Azure CI/CD-Datenpipelinen
Azure DevOps Services
In diesem Artikel werden Die Datenpipelinen für die kontinuierliche Azure-Integration und die kontinuierliche Bereitstellung (CI/CD) sowie ihre Bedeutung für Data Science erläutert.
Sie können Datenpipelines für Folgendes verwenden:
- Daten aus verschiedenen Datenquellen aufnehmen.
- Verarbeiten und Transformieren der Daten.
- Speichern Sie die verarbeiteten Daten an einem Stagingspeicherort, den andere nutzen können.
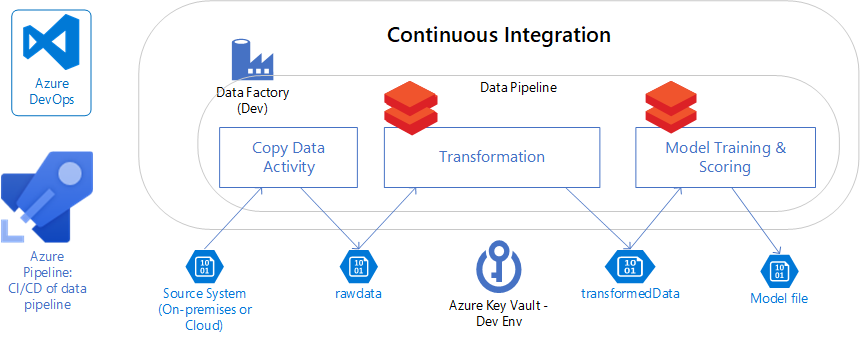
Enterprise-Datenpipelines können sich in komplexere Szenarien mit mehreren Quellsystemen und verschiedenen unterstützten Downstreamanwendungen entwickeln.
Datenpipelines bieten Folgendes:
- Konsistenz, indem Daten in ein konsistentes Format umgewandelt werden, das benutzer nutzen können.
- Fehlerreduzierung, indem sie automatisierte Datenpipelinen verwenden, um menschliche Fehler beim Bearbeiten von Daten zu beseitigen.
- Effizienz durch Reduzierung der Zeitaufwand für die Datenverarbeitungstransformation.
Mit Datenpipelines können Sich Datenprofis auf ihre Kernaufgaben konzentrieren, Einblicke aus den Daten erhalten und Unternehmen dabei helfen, bessere Entscheidungen zu treffen.
Continuous Integration und Continuous Delivery (CI/CD)
Kontinuierliche Integration und kontinuierliche Bereitstellung (CI/CD) ist ein Softwareentwicklungsansatz, bei dem alle Entwickler in einem freigegebenen Code-Repository von Code zusammenarbeiten. Wenn Entwickler Änderungen vornehmen, erkennen automatisierte Prozesse Codeprobleme. Das Ergebnis der Verwendung von CI/CD ist ein schnellerer Entwicklungslebenszyklus mit niedrigeren Fehlerraten.
CI/CD-Datenpipelinen in Data Science
Das Erstellen von Machine Learning-Modellen ähnelt der herkömmlichen Softwareentwicklung, in der Data Scientists Code schreiben, um Machine Learning-Modelle zu trainieren und zu scoren. Im Gegensatz zu herkömmlicher Software, die auf Code basiert, basieren Data Science Machine Learning-Modelle sowohl auf Code wie Algorithmen und Hyperparametern als auch auf den Daten, die zum Trainieren der Modelle verwendet werden. Die meisten Datenwissenschaftler sagen, sie verbringen 80 % ihrer Zeit mit der Datenvorbereitung, Reinigung und Featuretechnik.
Um die Qualität von Machine Learning-Modellen zu gewährleisten, werden auch Techniken wie A/B-Tests verwendet, um die Modellleistung zu vergleichen und aufrechtzuerhalten. A/B-Tests verwenden in der Regel ein Steuerungsmodell und ein oder mehrere Behandlungsmodelle.
Mehrere Machine Learning-Modelle können gleichzeitig verwendet werden, wodurch eine weitere Komplexitätsebene für die CI/CD von Machine Learning-Modellen hinzugefügt wird. Eine CI/CD-Datenpipeline ist für das Data Science-Team von entscheidender Bedeutung, um dem Unternehmen qualitativ hochwertige Machine Learning-Modelle zeitnah zu liefern.
Nächste Schritte
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für