Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Erstellen Sie einen intelligenten KI-Agent mithilfe von TypeScript und Azure DocumentDB. Diese Schnellstartanleitung veranschaulicht eine Zwei-Agent-Architektur, die die semantische Hotelsuche durchführt und personalisierte Empfehlungen generiert.
Von Bedeutung
In diesem Beispiel wird LangChain verwendet, ein beliebtes Framework zum Erstellen von KI-Anwendungen. LangChain bietet Abstraktionen für Agents, Tools und Eingabeaufforderungen, die die Agententwicklung vereinfachen.
Voraussetzungen
Sie können die Azure Developer CLI verwenden, um die erforderlichen Azure-Ressourcen zu erstellen, indem Sie die azd Befehle im Beispiel-Repository ausführen. Weitere Informationen finden Sie unter Deploy Infrastructure with Azure Developer CLI.
Azure-Ressourcen
Azure OpenAI in der Microsoft Foundry Models-Ressource (klassisch) mit den folgenden Modellbereitstellungen in Microsoft Azure AI Foundry:
-
gpt-4oBereitstellung (Synthesizer Agent) - Empfohlen: 50.000 Token pro Minute (TPM) Kapazität -
gpt-4o-miniBereitstellung (Planner Agent) – Empfohlen: 30.000 Token pro Minute (TPM) Kapazität -
text-embedding-3-smallBereitstellung (Embeddings) - Empfohlen: 10.000 Token pro Minute (TPM) Kapazität -
Tokenkontingente: Konfigurieren Sie für jede Bereitstellung ausreichende TPM, um eine Ratenbeschränkung zu vermeiden.
- Siehe Verwalten von Azure OpenAI-Kontingenten für die Kontingentverwaltung
- Wenn 429 Fehler auftreten, erhöhen Sie ihr TPM-Kontingent, oder verringern Sie die Anforderungshäufigkeit.
-
Azure DocumentDB (mit MongoDB-Kompatibilität) Cluster mit Vektorsuchunterstützung:
-
Anforderungen der Clusterebene basierend auf dem bevorzugten Vektorindexalgorithmus:
- IVF (Invertierter Dateiindex): M10 oder höher (Standardalgorithmus)
- HNSW (hierarchische navigierbare Kleine Welt): M30 oder höher (graphbasiert)
- DiskANN: M40 oder höher (optimiert für groß angelegte Anwendungen)
-
Firewallkonfiguration: ERFORDERLICH. Ohne ordnungsgemäße Firewallkonfiguration schlagen Verbindungsversuche fehl.
- Fügen Sie Ihre Client-IP-Adresse zu den Firewallregeln des Clusters hinzu. Weitere Informationen finden Sie unter Gewähren des Zugriffs von Ihrer IP-Adresse.
- Stellen Sie für die kennwortlose Authentifizierung sicher, dass die rollenbasierte Zugriffssteuerung (RBAC) aktiviert ist.
-
Anforderungen der Clusterebene basierend auf dem bevorzugten Vektorindexalgorithmus:
Entwicklungstools
- Azure Developer CLI für die Ressourcenbereitstellung
- Node.js LTS
- TypeScript 5.0 oder höher
- Azure CLI für die Authentifizierung
- Visual Studio Code mit der DocumentDB-Erweiterung für die Datenbankverwaltung (optional)
Agentische RAG-Anwendungsarchitektur für Node.js
Im Beispiel wird eine Zwei-Agent-Architektur verwendet, in der jeder Agent eine bestimmte Rolle hat.

In diesem Beispiel wird das Agentframework von LangChain mit dem OpenAI SDK verwendet. Es nutzt langChains Funktionsaufrufe für die Toolintegration und folgt einem linearen Workflow zwischen den Agents und dem Suchtool. Die Ausführung erfolgt statuslos und ohne Historie der Kommunikation, so dass sie sich für Abfrage- und Antwortszenarien mit nur einem Durchgang eignet.
Node.js-Beispielcode abrufen
Klonen Sie oder laden Sie das Repository Azure DocumentDB Samples auf Ihren lokalen Computer herunter, um den Schnellstartanweisungen zu folgen.
Navigieren Sie zum Projektverzeichnis:
cd ai/vector-search-agent-typescript
Bereitstellen von Azure-Ressourcen mit azure Developer CLI
Verwenden Sie die Azure Developer CLI (azd), um die erforderlichen Azure OpenAI- und DocumentDB-Ressourcen bereitzustellen.
Melden Sie sich bei Azure an:
azd auth login** Bereitstellung und Implementierung der Infrastruktur:
azd upWenn Sie dazu aufgefordert werden, wählen Sie Ihr Abonnement und einen Standort aus (z. B.
swedencentralodereastus2).Nachdem die Bereitstellung abgeschlossen ist, werden die benötigten Umgebungsvariablen
azdausgegeben. Kopieren Sie sie in Ihre.envDatei (siehe Konfigurieren von Umgebungsvariablen).
Tipp
Führen Sie die Ausführung azd env get-values jederzeit aus, um die aktuellen Umgebungswerte anzuzeigen.
Umgebungsvariablen konfigurieren
Wenn Sie Ihre Azure-Ressourcen manuell erstellt oder Ihre eigenen vorhandenen Ressourcen verwenden möchten, müssen Sie Umgebungsvariablen für die Anwendung konfigurieren, um eine Verbindung mit Azure OpenAI und Azure DocumentDB herzustellen. Wenn Sie azd up verwendet haben, können Sie diesen Schritt überspringen, da die erforderlichen Umgebungsvariablen automatisch in der azd Umgebung festgelegt werden und mit azd env get-values darauf zugegriffen werden kann.
Erstellen Sie eine .env Datei im Projektstamm, um Umgebungsvariablen zu konfigurieren. Sie können eine Kopie der .env.sample Datei aus dem Repository erstellen.
Bearbeiten Sie die .env Datei, und ersetzen Sie diese Platzhalterwerte:
Diese Schnellstartanleitung verwendet eine Zwei-Agent-Architektur (Planner + Synthesizer) mit drei Modellbereitstellungen (zwei Chatmodelle + Einbettungen). Die Umgebungsvariablen werden für jede Modellbereitstellung konfiguriert.
-
AZURE_OPENAI_PLANNER_MODEL: Der Name Ihres gpt-4o-mini-Modells -
AZURE_OPENAI_SYNTH_MODEL: Name des gpt-4o-Modells -
AZURE_OPENAI_EMBEDDING_MODEL: Der Name Ihres text-embedding-3-small-Modells
Sie können zwischen zwei Authentifizierungsmethoden wählen: kennwortlose Authentifizierung mit Azure Identity (empfohlen) oder herkömmlicher Verbindungszeichenfolge und API-Schlüssel.
Option 1: Kennwortlose Authentifizierung
Verwenden Sie kennwortlose Authentifizierung mit Azure OpenAI und Azure DocumentDB. Set USE_PASSWORDLESS=true, AZURE_OPENAI_ENDPOINT und AZURE_DOCUMENTDB_CLUSTER.
# Enable passwordless authentication
USE_PASSWORDLESS=true
# Azure OpenAI Configuration (passwordless)
AZURE_OPENAI_ENDPOINT=your-openai-endpoint
AZURE_OPENAI_PLANNER_MODEL=gpt-4o-mini
AZURE_OPENAI_PLANNER_API_VERSION=2024-08-01-preview
AZURE_OPENAI_SYNTH_MODEL=gpt-4o
AZURE_OPENAI_SYNTH_API_VERSION=2024-08-01-preview
AZURE_OPENAI_EMBEDDING_MODEL=text-embedding-3-small
AZURE_OPENAI_EMBEDDING_API_VERSION=2023-05-15
# Azure DocumentDB (passwordless)
AZURE_DOCUMENTDB_CLUSTER=your-mongo-cluster-name
AZURE_DOCUMENTDB_DATABASENAME=Hotels
AZURE_DOCUMENTDB_COLLECTION=hotel_data
# Data Configuration
DATA_FILE_WITHOUT_VECTORS=../data/Hotels.json
# Vector Index Configuration
VECTOR_INDEX_ALGORITHM=vector-ivf
EMBEDDING_DIMENSIONS=1536
Voraussetzungen für die kennwortlose Authentifizierung:
Stellen Sie sicher, dass Sie bei Azure angemeldet sind:
az loginGewähren Sie Ihrer Identität die folgenden Rollen:
-
Cognitive Services OpenAI Userauf der Azure OpenAI-Ressource -
DocumentDB Account ContributorundCosmos DB Account Reader Roleauf der Azure DocumentDB-Ressource
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zuweisen von Azure-Rollen mithilfe des Azure-Portals.
-
Funktionsweise der kennwortlosen Authentifizierung
Wenn USE_PASSWORDLESS=true, verwendet die Anwendung DefaultAzureCredential aus dem Azure Identity SDK, um ein OAuth-Token zu erhalten. Bei Azure DocumentDB-Verbindungen wird ein OIDC-Tokenrückruf verwendet, der das Zugriffstoken direkt an den MongoDB-Treiber übergibt. Dies bedeutet, dass keine Kennwörter oder Verbindungszeichenfolgen in Konfigurationsdateien gespeichert werden.
Der Authentifizierungsfluss:
-
DefaultAzureCredentialsucht nach verfügbaren Anmeldeinformationen (Azure CLI, verwaltete Identität, Umgebungsvariablen) in der Reihenfolge. - Für Azure OpenAI wird das Token automatisch an die LangChain
AzureChatOpenAIundAzureOpenAIEmbeddingsClients übergeben. - Bei Azure DocumentDB ruft eine Tokenrückruffunktion ein Zugriffstoken ab und stellt es über den
MONGODB-OIDCAuthentifizierungsmechanismus dem MongoDB-Client bereit.
import { AzureOpenAIEmbeddings, AzureChatOpenAI } from "@langchain/openai";
import { MongoClient, OIDCCallbackParams } from 'mongodb';
import { AccessToken, DefaultAzureCredential, TokenCredential, getBearerTokenProvider } from '@azure/identity';
/*
This file contains utility functions to create Azure OpenAI clients for embeddings, planning, and synthesis.
It supports two modes of authentication:
1. API Key based authentication using AZURE_OPENAI_API_KEY and AZURE_OPENAI_ENDPOINTenvironment variables.
2. Passwordless authentication using DefaultAzureCredential from Azure Identity library.
*/
// Azure Identity configuration
const OPENAI_SCOPE = 'https://cognitiveservices.azure.com/.default';
const DOCUMENT_DB_SCOPE = 'https://ossrdbms-aad.database.windows.net/.default';
// Azure identity credential (used for passwordless auth)
const CREDENTIAL = new DefaultAzureCredential();
function requireEnvVars(names: string[]) {
const missing = names.filter((name) => {
const value = process.env[name];
return !value || value.trim().length === 0;
});
if (missing.length > 0) {
throw new Error(`Missing required environment variables: ${missing.join(', ')}`);
}
}
// Token callback for MongoDB OIDC authentication
async function azureIdentityTokenCallback(
params: OIDCCallbackParams,
credential: TokenCredential
): Promise<{ accessToken: string; expiresInSeconds: number }> {
const tokenResponse: AccessToken | null = await credential.getToken([DOCUMENT_DB_SCOPE]);
return {
accessToken: tokenResponse?.token || '',
expiresInSeconds: (tokenResponse?.expiresOnTimestamp || 0) - Math.floor(Date.now() / 1000)
};
Option 2: Verbindungszeichenfolge und API-Schlüsselauthentifizierung
Verwenden Sie die schlüsselbasierte Authentifizierung, indem Sie USE_PASSWORDLESS=false festlegen (oder weglassen) und die Werte AZURE_OPENAI_API_KEY und AZURE_DOCUMENTDB_CONNECTION_STRING in Ihrer .env-Datei bereitstellen.
# Disable passwordless authentication
USE_PASSWORDLESS=false
# Azure OpenAI Configuration (API key)
AZURE_OPENAI_ENDPOINT=your-openai-endpoint
AZURE_OPENAI_API_KEY=your-azure-openai-api-key
AZURE_OPENAI_PLANNER_MODEL=gpt-4o-mini
AZURE_OPENAI_PLANNER_API_VERSION=2024-08-01-preview
AZURE_OPENAI_SYNTH_MODEL=gpt-4o
AZURE_OPENAI_SYNTH_API_VERSION=2024-08-01-preview
AZURE_OPENAI_EMBEDDING_MODEL=text-embedding-3-small
AZURE_OPENAI_EMBEDDING_API_VERSION=2023-05-15
# Azure DocumentDB (connection string)
AZURE_DOCUMENTDB_CLUSTER=your-mongo-cluster-name
AZURE_DOCUMENTDB_CONNECTION_STRING=mongodb+srv://username:password@cluster.mongocluster.cosmos.azure.com/
AZURE_DOCUMENTDB_DATABASENAME=Hotels
AZURE_DOCUMENTDB_COLLECTION=hotel_data
# Data Configuration
DATA_FILE_WITHOUT_VECTORS=../data/Hotels.json
# Vector Index Configuration
VECTOR_INDEX_ALGORITHM=vector-ivf
EMBEDDING_DIMENSIONS=1536
Projektstruktur
Das Projekt folgt einem Standard-Node.js/TypeScript-Projektlayout. Die Verzeichnisstruktur sollte wie die folgende Struktur aussehen:
vector-search-agent-typescript/
├── src/
│ ├── agent.ts # Main agent application
│ ├── upload-documents.ts # Data upload utility
│ ├── cleanup.ts # Database cleanup utility
│ ├── vector-store.ts # Vector store and tool implementation
│ ├── utils/
│ │ ├── clients.ts # Azure OpenAI and DocumentDB client setup
│ │ ├── prompts.ts # System prompts and tool definitions
│ │ ├── types.ts # TypeScript type definitions
│ │ └── mongo.ts # MongoDB utility functions
│ └── scripts/ # Additional utility scripts
├── .env # Environment variable configuration
├── package.json # npm dependencies and scripts
└── tsconfig.json # TypeScript configuration
Erkunden Sie den Node.js-Code für die agentenbasierte RAG-Anwendung
In diesem Abschnitt werden die Kernkomponenten des AI-Agent-Workflows erläutert. Es hebt hervor, wie die Agents Anforderungen verarbeiten, wie Tools die KI mit der Datenbank verbinden und wie Aufforderungen das Verhalten der KI leiten.
Node.js agentische RAG-Anwendung
Die src/agent.ts Datei orchestriert ein KI-gestütztes Hotelempfehlungssystem.
Die Anwendung verwendet zwei Azure-Dienste:
- Azure OpenAI, das KI-Modelle verwendet, die Abfragen verstehen und Empfehlungen generieren
- Azure DocumentDB, das Hoteldaten speichert und Vektor-Ähnlichkeitssuchen durchführt
Node.js Agent- und Toolkomponenten
Die drei Komponenten arbeiten zusammen, um die Hotelsuchanfrage zu verarbeiten:
- Planner-Agent – Interpretiert die Anfrage und entscheidet, wie gesucht werden soll
- Vektorsuchtool – Findet Hotels, die dem entsprechen, was der Planer-Agent beschreibt.
- Synthesizer-Agent - Schreibt eine hilfreiche Empfehlung basierend auf Suchergebnissen
Agentenbasierter RAG-Anwendungs-Workflow
Die Anwendung verarbeitet eine Hotelsuchanfrage in zwei Schritten:
- Planung: Der Workflow ruft den Planer-Agent auf, der die Abfrage des Benutzers analysiert (z. B. "Hotels in der Nähe von Laufpfaden"), und durchsucht die Datenbank nach übereinstimmenden Hotels.
- Synthese: Der Workflow ruft den Synthesizer-Agent auf, der die Suchergebnisse überprüft und eine personalisierte Empfehlung schreibt, in der erläutert wird, welche Hotels am besten mit der Anforderung übereinstimmen.
// Authentication
const clients = process.env.USE_PASSWORDLESS === 'true' || process.env.USE_PASSWORDLESS === '1' ? createClientsPasswordless() : createClients();
const { embeddingClient, plannerClient, synthClient, dbConfig } = clients;
console.log(`DEBUG mode is ${process.env.DEBUG === 'true' ? 'ON' : 'OFF'}`);
console.log(`DEBUG_CALLBACKS length: ${DEBUG_CALLBACKS.length}`);
// Get vector store (get docs, create embeddings, insert docs)
const store = await getExistingStore(
embeddingClient,
dbConfig);
const query = process.env.QUERY || "quintessential lodging near running trails, eateries, retail";
const nearestNeighbors = parseInt(process.env.NEAREST_NEIGHBORS || '5', 10);
//Run planner agent
const hotelContext = await runPlannerAgent(plannerClient, embeddingClient, query, store, nearestNeighbors);
if (process.env.DEBUG === 'true') console.log(hotelContext);
//Run synth agent
const finalAnswer = await runSynthesizerAgent(synthClient, query, hotelContext);
// Get final recommendation (data + AI)
console.log('\n--- FINAL ANSWER ---');
console.log(finalAnswer);
Node.js Agenten zur Planung und Synthesierung
Die src/agent.ts Quelldatei implementiert die Planner- und Synthesizer-Agents, die zusammenarbeiten, um Hotelsuchanfragen zu verarbeiten.
Planungsagent
Der Planner-Agent ist der Entscheidungsträger , der bestimmt, wie nach Hotels gesucht wird.
Der Planner-Agent empfängt die Abfrage der natürlichen Sprache des Benutzers und sendet sie mithilfe des Agent-Frameworks von LangChain an ein KI-Modell zusammen mit verfügbaren Tools, die er verwenden kann. Die KI entscheidet, das Vektorsuchtool aufzurufen und Stellt Suchparameter bereit. LangChain verarbeitet die Toolausführung automatisch und gibt die passenden Hotels zurück. Anstatt die Suchlogik fest zu programmieren, interpretiert die KI, was der Benutzer möchte, und wählt die Suchmethode aus, wodurch das System flexibel für verschiedene Arten von Abfragen wird.
async function runPlannerAgent(
plannerClient: any,
embeddingClient: any,
userQuery: string,
store: AzureDocumentDBVectorStore,
nearestNeighbors = 5
): Promise<string> {
console.log('\n--- PLANNER ---');
const userMessage = `Use the "${TOOL_NAME}" tool with nearestNeighbors=${nearestNeighbors} and query="${userQuery}". Do not answer directly; call the tool.`;
const contextSchema = z.object({
store: z.any(),
embeddingClient: z.any()
});
const agent = createAgent({
model: plannerClient,
systemPrompt: PLANNER_SYSTEM_PROMPT,
tools: [getHotelsToMatchSearchQuery],
contextSchema,
});
const agentResult = await agent.invoke(
{ messages: [{ role: 'user', content: userMessage }] },
// @ts-ignore
{ context: { store, embeddingClient }, callbacks: DEBUG_CALLBACKS }
);
const plannerMessages = agentResult.messages || [];
const searchResultsAsText = extractPlannerToolOutput(plannerMessages);
return searchResultsAsText;
}
Synthesizer Agent
Der Synthesizer-Agent ist der Autor , der hilfreiche Empfehlungen erstellt.
Der Synthesizer-Agent empfängt die ursprüngliche Benutzerabfrage zusammen mit den Suchergebnissen des Hotels. Es sendet alles an ein KI-Modell mit Anweisungen zum Schreiben von Empfehlungen. Sie gibt eine Natürliche Sprachantwort zurück, die Hotels vergleicht und die besten Optionen erläutert. Dieser Ansatz ist wichtig, da unformatierte Suchergebnisse nicht benutzerfreundlich sind. Der Synthesizer wandelt Datenbankdatensätze in eine Unterhaltungsempfehlung um, die erklärt, warum bestimmte Hotels den Anforderungen des Benutzers entsprechen.
async function runSynthesizerAgent(synthClient: any, userQuery: string, hotelContext: string): Promise<string> {
console.log('\n--- SYNTHESIZER ---');
let conciseContext = hotelContext;
console.log(`Context size is ${conciseContext.length} characters`);
const agent = createAgent({
model: synthClient,
systemPrompt: SYNTHESIZER_SYSTEM_PROMPT,
});
const agentResult = await agent.invoke({
messages: [{
role: 'user',
content: createSynthesizerUserPrompt(userQuery, conciseContext)
}]
});
const synthMessages = agentResult.messages;
const finalAnswer = synthMessages[synthMessages.length - 1].content;
console.log(`Output: ${finalAnswer.length} characters of final recommendation`);
return finalAnswer as string;
}
Agentenwerkzeuge für die Vektorspeichersuche
Die src/vector-store.ts Quelldatei definiert das Vektorsuchtool, das der Planner-Agent verwendet.
Die Toolsdatei definiert ein Suchtool, mit dem der KI-Agent Hotels finden kann. Dieses Tool zeigt, wie der Agent eine Verbindung mit der Datenbank herstellt. Die KI durchsucht die Datenbank nicht direkt. Es wird aufgefordert, das Suchtool zu verwenden, und das Tool führt die eigentliche Suche aus.
Node.js Funktion als Tooldefinition
Die Funktion LangChain tool erstellt ein Tool aus einer regulären TypeScript-Funktion. Die Tooldefinition enthält den Namen, die Beschreibung und das Schema (mithilfe von Zod zur Überprüfung). Diese Definition informiert die KI darüber, dass das Tool vorhanden ist und wie es richtig verwendet wird.
export const getHotelsToMatchSearchQuery = tool(
async ({ query, nearestNeighbors }, config): Promise<string> => {
try {
const store = config.context.store as AzureDocumentDBVectorStore;
const embeddingClient = config.context.embeddingClient as AzureOpenAIEmbeddings;
// Create query embedding and perform search
const queryVector = await embeddingClient.embedQuery(query);
const results = await store.similaritySearchVectorWithScore(queryVector, nearestNeighbors);
console.log(`Found ${results.length} documents from vector store`);
// Format results for synthesizer
const formatted = results.map(([doc, score]) => {
const md = doc.metadata as Partial<HotelForVectorStore>;
console.log(`Hotel: ${md.HotelName ?? 'N/A'}, Score: ${score}`);
return formatHotelForSynthesizer(md, score);
}).join('\n\n');
return formatted;
} catch (error) {
console.error('Error in getHotelsToMatchSearchQuery tool:', error);
return 'Error occurred while searching for hotels.';
}
},
{
name: TOOL_NAME,
description: TOOL_DESCRIPTION,
schema: z.object({
query: z.string(),
nearestNeighbors: z.number().optional().default(5),
}),
}
);
Node.js Toolausführung mit Azure DocumentDB-Vektorsuche
Wenn die KI das Tool aufruft, wird der Funktionsrumpf ausgeführt. Es generiert eine Einbettung, indem die Textabfrage mithilfe des Einbettungsmodells von Azure OpenAI in einen numerischen Vektor konvertiert wird. Anschließend durchsucht sie die Datenbank, indem sie den Vektor an Azure DocumentDB sendet, der Hotels mit ähnlichen Vektoren findet, was ähnliche Beschreibungen bedeutet. Schließlich werden Ergebnisse formatiert, indem die Datenbankdatensätze in lesbaren Text konvertiert werden, den der Synthesizer-Agent verstehen kann.
Die Implementierung nutzt LangChains AzureDocumentDBVectorStore für die nahtlose Integration in Azure DocumentDB.
Warum dieses Muster verwenden?
Das Trennen des Tools vom Agenten bietet Flexibilität. Die KI entscheidet, wann gesucht und was gesucht werden soll, während das Tool die Suche behandelt. Sie können weitere Tools hinzufügen, ohne die Agentlogik zu ändern.
Agent fordert zur Steuerung des KI-Verhaltens auf
Die src/utils/prompts.ts Quelldatei enthält Systemaufforderungen und Tooldefinitionen für die Agents.
Die Prompt-Datei definiert die Anweisungen und den Kontext, die den KI-Modellen für die Planer- und Synthesizer-Agenten bereitgestellt werden. Diese Hinweise lenken das Verhalten der KI und stellen sicher, dass sie ihre Rolle im Arbeitsablauf versteht.
Die Qualität der KI-Antworten hängt stark von klaren Anweisungen ab. Diese Eingabeaufforderungen legen Grenzen fest, definieren das Ausgabeformat und konzentrieren die KI auf das Ziel des Benutzers, eine Entscheidung zu treffen. Sie können diese Eingabeaufforderungen anpassen, um zu ändern, wie sich die Agents verhalten, ohne Code zu ändern.
export const PLANNER_SYSTEM_PROMPT = `You are a hotel search planner. Transform the user's request into a clear, detailed search query for a vector database.
CRITICAL REQUIREMENT: You MUST ALWAYS call the "${TOOL_NAME}" tool. This is MANDATORY for every request.
Use a tool call with:
- query (string)
- nearestNeighbors (number 1-20)
QUERY REFINEMENT RULES:
- If vague (e.g., "nice hotel"), add specific attributes: "hotel with high ratings and good amenities"
- If minimal (e.g., "cheap"), expand: "budget hotel with good value"
- Preserve specific details from user (location, amenities, business/leisure)
- Keep natural language - this is for semantic search
- Don't just echo the input - improve it for better search results
- nearestNeighbors: Use 3-5 for specific requests, 10-15 for broader requests, max 20
EXAMPLES:
User: "cheap hotel" → {"tool": "${TOOL_NAME}", "args": {"query": "budget-friendly hotel with good value and affordable rates", "nearestNeighbors": 10}}
User: "hotel near downtown with parking" → {"tool": "${TOOL_NAME}", "args": {"query": "hotel near downtown with good parking and wifi", "nearestNeighbors": 5}}
User: "nice place to stay" → {"tool": "${TOOL_NAME}", "args": {"query": "hotel with high ratings, good reviews, and quality amenities", "nearestNeighbors": 10}}
Do not answer the user directly. Always call the tool.`;
// ============================================================================
// Synthesizer Prompts
// ============================================================================
export const SYNTHESIZER_SYSTEM_PROMPT = `You are an expert hotel recommendation assistant using vector search results.
Only use the TOP 3 results provided. Do not request additional searches or call other tools.
GOAL: Provide a concise comparative recommendation to help the user choose between the top 3 options.
REQUIREMENTS:
- Compare only the top 3 results across the most important attributes: rating, score, location, price-level (if available), and key tags (parking, wifi, pool).
- Identify the main tradeoffs in one short sentence per tradeoff.
- Give a single clear recommendation with one short justification sentence.
- Provide up to two alternative picks (one sentence each) explaining when they are preferable.
FORMAT CONSTRAINTS:
- Plain text only (no markdown).
- Keep the entire response under 220 words.
- Use simple bullets (•) or numbered lists and short sentences (preferably <25 words per sentence).
- Preserve hotel names exactly as provided in the tool summary.
Do not add extra commentary, marketing language, or follow-up questions. If information is missing and necessary to choose, state it in one sentence and still provide the best recommendation based on available data.`;
Vorbereiten und Hochladen von Daten in Azure DocumentDB mit Node.js
Im Beispiel werden Hoteldaten aus einer JSON-Datei verwendet. Das Repository enthält zwei Versionen:
-
Hotels.json- Hoteldaten ohne Vektoreinbettungen (verwendet von diesem Beispiel) -
Hotels_Vector.json– Hoteldaten mit vorab berechneten Einbettungen (von anderen Beispielen verwendet)
Funktionsweise des Uploads
Das upload-documents.ts Skript führt drei Schritte aus:
-
Laden von Daten – Liest Hoteldatensätze aus der
Hotels.jsonDatei. -
Generieren Von Einbettungen – Für jedes Hotel sendet das Skript das
DescriptionFeld an das Azure OpenAI-Modelltext-embedding-3-small, um eine 1536-dimensionale Vektoreinbettung zu generieren. Dadurch wird die Textbeschreibung in eine numerische Darstellung konvertiert, die ihre semantische Bedeutung erfasst. - Einfügen und Indizieren – Das Skript fügt Dokumente (mit ihren Einbettungen) in die Azure DocumentDB-Auflistung ein und erstellt einen Vektorindex mithilfe des konfigurierten Algorithmus (IVF, HNSW oder DiskANN).
import { createClientsPasswordless, createClients } from './utils/clients.js';
import { getStore } from './vector-store.js';
/**
* Upload documents to Azure DocumentDB MongoDB Vector Store
*/
async function uploadDocuments() {
try {
console.log('Starting document upload...\n');
// Get clients based on authentication mode
const usePasswordless = process.env.USE_PASSWORDLESS === 'true' || process.env.USE_PASSWORDLESS === '1';
console.log(`Authentication mode: ${usePasswordless ? 'Passwordless (Azure AD)' : 'API Key'}`);
console.log('\nEnvironment variables check:');
console.log(` DATA_FILE_WITHOUT_VECTORS: ${process.env.DATA_FILE_WITHOUT_VECTORS}`);
console.log(` AZURE_DOCUMENTDB_DATABASENAME: ${process.env.AZURE_DOCUMENTDB_DATABASENAME}`);
console.log(` AZURE_DOCUMENTDB_COLLECTION: ${process.env.AZURE_DOCUMENTDB_COLLECTION}`);
console.log(` AZURE_DOCUMENTDB_CLUSTER: ${process.env.AZURE_DOCUMENTDB_CLUSTER}`);
console.log(` AZURE_OPENAI_EMBEDDING_MODEL: ${process.env.AZURE_OPENAI_EMBEDDING_MODEL}`);
const requiredEnvVars = [
'DATA_FILE_WITHOUT_VECTORS',
'AZURE_DOCUMENTDB_DATABASENAME',
'AZURE_DOCUMENTDB_COLLECTION',
'AZURE_DOCUMENTDB_CLUSTER',
'AZURE_OPENAI_EMBEDDING_MODEL',
];
const missingEnvVars = requiredEnvVars.filter((name) => {
const value = process.env[name];
return !value || value.trim().length === 0;
});
if (missingEnvVars.length > 0) {
throw new Error(`Missing required environment variables: ${missingEnvVars.join(', ')}`);
}
const clients = usePasswordless ? createClientsPasswordless() : createClients();
const { embeddingClient, dbConfig } = clients;
console.log('\ndbConfig properties:');
console.log(` instance: ${dbConfig.instance}`);
console.log(` databaseName: ${dbConfig.databaseName}`);
console.log(` collectionName: ${dbConfig.collectionName}`);
// Check for data file path
const dataFilePath = process.env.DATA_FILE_WITHOUT_VECTORS!;
console.log(`\nReading data from: ${dataFilePath}`);
console.log(`Database: ${dbConfig.databaseName}`);
console.log(`Collection: ${dbConfig.collectionName}`);
console.log(`Vector algorithm: ${process.env.VECTOR_INDEX_ALGORITHM || 'vector-ivf'}\n`);
// Upload documents using existing getStore function
const startTime = Date.now();
const store = await getStore(dataFilePath, embeddingClient, dbConfig);
const duration = ((Date.now() - startTime) / 1000).toFixed(2);
console.log(`\n✓ Upload completed in ${duration} seconds`);
// Close connection
await store.close();
console.log('✓ Connection closed');
// Force exit to ensure process terminates (Azure credential timers may still be active)
process.exit(0);
} catch (error: any) {
console.error('\n✗ Upload failed:', error?.message || error);
console.error('\nFull error:', error);
process.exit(1);
}
}
// Run the upload
uploadDocuments();
Vektorindexerstellung
Der Vektorindex ermöglicht eine schnelle Ähnlichkeitssuche. Wenn der Index erstellt wird, organisiert Azure DocumentDB die Einbettungsvektoren, sodass Abfragen wie "Hotels ähnlich dieser Beschreibung suchen" effizient beantwortet werden können, ohne jedes Dokument zu scannen.
Der von Ihnen ausgewählte Indextyp wirkt sich auf die Leistung aus:
| Algorithmus | Cluster tier (Clustertarif) | Am besten geeignet für |
|---|---|---|
| IVF | M10+ | Kleine bis mittlere Datasets, niedrigere Kosten |
| HNSW | M30+ | Hoher Datenabruf, schnelle Abfragen |
| DiskANN | M40+ | Große Datensätze, mehr als eine Milliarde Vektoren |
import {
AzureDocumentDBVectorStore,
AzureDocumentDBSimilarityType,
AzureDocumentDBConfig
} from "@langchain/azure-cosmosdb";
import type { AzureOpenAIEmbeddings } from "@langchain/openai";
import { readFileSync } from 'fs';
import { Document } from '@langchain/core/documents';
import { HotelsData, Hotel } from './utils/types.js';
import { TOOL_NAME, TOOL_DESCRIPTION } from './utils/prompts.js';
import { z } from 'zod';
import { tool } from "langchain";
import { MongoClient } from 'mongodb';
import { BaseMessage } from "@langchain/core/messages";
type HotelForVectorStore = Omit<Hotel, 'Description_fr' | 'Location' | 'Rooms'>;
// Helper function for similarity type
function getSimilarityType(similarity: string) {
switch (similarity.toUpperCase()) {
case 'COS': return AzureDocumentDBSimilarityType.COS;
case 'L2': return AzureDocumentDBSimilarityType.L2;
case 'IP': return AzureDocumentDBSimilarityType.IP;
default: return AzureDocumentDBSimilarityType.COS;
}
}
// Consolidated vector index configuration
function getVectorIndexOptions() {
const algorithm = process.env.VECTOR_INDEX_ALGORITHM || 'vector-ivf';
const dimensions = parseInt(process.env.EMBEDDING_DIMENSIONS || '1536');
const similarity = getSimilarityType(process.env.VECTOR_SIMILARITY || 'COS');
const baseOptions = { dimensions, similarity };
switch (algorithm) {
case 'vector-hnsw':
return {
kind: 'vector-hnsw' as const,
m: parseInt(process.env.HNSW_M || '16'),
efConstruction: parseInt(process.env.HNSW_EF_CONSTRUCTION || '64'),
...baseOptions
};
case 'vector-diskann':
return {
kind: 'vector-diskann' as const,
...baseOptions
};
case 'vector-ivf':
default:
Ausführen der agentischen RAG-Anwendung mit Node.js
Installieren von Abhängigkeiten:
npm installBevor Sie den Agenten ausführen, laden Sie Hoteldaten mit Einbettungen hoch. Der
upload-documents.tsBefehl lädt Hotels aus der JSON-Datei, generiert Einbettungen für jedes Hotel, fügt Dokumente in Azure DocumentDB ein, und erstellt einen Vektorindex.npm run uploadFühren Sie den Hotelempfehlungs-Agent mithilfe des
agent.tsBefehls aus. Der Agent ruft den Planner-Agenten, die Vektorsuche und den Synthesizer-Agenten auf. Die Ausgabe umfasst Ähnlichkeitsscores und die vergleichende Analyse des Synthesizer Agents mit Empfehlungen.npm startDEBUG mode is OFF DEBUG_CALLBACKS length: 0 Connected to existing vector store: Hotels.hotel_data --- PLANNER --- Found 5 documents from vector store Hotel: Nordick's Valley Motel, Score: 0.49866509437561035 Hotel: White Mountain Lodge & Suites, Score: 0.48731985688209534 Hotel: Trails End Motel, Score: 0.47985398769378662 Hotel: Country Comfort Inn, Score: 0.47431993484497070 Hotel: Lakefront Captain Inn, Score: 0.45787304639816284 --- SYNTHESIZER --- Context size is 3233 characters Output: 812 characters of final recommendation --- FINAL ANSWER --- 1. COMPARISON SUMMARY: • Nordick's Valley Motel has the highest rating (4.5) and offers free parking, air conditioning, and continental breakfast. It is located in Washington D.C., near historic attractions and trails. • White Mountain Lodge & Suites is a resort with unique amenities like a pool, restaurant, and meditation gardens, but has the lowest rating (2.4). It is located in Denver, surrounded by forest trails. • Trails End Motel is budget-friendly with a moderate rating (3.2), free parking, free wifi, and a restaurant. It is close to downtown Scottsdale and eateries. Key tradeoffs: - Nordick's Valley Motel excels in rating and proximity to historic attractions but lacks a pool or free wifi. - White Mountain Lodge & Suites offers resort-style amenities and forest trails but has the lowest rating. - Trails End Motel balances affordability and essential amenities but has fewer unique features compared to the others. 2. BEST OVERALL: Nordick's Valley Motel is the best choice for its high rating, proximity to trails and attractions, and free parking. 3. ALTERNATIVE PICKS: • Choose White Mountain Lodge & Suites if you prioritize resort amenities and forest trails over rating. • Choose Trails End Motel if affordability and proximity to downtown Scottsdale are your main concerns.
Anzeigen und Verwalten von Daten in Visual Studio Code
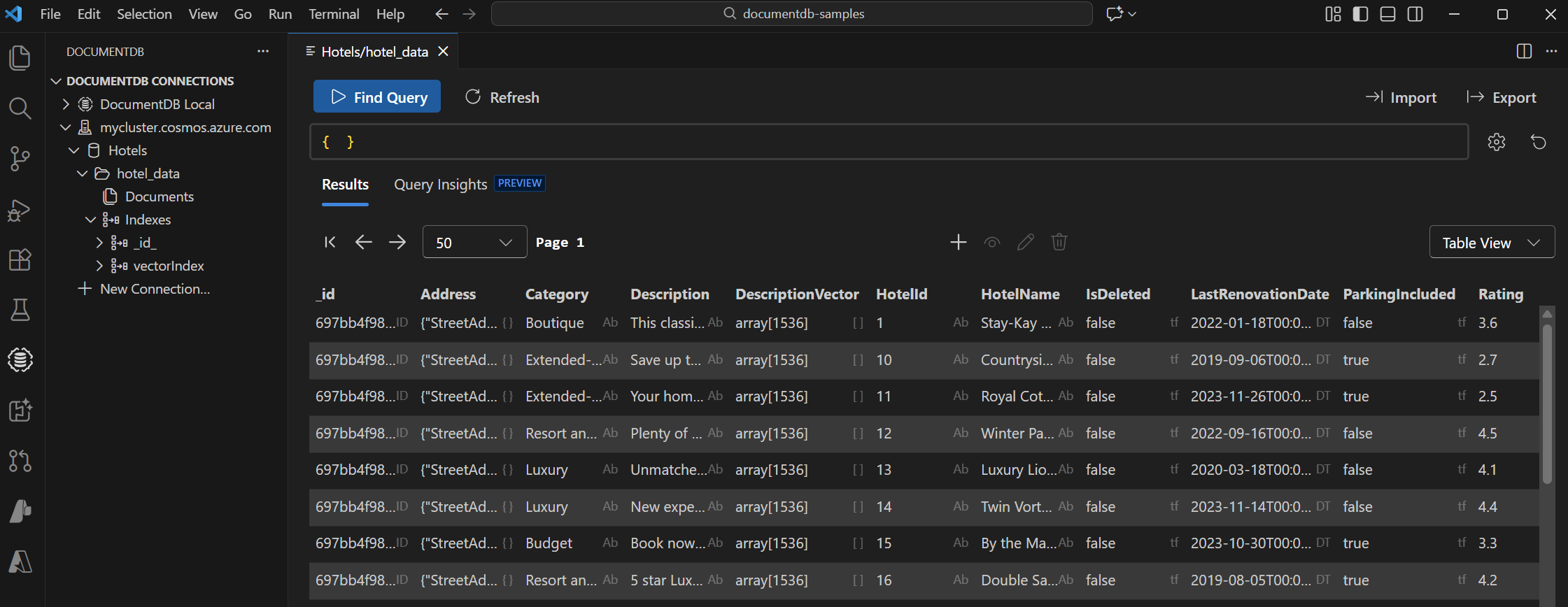
Wählen Sie die DocumentDB-Erweiterung in Visual Studio Code aus, um eine Verbindung mit Ihrem Azure DocumentDB-Konto herzustellen.
Zeigen Sie die Daten und Indizes der Datenbank "Hotels" an.
Bereinigen von Ressourcen
Wenn Sie azd up verwendet haben, um Ressourcen bereitzustellen, können Sie alle Azure-Ressourcen mit folgendem Befehl entfernen:
azd down
Wenn Sie die Ressourcen manuell erstellt haben und alle Ressourcen entfernen möchten, löschen Sie die Ressourcengruppe, um zusätzliche Kosten zu vermeiden.
Wenn Sie die Ressourcen wiederverwenden möchten, verwenden Sie den Bereinigungsbefehl, um die Testdatenbank zu löschen, wenn Sie fertig sind. Führen Sie den folgenden Befehl aus:
npm run cleanup