Was ist Apache Flink® in Azure HDInsight on AKS? (Vorschau)
Wichtig
Diese Funktion steht derzeit als Vorschau zur Verfügung. Die zusätzlichen Nutzungsbedingungen für Microsoft Azure-Vorschauen enthalten weitere rechtliche Bedingungen, die für Azure-Features in Betaversionen, in Vorschauversionen oder anderen Versionen gelten, die noch nicht allgemein verfügbar gemacht wurden. Informationen zu dieser spezifischen Vorschau finden Sie unter Informationen zur Vorschau von Azure HDInsight in AKS. Bei Fragen oder Funktionsvorschlägen senden Sie eine Anfrage an AskHDInsight mit den entsprechenden Details, und folgen Sie uns für weitere Updates in der Azure HDInsight-Community.
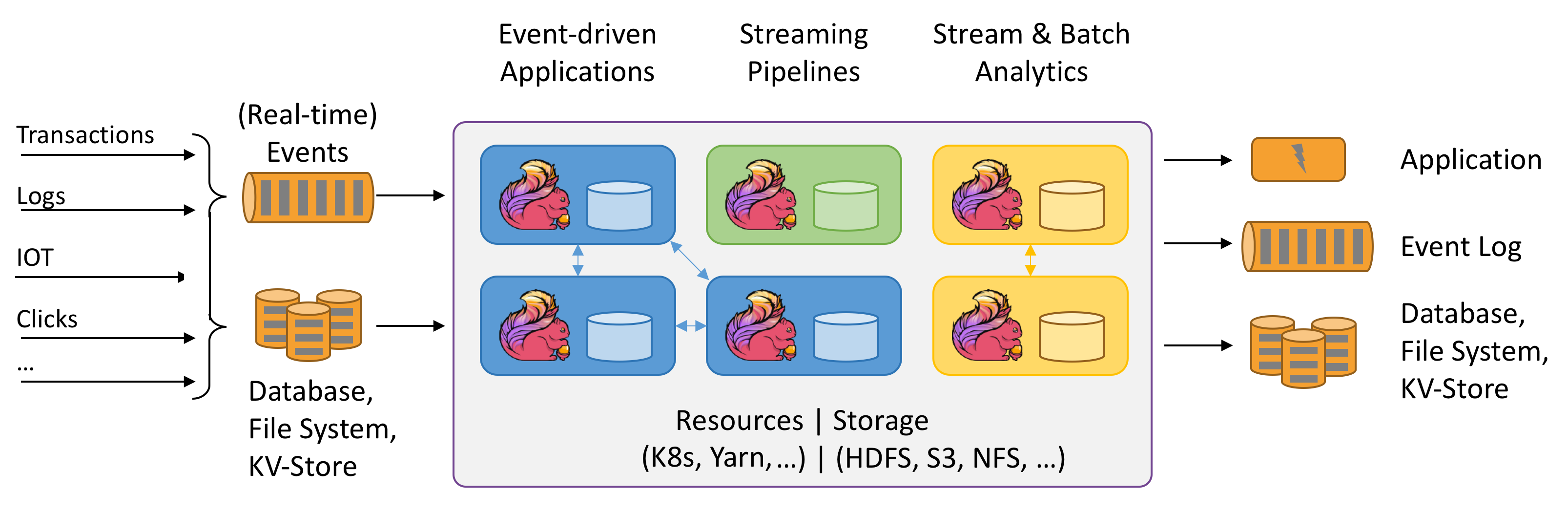
Apache Flink ist ein Framework und verteiltes Verarbeitungsmodul für zustandsbehaftete Berechnungen über ungebundene und gebundene Datenströme. Flink wurde entwickelt, um in allen gängigen Clusterumgebungen ausgeführt zu werden und um Berechnungen und zustandsbehaftete Streaminganwendungen mit speicherinterner Geschwindigkeit und beliebiger Skalierung durchzuführen. Anwendungen werden in möglicherweise Tausende von Aufgaben parallelisiert, die in einem Cluster verteilt und gleichzeitig ausgeführt werden. Daher kann eine Anwendung unbegrenzte Mengen von vCPUs, Hauptspeicher, Datenträger und Netzwerk-E/A verwenden. Darüber hinaus verwaltet Flink problemlos große Anwendungszustände. Der asynchrone und inkrementelle Prüfpunktalgorithmus sorgt für minimalen Einfluss auf die Verarbeitungslatenz und garantiert gleichzeitig Exactly-Once-Zustandskonsistenz.
Apache Flink ist ein massiv skalierbares Analysemodul für die Datenstromverarbeitung.
Einige der wichtigsten Features, die Flink bietet, sind:
- Vorgänge in gebundenen und ungebundenen Datenströmen
- In der Speicherleistung
- Möglichkeit für Streaming- und Batchberechnungen
- Niedrige Latenz, Vorgänge mit hohem Durchsatz
- Exactly-Once-Verarbeitung
- Hochverfügbarkeit
- Zustands- und Fehlertoleranz
- Vollständige Kompatibilität mit dem Hadoop-Ökosystem
- Einheitliche SQL-APIs sowohl für Stream als auch für Batch
Warum Apache Flink?
Apache Flink ist aufgrund seiner umfangreichen Features eine ausgezeichnete Wahl, um viele verschiedene Arten von Anwendungen zu entwickeln und auszuführen. Die Features von Flink umfassen Datenstrom- und Batchverarbeitungsunterstützung, komplexe Zustandsverwaltung, Ereigniszeitverarbeitungssemantik und Exactly-Once-Konsistenzgarantien für den Zustand. Flink hat keinen Single Point of Failure. Flink lässt sich bewährt auf Tausende von Kernen und Terabytes an Anwendungszuständen zu skalieren, bietet einen hohen Durchsatz, niedrige Latenz und ermöglicht einige der anspruchsvollsten Datenstromverarbeitungsanwendungen der Welt.
- Betrugserkennung: Flink kann verwendet werden, um betrügerische Transaktionen oder Aktivitäten in Echtzeit zu erkennen, indem komplexe Regeln und Machine Learning-Modelle auf Streamingdaten angewendet werden.
- Anomalieerkennung: Flink kann verwendet werden, um Ausreißer oder ungewöhnliche Muster in Streamingdaten, z. B. Sensorlesungen, Netzwerkdatenverkehr oder Benutzerverhalten zu identifizieren.
- Regelbasierte Warnung: Flink kann verwendet werden, um Warnungen oder Benachrichtigungen basierend auf vordefinierten Bedingungen oder Schwellenwerten für Streamingdaten wie Temperatur, Druck oder Aktienkurse auszulösen.
- Überwachung von Geschäftsprozessen: Flink kann verwendet werden, um den Status und die Leistung von Geschäftsprozessen oder Workflows, z. B. Auftragserfüllung, Lieferung oder Kundendienst in Echtzeit zu verfolgen und zu analysieren.
- Webanwendung (Soziale Netzwerke): Flink kann verwendet werden, um Webanwendungen zu betreiben, die eine Echtzeitverarbeitung von benutzergenerierten Daten, wie z. B. Nachrichten, Kommentare oder Empfehlungen erfordern.
Weitere Informationen zu gängigen Anwendungsfällen, finden Sie unter Apache Flink Anwendungsfälle
Apache Flink-Cluster in HDInsight on AKS sind ein vollständig verwalteter Dienst. Im Anschluss sind die Vorteile der Erstellung eines Flink-Clusters in HDInsight on AKS aufgeführt.
| Funktion | Beschreibung |
|---|---|
| Einfache Erstellung | Über das Azure-Portal, mithilfe von Azure PowerShell oder über das SDK können Sie in wenigen Minuten einen neuen Flink-Cluster in HDInsight erstellen. Siehe Erste Schritte mit Apache Spark-Clustern in HDInsight on AKS. |
| Benutzerfreundlichkeit | Flink-Cluster in HDInsight on AKS beinhalten portalbasierte Konfigurationsverwaltung und Skalierung. Zusätzlich zur Auftragsverwaltungs-API verwenden Sie die REST-API oder das Azure-Portal für die Auftragsverwaltung. |
| REST-APIs | Flink-Cluster in HDInsight on AKS enthalten die Auftragsverwaltungs-API, eine REST-API-basierte Flink-Auftragsübermittlungsmethode zur Remoteübermittlung und -überwachung von Aufträgen im Azure-Portal. |
| Bereitstellungstyp | Flink kann Anwendungen im Sitzungsmodus oder im Anwendungsmodus ausführen. Derzeit unterstützt HDInsight on AKS nur Sitzungscluster. Sie können mehrere Flink-Aufträge in einem Sitzungscluster ausführen. Der App-Modus ist in der Roadmap für HDInsight on AKS-Cluster enthalten. |
| Unterstützung für Metastore | Flink-Cluster in HDInsight on AKS können Kataloge mit Hive-Metastore in verschiedenen offenen Dateiformaten mit Remoteprüfpunkten für Azure Data Lake Storage Gen2 unterstützen. |
| Unterstützung für Azure Storage | Flink-Cluster in HDInsight können Azure Data Lake Storage Gen2 als Dateisenke verwenden. Weitere Informationen zu Data Lake Storage Gen2 finden Sie unter Azure Data Lake Storage Gen2. |
| Integration in Azure-Dienste | Flink-Cluster in HDInsight on AKS verfügen über eine Integration in Kafka sowie Azure Event Hubs und Azure HDInsight. Sie können Streaminganwendungen unter Verwendung von Event Hubs oder HDInsight erstellen. |
| Flexibilität | HDInsight on AKS ermöglicht es Ihnen, die Flink-Clusterknoten basierend auf einem Zeitplan mit der Autoskalierungsfunktion zu skalieren. Weitere Informationen finden Sie unter Automatisches Skalieren von Azure HDInsight on AKS-Clustern. |
| Status-Back-End | HDInsight on AKS verwendet standardmäßig RocksDB als Zustands-Backend. RocksDB ist ein einbettbarer persistenter Schlüsselwertspeicher zur schnellen Speicherung. |
| Prüfpunkte | Die Prüfpunkterstellung ist in HDInsight on AKS-Clustern standardmäßig aktiviert. Standardeinstellungen für HDInsight on AKS verwalten die letzten fünf Prüfpunkte im dauerhaften Speicher. Falls Ihr Auftrag fehlschlägt, kann der Auftrag vom letzten Prüfpunkt neu gestartet werden. |
| Inkrementelle Prüfpunkte | RocksDB unterstützt inkrementelle Prüfpunkte. Wir empfehlen die Verwendung inkrementeller Prüfpunkte für einen großen Zustand. Sie müssen dieses Feature manuell aktivieren. Wenn Sie in Ihrem flink-conf.yaml: state.backend.incremental: true einen Standardwert festlegen, werden inkrementelle Prüfpunkte aktiviert, es sei denn, die Anwendung setzt diese Einstellung im Code außer Kraft. Diese Anweisung ist standardmäßig wahr. Alternativ können Sie diesen Wert direkt im Code konfigurieren (dies setzt den Konfigurationsstandard außer Kraft): EmbeddedRocksDBStateBackend` backend = new `EmbeddedRocksDBStateBackend(true);. Standardmäßig behalten wir die letzten fünf Prüfpunkte im konfigurierten Prüfpunkt-Verzeichnis bei. Dieser Wert kann geändert werden, indem Sie die Konfiguration im Abschnitt mit der Konfigurationsverwaltung ändern: state.checkpoints.num-retained: 5. |
Apache Flink-Cluster in HDInsight on AKS enthalten die folgenden Komponenten. Diese sind standardmäßig in den Clustern verfügbar.
Informationen zu anstehenden Neuerungen finden Sie in der Roadmap.
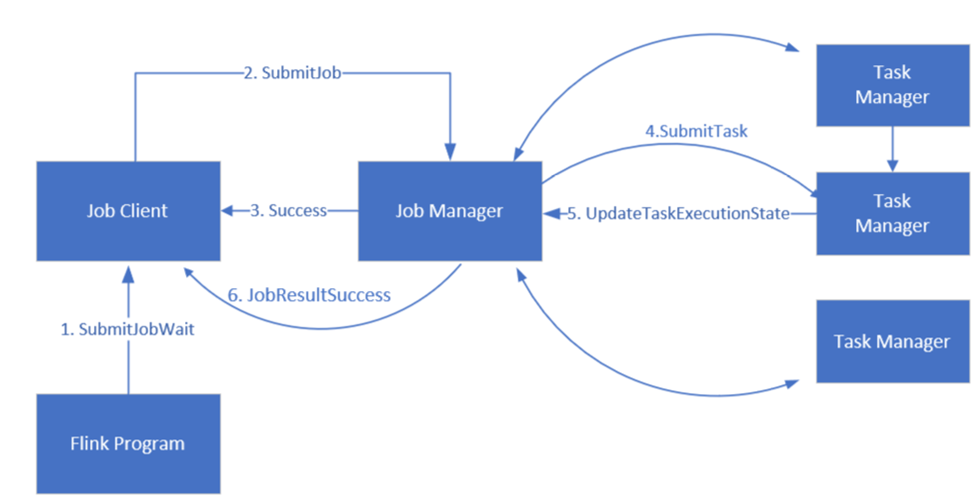
Apache Flink Auftragsverwaltung
Flink plant Aufträge mit drei verteilten Komponenten: Job-Manager, Task-Manager und Job-Client, die in einem Leader-Follower-Muster festgelegt sind.
Flink-Auftrag: Ein Flink-Auftrag (Job) oder Programm besteht aus mehreren Aufgaben. Aufgaben (Tasks) sind die grundlegende Ausführungseinheit in Flink. Jede Flink-Aufgabe verfügt je nach Parallelitätsebene über mehrere Instanzen, und jede Instanz wird auf einem Task-Manager ausgeführt.
Job Manager: Der Job-Manager fungiert als Planer und plant Vorgänge für Task-Manager.
Task-Manager: Task-Manager verfügen über einen oder mehrere Schlitze, um Aufgaben parallel auszuführen.
Job-Client: Der Job-Client kommuniziert mit dem Job-Manager, um Flink-Aufträge zu übermitteln
Flink Weboberfläche: Flink verfügt über eine Weboberfläche zum Überprüfen, Überwachen und Debuggen laufender Anwendungen.
Verweis
- Apache Flink-Website
- Apache, Apache Kafka, Kafka, Apache Flink, Flink und zugehörige Open Source-Projektnamen sind Handelsmarken der Apache Software Foundation (ASF).