstellt.
- Exportierte Notizbücher: Alle Notizbücher werden mit ihren Inhalten und Metadaten exportiert.
- Tabellen geklont: Verwaltete Tabellen werden erfolgreich an den Exportspeicherort geklont.
- Kopierte Datendateien: Cloudspeicherdaten werden vollständig ohne Fehler kopiert.
- MLflow-Objekte exportiert: Experimente, Ausführungen und Modelle werden mit ihren Artefakten exportiert.
- Dokumentierte Berechtigungen: Zugriffssteuerungslisten und -berechtigungen werden in der Terraform-Konfiguration erfasst.
- Ermittelte Abhängigkeiten: Beziehungen zwischen Objekten (z. B. Aufträge, die auf Notizbücher verweisen) werden im Export beibehalten.
Bewährte Methoden nach dem Export
Validierungs- und Akzeptanztests werden weitgehend von Ihren Anforderungen gesteuert und können stark variieren. Die folgenden allgemeinen bewährten Methoden gelten jedoch:
- Definieren Sie ein Testbett: Erstellen Sie ein Testbett aus Aufträgen oder Notizbüchern, die überprüfen, ob Geheimnisse, Daten, Einbindungen, Connectors und andere Abhängigkeiten in der exportierten Umgebung korrekt funktionieren.
- Beginnen Sie mit Entwicklungsumgebungen: Wenn Sie sich in einer mehrstufigen Weise bewegen, beginnen Sie mit der Entwicklungsumgebung und arbeiten bis zur Produktion. Dies zeigt wichtige Probleme frühzeitig an und vermeidet produktionsbezogene Auswirkungen.
- Nutzen Sie Git-Ordner: Verwenden Sie nach Möglichkeit Git-Ordner, da sie in einem externen Git-Repository gespeichert sind. Dadurch wird der manuelle Export vermieden und sichergestellt, dass Code in allen Umgebungen identisch ist.
- Dokumentieren Sie den Exportvorgang: Zeichnen Sie die verwendeten Tools, ausgeführten Befehle und alle aufgetretenen Probleme auf.
- Sichere exportierte Daten: Stellen Sie sicher, dass exportierte Daten sicher mit entsprechenden Zugriffssteuerungen gespeichert werden, insbesondere, wenn sie vertrauliche oder persönlich identifizierbare Informationen enthält.
- Compliance beibehalten: Wenn der Export zu Compliance-Zwecken erfolgt, überprüfen Sie, ob der Export gesetzliche Anforderungen und Aufbewahrungsrichtlinien erfüllt.
Beispielskripts und Automatisierung
Sie können Arbeitsbereichsexporte mithilfe von Skripts und geplanten Aufträgen automatisieren.
Deep Clone-Exportskript
Das folgende Skript exportiert verwaltete Tabellen im Unity-Katalog mithilfe von DEEP CLONE. Dieser Code sollte im Quellarbeitsbereich ausgeführt werden, um einen bestimmten Katalog in einen Zwischen bucket zu exportieren. Aktualisieren Sie die Variablen catalogs_to_copy und dest_bucket.
import pandas as pd
# define catalogs and destination bucket
catalogs_to_copy = ["my_catalog_name"]
dest_bucket = "<cloud-storage-path>://my-intermediate-bucket"
manifest_name = "manifest"
# initialize vars
system_info = sql("SELECT * FROM system.information_schema.tables")
copied_table_names = []
copied_table_types = []
copied_table_schemas = []
copied_table_catalogs = []
copied_table_locations = []
# loop through all catalogs to copy, then copy all non-system tables
# note: this would likely be parallelized using thread pooling in prod
for catalog in catalogs_to_copy:
filtered_tables = system_info.filter((system_info.table_catalog == catalog) & (system_info.table_schema != "information_schema"))
for table in filtered_tables.collect():
schema = table['table_schema']
table_name = table['table_name']
table_type = table['table_type']
print(f"Copying table {schema}.{table_name}...")
target_location = f"{dest_bucket}/{catalog}_{schema}_{table_name}"
sqlstring = f"CREATE TABLE delta.`{target_location}` DEEP CLONE {catalog}.{schema}.{table_name}"
sql(sqlstring)
# lists used to create manifest table DF
copied_table_names.append(table_name)
copied_table_types.append(table_type)
copied_table_schemas.append(schema)
copied_table_catalogs.append(catalog)
copied_table_locations.append(target_location)
# create the manifest as a df and write to a table in dr target
# this contains catalog, schema, table and location
manifest_df = pd.DataFrame({"catalog": copied_table_catalogs,
"schema": copied_table_schemas,
"table": copied_table_names,
"location": copied_table_locations,
"type": copied_table_types})
spark.createDataFrame(manifest_df).write.mode("overwrite").format("delta").save(f"{dest_bucket}/{manifest_name}")
display(manifest_df)
Überlegungen zur Automatisierung
Beim Automatisieren von Exporten:
- Verwenden Sie geplante Aufträge: Erstellen Sie Azure Databricks-Aufträge, die Exportskripts regelmäßig ausführen.
- Überwachen von Exportaufträgen: Konfigurieren Sie Warnungen, um Sie zu benachrichtigen, wenn Exporte fehlschlagen oder länger als erwartet dauern.
- Verwalten von Anmeldeinformationen: Speichern sie Anmeldeinformationen und API-Token sicher mithilfe von Azure Databricks-Geheimschlüsseln. Siehe Verwaltung von Geheimnissen.
- Versionsexporte: Verwenden Sie Zeitstempel oder Versionsnummern in Exportpfaden, um historische Exporte beizubehalten.
- Bereinigen Sie alte Exporte: Implementieren Sie Aufbewahrungsrichtlinien zum Löschen alter Exporte und zur Verwaltung der Speicherkosten.
- Inkrementelle Exporte: Für große Arbeitsbereiche sollten Sie inkrementelle Exporte implementieren, die nur die seit dem letzten Export geänderten Daten exportieren.