Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure Databricks unterstützt sparklyr in Notebooks, Aufträgen und RStudio Desktop. In diesem Artikel wird die Verwendung von sparklyr beschrieben. Außerdem werden Beispielskripts bereitgestellt, die Sie ausführen können. Weitere Informationen finden Sie unter R-Schnittstelle zu Apache Spark.
Anforderungen
Azure Databricks stellt die neueste stabile Version von sparklyr mit jedem Databricks Runtime-Release bereit. Sie können sparklyr in Azure Databricks R-Notebooks oder in RStudio Server verwenden, das auf Azure Databricks gehostet wird, indem Sie die installierte Version von sparklyr importieren.
In RStudio Desktop können Sie mit Databricks Verbinden Sparklyr von Ihrem lokalen Computer aus mit Azure Databricks-Clustern verbinden und Apache Spark ausführen. Siehe Verwenden von sparklyr und RStudio Desktop mit Databricks Connect.
sparklyr mit Azure Databricks-Clustern verbinden
Um eine Sparklyr-Verbindung herzustellen, können Sie "databricks" als Verbindungsmethode in spark_connect() verwenden.
Es sind keine zusätzlichen Parameter für spark_connect() erforderlich, und es wird auch kein Aufruf von spark_install() benötigt, da Spark bereits auf einem Azure Databricks ist.
# Calling spark_connect() requires the sparklyr package to be loaded first.
library(sparklyr)
# Create a sparklyr connection.
sc <- spark_connect(method = "databricks")
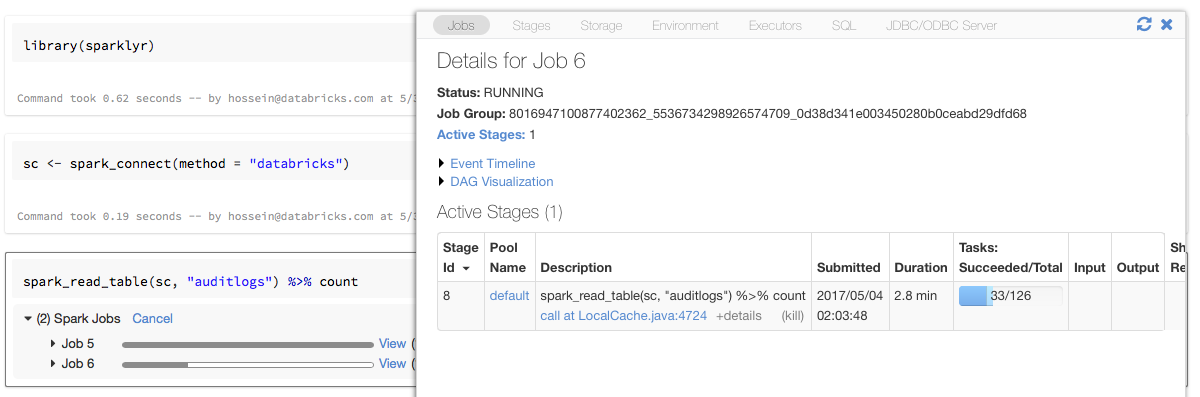
Statusleisten und Spark-Benutzeroberfläche mit sparklyr
Wenn Sie das Sparklyr-Verbindungsobjekt einer Variablen namens sc wie im obigen Beispiel zuweisen, werden spark-Statusleisten im Notebook nach jedem Befehl angezeigt, der Spark-Aufträge auslöst.
Darüber hinaus können Sie auf den Link neben der Statusanzeige klicken, um die Spark-Benutzeroberfläche anzuzeigen, die dem angegebenen Spark-Auftrag zugeordnet ist.
sparklyr verwenden
Nachdem Sie sparklyr installiert und die Verbindung hergestellt haben, funktionieren alle anderen sparklyr-APIs wie gewohnt. Einige Beispiele finden Sie im Beispiel-Notebook.
sparklyr wird in der Regel zusammen mit anderen Tidyverse-Paketen wie dplyr verwendet. Die meisten dieser Pakete sind zur Vereinfachung in Databricks vorinstalliert. Sie können sie einfach importieren und mit der Verwendung der API beginnen.
sparklyr und SparkR zusammen verwenden
SparkR und sparklyr können zusammen in einem einzelnen Notebook oder Auftrag verwendet werden. Sie können SparkR zusammen mit sparklyr importieren und dessen Funktionalität verwenden. In Azure Databricks Notebooks ist die SparkR-Verbindung vorkonfiguriert.
Einige der Funktionen in SparkR maskieren eine Reihe von Funktionen in dplyr:
> library(SparkR)
The following objects are masked from ‘package:dplyr’:
arrange, between, coalesce, collect, contains, count, cume_dist,
dense_rank, desc, distinct, explain, filter, first, group_by,
intersect, lag, last, lead, mutate, n, n_distinct, ntile,
percent_rank, rename, row_number, sample_frac, select, sql,
summarize, union
Wenn Sie SparkR importieren, nachdem Sie dplyr importiert haben, können Sie auf die Funktionen in dplyr verweisen, indem Sie die vollqualifizierten Namen verwenden, z. B. dplyr::arrange().
Wenn Sie dplyr nach SparkR importieren, werden die Funktionen in SparkR ebenfalls von dplyr maskiert.
Alternativ können Sie eines der beiden Pakete selektiv trennen, ohne es zu benötigen.
detach("package:dplyr")
Siehe auch Vergleich von SparkR und sparklyr.
Verwenden von sparklyr in spark-submit-Aufträgen
Sie können Skripts, die sparklyr in Azure Databricks verwenden, mit geringfügigen Änderungen am Code als spark-submit-Aufträge ausführen. Einige der obigen Anweisungen gelten nicht für die Verwendung von sparklyr in spark-submit-Aufträgen auf Azure Databricks. Insbesondere müssen Sie die Spark-Master-URL für spark_connect angeben. Beispiele:
library(sparklyr)
sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>")
...
Nicht unterstützte Funktionen
Azure Databricks unterstützt keine sparklyr-Methoden wie spark_web() und spark_log(), die einen lokalen Browser erfordern. Da die Spark-Benutzeroberfläche jedoch in Azure Databricks integriert ist, können Sie Spark-Aufträge und -Protokolle problemlos überprüfen.
Siehe Computetreiber- und Arbeitsprotokolle.
Beispielnotizbuch: Sparklyr-Demonstration
Sparklyr-Notebook
Weitere Beispiele finden Sie unter Arbeiten mit DataFrames und Tabellen in R.